文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州
▲ 本章节目的
⚪ 了解YARN的概念和结构;
⚪ 掌握YARN的资源调度流程;
⚪ 了解Hadoop支持的资源调度器:FIFO、Capacity、Fair;
⚪ 掌握YARN的完全分布式结构和常见问题;
⚪ 掌握YARN的服役新节点操作;
一、简介
1. 概述
1. Another Resource Negotiator - 迄今另一个资源调度器) - 负责任务管理和资源调度。
2. YARN是Hadoop2.X开始出现的,也是Hadoop2.X中最重要的特性之一。也正是因为YARN的出现,导致Hadoop1.X和Hadoop2.X不兼容。
3. 产生原因:
a. 内部原因:
Ⅰ. 在Hadoop1.X中,没有YARN的说法,此时MapReduce分为主进程JobTracker和从进程TaskTracker。JobTracker只允许存在1个,容易出现单点故障。
Ⅱ. JobTracker负责对外接收任务,接收到任务之后需要将任务拆分成子任务(MapTask和ReduceTask)。JobTracker拆分完任务之后,将子任务分配给从进程TaskTracker。JobTracker会监控每一个TaskTracker的执行情况。在官方文档中,每一个JobTracker最多能够管理4000个TaskTracker。如果TaskTracker数量过多,导致JobTracker的效率成别下降,甚至于导致JobTracker的崩溃。
b. 外部原因:
Ⅰ. Hadoop产生的时候,市面上并没有太多的大数据框架,因此Hadoop在刚开始涉及的时候,只考虑MapReduce的资源调度问题。
Ⅱ. 后来随着大数据的发展,产生了越来越多的计算框架,很大一部分的框架都是围绕着Hadoop使用,因为Hadoop没有考虑其他框架的资源调度问题,所以这些计算框架就产生了资源调度冲突。
4. YARN的结构:
a. 主进程ResourceManager:
Ⅰ. 负责对外接收请求
Ⅱ. 负责管理NodeManager
Ⅲ. 负责管理ApplicationMaster
b. 从进程NodeManager:
Ⅰ. 执行任务。
Ⅱ. 负责管理本节点上的资源。
c. 辅助进程ApplicationMaster:负责管理具体的子任务。
2. 流程
1. 当ResourceManager收到客户端提交的任务之后,会先将这个任务临时存储下来,等待NodeManager的心跳。
2. 当ResourceManager收到NodeManager的心跳之后,会在心跳响应中将Job任务返回给NodeManager。
3. NodeManager通过心跳响应之后,收到任务之后,就会在本节点内部开启一个ApplicationMaster进程,然后将Job任务交给这个ApplicationMaster处理。
4. ApplicationMaster收到任务之后,会将Job任务来进行拆分,拆分成子任务。例如,如果是一个MapReduce程序,那么拆分成MapTask和ReduceTask。
5. 拆分完成之后,ApplicationMaster会给ResourceManager发送请求申请资源。
6. ResourceManager收到请求之后,将请求交给内部组件ResourceScheduler处理。
7. ResourceScheduler收到请求之后,会将资源的描述封装成一个Container对象返回给ApplicationMaster。
8. ApplicationMaster收到资源之后,会对资源进行二次拆分,分配给具体的子任务,然后将子任务分配到不同的NodeManager上执行,并且ApplicationMaster还会监控这些子任务的执行。
9. 如果子任务执行失败,那么ApplicationMaster监控到之后,会自动的重启这个失败的子任务,或者会自动的将失败的子任务分配到其他的节点上重新执行。
10. 当Job任务结束之后,ApplicationMaster会ResourceManager发送请求,同时请求注销自己。

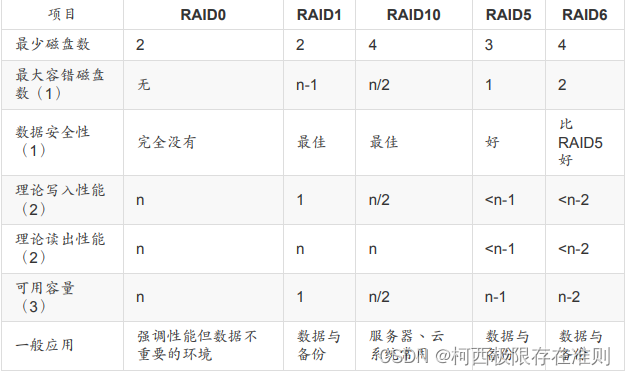
3. ResourceScheduler - 资源调度器
1. 在Hadoop中,目前为止,支持3种资源调度器:FIFO(先进先出),Capacity(资源容量)以及Fair(公平)。
2. FIFO(先进先出):
a. 在Hadoop2.X中,默认使用是这个资源调度器,但是Hadoop3.X发生变化。
b. 底层会为维系唯一的队列,任务会先进入队列,然后从队列头获取任务,为这个任务分配资源。如果资源不充足的情况下,后入队的任务就会被阻塞。
3. Capacity(资源容量):
a. 在Hadoop3.X中,默认使用的是这个资源调度器。
b. 这个资源调度器中,可以维系多个队列,每一个队列维系FIFO的规则。默认情况下,这个调度器中只有1个队列default。
c. 如果资源调度器中维系了多个队列,那么可以为每一个队列设置资源分配比。在提交任务的时候,可以将任务提交到不同的队列中。
4. Fair(公平资源):
a. 在这个资源调取其中,也可以维系多个队列。
b. 这个队列中可以保证每一个在时间上是相对公平中 - 即任务在队列中是进行轮询的。
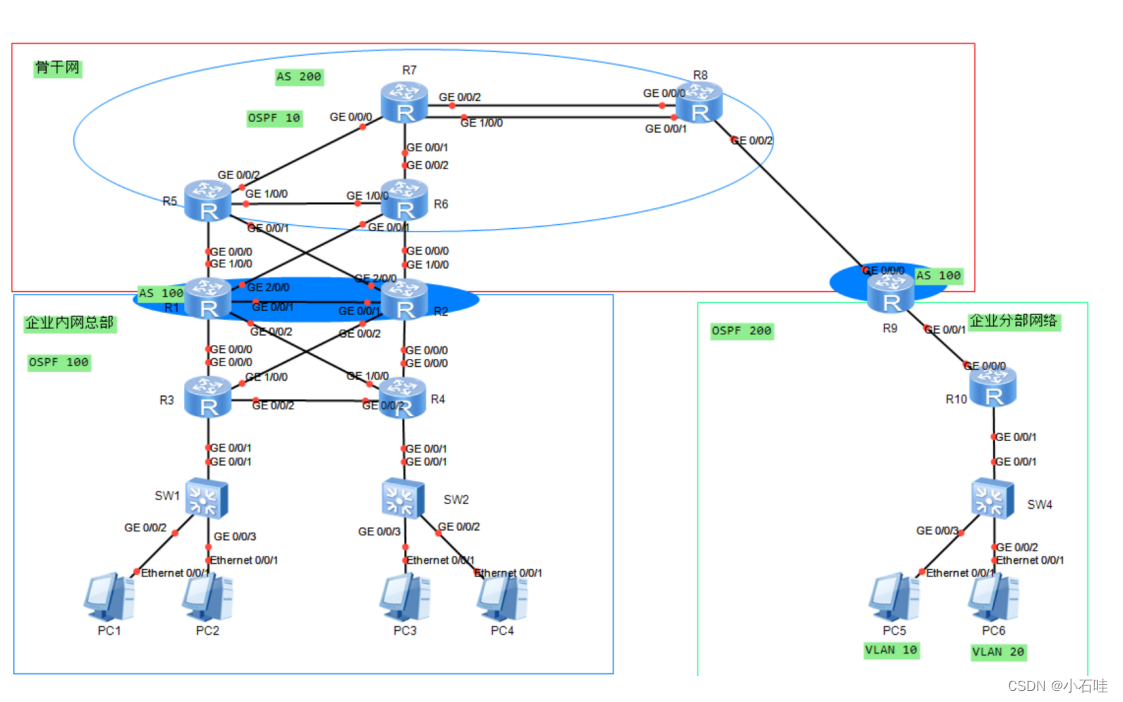
二、完全分布式结构
1. 结构
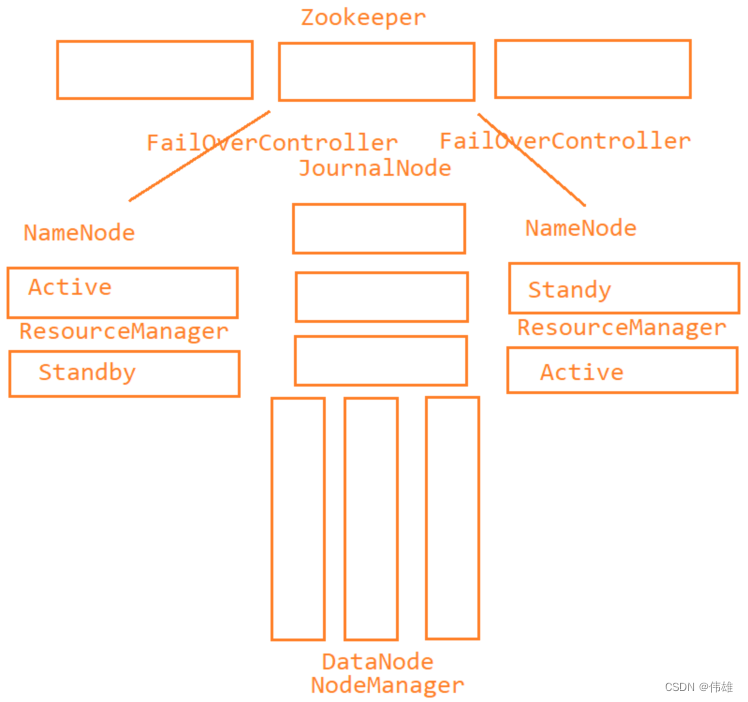
2. 常见问题
1. 在第一次关闭Hadoop之前,先修改stop-dfs.sh和stop-yarn.sh中的内容。将start-dfs.sh中添加的内容放到stop-dfs.sh中,将start-yarn.sh中的内容放到stop-yarn.sh中。
2. 在Hadoop集群中,一定要先启动Zookeeper再启动Hadoop。
3. 以后再次启动Hadoop,只需要通过start-all.sh即可启动。
4. 在执行命令的时候,出现了Name or service not known或者UnknownHost之类的异常,那么先检查主机名是否写对;再检查/etc/hostname或者是/etc/hosts文件是否配置正确。
5. 在进行ssh的时候需要输入密码,需要重新进行免密。
6. 在执行命令的时候,出现了command not found,那么先检查命令是否配置正确;然后再检查/etc/profile中的环境变量是否配置正确;最后确定对/etc/profile文件修改之后是否进行了重新生效source。
7. 在格式化的时候,出现了HA is not enabled/HA is not available之类的异常,那么说明Hadoop和当前系统出现了兼容性问题 - 重装系统。
8. 如果执行命令的时候出现了IllegalArgument之类的异常,那么说明命令或者参数写错了。
9. 如果启动之后,发现缺少了QuorumPeerMain,那么Zookeeper启动失败。
10. 如果启动之后,发现缺少了NameNode/DataNode/JournalNode/ DFSZKFailoverController进程,可以试图通过hdfs --daemon start namenode/datanode/journalnode/zkfc来单独这个进程,例如hdfs --daemon start datanode。
11. 如果启动之后,发现缺少了ResourceManager/NodeManage进程,那么可以试图通过yarn --daemon start resourcemanager/nodemanager来单独启动这个进程,例如yarn --daemon start nodemanager。
12. 如果在启动的时候,出现process already running as xxx,那么先kill -9 xxx,然后再单独重新启动。
13. 在NameNode格式化的时候,如果格式化失败,那么改错之后,先删除掉/home/software/hadoop-3.1.3/tmp/dfs/name目录,再重新格式化。
三、扩展
1. 服役新节点
1. 先修改新节点的主机名
vim /etc/hostname
#将主机名改为对应的名字,例如hadoop04
2. 进行主机名和IP的映射
vim /etc/hosts
#需要将所有云主机的IP和主机名都进行映射
cd /etc/
#远程拷贝给其他主机
scp -r hosts root@hadoop01:$PWD
scp -r hosts root@hadoop02:$PWD
scp -r hosts root@hadoop03:$PWD
3. 重启
4. 配置免密码互通
ssh-keygen
ssh-copy-id root@hadoop01
ssh hadoop01 --- 如果不需要密码,则输入logout
ssh-copy-id root@hadoop02
ssh hadoop02 --- 如果不需要密码,则输入logout
ssh-copy-id root@hadoop03
ssh hadoop03 --- 如果不需要密码,则输入logout
5. 所有的主机都需要和新添加的节点进行免密
ssh-copy-id root@hadoop04
ssh hadoop04 --- 如果不需要密码,则输入logout
6. 从其他节点拷贝一个Hadoop安装目录到第四个节点上
cd /home/software/
scp -r hadoop-3.1.3 root@hadoop04:$PWD
7. 新添加的节点上,进入Hadoop的安装目录,然后删除对应的目录
cd /home/software/hadoop-3.1.3/
rm -rf tmp
rm -rf logs/
8. 新节点配置环境变量
vim /etc/profile
#在文件末尾添加
export HADOOP_HOME=/home/software/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#保存退出,重新生效
source /etc/profile
9. 启动DataNode
10. 启动YARN
2. Federation HDFS - 联邦HDFS
1. 当前HDFS架构的弊端:
a. NameNode会将元数据维系在内存中。实际开发中,一台服务器大概能腾出50G左右的内存给NameNode来使用,也就意味着一台服务器大概能存储3亿~4亿条元数据,经过计算,意味着NameNode所管理的集群大概能够存储12~15PB的数据。但是在现在的开发中,很多大型企业的数据量已经超过上百PB,原始的NameNode架构就不能满足这个需求。
b. NameNode无法做到程序的隔离。所有的元数据都维系在一个NameNode上,意味着如果某一个任务占用的资源比较多,那么就会影响其他在进行的任务。
c. 所有的请求都只能访问这唯一的一个NameNode,此时NameNode的并发量就成了整个HDFS的并发瓶颈。
2. 在联邦HDFS中,可以利用多个节点同时作为NameNode对外接收请求,在请求之前,需要将HDFS中的路径于NameNode之间来进行映射。每一个路径必须对应某一个NameNode。
3. 在联邦HDFS中,所有的请求不再集中于某一个节点上而是分散到不同的节点上,从而提高了集群的并发量的上限。
4. 因为不同路径分别对应了不同的节点,此时某一个节点上资源被过多的占用,例如节点的磁盘的IO资源占用比较多,并不会影响其他的节点的读写。
5. 因为利用多个NameNode来实现功能,此时元数据也不再集中于一个节点上,而是分散到多个节点上,大大的提高了集群的数据量容纳的上限。
6. 在联邦HDFS中,要求所有的NameNode的BlockPoolID必须一致。