之前有面试官问到了parquet的数据格式,下面对这种格式做一个详细的解读。
参考链接 :
列存储格式Parquet浅析 - 简书
Parquet 文件结构与优势_parquet文件_KK架构的博客-CSDN博客
Parquet文件格式解析_parquet.block.size_david'fantasy的博客-CSDN博客
Parquet文件组织格式
行组(Row Group)
按照行将数据物理上划分为多个单元,每一个行组包含一定的行数。一个行组包含这个行组对应的区间内的所有列的列块。
官方建议:
更大的行组意味着更大的列块,使得能够做更大的序列IO。我们建议设置更大的行组(512MB-1GB)。因为一次可能需要读取整个行组,所以我们想让一个行组刚好在一个HDFS块中。因此,HDFS块的大小也需要被设得更大。一个最优的读设置是:1GB的行组,1GB的HDFS块,1个HDFS块放一个HDFS文件。
列块(Column Chunk)
在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。不同的列块可能使用不同的算法进行压缩。一个列块由多个页组成。
页(Page)
每一个列块划分为多个页,页是压缩和编码的单元,对数据模型来说页是透明的。在同一个列块的不同页可能使用不同的编码方式。官方建议一个页为8KB。
==========================================================
Parquet 文件组织格式图示详解
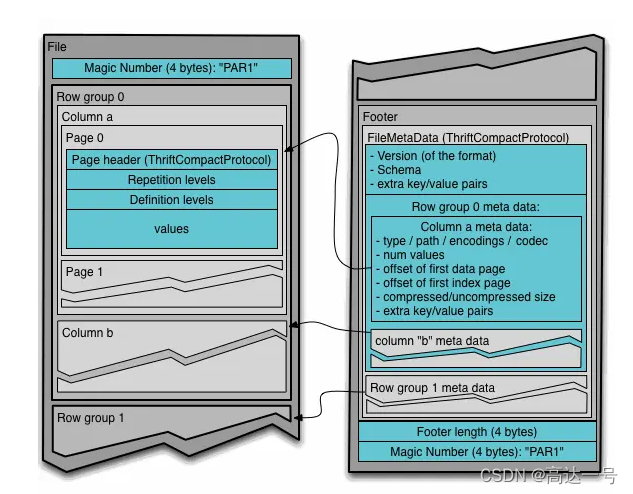
图片1
图片2
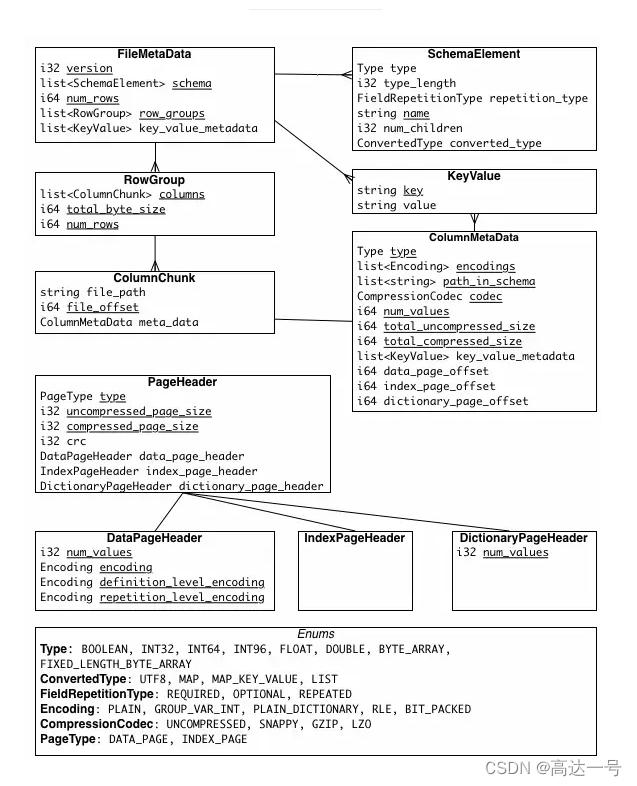
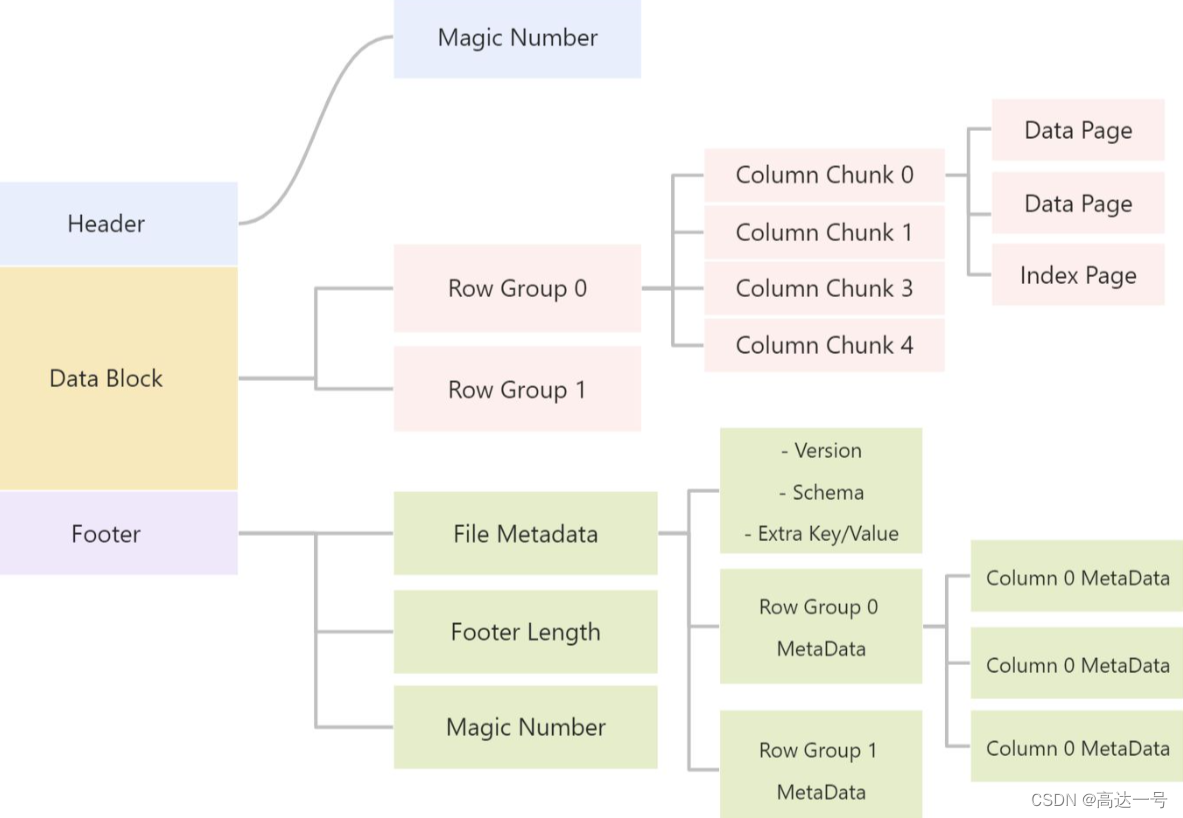
通过上面的图片1,我们知道parquet 主要由Header, Data Block, Footer 三个部分构成
Header
每个 Parquet 的首尾各有一个大小为 4 bytes ,内容为 PAR1 的 Magic Number,用来标识这个文件是 Parquet 文件。
Data Block
中间的 Data Block 是具体存放数据的区域,由多个行组(Row Group)组成。
行组 (Row Group),是按照行将数据在物理上分成多个单元,每一个行组包含一定的行数。
比如一个文件有10000条数据,被划分成两个 Row Group,那么每个 Row Group 有 5000 行数据。
在每个行组(Row Group)中,数据按列连续的存储在这个行组文件中,每列的所有数据组合成一个 Column Chunk(列块),一个列块拥有相同的数据类型,不同的列块可以有不同的压缩格式。
在每个列块(Column Chunk)中,数据按 Page 为最小单元来存储,Page 按内容分为 Data page 和 Index Page。(目前Parquet中还不支持索引页,但是在后面的版本中增加。)
这样逐层设计的目的在于:
多个 Row Group 可以实现数据的并行;
不同的 Column Chunk 用来实现列存储;
进一步分割成 Page,可以实现更细粒度的访问;
Footer
Footer部分由 File Metadata、**Footer Length **和 **Magic Number **三部分组成。
Footer Length 是一个 4 字节的数据,用于标识 Footer 部分的大小,帮助找到 Footer 的起始指针位置。
Magic Number同样是PAR1。
File Metada包含了非常重要的信息,包括Schema和每个 Row Group 的 Metadata。
每个 Row Group 的 Metadata 又由各个 Column 的 Metadata 组成,每个 Column Metadata 包含了其Encoding、Offset、Statistic 信息等等。
Parquet 文件的优势
(1) 映射下推(Project PushDown)/ 列裁剪(offset of first data page -> 列的起始结束位置)
说到列式存储的优势,映射下推是最突出的,它意味着在获取表中原始数据时只需要扫描查询中需要的列,由于每一列的所有值都是连续存储的,所以分区取出每一列的所有值就可以实现TableScan算子,而避免扫描整个表文件内容。
在Parquet中原生就支持映射下推,执行查询的时候可以通过Configuration传递需要读取的列的信息,这些列必须是Schema的子集,映射每次会扫描一个Row Group的数据,然后一次性得将该Row Group里所有需要的列的Cloumn Chunk都读取到内存中,每次读取一个Row Group的数据能够大大降低随机读的次数,除此之外,Parquet在读取的时候会考虑列是否连续,如果某些需要的列是存储位置是连续的,那么一次读操作就可以把多个列的数据读取到内存。
Parquet 列式存储方式可以方便地在读取数据到内存之间找到真正需要的列,具体是:
并行的 task 对应一个Parquet的行组(row group),每一个task内部有多个列块,列快连续存储,同一列的数据存储在一起,任务中先去访问 footer 的 File metadata,其中包括每个行组的 metadata,里面的 Column Metadata 记录 offset of first data page 和 offset of first index page,这个记录了每个不同列的起始位置,这样就找到了需要的列的开始和结束位置。
其中 data 和 index 是对数值和字符串数据的处理方式,对于字符变量会存储为key/value对的字典转化为数值
(2)谓词下推(Column Statistic -> 列的range和枚举值信息)
谓词下推的基本思想:
尽可能用过滤表达式提前过滤数据,以使真正执行时能直接跳过无关的数据。
比如这个 SQL:
select item.name, order.* from order , item where order.item_id = item.id and item.category = 'book';
使用谓词下推,会将表达式 item.category = ‘book’ 下推到 join 条件 order.item_id = item.id 之前。
再往高大上的方面说,就是将过滤表达式下推到存储层直接过滤数据,减少传输到计算层的数据量。
Parquet 中 File metadata 记录了每一个 Row group 的 Column statistic,包括数值列的 max/min,字符串列的枚举值信息,比如如果 SQL 语句中对一个数字列过滤 >21 以上的,因此 File 0 的行组 1 和 File 1 的行组 0 不需要读取
另外Parquet未来还会增加诸如Bloom Filter和Index等优化数据,更加有效的完成谓词下推。
(3)压缩效率高,占用空间少,存储成本低
Parquet 这类列式存储有着更高的压缩比,相同类型的数据为一列存储在一起方便压缩,不同列可以采用不同的压缩方式,结合Parquet 的嵌套数据类型,可以通过高效的编码和压缩方式降低存储空间提高 IO 效率
===============
HDFS 上的Parquet 性能调优
如果采用HDFS文件系统,影响Parquet文件读写性能的参数主要有两个,dfs.blocksize和parquet.block.size
- dfs.blocksize
控制HDFS file中每个block的大小,该参数主要影响计算任务的并行度,例如在spark中,一个map操作的默认分区数=(输入文件的大小/dfs.block.size)*输入的文件数(分区数等于该操作产生的任务数),如果dfs.block.size设置过大或过小,都会导致
生成的Task数量不合理,因此应根据实际计算所涉及的输入文件大小以及executor数量决定何时的值。
- parquet.block.size
控制parquet的Row Group大小,一般情况下较大的值可以组织更大的连续存储的Column Chunk,有利于提升I/O性能,但上面也提到Row group是数据读写时候的缓存单元,每个需要读写的parquet文件都需要在内存中占据Row Group size设置的内存空间(读取的情况,由于可能跳过部分列,占据的内存会小于Row Group size),这样更大的Row Group size意味着更多的内存开销。同时设置该值时还需要考虑dfs.blocksize的值,尽量让Row Group size等同于HDFS一个block的大小,因为单个Row Group必须在一个计算任务中被处理,如果一个Row Group跨越了多个hdfs block可能会导致额外的远程数据读取。一般推荐的参数一个Row group大小1G,一个HDFS块大小1G,一个HDFS文件只含有一个块。
在Spark中可以使用如下方式修改默认配置参数:
val ONE_GB = 1024 * 1024 * 1024
sc.hadoopConfiguration.setInt("dfs.blocksize", ONE_GB)
sc.hadoopConfiguration.setInt("parquet.block.size", ONE_GB)Parquet 性能测试
压缩

上图是展示了使用不同格式存储TPC-H和TPC-DS数据集中两个表数据的文件大小对比,可以看出Parquet较之于其他的二进制文件存储格式能够更有效的利用存储空间,而新版本的Parquet(2.0版本)使用了更加高效的页存储方式,进一步的提升存储空间。
查询

上图展示了Twitter在Impala中使用不同格式文件执行TPC-DS基准测试的结果,测试结果可以看出Parquet较之于其他的行式存储格式有较明显的性能提升。
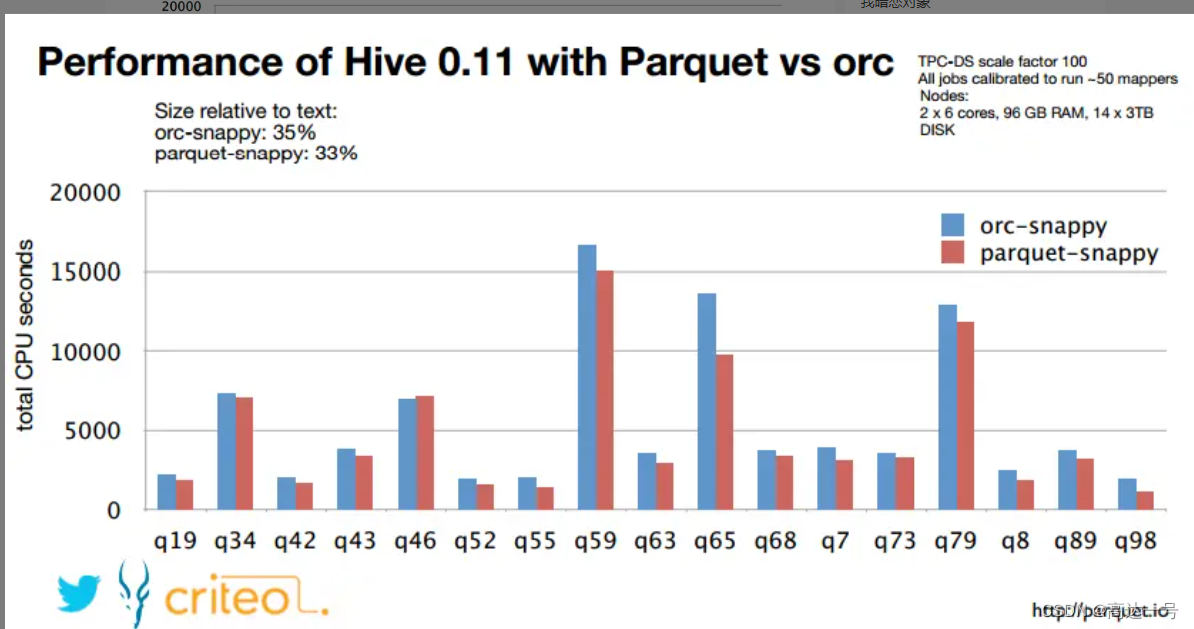
上图展示了criteo公司在Hive中使用ORC和Parquet两种列式存储格式执行TPC-DS基准测试的结果,测试结果可以看出在数据存储方面,两种存储格式在都是用snappy压缩的情况下量中存储格式占用的空间相差并不大,查询的结果显示Parquet格式稍好于ORC格式,两者在功能上也都有优缺点,Parquet原生支持嵌套式数据结构,而ORC对此支持的较差,这种复杂的Schema查询也相对较差;而Parquet不支持数据的修改和ACID,但是ORC对此提供支持,但是在OLAP环境下很少会对单条数据修改,更多的则是批量导入。