注1:本文系“简要介绍”系列之一,仅从概念上对跨模态学习和多模态学习进行非常简要的介绍,不适合用于深入和详细的了解。
解析模态之间的联系:跨模态学习与多模态学习的区别和联系
在人工智能的广泛领域中,跨模态学习(Cross-modal Learning)和多模态学习(Multi-modal Learning)是两个重要的研究领域,这两者都致力于理解和解析不同情境和环境下的数据。然而,这两个概念的含义、应用和挑战却有着显著的差异。本文旨在揭示这两个领域的核心概念、区别和联系。
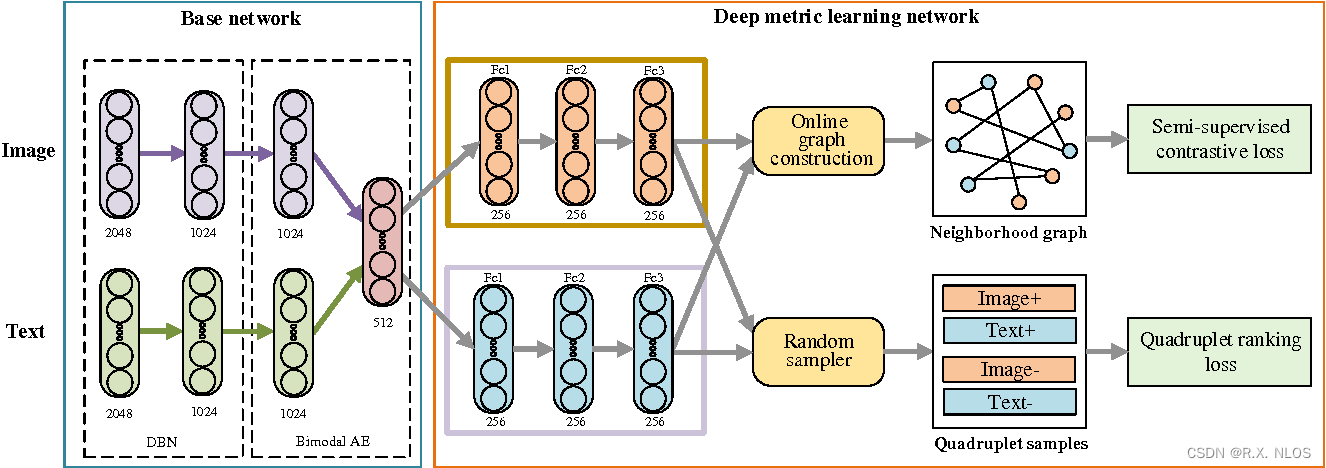
Cross-modal deep metric learning with multi-task regularization | Semantic Scholar
背景介绍
跨模态学习
跨模态学习是一种学习策略,主要关注如何通过一个模态的信息来理解另一个模态的信息。例如,你可能通过阅读一段文字(一种模态)来理解一幅图片(另一种模态)的内容。
多模态学习
相比之下,多模态学习则更关注如何同时处理和理解来自多种模态的信息,并从中提取有用的知识。例如,自动驾驶系统可能需要同时处理来自摄像头、雷达和GPS等多种模态的信息。
原理介绍和推导
跨模态学习的原理
跨模态学习的一个基本原理是进行特征映射,即找到一个映射函数,可以将一个模态的特征空间映射到另一个模态的特征空间。例如,我们可以通过训练神经网络模型,使其学会将文字描述映射为图片特征,或者反之亦然。
假设我们有两种模态的数据,分别是 X X X和 Y Y Y,我们的目标是找到一个映射函数 f f f,使得 f ( X ) f(X) f(X)尽可能接近 Y Y Y。这个问题可以通过最小化以下损失函数 L L L来求解:
L = ∣ ∣ f ( X ) − Y ∣ ∣ 2 2 L = ||f(X) - Y||_2^2 L=∣∣f(X)−Y∣∣22
多模态学习的原理
多模态学习的一个基本原理是进行信息融合,即将来自不同模态的信息融合在一起,以获得更全面的知识。这通常涉及到特征提取和特征融合两个步骤。
假设我们有 n n n种模态的数据,分别是 X 1 , X 2 , . . . , X n X_1, X_2, ..., X_n X1,X2,...,Xn,我们的目标是找到一个融合函数 f f f,使得 f ( X 1 , X 2 , . . . , X n ) f(X_1, X_2, ..., X_n) f(X1,X2,...,Xn)可以最好地表示这 n n n种模态的共享信息。这个问题可以通过最小化以下损失函数 L L L来求解:
L = ∣ ∣ f ( X 1 , X 2 , . . . , X n ) − Y ∣ ∣ 2 2 L = ||f(X_1, X_2, ..., X_n) - Y||_2^2 L=∣∣f(X1,X2,...,Xn)−Y∣∣22
其中 Y Y Y是我们希望学习的目标信息。
研究现状
跨模态学习的研究现状
在跨模态学习领域,最初的研究主要关注文字和图像之间的映射,例如通过文字描述来生成图像,或者通过图像来生成文字描述。然而,随着技术的进步,跨模态学习已经被应用到了许多其他领域,例如音频和视频之间的映射,3D模型和2D图片之间的映射等。
多模态学习的研究现状
多模态学习的研究则更为广泛,包括语音识别、图像识别、自然语言处理、医疗图像分析等领域。其中,一项重要的研究是如何有效地融合来自不同模态的信息。为了解决这个问题,研究者们提出了许多信息融合的方法,例如早期融合、晚期融合和层次融合等。

Multimodal Learning: Engaging Your Learner’s Senses
挑战
尽管跨模态学习和多模态学习在许多领域都取得了显著的成果,但它们仍然面临着许多挑战。例如,如何有效地处理模态间的数据不匹配问题,如何处理模态间的数据不完整问题,如何设计更有效的特征映射和信息融合算法等。
未来展望
虽然跨模态学习和多模态学习的研究仍然面临许多挑战,但随着深度学习和大数据技术的发展,我们有理由相信这两个领域的研究将取得更大的进展。未来,我们期待看到更多的创新算法和应用,以及更深入的理论研究。
代码示例
以下是一个使用Python和PyTorch进行跨模态学习的简单代码示例:
import torch
import torch.nn as nn
# 定义一个简单的线性模型作为映射函数
class MappingModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(MappingModel, self).__init__()
self.linear = nn.Linear(input_dim, output_dim)
def forward(self, x):
return self.linear(x)
# 假设我们有两种模态的数据
X = torch.randn(100, 10) # 模态1的数据
Y = torch.randn(100, 20) # 模态2的数据
# 创建映射模型
model = MappingModel(10, 20)
# 创建优化器和损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
criterion = nn.MSELoss()
# 训练映射模型
for epoch in range(100):
# 前向传播
Y_pred = model(X)
# 计算损失
loss = criterion(Y_pred, Y)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
```