文章目录
- Reinforcement-Learning
- 1. RL方法分类汇总:
- 2. Q-Learning
- 3. SARSA算法
- 4. SARSA(λ)
Reinforcement-Learning
1. RL方法分类汇总:
(1)不理解环境(Model-Free RL):不尝试理解环境,环境给了什么就是什么;机器人只能按部就班一步一步等待真实世界的反馈,再根据反馈采取下一步的行动
理解环境(Model-Based RL):学会了用一种模型来模拟环境;能够通过想象来预判断接下来要发生的所有情况,然后根据这些想象中的情况选择最好的那种,并根据这种情况来采取下一步的策略。
(2)基于概率(Policy-Based RL):通过感官分析所处的环境,直接输出下一步采取的各种行动的概率,然后根据概率采取行动,所以每种动作都有可能被选中,只是可能性不同;用一个概率分布在连续动作中选择特定的动作
基于价值(Value-Based RL):通过感官分析所处的环境,直接输出所有动作的价值,我们会选择价值最高的那个动作;对于连续的动作无能为力
(3)回合更新(Monte-Carlo update):假设强化学习是一个玩游戏的过程。游戏开始后需要等待游戏结束,然后再总结,再更新我们的行为准则
单步更新(Temporal-Difference update):在游戏进行中的每一步都在更新,不用等待游戏的结束,这样就能边玩边学习了
(4)在线学习(On-Policy):本人在场,而且必须是本人边玩边学习
离线学习(Off-Policy):可以选择自己玩,也可以选择看着别人玩,通过看着别人玩来学习别人的行为准则,同样是从过往经历中学习,但这些经历没必要是自己的
2. Q-Learning
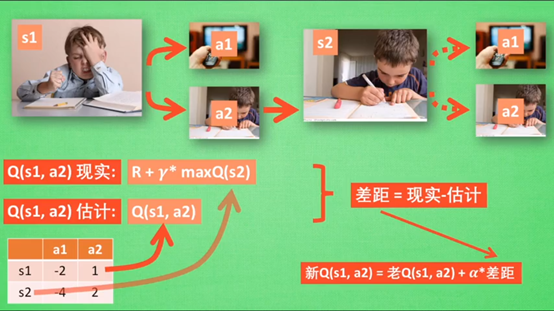
注意!虽然用了maxQ(s2)来估计下一个s2状态,但还没有在状态s2作出任何的行为,s2的决策部分要等到更新完了以后再重新另外执行这一过程

ϵ - greedy是用在决策上的一种策略,如ϵ=0.9时,说明90%的情况按Q表的最优值来选择行为,10%的时间使用随机选择行为;
α是学习效率,来决定这一次误差有多少要被学习,α<1
γ是对未来奖励的衰减值
"""
Reinforcement learning maze example.
Red rectangle: explorer.
Black rectangles: hells [reward = -1].
Yellow bin circle: paradise [reward = +1].
All other states: ground [reward = 0].
This script is the environment part of this example. The RL is in RL_brain.py.
"""
import numpy as np
import time
import sys
if sys.version_info.major == 2:
import Tkinter as tk
else:
import tkinter as tk
UNIT = 40 # pixels
MAZE_H = 4 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.title('maze')
self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_H * UNIT))
self._build_maze()
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_H * UNIT,
width=MAZE_W * UNIT)
# create grids
for c in range(0, MAZE_W * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_W * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create origin
origin = np.array([20, 20])
# hell
hell1_center = origin + np.array([UNIT * 2, UNIT])
self.hell1 = self.canvas.create_rectangle(
hell1_center[0] - 15, hell1_center[1] - 15,
hell1_center[0] + 15, hell1_center[1] + 15,
fill='black')
# hell
hell2_center = origin + np.array([UNIT, UNIT * 2])
self.hell2 = self.canvas.create_rectangle(
hell2_center[0] - 15, hell2_center[1] - 15,
hell2_center[0] + 15, hell2_center[1] + 15,
fill='black')
# create oval
oval_center = origin + UNIT * 2
self.oval = self.canvas.create_oval(
oval_center[0] - 15, oval_center[1] - 15,
oval_center[0] + 15, oval_center[1] + 15,
fill='yellow')
# create red rect
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# pack all
self.canvas.pack()
def reset(self):
self.update()
time.sleep(0.5)
self.canvas.delete(self.rect)
origin = np.array([20, 20])
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# return observation
return self.canvas.coords(self.rect)
def step(self, action):
s = self.canvas.coords(self.rect)
base_action = np.array([0, 0])
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_H - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_W - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
s_ = self.canvas.coords(self.rect) # next state
# reward function
if s_ == self.canvas.coords(self.oval):
reward = 1
done = True
s_ = 'terminal'
elif s_ in [self.canvas.coords(self.hell1), self.canvas.coords(self.hell2)]:
reward = -1
done = True
s_ = 'terminal'
else:
reward = 0
done = False
return s_, reward, done
def render(self):
time.sleep(0.1)
self.update()
def update():
for t in range(10):
s = env.reset()
while True:
env.render()
a = 1
s, r, done = env.step(a)
if done:
break
if __name__ == '__main__':
env = Maze()
env.after(100, update)
env.mainloop()
import numpy as np
import pandas as pd
class QLearningTable:
def __init__(self,actions,learning_rate=0.01,reward_decay=0.9,e_greedy=0.9):
self.actions=actions
self.lr=learning_rate
self.gamma=reward_decay
self.epsilon=e_greedy
self.q_table=pd.DataFrame(columns=self.actions,dtype=np.float64)
def choose_action(self,observation):
self.check_state_exist(observation) #判断当前观测值是否在表中
#动作选择
if np.random.uniform()<self.epsilon:#numpy.random.uniform(x,y)随机生成一个浮点数,它在 [x, y] 范围内,默认值x=0,y=1
#choose best action
state_action=self.q_table.loc[observation,:]
#some actions may have the same value,randomly choose in these actions
action=np.random.choice(state_action[state_action==np.max(state_action)].index)
else:
#choose random action
action=np.random.choice(self.actions)
return action
def learn(self,s,a,r,s_):
self.check_state_exist(s_)
q_predict=self.q_table.loc[s,a]
if s_!='terminal': #next state is not terminal
q_target=r+self.gamma*self.q_table.loc[s_,:].max()
else: #到达terminal,得到奖励
q_target=r
self.q_table.loc[s,a]+=self.lr*(q_target-q_predict) #更新
def check_state_exist(self,state):
if state not in self.q_table.index:
#不在,就将新出现的state值追加到表中
self.q_table=self.q_table.append(
pd.Series( #Series是能够保存任何类型的数据(整数,字符串,浮点数,Python对象等)的一维标记数组。轴标签统称为索引。
[0]*len(self.actions), #len()方法返回列表元素个数,[0]*3=[0,0,0]
index=self.q_table.columns,
name=state,
)
)
from maze_env import Maze
from RL_brain import QLearningTable
def update():
for episode in range(100):
observation=env.reset() #初始化观测值
while True:
env.render() #渲染刷新环境
action=RL.choose_action(str(observation))
observation_,reward,done=env.step(action)
RL.learn(str(observation),action,reward,str(observation_))
observation=observation_
if done:
break
#end of the game
print('game over')
env.destroy()
if __name__=="__main__":
env=Maze()
RL=QLearningTable(actions=list(range(env.n_actions)))
env.after(100,update)
env.mainloop()
3. SARSA算法
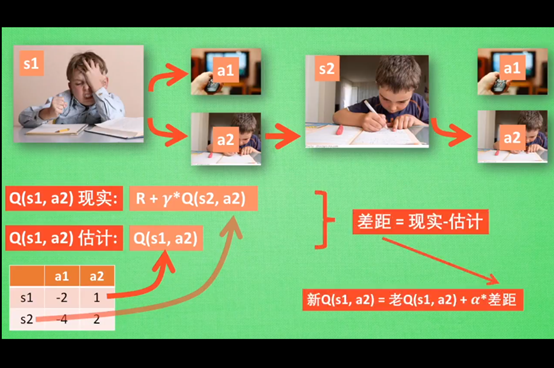
SARSA算法在S2这一步估计的动作也是接下来要做的动作,所以现实值会进行改动,去掉maxQ,改为实实在在的该动作的Q值

SARSA算法:说到做到,行为策略和目标策略相同
Q-Learning:说到不一定做到,行为策略和目标策略不同
import numpy as np
import time
import sys
if sys.version_info.major == 2:
import Tkinter as tk
else:
import tkinter as tk
UNIT = 40 # pixels
MAZE_H = 4 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.title('maze')
self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_H * UNIT))
self._build_maze()
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_H * UNIT,
width=MAZE_W * UNIT)
# create grids
for c in range(0, MAZE_W * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_W * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create origin
origin = np.array([20, 20])
# hell
hell1_center = origin + np.array([UNIT * 2, UNIT])
self.hell1 = self.canvas.create_rectangle(
hell1_center[0] - 15, hell1_center[1] - 15,
hell1_center[0] + 15, hell1_center[1] + 15,
fill='black')
# hell
hell2_center = origin + np.array([UNIT, UNIT * 2])
self.hell2 = self.canvas.create_rectangle(
hell2_center[0] - 15, hell2_center[1] - 15,
hell2_center[0] + 15, hell2_center[1] + 15,
fill='black')
# create oval
oval_center = origin + UNIT * 2
self.oval = self.canvas.create_oval(
oval_center[0] - 15, oval_center[1] - 15,
oval_center[0] + 15, oval_center[1] + 15,
fill='yellow')
# create red rect
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# pack all
self.canvas.pack()
def reset(self):
self.update()
time.sleep(0.5)
self.canvas.delete(self.rect)
origin = np.array([20, 20])
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# return observation
return self.canvas.coords(self.rect)
def step(self, action):
s = self.canvas.coords(self.rect)
base_action = np.array([0, 0])
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_H - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_W - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
s_ = self.canvas.coords(self.rect) # next state
# reward function
if s_ == self.canvas.coords(self.oval):
reward = 1
done = True
s_ = 'terminal'
elif s_ in [self.canvas.coords(self.hell1), self.canvas.coords(self.hell2)]:
reward = -1
done = True
s_ = 'terminal'
else:
reward = 0
done = False
return s_, reward, done
def render(self):
time.sleep(0.1)
self.update()
"""
import numpy as np
import pandas as pd
#Q-Learning和SARSA的公共部分写在RL class内,让他们俩继承
class RL(object):
def __init__(self,action_space,learning_rate=0.01,reward_decay=0.9,e_greedy=0.9):
self.actions=action_space #a list
self.lr=learning_rate
self.gamma=reward_decay
self.epsilon=e_greedy
self.q_table=pd.DataFrame(columns=self.actions,dtype=np.float64)
def check_state_exist(self,state):
if state not in self.q_table.index:
self.q_table=self.q_table.append(
pd.Series(
[0]*len(self.actions),
index=self.q_table.columns,
name=state,
)
)
def choose_action(self,observation):
self.check_state_exist(observation)
if np.random.rand()<self.epsilon: #np.random.rand()可以返回一个服从“0~1”均匀分布的随机样本值。随机样本取值范围是[0,1)
#choose best action
state_action=self.q_table.loc[observation,:]
#some action may have the same value, randomly choose on in these actions
action=np.random.choice(state_action[state_action==np.max(state_action)].index)
else:
#choose random action
action=np.random.choice(self.actions)
return action
def learn(self,*args): #Q-Learning和SARSA的这个部分不一样,接受的参数也不一样
pass
#off-policy
class QLearningTable(RL): #继承了class RL
def __init__(self,actions,learning_rate=0.01,reward_decay=0.9,e_greedy=0.9):
super(QLearningTable,self).__init__(actions,learning_rate,reward_decay,e_greedy)
def learn(self,s,a,r,s_):
self.check_state_exist(s_)
q_prediect=self.q_table.loc[s,a]
if s_!='terminal': #next state isn't terminal
q_target=r+self.gamma*self.q_table.loc[s_,:].max() #找出s_下最大的那个动作值
else: #next state is terminal
q_target=r
self.q_table.loc[s,a]+=self.lr*(q_target-q_prediect) #update
#on-policy 边学边走,比Q-Learning要胆小一点的算法
class SarsaTable(RL): ##继承了class RL
def __init__(self,actions,learning_rate=0.01,reward_decay=0.9,e_greedy=0.9):
super(SarsaTable,self).__init__(actions,learning_rate,reward_decay,e_greedy)
def learn(self,s,a,r,s_,a_): #比Q-learning多一个a_参数
self.check_state_exist(s_)
q_prediect=self.q_table.loc[s,a]
if s_!='terminal':
q_target=r+self.gamma*self.q_table.loc[s_,a_] #具体的s_,a_确定的唯一动作值
else:
q_target=r;
self.q_table.loc[s,a]+=self.lr*(q_target-q_prediect)
"""
import numpy as np
import pandas as pd
class RL(object):
def __init__(self, action_space, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
self.actions = action_space # a list
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon = e_greedy
self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float64)
def check_state_exist(self, state):
if state not in self.q_table.index:
# append new state to q table
self.q_table = self.q_table.append(
pd.Series(
[0]*len(self.actions),
index=self.q_table.columns,
name=state,
)
)
def choose_action(self, observation):
self.check_state_exist(observation)
# action selection
if np.random.rand() < self.epsilon:
# choose best action
state_action = self.q_table.loc[observation, :]
# some actions may have the same value, randomly choose on in these actions
action = np.random.choice(state_action[state_action == np.max(state_action)].index)
else:
# choose random action
action = np.random.choice(self.actions)
return action
def learn(self, *args):
pass
# off-policy
class QLearningTable(RL):
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
super(QLearningTable, self).__init__(actions, learning_rate, reward_decay, e_greedy)
def learn(self, s, a, r, s_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, :].max() # next state is not terminal
else:
q_target = r # next state is terminal
self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
# on-policy
class SarsaTable(RL):
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
super(SarsaTable, self).__init__(actions, learning_rate, reward_decay, e_greedy)
def learn(self, s, a, r, s_, a_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, a_] # next state is not terminal
else:
q_target = r # next state is terminal
self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
"""
from maze_env1 import Maze
from RL_brain1 import SarsaTable
def update():
for episode in range(100):
observation=env.reset() #从环境里获得observation
action=RL.choose_action(str(observation))
#Q-Learning的action是在下面这个while循环里选的,SARSA算法是在循环外
while(True):
env.render() #环境更新
observation_,reward,done=env.step(action)
action_=RL.choose_action(str(observation_))
#与Q—learning不同之处:SARSA还要传入下一个动作action_,而Q—learning不需要
RL.learn(str(observation),action,reward,str(observation_),action_)
#sarsa所估计的下一个action,也是sarsa会采取的action
#observation和action都更新
observation=observation_
action=action_
if done:
break
#end of the game
print('game over')
env.destroy()
if __name__=="main":
env=Maze()
RL=SarsaTable(actions=list(range(env.n_actions)))
env.after(100,update)
env.mainloop()
"""
from maze_env1 import Maze
from RL_brain1 import SarsaTable
def update():
for episode in range(100):
# initial observation
observation = env.reset()
# RL choose action based on observation
action = RL.choose_action(str(observation))
while True:
# fresh env
env.render()
# RL take action and get next observation and reward
observation_, reward, done = env.step(action)
# RL choose action based on next observation
action_ = RL.choose_action(str(observation_))
# RL learn from this transition (s, a, r, s, a) ==> Sarsa
RL.learn(str(observation), action, reward, str(observation_), action_)
# swap observation and action
observation = observation_
action = action_
# break while loop when end of this episode
if done:
break
# end of game
print('game over')
env.destroy()
if __name__ == "__main__":
env = Maze()
RL = SarsaTable(actions=list(range(env.n_actions)))
env.after(100, update)
env.mainloop()
4. SARSA(λ)
λ其实是一个衰变值,让你知道离奖励越远的步可能并不是让你最快拿到奖励的步。所以我们现在站在宝藏所处的位置,回头看看我们所走的寻宝之路,离宝藏越近的脚步我们看得越清楚,越远的脚步越渺小很难看清。所以我们索性认为离宝藏越近的脚步越重要,越需要好好更新。和之前提到的奖励衰减值γ一样,λ是脚步衰减值,都是一个在0和1之间的数.

当λ=0:Sarsa(0)就变成了SARSA的单步更新:每次只能更新最近的一步
当λ=1:Sarsa(1)就变成了SARSA的回合更新:对所有步更新的力度一样
当λ在(0,1),则取值越大,离宝藏越近的步更新力度越大。以不同力度更新所有与宝藏相关的步
SARSA(λ)的伪代码:

SARSA(λ)是向后看的过程,经历了哪些步就要标记一下,标记方法有两种:
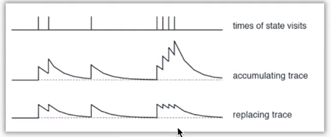
Method 1(accumulating trace): 遇到state就加一,没有遇到衰减,没有封顶值(可能会有)
Method 2(replacing trace): 遇到state就加一,没有遇到衰减,有封顶值,到达封顶值在遇到不可以再往上加了,只能保持在峰值。
import numpy as np
import time
import sys
if sys.version_info.major == 2:
import Tkinter as tk
else:
import tkinter as tk
UNIT = 40 # pixels
MAZE_H = 4 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.title('maze')
self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_H * UNIT))
self._build_maze()
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_H * UNIT,
width=MAZE_W * UNIT)
# create grids
for c in range(0, MAZE_W * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_W * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create origin
origin = np.array([20, 20])
# hell
hell1_center = origin + np.array([UNIT * 2, UNIT])
self.hell1 = self.canvas.create_rectangle(
hell1_center[0] - 15, hell1_center[1] - 15,
hell1_center[0] + 15, hell1_center[1] + 15,
fill='black')
# hell
hell2_center = origin + np.array([UNIT, UNIT * 2])
self.hell2 = self.canvas.create_rectangle(
hell2_center[0] - 15, hell2_center[1] - 15,
hell2_center[0] + 15, hell2_center[1] + 15,
fill='black')
# create oval
oval_center = origin + UNIT * 2
self.oval = self.canvas.create_oval(
oval_center[0] - 15, oval_center[1] - 15,
oval_center[0] + 15, oval_center[1] + 15,
fill='yellow')
# create red rect
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# pack all
self.canvas.pack()
def reset(self):
self.update()
time.sleep(0.5)
self.canvas.delete(self.rect)
origin = np.array([20, 20])
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# return observation
return self.canvas.coords(self.rect)
def step(self, action):
s = self.canvas.coords(self.rect)
base_action = np.array([0, 0])
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_H - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_W - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
s_ = self.canvas.coords(self.rect) # next state
# reward function
if s_ == self.canvas.coords(self.oval):
reward = 1
done = True
s_ = 'terminal'
elif s_ in [self.canvas.coords(self.hell1), self.canvas.coords(self.hell2)]:
reward = -1
done = True
s_ = 'terminal'
else:
reward = 0
done = False
return s_, reward, done
def render(self):
time.sleep(0.05)
self.update()
import numpy as np
import pandas as pd
class RL(object):
def __init__(self,action_space,learning_rate=0.01,reward_decay=0.9,e_greedy=0.9):
self.actions=action_space #a list
self.lr=learning_rate
self.gamma=reward_decay
self.epsilon=e_greedy
self.q_table=pd.DataFrame(columns=self.actions,dtype=np.float64)
def check_state_exist(self,state):
if state not in self.q_table.index:
self.q_table=self.q_table.append(
pd.Series(
[0]*len(self.actions),
index=self.q_table.columns,
name=state,
)
)
def choose_action(self,observation):
self.check_state_exist(observation)
if np.random.rand()<self.epsilon:
#choose best action
state_action=self.q_table.loc[observation,:]
action=np.random.choice(state_action[state_action==np.max(state_action)].index)
else:
#choose random action
action=np.random.choice(self.actions)
return action
def learn(self,*args):
pass
#backward eligibility traces
class SarsaLambdaTable(RL):
def __init__(self,actions,learning_rate=0.01,reward_decay=0.9,e_greedy=0.9,trace_decay=0.9):
super(SarsaLambdaTable,self).__init__(actions,learning_rate,reward_decay,e_greedy)
#除了继承父类的参数,SARSA(lambda)还有自己的参数
#backward view,eligibility trace——sarsa(lambda)的新参数
self.lambda_=trace_decay #脚步衰减值,在0-1之间
self.eligibility_trace=self.q_table.copy() #和q_table一样的table,也是一个行为state,列为action的表,经历了某个state,采取某个action时,在表格对应位置加1
def check_state_exist(self,state):
if state not in self.q_table.index:
#生成一个符合q_table标准的全0数列
to_be_append=pd.Series(
[0]*len(self.actions),
index=self.q_table.columns,
name=state,
)
#追加在q_table后
self.q_table=self.q_table.append(to_be_append)
#追加在eligibility_trace后
#also update eligibility trace
self.eligibility_trace=self.eligibility_trace.append(to_be_append)
def learn(self,s,a,r,s_,a_):
self.check_state_exist(s_)
q_predict=self.q_table.loc[s,a]
if s_!='terminal':
q_target=r+self.gamma*self.q_table.loc[s_,a_]
else:
q_target=r
error=q_target-q_predict #求出误差,反向传递过去
#increase trace amount for visited state_action pair
#计算每个步的不可或缺性(eligibility trace)
#Method 1:没有封顶值,遇到就加一
self.eligibility_trace.loc[s,a]+=1
#Method 2:有封顶值
#self.eligibility_trace.loc[s,:]*=0 #对于这个state,把他的action全部设为0
#self.eligibility_trace.loc[s,a]=1 #在这个state上采取的action,把它变为1
#Q表update,sarsa(lambda)的更新方式:还要乘以eligibility_trace
self.q_table+=self.lr*error*self.eligibility_trace
#decay eligibility trace after update,体现eligibility_trace的衰减:lambda_是脚步衰变值,gamma是reward的衰变值
self.eligibility_trace*=self.gamma*self.lambda_
from maze_env2 import Maze
from RL_brain2 import SarsaLambdaTable
def update():
for episode in range(100):
# initial observation
observation = env.reset()
# RL choose action based on observation
action = RL.choose_action(str(observation))
# initial all zero eligibility trace
RL.eligibility_trace *= 0
while True:
# fresh env
env.render()
# RL take action and get next observation and reward
observation_, reward, done = env.step(action)
# RL choose action based on next observation
action_ = RL.choose_action(str(observation_))
# RL learn from this transition (s, a, r, s, a) ==> Sarsa
RL.learn(str(observation), action, reward, str(observation_), action_)
# swap observation and action
observation = observation_
action = action_
# break while loop when end of this episode
if done:
break
# end of game
print('game over')
env.destroy()
if __name__ == "__main__":
env = Maze()
RL = SarsaLambdaTable(actions=list(range(env.n_actions)))
env.after(100, update)
env.mainloop()
![无涯教程-jQuery - outerWidth( margin])方法函数](https://www.learnfk.com/guide/images/wuya.png)