目录
1. XGBoost VS 梯度提升树
1.1 XGBoost实现精确性与复杂度之间的平衡
1.2 XGBoost极大程度地降低模型复杂度、提升模型运行效率
1.3 保留了部分与梯度提升树类似的属性
2. XGBoost回归的sklearnAPI实现
2.1 sklearn API 实现回归
2.2 sklearn API 实现分类
3. XGBoost回归的原生代码实现
4. XGBoost分类的代码实现
4.1 二分类
4.2 多分类
极限提升树XGBoost(Extreme Gradient Boosting,XGB)是基于梯度提升树GBDT全面升级的新一代提升算法,也是提升家族中最富盛名、最灵活、最被机器学习竞赛所青睐的算法。XGBoost是一个以提升树为核心的算法系统,它覆盖了至少3+建树流程、10+损失函数,可以实现各种类型的梯度提升树。同时,XGBoost天生被设计成支持巨量数据,因此可以自由接入GPU/分布式/数据库等系统、还创新了众多工程上对传统提升算法进行加速的新方法。
作为Boosting算法,XGBoost中自然包含Boosting三要素:
① 损失函数𝐿(𝑥,𝑦):用以衡量模型预测结果与真实结果的差异
② 弱评估器𝑓(𝑥):(一般为)决策树,不同的boosting算法使用不同的建树过程
③ 综合集成结果𝐻(𝑥):即集成算法具体如何输出集成结果
同时,XGBoost也遵循boosting算法的基本流程进行建模:
依据上一个弱评估器的结果,计算损失函数
,
并使用自适应地影响下一个弱评估器
的构建。
集成模型输出的结果,受到整体所有弱评估器 ~
的影响。
1. XGBoost VS 梯度提升树
1.1 XGBoost实现精确性与复杂度之间的平衡
树的集成模型是机器学习中最为强大的学习器之一,这一族学习器的特点是精确性好、适用于各种场景,但运行缓慢、且过拟合风险很高,树模型的学习能力与过拟合风险之间的平衡,就是预测精确性与模型复杂度之间的平衡,也是经验风险与结构风险之间的平衡,这一平衡对决策树以及树的集成模型来说是永恒的议题。在过去,我们总是先建立效果优异的模型,再依赖于手动剪枝来调节树模型的复杂度,但在XGBoost中,精确性与复杂度会在训练的每一步被考虑到。主要体现在:
① XGBoost为损失函数𝐿(𝑦,𝑦̂ )加入结构风险项,构成目标函数𝑂(𝑦,𝑦̂ )
在AdaBoost与GBDT当中,我们的目标是找到损失函数𝐿(𝑦,𝑦̂ )的最小值,也就是让预测结果与真实结果差异最小,这一流程只关心精确性、不关心复杂度和过拟合情况。为应对这个问题,XGBoost从决策树的预剪枝流程、逻辑回归、岭回归、Lasso等经典算法的抗过拟合流程吸取经验,在损失函数中加入了控制过拟合的结构风险项,并将【𝐿(𝑦,𝑦̂ ) + 结构风险】定义为目标函数𝑂(𝑦,𝑦̂ )。这一变化让XGBoost在许多方面都与其他Boosting算法不同:例如,XGBoost是向着令目标函数最小化的目标进行训练,而不是令损失函数最小化的方向。再比如,XGBoost会优先利用结构风险中的参数来控制过拟合,而不像其他树的集成模型一样依赖于树结构参数(例如max_depth,min_impurity_decrease等)。
② 使用全新不纯度衡量指标,将复杂度纳入分枝规则
在之前的算法当中,无论Boosting流程如何进化,建立单棵决策树的规则基本都遵循CART树流程,在分类树中,使用信息增益(information gain)来衡量叶子的质量,在回归树中,使用MSE或者弗里德曼MSE来衡量叶子的质量。这一流程有成熟的剪枝机制、预测精度高、能够适应各种场景,但却可能建立复杂度很高的树。为实现精确性与复杂度之间的平衡,XGBoost重新设定了分枝指标【结构分数】(原论文中写作Structure Score,也被称为质量分数Quality Score),以及基于结构分数的【结构分数增益】(Gain of structure score),结构分数增益可以逼迫决策树向整体结构更简单的方向生长。这一变化让XGBoost使用与传统CART略有区别的建树流程,同时在建树过程中大量使用残差(Residuals)或类残差对象作为中间变量,因此XGBoost的数学过程比其他Boosting算法更复杂。
1.2 XGBoost极大程度地降低模型复杂度、提升模型运行效率
在任意决策树的建树过程中,都需要对每一个特征上所有潜在的分枝节点进行不纯度计算,当数据量巨大时,这一计算将消耗巨量的时间,因此树集成模型的关键缺点之一就是计算缓慢。为了提升树模型的运算速度、同时又不极大地伤害模型的精确性,将算法武装成更加适合于大数据的算法,XGBoost使用多种优化技巧来实现效率提升:
① 使用估计贪婪算法、平行学习、分位数草图算法等方法构建了适用于大数据的全新建树流程。
② 使用感知缓存访问技术与核外计算技术,提升算法在硬件上的运算性能。
③ 引入Dropout技术,为整体建树流程增加更多随机性、让算法适应更大数据
1.3 保留了部分与梯度提升树类似的属性
① 弱评估器的输出类型与集成算法输出类型不一致
对于AdaBoost或随机森林算法来说,当集成算法执行的是回归任务时,弱评估器也是回归器,当集成算法执行分类任务时,弱评估器也是分类器。但对于GBDT以及基于GBDT的复杂Boosting算法们而言,无论集成算法整体在执行回归/分类/排序任务,弱评估器一定是回归器。GBDT通过sigmoid或softmax函数输出具体的分类结果,但实际弱评估器一定是回归器,XGBoost也是如此。
② 拟合负梯度,且当损失函数是0.5倍MSE时,拟合残差
任意Boosting算法都有自适应调整弱评估器的步骤。在GBDT当中,每次用于建立弱评估器的是样本𝑋以及当下集成输出𝐻(𝑥𝑖)与真实标签𝑦之间的伪残差(也就是负梯度)。当损失函数是1/2𝑀𝑆𝐸时,负梯度在数学上等同于残差(Residual),因此GBDT是通过拟合残差来影响后续弱评估器结构。XGBoost也是依赖于拟合残差来影响后续弱评估器结构。
③ 抽样思想
GBDT借鉴了大量Bagging算法中的抽样思想,XGBoost也继承了这一属性,因此在XGBoost当中,我们也可以对样本和特征进行抽样来增大弱评估器之间的独立性。
2. XGBoost回归的sklearnAPI实现
XGBoost自带sklearn接口(sklearn API),通过这个接口,我们可以使用跟sklearn代码一样的方式来实现xgboost,即可以通过fit和predict等接口来执行训练预测过程,也可以调用属性比如coef_等。在XGBoost的sklearn API中,可以看到下面五个类:
| 类 | 说明 |
|---|---|
| XGBRegressor() | 实现xgboost回归 |
| XGBClassifier() | 实现xgboost分类 |
| XGBRanker() | 实现xgboost排序 |
| XGBRFClassifier() | 基于xgboost库实现随机森林分类 |
| XGBRFRegressor() | 基于xgboost库实现随机森林回归 |
其中XGBRF的两个类是以XGBoost方式建树、但以bagging方式构建森林的类,通常只有在使用普通随机森林效果不佳、但又不希望使用Boosting的时候使用。另外两个类一个是XGBoost的回归,一个是XGBoost的分类。这两个类的参数高度相似:
class xgboost.XGBRegressor(n_estimators, max_depth, learning_rate, verbosity, objective,
booster, tree_method, n_jobs, gamma, min_child_weight, max_delta_step, subsample,
colsample_bytree, colsample_bylevel, colsample_bynode, reg_alpha, reg_lambda,
scale_pos_weight, base_score, random_state, missing, num_parallel_tree,
monotone_constraints, interaction_constraints, importance_type, gpu_id,
validate_parameters, predictor, enable_categorical, eval_metric, early_stopping_rounds,
callbacks,**kwargs)class xgboost.XGBClassifier(n_estimators, use_label_encoder, max_depth, learning_rate,
verbosity, objective, booster, tree_method, n_jobs, gamma, min_child_weight,
max_delta_step, subsample, colsample_bytree, colsample_bylevel, colsample_bynode,
reg_alpha, reg_lambda, scale_pos_weight, base_score, random_state, missing,
num_parallel_tree, monotone_constraints, interaction_constraints, importance_type, gpu_id,
validate_parameters, predictor, enable_categorical, **kwargs)2.1 sklearn API 实现回归
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from xgboost import XGBRegressor
from sklearn.model_selection import cross_validate, KFold
from sklearn.model_selection import train_test_split
#回归数据
data = pd.read_csv(r"F:\\Jupyter Files\\机器学习进阶\\datasets\\House Price\\train_encode.csv",index_col=0)
X = data.iloc[:,:-1]
y = data.iloc[:,-1]
#sklearn普通训练代码三步走:实例化,fit,score
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.3,random_state=1412)
xgb_sk = XGBRegressor(random_state=1412) #实例化模型
xgb_sk.fit(Xtrain,Ytrain)
xgb_sk.score(Xtest,Ytest) #默认指标R2
#sklearn交叉验证三步走:实例化,交叉验证,对结果求平均
xgb_sk = XGBRegressor(random_state=1412) #实例化模型
#定义所需的交叉验证方式
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
result_xgb_sk = cross_validate(xgb_sk,X,y,cv=cv
,scoring="neg_root_mean_squared_error" #负根均方误差
,return_train_score=True
,verbose=True)
def RMSE(result,name):
return abs(result[name].mean())
RMSE(result_xgb_sk,"train_score") #940.7718003131752
RMSE(result_xgb_sk,"test_score") #29753.814742669765
在默认参数下,xgboost模型极度不稳定,并且过拟合的情况非常严重,在训练集上的RMSE达到了低点940.77,这说明XGBoost的学习能力的确强劲,现有数据量对xgboost来说可能有点不足。在没有调整任何参数的情况下,XGBoost的表现没能胜过梯度提升树,这可能是因为在默认参数下梯度提升树的过拟合程度较轻。对XGBoost的参数略微进行调整,例如将最可能影响模型的参数之一:max_depth设置为一个较小的值:
xgb_sk = XGBRegressor(max_depth=5,random_state=1412) #实例化
result_xgb_sk = cross_validate(xgb_sk,X,y,cv=cv
,scoring="neg_root_mean_squared_error" #负根均方误差
,return_train_score=True
,verbose=True)
RMSE(result_xgb_sk,"train_score") #2362.6596931022264
RMSE(result_xgb_sk,"test_score") #28623.2199609373过拟合程度立刻减轻了,这说明模型是有潜力的,经过精密的调参之后xgboost上应该能够获得不错的结果。
当sklearn API训练完毕之后,我们可以调用sklearn中常见的部分属性对训练后的模型进行查看,例如查看特征重要性的属性feature_importances_,以及查看XGB下每一棵树的get_booster()方法、查看总共有多少棵树的get_num_boosting_rounds()方法、以及查看当前所有参数的方法get_params。
xgb_sk = XGBRegressor(max_depth=5,random_state=1412).fit(X,y)
xgb_sk.feature_importances_ #查看特征重要性
xgb_sk.get_num_boosting_rounds() #查看一共建立了多少棵树,相当于是n_estimators的取值
xgb_sk.get_params() ##获取每一个参数的取值2.2 sklearn API 实现分类
from xgboost import XGBClassifier
from sklearn.datasets import load_digits
#多分类数据
X_multi = load_digits().data
y_multi = load_digits().target
data_multi = xgb.DMatrix(X_multi, y_multi)
clf = XGBClassifier()
clf = XGBClassifier(objective="multi:softmax"
, eval_metric="mlogloss" #设置评估指标避免警告
, num_class = 10)
clf = clf.fit(X_multi,y_multi)
clf.predict(X_multi) #输出具体数值 - 具体的预测类别 #array([0, 1, 2, ..., 8, 9, 8])
clf.score(X_multi,y_multi) #虽然设置了评估指标,但score接口还是准确率 #1.03. XGBoost回归的原生代码实现
首先,原生代码必须使用XGBoost自定义的数据结构DMatrix,这一数据结构能够保证xgboost算法运行更快,并且能够自然迁移到GPU上运行,类似于列表、数组、Dataframe等结构都不能用于原生代码,因此使用原生代码的第一步就是要更换数据结构。

当设置好数据结构后,需要以字典形式设置参数。XGBoost也可以接受像sklearn一样,将所有参数都写在训练所用的类当中,然而由于xgboost的参数列表过长、参数类型过多,直接将所有参数混写在训练模型的类中会显得代码冗长且混乱,因此我们往往会使用字典单独呈现参数。准备好参数列表后,我们将使用xgboost中自带的方法xgb.train或xgb.cv进行训练,训练完毕后,可以使用predict方法对结果进行预测。虽然xgboost原生代码库所使用的数据结构是DMatrix,但在预测试输出的数据结构却是普通的数组,因此可以直接使用sklearn中的评估指标,或者python编写的评估指标进行评估。xgboost原生代码中最关键的方法:
class xgboost.DMatrix(data, label=None, *, weight=None, base_margin=None, missing=None,
silent=False, feature_names=None, feature_types=None, nthread=None, group=None, qid=None,
label_lower_bound=None, label_upper_bound=None, feature_weights=None,
enable_categorical=False)
function xgboost.train(*params, dtrain, num_boost_round=10, *, evals=None, obj=None,
feval=None, maximize=None, early_stopping_rounds=None, evals_result=None,
verbose_eval=True, xgb_model=None, callbacks=None, custom_metric=None)
function xgboost.cv(*params, dtrain, num_boost_round=10, nfold=3, stratified=False,
folds=None, metrics=(), obj=None, feval=None, maximize=None, early_stopping_rounds=None,
fpreproc=None, as_pandas=True, verbose_eval=None, show_stdv=True, seed=0, callbacks=None,
shuffle=True, custom_metric=None)其中,方法xgb.train和xgb.cv的第一个参数params就是需要使用字典自定义的参数列表,第二个参数dtrain就是DMatrix结构的训练数据,第三个参数num_boost_round其实就等同于sklearn中的n_estimators,表示总共建立多少棵提升树,也就是提升过程中的迭代次数。
XGBoost模块的三步走:将数据转换为DMatrix,定义需要输入的参数params,直接调用训练:
import xgboost as xgb
# 将数据转换为DMatrix
data_xgb = xgb.DMatrix(X,y)
#如果有分割训练集和测试集
from sklearn.model_selection import train_test_split
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.3,random_state=1412)
dtrain = xgb.DMatrix(Xtrain,Ytrain)
dtest = xgb.DMatrix(Xtest,Ytest)
#定义所需要输出的参数,直接进行训练
params = {"max_depth":5,"seed":1412}
reg = xgb.train(params, data_xgb, num_boost_round=100)
y_pred = reg.predict(data_xgb)
y_pred
------------------------------------------------------------
array([204427.03, 181824.06, 220590.2 , ..., 266362.62, 141301.05,
149763.83], dtype=float32)使用sklearn中的评估指标进行评估:
from sklearn.metrics import mean_squared_error as MSE
MSE(y,y_pred,squared=False) #对回归类算法,xgboost的默认评估指标是RMSE
--------------------------------------------
16853.386170715003使用交叉验证进行训练:
params = {"max_depth":5,"seed":1412}
result = xgb.cv(params,data_xgb,num_boost_round=100
,nfold=5 #补充交叉验证中所需的参数,nfold=5表示5折交叉验证
,seed=1412 #交叉验证的随机数种子,params中的是管理boosting过程的随机数种子
)
result
----------------------------------------------------------
train-rmse-mean train-rmse-std test-rmse-mean test-rmse-std
0 141522.721875 1318.896997 141941.484375 6432.947712
1 102183.568750 1053.673671 103857.753125 5778.064364
2 74524.579688 728.019143 77554.021875 5732.164228
3 55214.231250 465.428776 59894.982031 6121.923227
4 41754.467188 345.496649 47824.114063 5734.477932
... ... ... ... ...
95 2513.421875 206.432972 28623.110938 7513.194129
96 2476.676709 201.605999 28624.677344 7517.551419
97 2440.533399 203.698024 28620.468359 7523.209246
98 2405.017529 210.983203 28619.228125 7525.503699
99 2362.659668 218.221383 28623.220313 7526.333222
100 rows × 4 columns
result返回了一个100行,4列的矩阵,格式为DataFrame。该矩阵行数与迭代次数一致,当我们规定迭代次数为100时,这个矩阵就有100行,如果我们规定的迭代次数为10,这个矩阵就只会有10行。每一行代表了每次迭代后进行交叉验证的结果的均值,例如索引为0的行就表示迭代了一次时(刚建立第一棵树时),进行5折交叉验证的结果,最后一行的结果也就是当前模型迭代完毕后(建好了全部的nun_boost_round棵树时)输出的结果,也是之前使用sklearn API时得到过的结果:测试集上5折交叉验证结果28623.22。每次迭代后xgboost会执行5折交叉验证,并收集交叉验证上的训练集RMSE均值、训练集RMSE的标准差、测试集RMSE的均值、测试集RMSE的标准差,这些数据构成了4列数据。实际上,这个矩阵展示了每次迭代过后,进行5折交叉验证的结果,也展示出了随着迭代次数增多,模型表现变化的趋势,将输出结果绘制成图像。
plt.figure(dpi=300)
plt.plot(result["train-rmse-mean"])
plt.plot(result["test-rmse-mean"])
plt.legend(["train","test"])
plt.title("xgboost 5fold cv")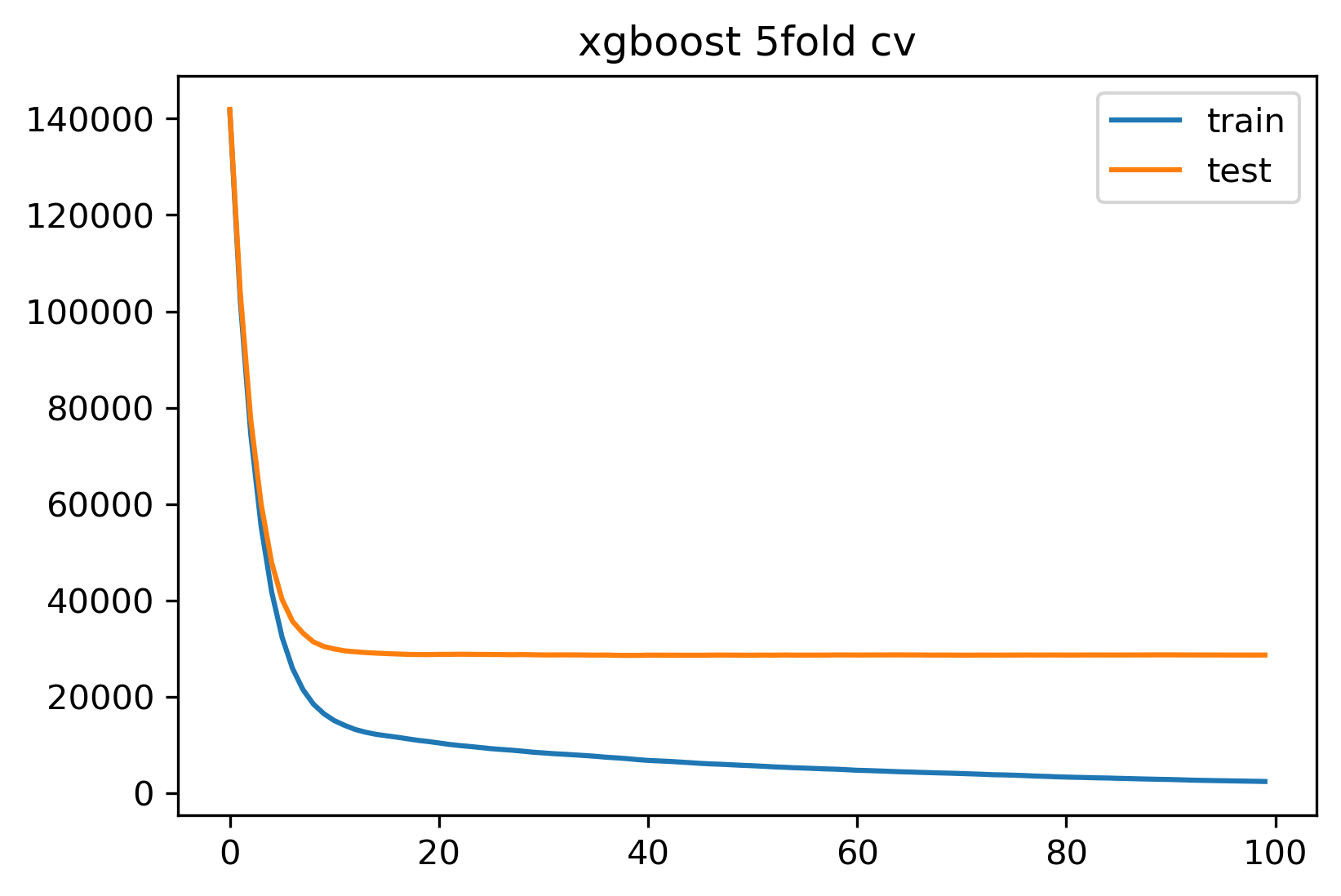
注:① DMatrix会将特征矩阵与标签打包在同一个对象中,且一次只能转换一组数据。并且,我们无法通过索引或循环查看内部的内容,一旦数据被转换为DMatrix,就难以调用或修改了。因此,数据预处理需要在转换为DMatrix之前做好。如果我们有划分训练集和测试集,则需要分别将训练集和测试集转换为DMatrix。
② XGBoost不需要实例化,xgb.train函数包揽了实例化和训练的功能,一行代码解决所有问题。同时,XGBoost在训练时没有区分回归和分类器,它默认是执行回归算法。
③ xgboost将参数分为了两大部分,一部分可以通过params进行设置,另一部分则需要在方法xgb.train或者xgb.cv中进行设置。一般来说,除了建树棵树num_boost_round、提前停止early_stopping_rounds这两个关键元素,其他参数基本都被设置在params当中。
4. XGBoost分类的代码实现
XGBoost默认会实现回归算法,因此在执行分类的时候,需要主动声明算法的类型。xgboost是通过当前算法所使用的损失函数来判断任务类型的,即是通过在params中填写的objective参数来判断任务类型。当不再执行回归任务时,模型的评估指标也会发生变化,因此xgboost分类所需要的参数会更多。objective参数中可以输入数十种不同的选项,常见的有:
◆用于回归
reg:squarederror:平方损失,即,其中
是为了计算简便。
reg:squaredlogerror:平方对数损失,即,其中
是为了计算简便
◆用于分类
binary:logistic:二分类交叉熵损失,使用该损失时predict接口输出概率。
binary:logitraw:二分类交叉熵损失,使用该损失时predict接输出执行sigmoid变化之前的值
multi:softmax:多分类交叉熵损失,使用该损失时predict接口输出具体的类别。
multi:softprob:多分类交叉熵,适用该损失时predict接口输出每个样本每个类别下的概率
除此之外,还有众多用于排序算法、计数算法的损失函数。xgboost几乎适用于所有可微的损失函数,不同的损失函数会影响predict的输出,但却不会影响交叉验证方法xgb.cv的输出。当不填写任何内容时,参数objective的默认值为reg:squarederror。
4.1 二分类
#导入2个最简单的分类数据集:乳腺癌数据集与手写数字数据集
from sklearn.datasets import load_breast_cancer, load_digits
#二分类数据
X_binary = load_breast_cancer().data
y_binary = load_breast_cancer().target
data_binary = xgb.DMatrix(X_binary,y_binary)
#设置params,进行训练
params1 = {"seed":1412, "objective":"binary:logistic"
,"eval_metric":"logloss" #二分类交叉熵损失
}
clf_binary = xgb.train(params1, data_binary, num_boost_round=100)
#预测与评估
y_pred_binary = clf_binary.predict(data_binary)
y_pred_binary[:20] #二分类直接返回概率,不返回类别,需要自己转换
------------------------------------------------------------------
array([5.8410629e-03, 5.9211289e-04, 1.5155278e-04, 2.4505438e-02,
8.6602634e-03, 2.3524903e-02, 8.7698136e-05, 2.2055734e-04,
1.5081177e-03, 4.2824438e-03, 1.5698196e-02, 2.2565569e-04,
4.6376034e-04, 9.0418644e-03, 7.7753547e-03, 6.4944592e-04,
9.2663817e-05, 1.2998856e-04, 9.4483788e-05, 9.9722409e-01],
dtype=float32)from sklearn.metrics import accuracy_score as ACC #当返回具体类别时,可以使用准确率
from sklearn.metrics import log_loss as logloss #当返回概率时,则必须使用交叉熵损失
(y_pred_binary > 0.5).astype("int") #转换成类别
ACC(y_binary,(y_pred_binary > 0.5).astype(int)) #对二分类计算准确率,则必须先转换为类别
logloss(y_binary,y_pred_binary) #只有二分类输出了概率,因此可以查看交叉熵损失4.2 多分类
对多分类算法来说,除了设置损失函数和评估指标,还需要设置参数num_class。参数num_class用于多分类状况下、具体的标签类别数量,例如,如果是三分类,则需设置{"num_calss":3}。
#多分类数据
X_multi = load_digits().data
y_multi = load_digits().target
data_multi = xgb.DMatrix(X_multi, y_multi)
#设置params,进行训练
params2 = {"seed":1412, "objective":"multi:softmax"
,"eval_metric":"mlogloss" #多分类交叉熵损失 #"merror"
,"num_class":10}
clf_multi = xgb.train(params2, data_multi, num_boost_round=100)
#预测与评估
y_pred_multi = clf_multi.predict(data_multi)
y_pred_multi #多分类,选择`multi:softmax`时返回具体类别,也可以选择`multi:softprob`返回概率。
-------------------------------------------------------
array([0., 1., 2., ..., 8., 9., 8.], dtype=float32)ACC(y_multi, y_pred_multi)
------------------------------
1.0#交叉验证
params2 = {"seed":1412
, "objective":"multi:softmax" #无论填写什么损失函数都不影响交叉验证的评估指标
, "num_class":10}
result = xgb.cv(params2,data_multi,num_boost_round=100
,metrics = ("mlogloss") #交叉验证的评估指标由cv中的参数metrics决定
,nfold=5 #补充交叉验证中所需的参数,nfold=5表示5折交叉验证
,seed=1412 #交叉验证的随机数种子,params中的是管理boosting过程的随机数种子
)
result #返回多分类交叉熵损失
-----------------------------------------------------------------
train-mlogloss-mean train-mlogloss-std test-mlogloss-mean test-mlogloss-std
0 1.228912 0.006192 1.330349 0.039377
1 0.869281 0.005974 1.009304 0.046665
2 0.642709 0.005521 0.805701 0.050207
3 0.484223 0.004590 0.658486 0.049434
4 0.370331 0.004205 0.552657 0.049002
... ... ... ... ...
95 0.003921 0.000027 0.118105 0.027968
96 0.003908 0.000026 0.118007 0.027899
97 0.003896 0.000026 0.118073 0.027942
98 0.003885 0.000026 0.117976 0.027911
99 0.003874 0.000026 0.117779 0.027960
100 rows × 4 columns参数metrics支持多个评估指标:
params3 = {"seed":1412
, "objective":"multi:softmax" #无论填写什么损失函数都不影响交叉验证的评估指标
, "num_class":10}
result = xgb.cv(params3,data_multi,num_boost_round=100
,metrics = ("mlogloss","merror")
,nfold=5 #补充交叉验证中所需的参数,nfold=5表示5折交叉验证
,seed=1412 #交叉验证的随机数种子,params中的是管理boosting过程的随机数种子
)
result #可以执行多个指标,让输出结果的列数翻倍
------------------------------------------------------------
train-mlogloss-mean train-mlogloss-std train-merror-mean train-merror-std test-mlogloss-mean test-mlogloss-std test-merror-mean test-merror-std
0 1.228912 0.006192 0.030746 0.002658 1.330349 0.039377 0.122978 0.022670
1 0.869281 0.005974 0.014329 0.003948 1.009304 0.046665 0.094041 0.022593
2 0.642709 0.005521 0.008765 0.002732 0.805701 0.050207 0.080682 0.022009
3 0.484223 0.004590 0.005147 0.001432 0.658486 0.049434 0.070664 0.022264
4 0.370331 0.004205 0.003200 0.001362 0.552657 0.049002 0.065101 0.018976
... ... ... ... ... ... ... ... ...
95 0.003921 0.000027 0.000000 0.000000 0.118105 0.027968 0.038392 0.005910
96 0.003908 0.000026 0.000000 0.000000 0.118007 0.027899 0.038392 0.005910
97 0.003896 0.000026 0.000000 0.000000 0.118073 0.027942 0.038392 0.005910
98 0.003885 0.000026 0.000000 0.000000 0.117976 0.027911 0.038392 0.005910
99 0.003874 0.000026 0.000000 0.000000 0.117779 0.027960 0.038392 0.005910
100 rows × 8 columns