一、说明
强化学习代理是一个自主决策的人工智能智能系统,它通过与环境进行交互,通过试错学习,逐步优化其行为以实现其目标。这种代理能够学习如何在环境中进行行为,以实现预期的目标。代理可以通过尝试不同的行为来评估其对环境的影响,并根据它做出的决策获得奖励或惩罚。
在强化学习中,代理按照特定的方式选择行动,并从环境中获取反馈(奖励或惩罚)。代理基于获得的反馈来调整其策略,以便在相同的环境下获得更高的奖励。这种学习过程可以持续不断,直到代理的性能达到最优。
由于强化学习代理具有自主决策的能力,因此它们可以用于各种不同的自主控制环境中,例如自动驾驶汽车、机器人和电力网络控制系统等。
二、介绍
强化学习专家面临的最大挑战之一是他们无法控制智能体的动作行为。有时让座席收敛并最大化奖励是不够的,你还希望你的座席有平滑的操作。让我们看几个例子:
2.1 交易
在交易中,对交易者不利的最大力量是交易成本。您更改投资组合的频率越高,产生的交易成本就越高。我的RL交易代理过去常常在某一天建立完全多头头寸,另一天做空。这种双重交易成本吞噬了我所有的回报。可悲吧!
2.2 热交换
想象一下,您正在控制火力发电厂或建筑物中的蒸汽温度。您构建了一个在保持近乎恒定的温度方面效果很好的代理,但问题是代理在 1 秒或 1 次步长内从 +1(全热输入)跳到 -1(全热输出)。这种不稳定的热流跳跃会损坏您的热流控制系统,或者控制系统甚至可能不支持这种不稳定的跳跃。
2.3 自动驾驶汽车
强化学习剂广泛应用于自动驾驶汽车案例。想象一下,RL代理将车辆从“全左”转向“全右”。你不想给自己找一辆这样的自动驾驶汽车。
这个问题在强化学习代理为现实生活中的业务用例部署时是一个大问题。我希望本博客中介绍的解决方案可以解决这个问题,并使 RL 更接近业务用例。
三、解决
老实说,这是一个研究课题,但有一些非常合理的捷径。我们可以通过稍微调整奖励函数来解决这个问题。本博客主要讨论如何进行这种简单的调整。这是我观察到这个不稳定的动作跳跃问题时尝试的第一件事。
3.1将交易添加到奖励
这个想法简单而优雅。将“操作更改”或操作增量添加到奖励功能。简单对吧。让我们讨论一个例子并使其具体化。
3.2 热交换问题
这个博客的想法是解释一种处理不稳定奖励功能的方法。所以环境没有详细描述。环境很简单:
- 动作:(-1, 1), +1: 最大热量, -1: 最大热量输出之间的连续操作
- 奖励:越接近目标温度,奖励越高
3.3 无奖励调整的环境代码:
import numpy as np
import random
import matplotlib.pyplot as plt
import time
import gym
from gym import spaces
import numpy as np
class Room:
def __init__(self, mC=300, K=20, Q_AC_Max = 1500, simulation_time = 12*60*60, control_step = 300):
self.timestep = control_step
self.max_iteration = int(simulation_time/self.timestep)
self.Q_AC_Max = Q_AC_Max
self.mC = mC
self.K = K
def reset(self,T_in = 20):
self.iteration = 0
self.schedule()
self.T_in = T_in
def schedule(self):
self.T_set = 25
self.T_out = np.empty(self.max_iteration)
self.T_out[:int(self.max_iteration/2)] = 28
self.T_out[int(self.max_iteration/2):int(self.max_iteration)]= 32
def update_Tin(self, action):
self.Q_AC = action*self.Q_AC_Max #
self.T_in = self.T_in - 0.001*(self.timestep / self.mC) * (self.K*(self.T_in-self.T_out[self.iteration])+self.Q_AC)
self.iteration +=1
class GymACRoom(gym.Env):
metadata = {'render.modes' : ['human']}
def __init__(self, mC=300, K=20, Q_AC_Max = 1000, simulation_time = 12*60*60, control_step = 300):
super(GymACRoom, self).__init__()
self.AC_sim = Room(mC=300, K=20, Q_AC_Max = 1000, simulation_time = 12*60*60, control_step = 300)
self.time_step = control_step
self.Q_AC_Max = Q_AC_Max
self.action_space = spaces.Box(low = -1, high = 1, shape=(1,))
self.observation_space = spaces.Box(low = -100, high = 100, shape =(1,))
self.observation = np.empty(1)
def reset(self):
self.AC_sim.reset(T_in = np.random.randint(20, 30))
self.iter = 0
self.observation[0] = self.AC_sim.T_in - self.AC_sim.T_set
self.observation = self.observation
return self.observation
def step(self, action):
self.AC_sim.update_Tin(action=action)
self.observation[0] = self.AC_sim.T_in - self.AC_sim.T_set
self.iter += 1
if self.iter >= self.AC_sim.max_iteration:
done = True
else:
done = False
self.reward = np.exp(-(abs(10*self.observation)))[0]
info = {}
self.observation = self.observation
return self.observation, self.reward, done, info
def render(self, mode='human'):
pass
def close (self):
pass 观察第 68 行中的奖励函数:
self.reward = np.exp(-(abs(10*self.observation))))[0]
它基于代理设置温度与目标温度的偏差。
3.4 使用稳定基线训练代理
让我们使用稳定基线来训练代理并绘制代理的操作配置文件。
from stable_baselines3 import DQN, A2C, PPO, DDPG
env = GymACRoom()
model = A2C(policy = 'MlpPolicy', env=env, verbose=0, learning_rate=0.001)
model.learn(total_timesteps = 10000)
done = False
env = GymACRoom()
obs = env.reset()
c = 0
action_profile = []
reward_profile = []
temperatue_set = []
temperature_achieved =[]
while not done:
act = model.predict(obs)
obs_, reward, done, info = env.step(act[0])
obs = obs_
action_profile.append(act[0][0])
reward_profile.append(env.observation[0])
temperature_achieved.append(env.AC_sim.T_in[0] )
temperatue_set.append(env.AC_sim.T_set )3.5、没有奖励调整的代理绩效
药剂可以将温度保持在设定温度附近。所以代理成功了。
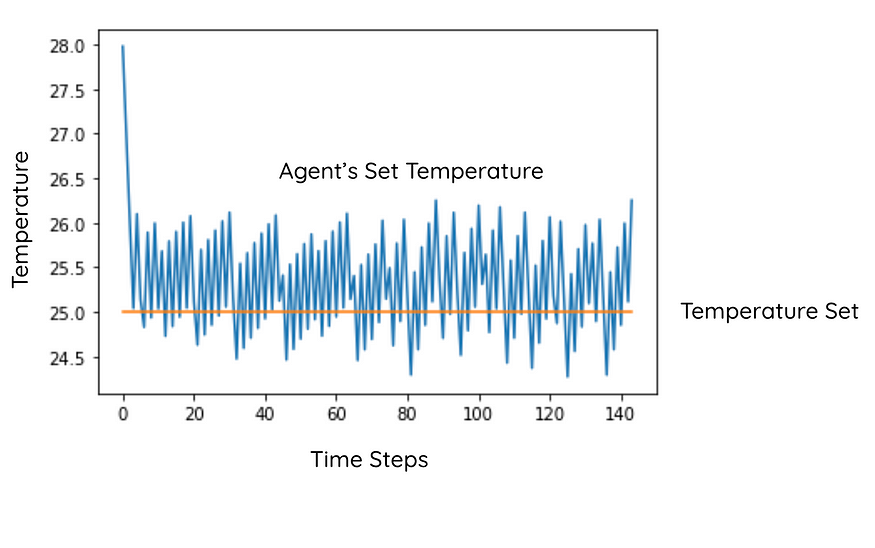
3.6 没有奖励调整的代理行为
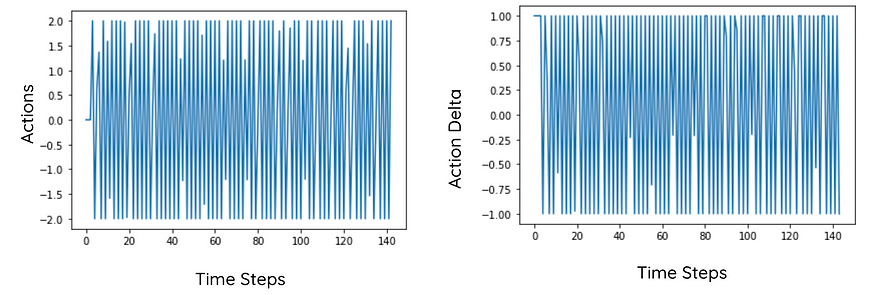
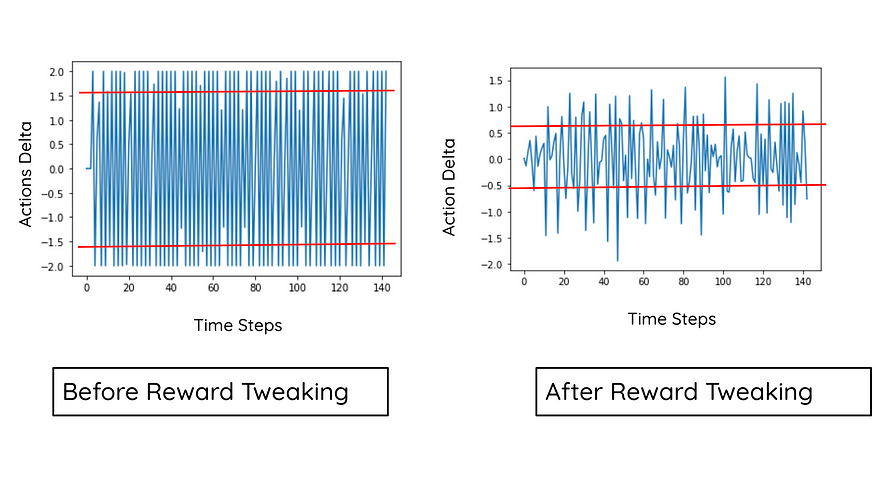
查看操作,代理正在从 +1 操作跳到 -1 操作。这使得代理不惜一切代价都无法使用。
现在让我们介绍奖励调整并重新审视代理的表现
3.7 将交易添加到奖励
我从设计的奖励中减去交易成本(delta:action-last_action)。奖励函数中的此增量组件会惩罚代理采取不稳定的操作。
def step(self, action):
delta = np.abs(action[0] -self.last_action)
self.AC_sim.update_Tin(action=action)
self.observation[0] = self.AC_sim.T_in - self.AC_sim.T_set
self.iter += 1
if self.iter >= self.AC_sim.max_iteration:
done = True
else:
done = False
self.reward = np.exp(-(abs(10*self.observation)))[0] - delta*0.1
info = {}
self.observation = self.observation
self.last_action = action[0]
return self.observation, self.reward, done, info3.8 代理的表现与奖励调整
该药剂再次成功地保持了温度,但不如以前那么好。但是现在的动作配置文件更流畅了。操作增量现在主要包含。
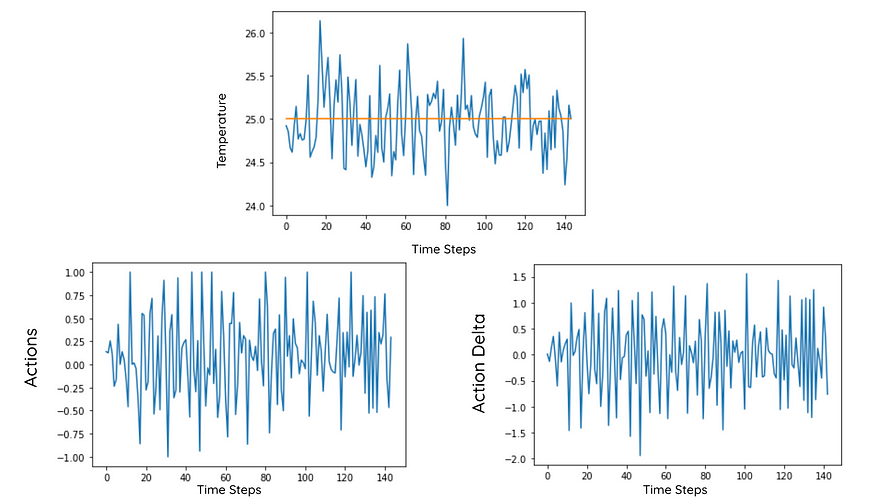
3.9 代理的操作配置文件比较
您可以清楚地观察到,基于交易的奖励调整增加了操作配置文件的流畅性。
四、结论
我们学习了如何平滑 RL 代理的操作。我希望这篇博客将有助于弥合强化学习范围内部署和研究之间的差距。
参考资料:
Kowshik chilamkurthy
数据驱动投资者











![ERROR:No tf data. Actual error: Fixed Frame [map] does not exist 解决办法](https://img-blog.csdnimg.cn/aaa0a4f39c94412bb30b46acd1e6e959.png)