目录
- 下载编译部署
- 官网地址
- 编译
- 部署
- 启动
- 简单使用
- 输出文件方式
- 可以正常执行的任务
- 自定义任务
- 获取小说名
- 总结
下载编译部署
官网地址
-
修改端口、数据库、存放地址、执行文件等配置(前后端不分离,配置文件端口即页面登录端口)
spider-flow-web/src/main/resources/application.properties

-
初始化数据库,执行
db/spiderflow.sql
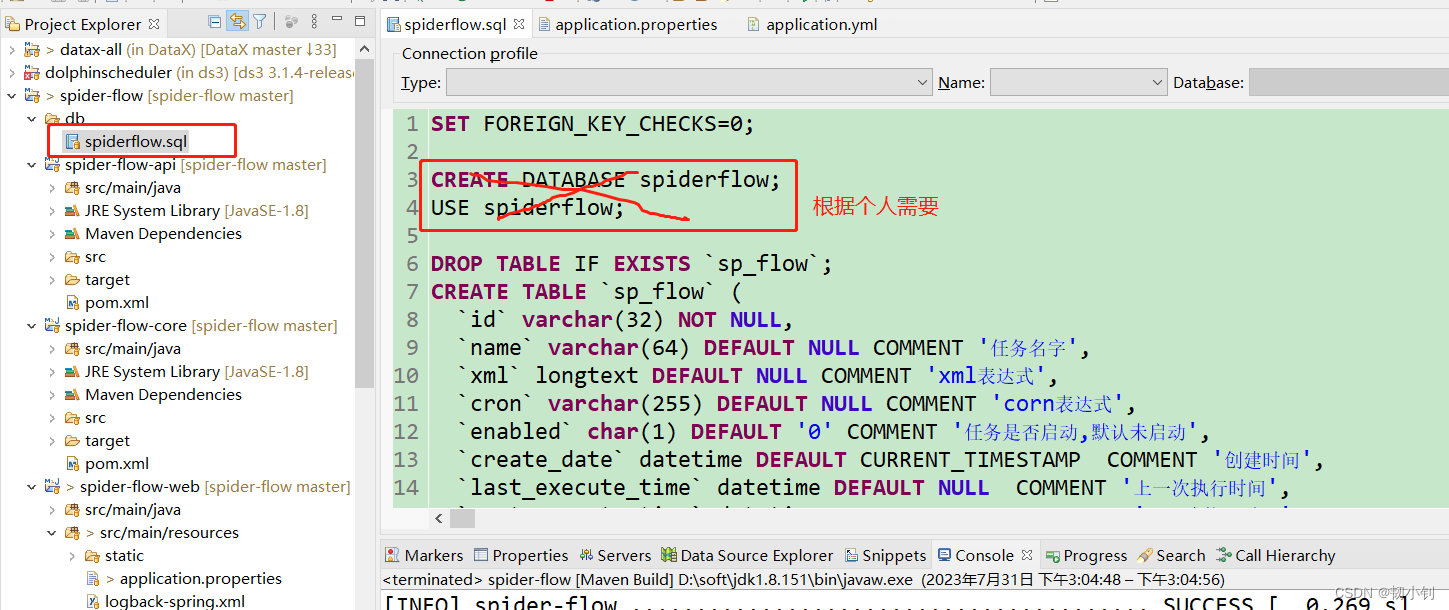
编译
-
mvn clean install


-
编译好的部署包位置
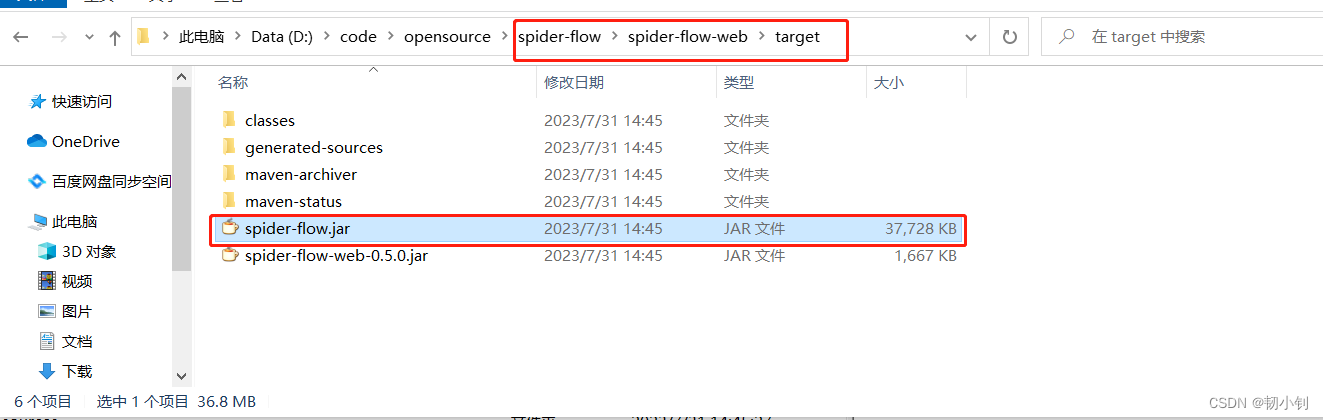
部署

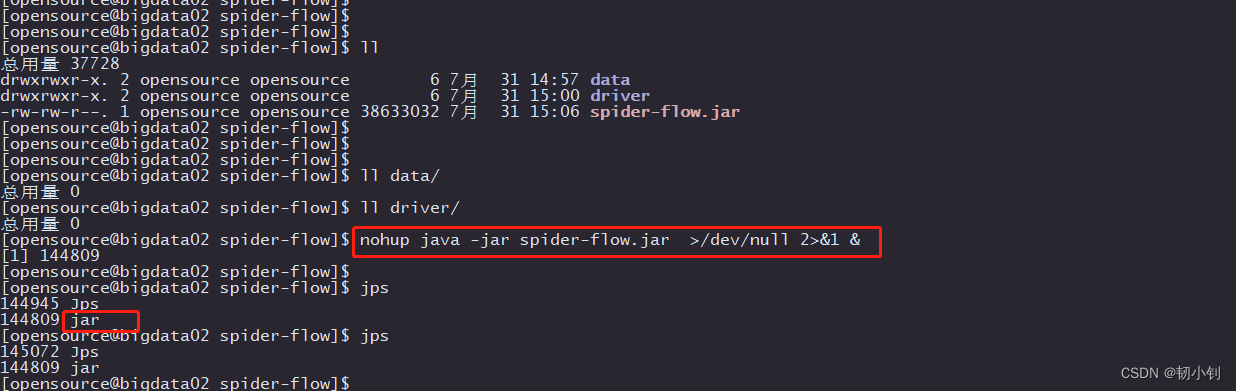
启动
nohup java -jar spider-flow.jar >/dev/null 2>&1 &
简单使用
输出文件方式
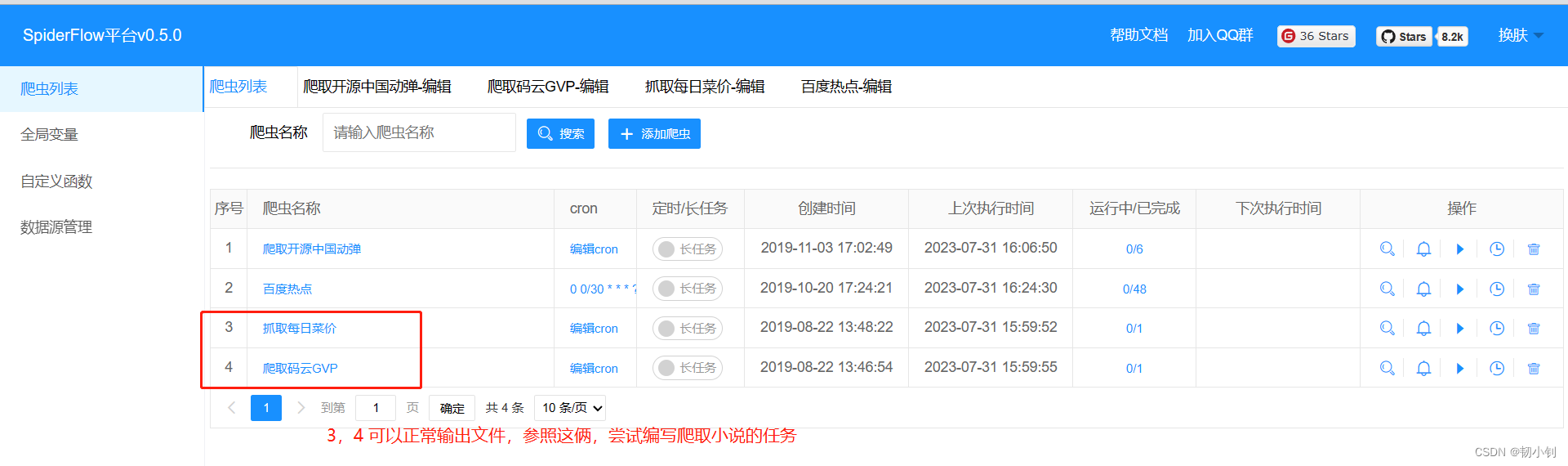
- 项目中自动初始化四个任务,任务输出可以输出到表(数据源管理)或者csv文件中(不指定文件后缀及路径,默认就是文本文件,位置就在项目部署更目录下)

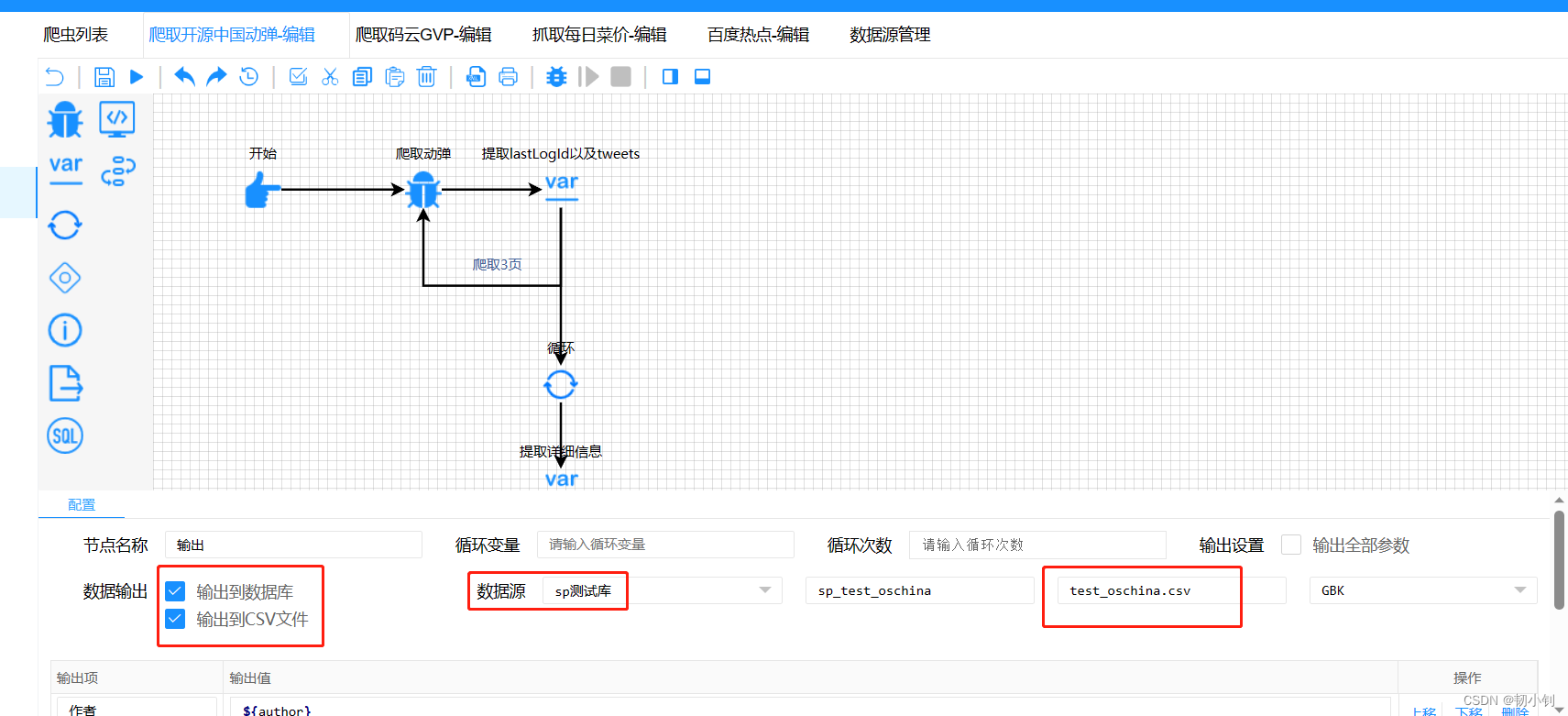
- 执行任务

- 查看日志
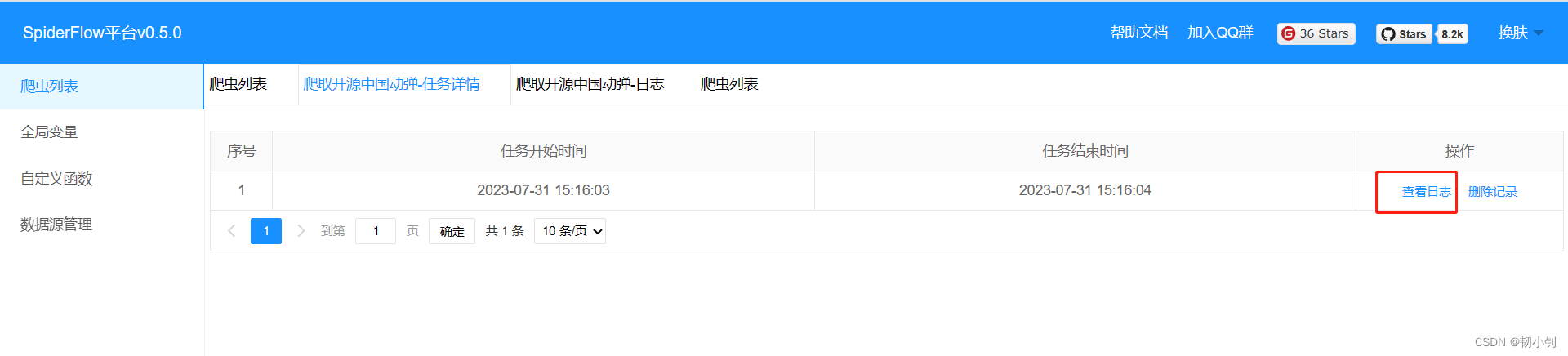
- 爬取到数据,日志中会打印出来(下图即未爬取到数据,也没有输出)

- 创建输出表,选择输出到表,依然没有输出
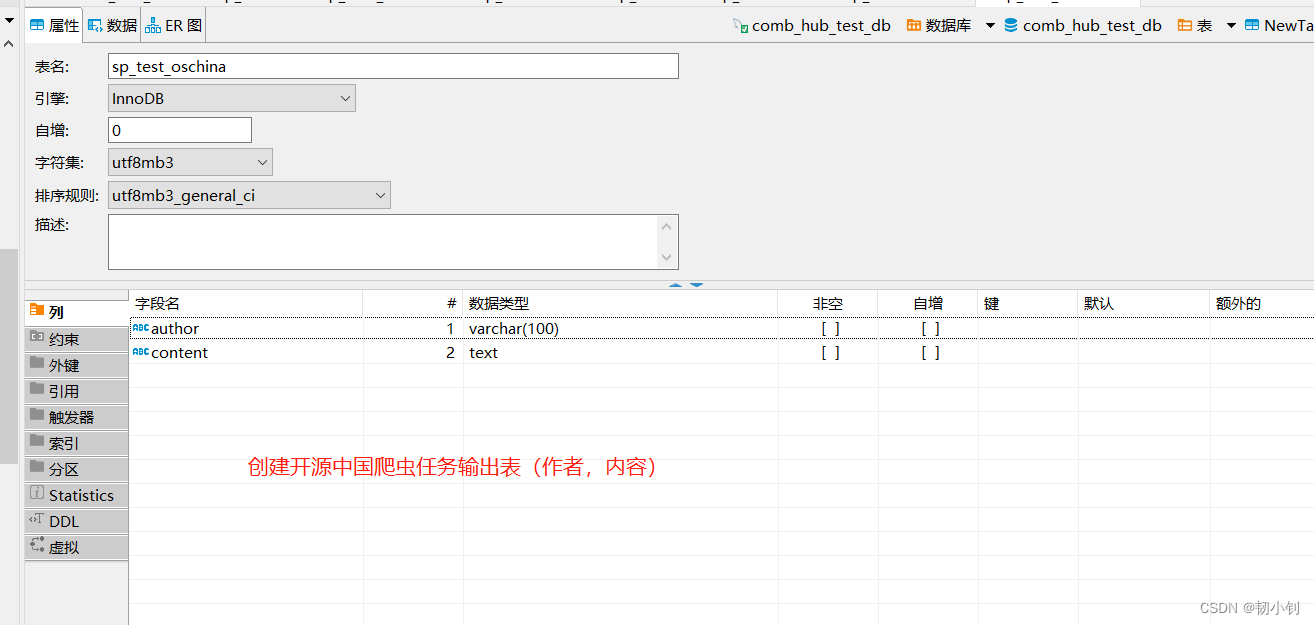
测试了半天看不到输出文件,难道是因为没下载驱动?
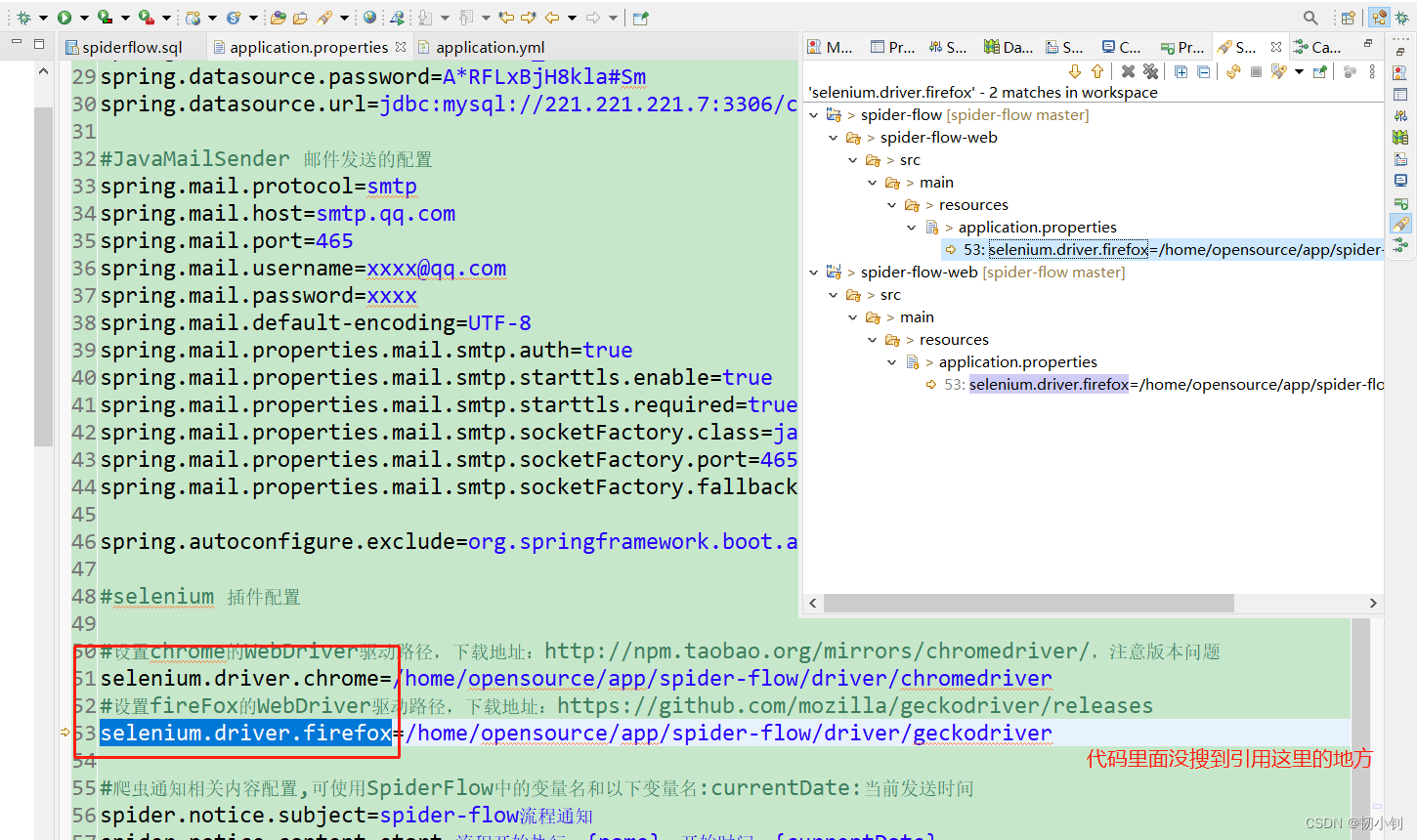
下载驱动丢到对应目录下,重启,再次尝试,依然没有输出文件

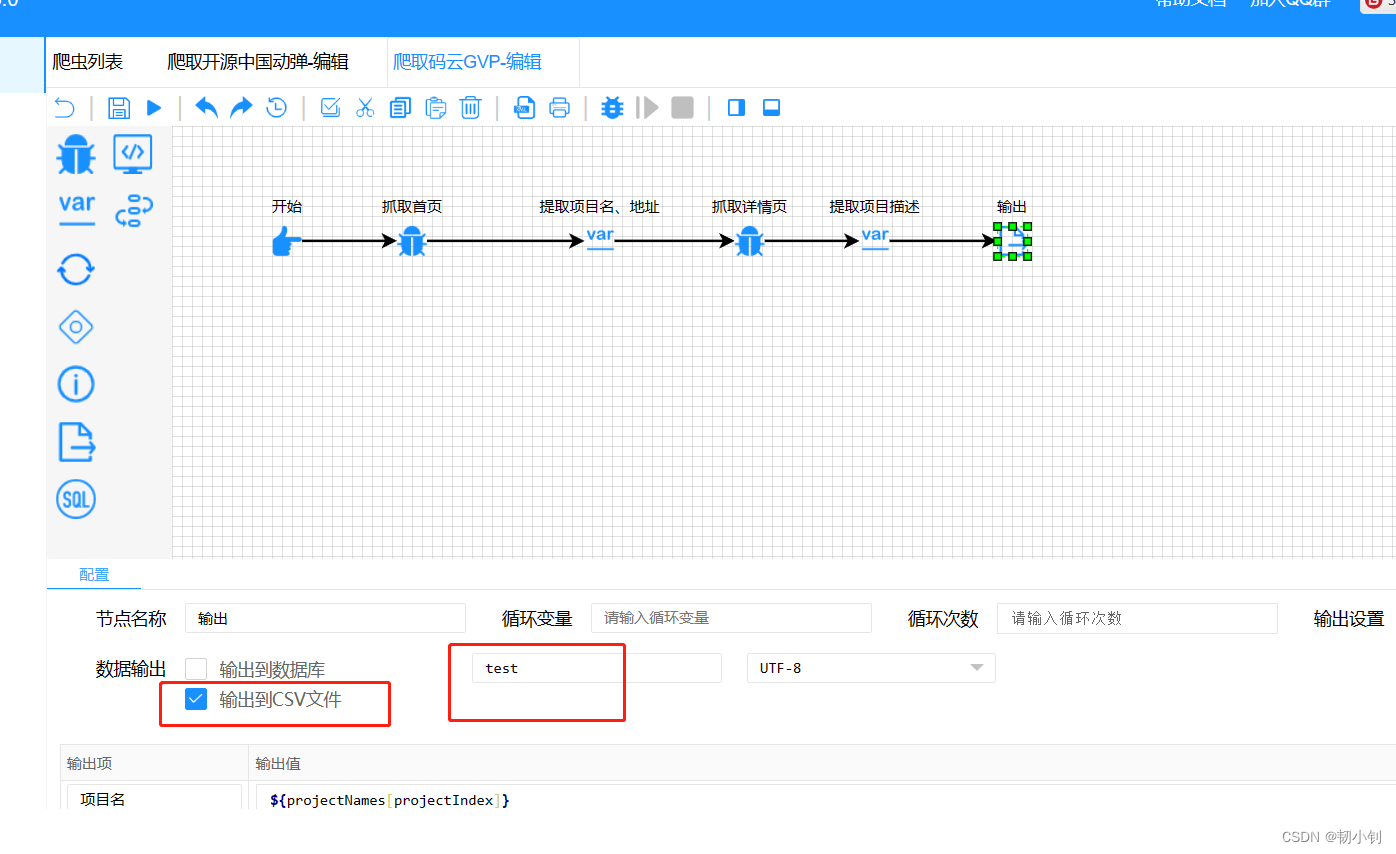
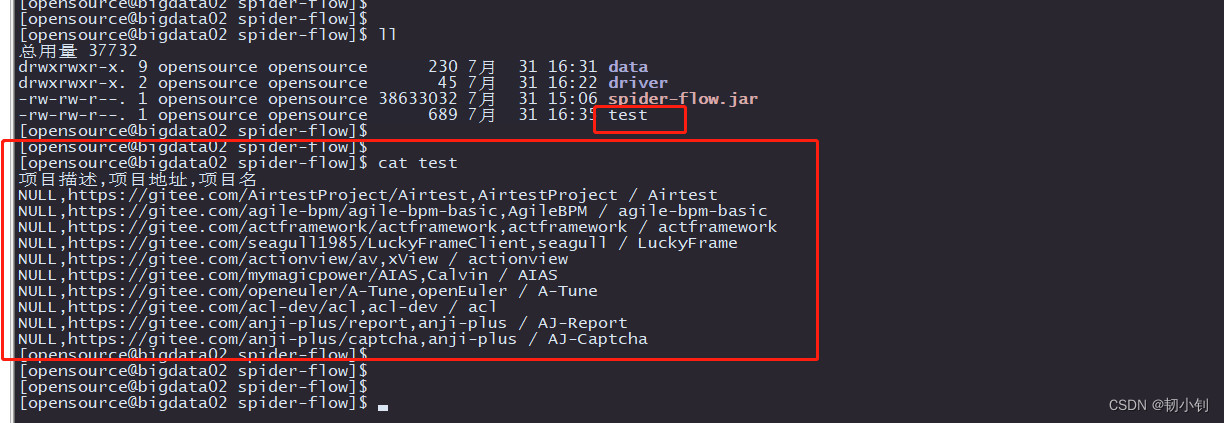
可以正常执行的任务
-
爬取码云GVP
-
每日菜价
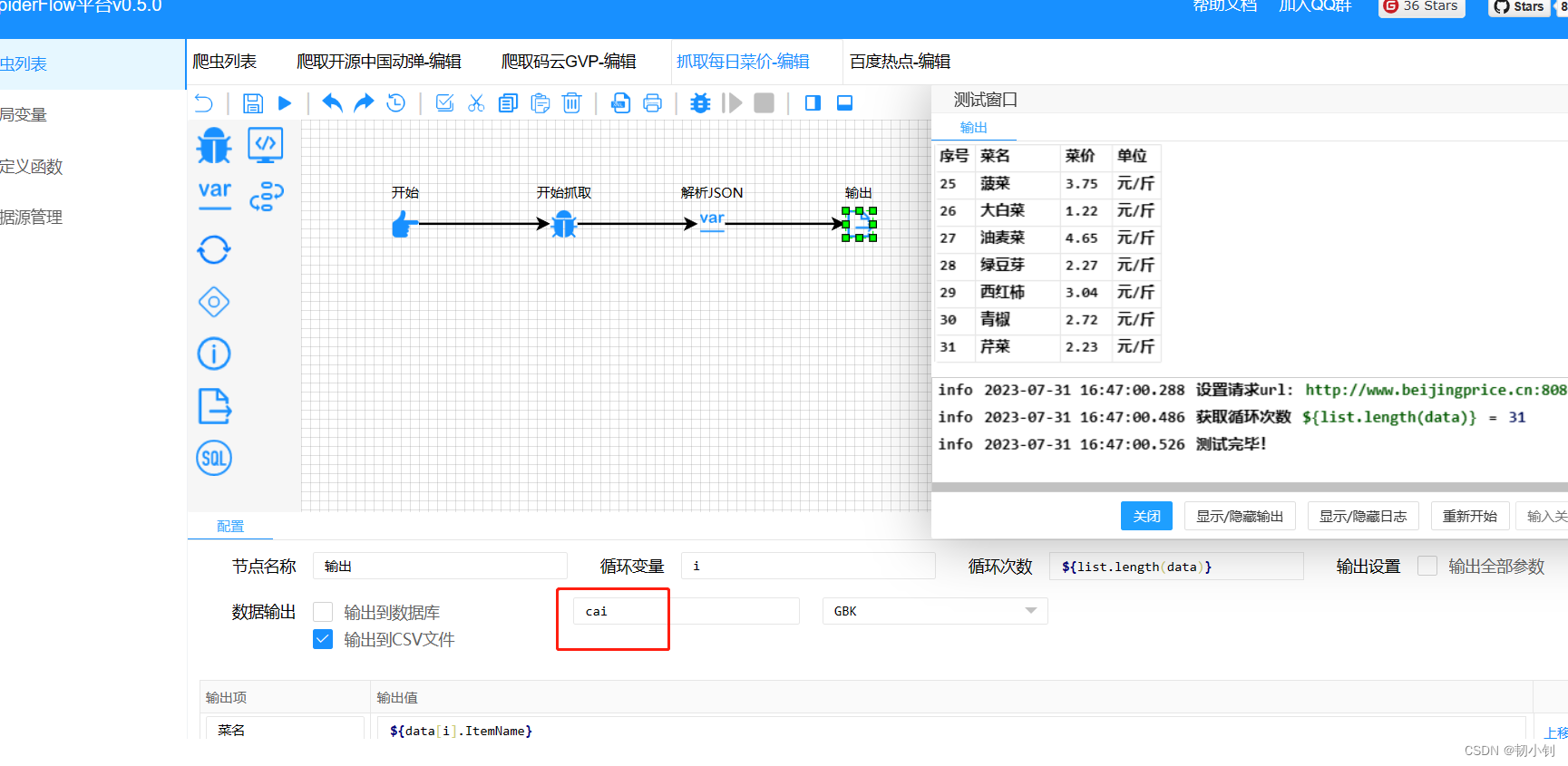
还乱码了,改成UTF-8也乱码

自定义任务
参照可以正常输出的任务,尝试自定义爬虫任务,放弃吧,一点也不简单,感觉毫无章法可言
获取小说名
- 获取该页面的小说名称

- 找到关键字
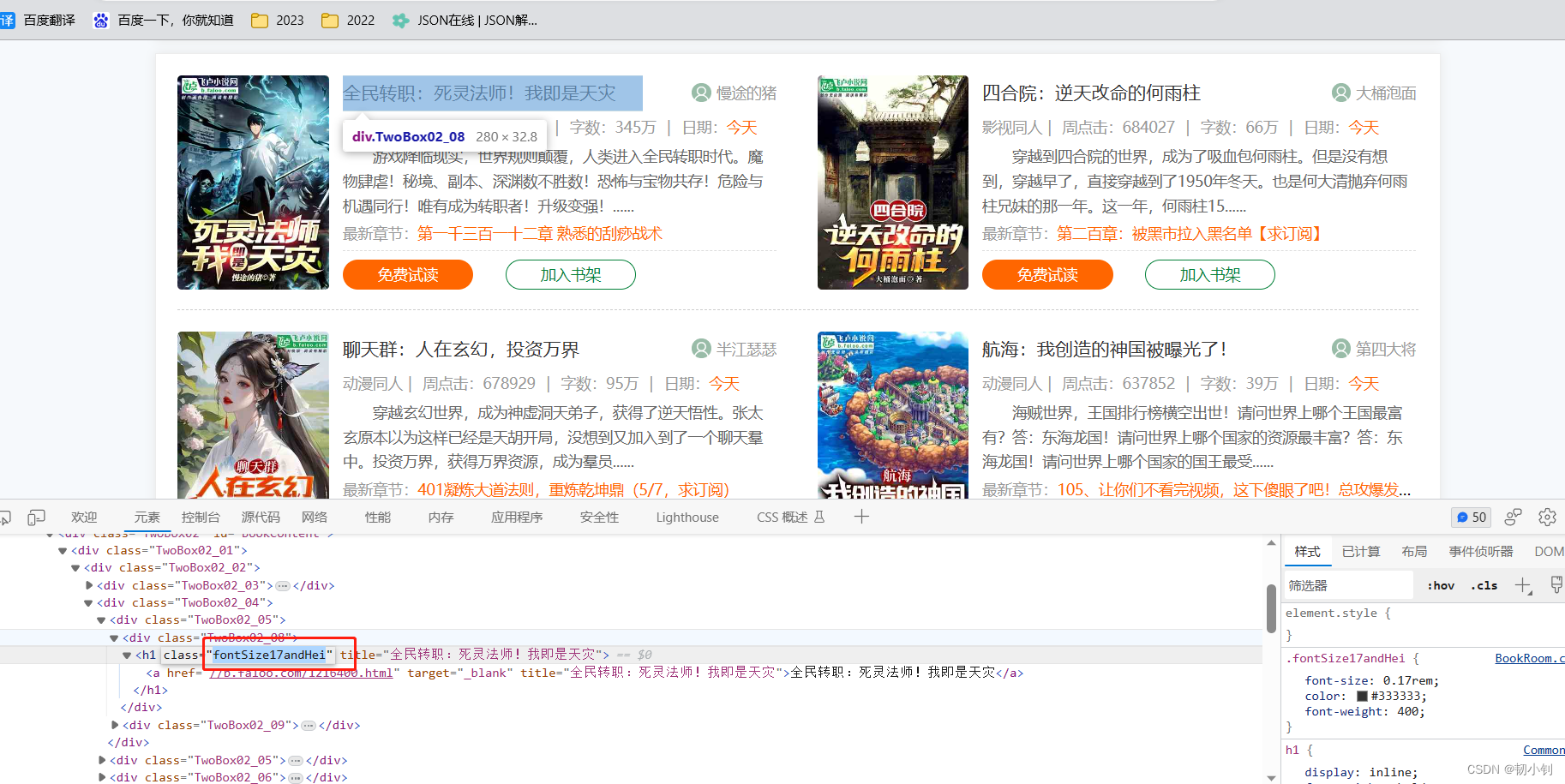
- 定义各节点

- 定义循环节点,不然是所有的小说名输出到一条记录中

- 遍历输出小说名
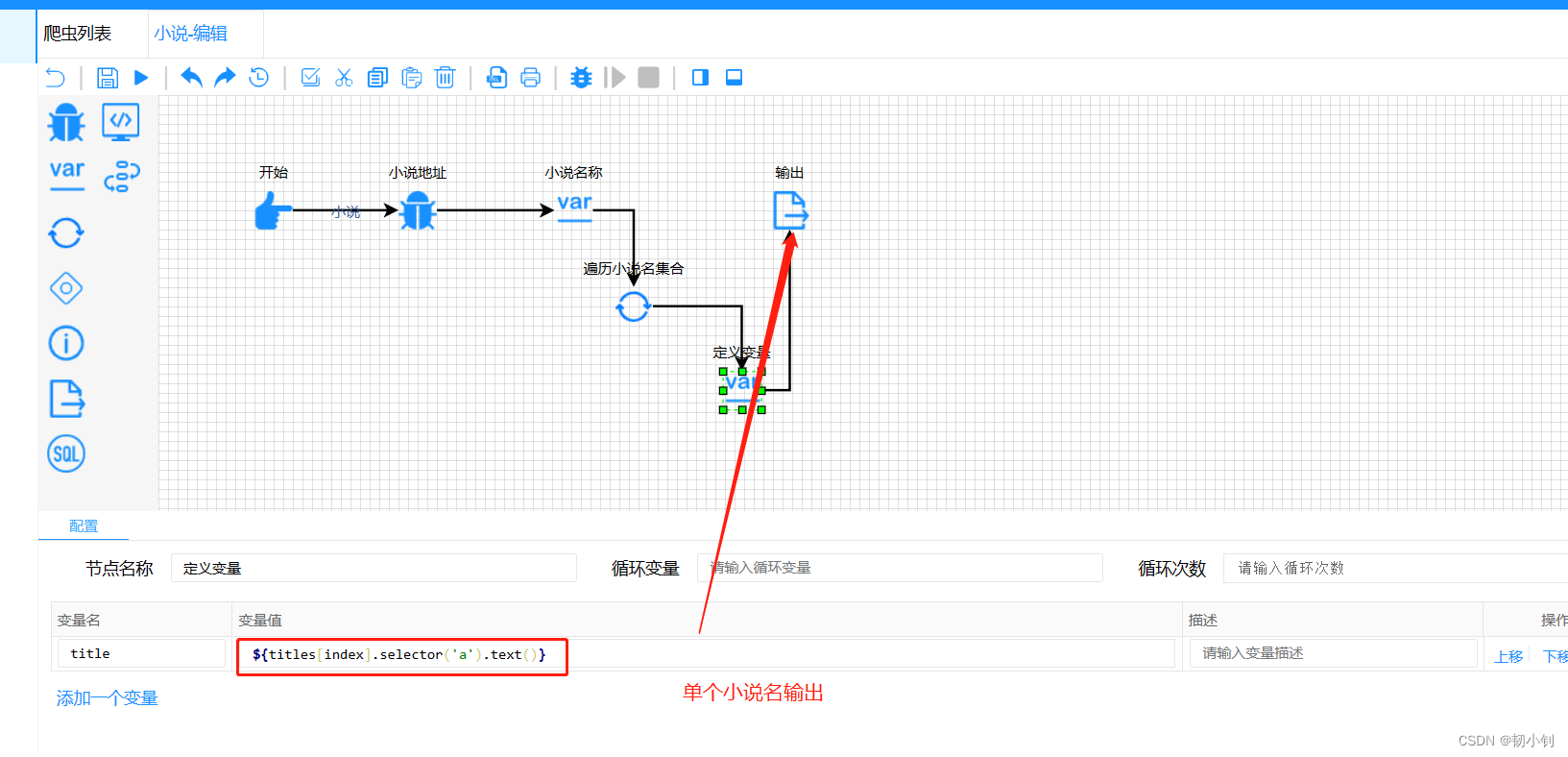
- 输出
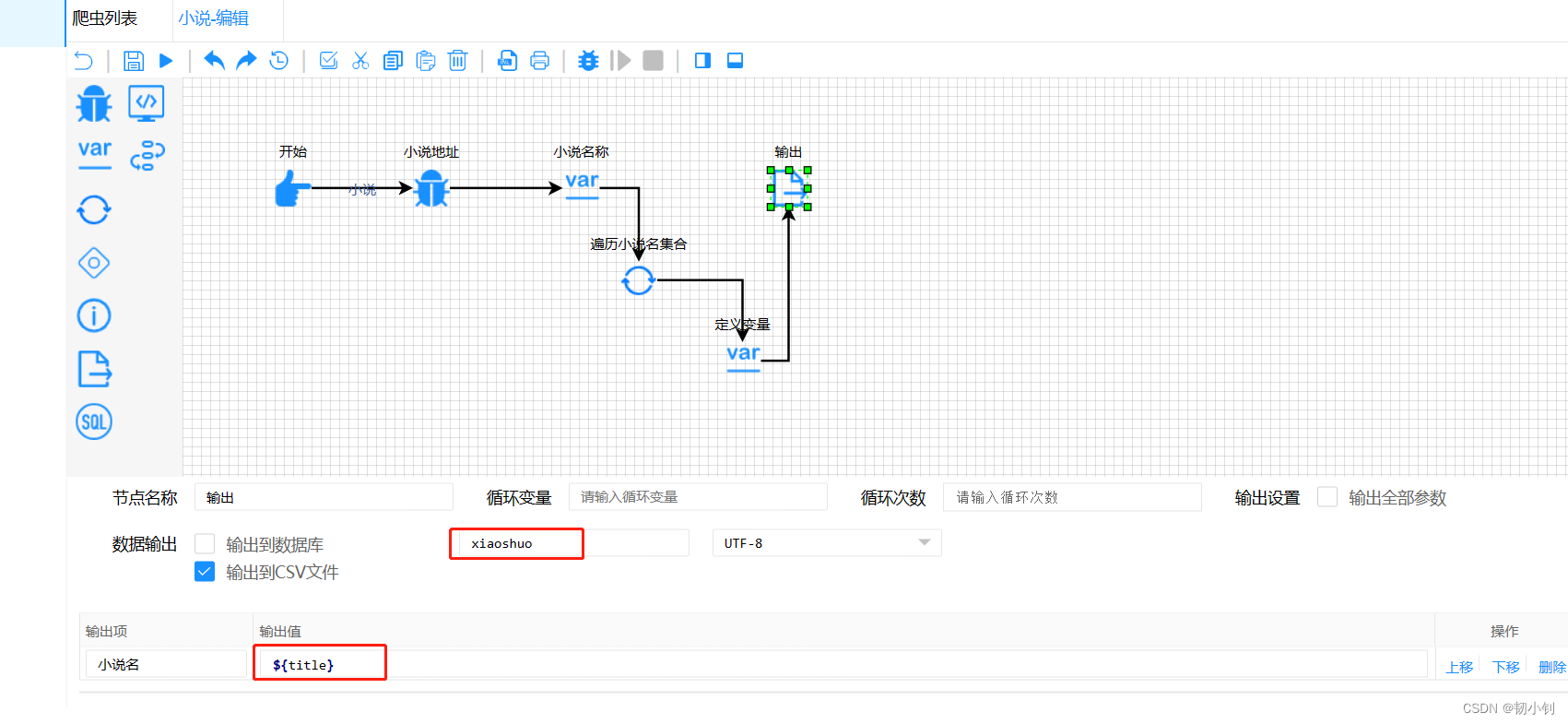
- 测试结果

- 测试输出文件

总结
可视化给人的感觉就是简单易操作,小白都可以轻易上手,在爬虫方面算是小白,但是作为一名程序员,这一套流程走下来,我觉得一点也不简单,更别说纯小白了,主要是没有帮助文档(网站已经禁用了),只能参照执行成功的任务在那一点一点调试,具体一些语法也不清楚,所以感觉还是有难度的,我也是好奇,看了别人分享的文章,感觉好像很简单,结果发现网上一堆一样的文章,全是从官网下载的,几个gif图片,没了,简直可耻,没有亲自实验过就乱发!!!
最后都放弃了,结果参照这篇博客超详细spiderflow实践教程,又试了一把,勉强跑成功了吧!以后应该不会碰了,毕竟这玩意不安全,一不小心端上铁饭碗了!