文章目录
- 1. AOP 用法
- 2. 原理分析
- 2.1 doCreateBean
- 2.2 postProcessAfterInitialization
- 2.3 getAdvicesAndAdvisorsForBean
- 2.3.1 findCandidateAdvisors
- 2.3.2 findAdvisorsThatCanApply
- 2.3.3 extendAdvisors
- 2.4 createProxy
今天和小伙伴们聊一聊 Spring AOP 中的代理对象是怎么创建出来的,透过这个过程再去熟悉一下 Bean 的创建过程。
最近几篇文章都是和小伙伴们聊 Spring 容器的一些使用细节,结合这些细节再看一看源码,等到这些功能都看完之后,我会再做一个汇总,到时候小伙伴们对 Spring 容器的整个创建过程就会有一个比较完整的了解了。
1. AOP 用法
先来一个简单的案例,小伙伴们先回顾一下 AOP,假设我有如下类:
@Service
public class UserService {
public void hello() {
System.out.println("hello javaboy");
}
}
然后我写一个切面,拦截 UserService 中的方法:
@Component
@Aspect
@EnableAspectJAutoProxy
public class LogAspect {
@Before("execution(* org.javaboy.bean.aop.UserService.*(..))")
public void before(JoinPoint jp) {
String name = jp.getSignature().getName();
System.out.println(name+" 方法开始执行了...");
}
}
最后,我们看一下从 Spring 容器中获取到的 UserService 对象:
ClassPathXmlApplicationContext ctx = new ClassPathXmlApplicationContext("aop.xml");
UserService us = ctx.getBean(UserService.class);
System.out.println("us.getClass() = " + us.getClass());
打印结果如下:

可以看到,获取到的 UserService 是一个代理对象。
其他各种类型的通知我这里就不说了,不熟悉的小伙伴可以在公众号【江南一点雨】后台回复 ssm,有松哥录制的免费入门视频。
2. 原理分析
那么注入到 Spring 容器中的 UserService,为什么在获取的时候变成了一个代理对象,而不是原本的 UserService 了呢?
整体上来说,我们可以将 Spring Bean 的生命周期分为四个阶段,分别是:
- 实例化。
- 属性赋值。
- 初始化。
- 销毁。
如下图:
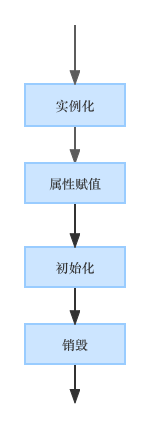
首先实例化就是通过反射,先把 Bean 的实例创建出来;接下来属性赋值就是给创建出来的 Bean 的各个属性赋值;接下来的初始化就是给 Bean 应用上各种需要的后置处理器;最后则是销毁。
2.1 doCreateBean
AOP 代理对象的创建是在初始化这个过程中完成的,所以今天我们就从初始化这里开始看起。
AbstractAutowireCapableBeanFactory#doCreateBean:
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
//...
try {
populateBean(beanName, mbd, instanceWrapper);
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
//...
return exposedObject;
}
小伙伴们看到,这里有一个 initializeBean 方法,在这个方法中会对 Bean 执行各种后置处理器:
protected Object initializeBean(String beanName, Object bean, @Nullable RootBeanDefinition mbd) {
invokeAwareMethods(beanName, bean);
Object wrappedBean = bean;
if (mbd == null || !mbd.isSynthetic()) {
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
}
try {
invokeInitMethods(beanName, wrappedBean, mbd);
}
catch (Throwable ex) {
throw new BeanCreationException(
(mbd != null ? mbd.getResourceDescription() : null), beanName, ex.getMessage(), ex);
}
if (mbd == null || !mbd.isSynthetic()) {
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
}
return wrappedBean;
}
这里一共是执行了四个方法,也都是非常常见的 Bean 初始化方法:
- invokeAwareMethods:执行 Aware 接口下的 Bean。
- applyBeanPostProcessorsBeforeInitialization:执行 BeanPostProcessor 中的前置方法。
- invokeInitMethods:执行 Bean 的初始化方法 init。
- applyBeanPostProcessorsAfterInitialization:执行 BeanPostProcessor 中的后置方法。
1、3 这两个方法很明显跟 AOP 关系不大,我们自己平时创建的 AOP 对象基本上都是在 applyBeanPostProcessorsAfterInitialization 中进行处理的,我们来看下这个方法:
@Override
public Object applyBeanPostProcessorsAfterInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
for (BeanPostProcessor processor : getBeanPostProcessors()) {
Object current = processor.postProcessAfterInitialization(result, beanName);
if (current == null) {
return result;
}
result = current;
}
return result;
}
小伙伴们看到,这里就是遍历各种 BeanPostProcessor,并执行其 postProcessAfterInitialization 方法,将执行结果赋值给 result 并返回。
2.2 postProcessAfterInitialization
BeanPostProcessor 有一个实现类 AbstractAutoProxyCreator,在 AbstractAutoProxyCreator 的 postProcessAfterInitialization 方法中,进行了 AOP 的处理:
@Override
public Object postProcessAfterInitialization(@Nullable Object bean, String beanName) {
if (bean != null) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
if (this.earlyProxyReferences.remove(cacheKey) != bean) {
return wrapIfNecessary(bean, beanName, cacheKey);
}
}
return bean;
}
protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {
if (StringUtils.hasLength(beanName) && this.targetSourcedBeans.contains(beanName)) {
return bean;
}
if (Boolean.FALSE.equals(this.advisedBeans.get(cacheKey))) {
return bean;
}
if (isInfrastructureClass(bean.getClass()) || shouldSkip(bean.getClass(), beanName)) {
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return bean;
}
// Create proxy if we have advice.
Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null);
if (specificInterceptors != DO_NOT_PROXY) {
this.advisedBeans.put(cacheKey, Boolean.TRUE);
Object proxy = createProxy(
bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));
this.proxyTypes.put(cacheKey, proxy.getClass());
return proxy;
}
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return bean;
}
可以看到,首先会尝试去缓存中获取代理对象,如果缓存中没有的话,则会调用 wrapIfNecessary 方法进行 AOP 的创建。
正常来说,普通 AOP 的创建,前面三个 if 的条件都是不满足的。第一个 if 是说 beanName 是否是一个 targetSource,显然我们这里不是;第二个 if 是说这个 Bean 是不是不需代理(结合上篇文章一起理解),我们这里显然是需要代理的;第三个 if 的作用我们也在上篇文章中和小伙伴们介绍过,这里就不再赘述了。
关于第二个 if 我多说一句,如果这里进来的是一个切面的 Bean,例如第一小节中的 LogAspect,这种 Bean 显然是不需要代理的,所以会在第二个方法中直接返回,如果是其他普通的 Bean,则第二个 if 并不会进来。
所在在 wrapIfNecessary 中,最重要的方法实际上就是两个:getAdvicesAndAdvisorsForBean 和 createProxy,前者用来找出来所有跟当前类匹配的切面,后者则用来创建代理对象。
2.3 getAdvicesAndAdvisorsForBean
这个方法,说白了,就是查找各种 Advice(通知/增强) 和 Advisor(切面)。来看下到底怎么找的:
AbstractAdvisorAutoProxyCreator#getAdvicesAndAdvisorsForBean:
@Override
@Nullable
protected Object[] getAdvicesAndAdvisorsForBean(
Class<?> beanClass, String beanName, @Nullable TargetSource targetSource) {
List<Advisor> advisors = findEligibleAdvisors(beanClass, beanName);
if (advisors.isEmpty()) {
return DO_NOT_PROXY;
}
return advisors.toArray();
}
从这里可看到,这个方法主要就是调用 findEligibleAdvisors 去获取到所有的切面,继续:
protected List<Advisor> findEligibleAdvisors(Class<?> beanClass, String beanName) {
List<Advisor> candidateAdvisors = findCandidateAdvisors();
List<Advisor> eligibleAdvisors = findAdvisorsThatCanApply(candidateAdvisors, beanClass, beanName);
extendAdvisors(eligibleAdvisors);
if (!eligibleAdvisors.isEmpty()) {
eligibleAdvisors = sortAdvisors(eligibleAdvisors);
}
return eligibleAdvisors;
}
这里一共有三个主要方法:
- findCandidateAdvisors:这个方法是查询到所有候选的 Advisor,说白了,就是把项目启动时注册到 Spring 容器中所有切面都找到,由于一个 Aspect 中可能存在多个 Advice,每个 Advice 最终都能封装为一个 Advisor,所以在具体查找过程中,找到 Aspect Bean 之后,还需要遍历 Bean 中的方法。
- findAdvisorsThatCanApply:这个方法主要是从上个方法找到的所有切面中,根据切点过滤出来能够应用到当前 Bean 的切面。
- extendAdvisors:这个是添加一个 DefaultPointcutAdvisor 切面进来,这个切面使用的 Advice 是 ExposeInvocationInterceptor,ExposeInvocationInterceptor 的作用是用于暴露 MethodInvocation 对象到 ThreadLocal 中,如果其他地方需要使用当前的 MethodInvocation 对象,直接通过调用 currentInvocation 方法取出即可。
接下来我们就来看一下这三个方法的具体实现。
2.3.1 findCandidateAdvisors
AnnotationAwareAspectJAutoProxyCreator#findCandidateAdvisors
@Override
protected List<Advisor> findCandidateAdvisors() {
List<Advisor> advisors = super.findCandidateAdvisors();
if (this.aspectJAdvisorsBuilder != null) {
advisors.addAll(this.aspectJAdvisorsBuilder.buildAspectJAdvisors());
}
return advisors;
}
这个方法的关键在于通过 buildAspectJAdvisors 构建出所有的切面,这个方法有点复杂:
public List<Advisor> buildAspectJAdvisors() {
List<String> aspectNames = this.aspectBeanNames;
if (aspectNames == null) {
synchronized (this) {
aspectNames = this.aspectBeanNames;
if (aspectNames == null) {
List<Advisor> advisors = new ArrayList<>();
aspectNames = new ArrayList<>();
String[] beanNames = BeanFactoryUtils.beanNamesForTypeIncludingAncestors(
this.beanFactory, Object.class, true, false);
for (String beanName : beanNames) {
if (!isEligibleBean(beanName)) {
continue;
}
// We must be careful not to instantiate beans eagerly as in this case they
// would be cached by the Spring container but would not have been weaved.
Class<?> beanType = this.beanFactory.getType(beanName, false);
if (beanType == null) {
continue;
}
if (this.advisorFactory.isAspect(beanType)) {
aspectNames.add(beanName);
AspectMetadata amd = new AspectMetadata(beanType, beanName);
if (amd.getAjType().getPerClause().getKind() == PerClauseKind.SINGLETON) {
MetadataAwareAspectInstanceFactory factory =
new BeanFactoryAspectInstanceFactory(this.beanFactory, beanName);
List<Advisor> classAdvisors = this.advisorFactory.getAdvisors(factory);
if (this.beanFactory.isSingleton(beanName)) {
this.advisorsCache.put(beanName, classAdvisors);
}
else {
this.aspectFactoryCache.put(beanName, factory);
}
advisors.addAll(classAdvisors);
}
else {
// Per target or per this.
if (this.beanFactory.isSingleton(beanName)) {
throw new IllegalArgumentException("Bean with name '" + beanName +
"' is a singleton, but aspect instantiation model is not singleton");
}
MetadataAwareAspectInstanceFactory factory =
new PrototypeAspectInstanceFactory(this.beanFactory, beanName);
this.aspectFactoryCache.put(beanName, factory);
advisors.addAll(this.advisorFactory.getAdvisors(factory));
}
}
}
this.aspectBeanNames = aspectNames;
return advisors;
}
}
}
if (aspectNames.isEmpty()) {
return Collections.emptyList();
}
List<Advisor> advisors = new ArrayList<>();
for (String aspectName : aspectNames) {
List<Advisor> cachedAdvisors = this.advisorsCache.get(aspectName);
if (cachedAdvisors != null) {
advisors.addAll(cachedAdvisors);
}
else {
MetadataAwareAspectInstanceFactory factory = this.aspectFactoryCache.get(aspectName);
advisors.addAll(this.advisorFactory.getAdvisors(factory));
}
}
return advisors;
}
这个方法第一次进来的时候,aspectNames 变量是没有值的,所以会先进入到 if 分支中,给 aspectNames 和 aspectBeanNames 两个变量赋值。
具体过程就是首先调用 BeanFactoryUtils.beanNamesForTypeIncludingAncestors 方法(不熟悉该方法的小伙伴参考 Spring 中的父子容器是咋回事?一文),去当前容器以及当前容器的父容器中,查找到所有的 beanName,将返回的数组赋值给 beanNames 变量,然后对 beanNames 进行遍历。
遍历时,首先调用 isEligibleBean 方法,这个方法是检查给定名称的 Bean 是否符合自动代理的条件的,这个细节我们就不看了,因为一般情况下,我们项目中的 AOP 都是自动代理的。
接下来根据 beanName,找到对应的 bean 类型 beanType,然后调用 advisorFactory.isAspect 方法去判断这个 beanType 是否是一个 Aspect,具体的判断过程上篇文章讲过了,小伙伴们可以参考。
如果当前 beanName 对应的 Bean 是一个 Aspect,那么就把 beanName 添加到 aspectNames 集合中,并且把 beanName 和 beanType 封装为一个 AspectMetadata 对象。
接下来会去判断 kind 是否为 SINGLETON,这个默认都是 SINGLETON,所以这里会进入到分支中,进来之后,会调用 this.advisorFactory.getAdvisors 方法去 Aspect 中找到各种通知和切点并封装成 Advisor 对象返回,由于一个切面中可能定义多个通知,所以最终返回的 Advisor 是一个集合,最后把找到的 Advisor 集合存入到 advisorsCache 缓存中。
后面方法的逻辑就很好懂了,从 advisorsCache 中找到某一个 aspect 对应的所有 Advisor,并将之存入到 advisors 集合中,然后返回集合。
这样,我们就找到了所有的 Advisor。
额外多说一句,在上篇文章中,松哥最后留了一个彩蛋,当时说普通的 Bean 会走到 shouldSkip 方法中,这个 shouldSkip 方法最终就会走到 buildAspectJAdvisors 中来,所以上篇文章后来就没和大家分析 buildAspectJAdvisors 方法了。其实,如果在 shouldSkip 方法中就调用了 buildAspectJAdvisors,那么就完成了 Advisor 的收集了,后续每次直接获取就可以了。
2.3.2 findAdvisorsThatCanApply
接下来 findAdvisorsThatCanApply 方法主要是从众多的 Advisor 中,找到能匹配上当前 Bean 的 Advisor,小伙伴们知道,每一个 Advisor 都包含一个切点 Pointcut,不同的切点意味着不同的拦截规则,所以现在需要进行匹配,检查当前类需要和哪个 Advisor 匹配:
protected List<Advisor> findAdvisorsThatCanApply(
List<Advisor> candidateAdvisors, Class<?> beanClass, String beanName) {
ProxyCreationContext.setCurrentProxiedBeanName(beanName);
try {
return AopUtils.findAdvisorsThatCanApply(candidateAdvisors, beanClass);
}
finally {
ProxyCreationContext.setCurrentProxiedBeanName(null);
}
}
这里实际上就是调用了静态方法 AopUtils.findAdvisorsThatCanApply 去查找匹配的 Advisor:
public static List<Advisor> findAdvisorsThatCanApply(List<Advisor> candidateAdvisors, Class<?> clazz) {
if (candidateAdvisors.isEmpty()) {
return candidateAdvisors;
}
List<Advisor> eligibleAdvisors = new ArrayList<>();
for (Advisor candidate : candidateAdvisors) {
if (candidate instanceof IntroductionAdvisor && canApply(candidate, clazz)) {
eligibleAdvisors.add(candidate);
}
}
boolean hasIntroductions = !eligibleAdvisors.isEmpty();
for (Advisor candidate : candidateAdvisors) {
if (candidate instanceof IntroductionAdvisor) {
// already processed
continue;
}
if (canApply(candidate, clazz, hasIntroductions)) {
eligibleAdvisors.add(candidate);
}
}
return eligibleAdvisors;
}
这个方法中首先会去判断 Advisor 的类型是否是 IntroductionAdvisor 类型,IntroductionAdvisor 类型的 Advisor 只能在类级别进行拦截,灵活度不如 PointcutAdvisor,所以我们一般都不是 IntroductionAdvisor,因此这里最终会走入到最后一个分支中:
public static boolean canApply(Advisor advisor, Class<?> targetClass, boolean hasIntroductions) {
if (advisor instanceof IntroductionAdvisor ia) {
return ia.getClassFilter().matches(targetClass);
}
else if (advisor instanceof PointcutAdvisor pca) {
return canApply(pca.getPointcut(), targetClass, hasIntroductions);
}
else {
// It doesn't have a pointcut so we assume it applies.
return true;
}
}
从这里小伙伴们就能看到,IntroductionAdvisor 类型的 Advisor 只需要调用 ClassFilter 过滤一下就行了,ClassFilter 松哥在前面的文章中已经介绍过了(玩一玩编程式 AOP),小伙伴们看这里的匹配逻辑也是非常 easy!而 PointcutAdvisor 类型的 Advisor 则会继续调用 canApply 方法进行判断:
public static boolean canApply(Pointcut pc, Class<?> targetClass, boolean hasIntroductions) {
if (!pc.getClassFilter().matches(targetClass)) {
return false;
}
MethodMatcher methodMatcher = pc.getMethodMatcher();
if (methodMatcher == MethodMatcher.TRUE) {
// No need to iterate the methods if we're matching any method anyway...
return true;
}
IntroductionAwareMethodMatcher introductionAwareMethodMatcher = null;
if (methodMatcher instanceof IntroductionAwareMethodMatcher iamm) {
introductionAwareMethodMatcher = iamm;
}
Set<Class<?>> classes = new LinkedHashSet<>();
if (!Proxy.isProxyClass(targetClass)) {
classes.add(ClassUtils.getUserClass(targetClass));
}
classes.addAll(ClassUtils.getAllInterfacesForClassAsSet(targetClass));
for (Class<?> clazz : classes) {
Method[] methods = ReflectionUtils.getAllDeclaredMethods(clazz);
for (Method method : methods) {
if (introductionAwareMethodMatcher != null ?
introductionAwareMethodMatcher.matches(method, targetClass, hasIntroductions) :
methodMatcher.matches(method, targetClass)) {
return true;
}
}
}
return false;
}
小伙伴们看一下,这里就是先按照类去匹配,匹配通过则继续按照方法去匹配,方法匹配器要是设置的 true,那就直接返回 true 就行了,否则就加载当前类,也就是 targetClass,然后遍历 targetClass 中的所有方法,最后调用 introductionAwareMethodMatcher.matches 方法去判断方法是否和切点契合。
就这样,我们就从所有的 Advisor 中找到了所有和当前类匹配的 Advisor 了。
2.3.3 extendAdvisors
这个是添加一个 DefaultPointcutAdvisor 切面进来,这个切面使用的 Advice 是 ExposeInvocationInterceptor,ExposeInvocationInterceptor 的作用是用于暴露 MethodInvocation 对象到 ThreadLocal 中,如果其他地方需要使用当前的 MethodInvocation 对象,直接通过调用 currentInvocation 方法取出即可。
这个方法的逻辑比较简单,我就不贴出来了,小伙伴们可以自行查看。
2.4 createProxy
看完了 getAdvicesAndAdvisorsForBean 方法,我们已经找到了适合我们的 Advisor,接下来继续看 createProxy 方法,这个方法用来创建一个代理对象:
protected Object createProxy(Class<?> beanClass, @Nullable String beanName,
@Nullable Object[] specificInterceptors, TargetSource targetSource) {
return buildProxy(beanClass, beanName, specificInterceptors, targetSource, false);
}
private Object buildProxy(Class<?> beanClass, @Nullable String beanName,
@Nullable Object[] specificInterceptors, TargetSource targetSource, boolean classOnly) {
if (this.beanFactory instanceof ConfigurableListableBeanFactory clbf) {
AutoProxyUtils.exposeTargetClass(clbf, beanName, beanClass);
}
ProxyFactory proxyFactory = new ProxyFactory();
proxyFactory.copyFrom(this);
if (proxyFactory.isProxyTargetClass()) {
// Explicit handling of JDK proxy targets and lambdas (for introduction advice scenarios)
if (Proxy.isProxyClass(beanClass) || ClassUtils.isLambdaClass(beanClass)) {
// Must allow for introductions; can't just set interfaces to the proxy's interfaces only.
for (Class<?> ifc : beanClass.getInterfaces()) {
proxyFactory.addInterface(ifc);
}
}
}
else {
// No proxyTargetClass flag enforced, let's apply our default checks...
if (shouldProxyTargetClass(beanClass, beanName)) {
proxyFactory.setProxyTargetClass(true);
}
else {
evaluateProxyInterfaces(beanClass, proxyFactory);
}
}
Advisor[] advisors = buildAdvisors(beanName, specificInterceptors);
proxyFactory.addAdvisors(advisors);
proxyFactory.setTargetSource(targetSource);
customizeProxyFactory(proxyFactory);
proxyFactory.setFrozen(this.freezeProxy);
if (advisorsPreFiltered()) {
proxyFactory.setPreFiltered(true);
}
// Use original ClassLoader if bean class not locally loaded in overriding class loader
ClassLoader classLoader = getProxyClassLoader();
if (classLoader instanceof SmartClassLoader smartClassLoader && classLoader != beanClass.getClassLoader()) {
classLoader = smartClassLoader.getOriginalClassLoader();
}
return (classOnly ? proxyFactory.getProxyClass(classLoader) : proxyFactory.getProxy(classLoader));
}
这段代码不知道小伙伴们看了是否觉得眼熟,这就是前面发的另类 AOP,编程式 AOP!一文中的内容,所以这块源码大家自己看看就好了,我就不啰嗦了。
好啦,经过上面这一顿操作,代理对象就创建出来了~本文是一个大致的逻辑,还有一些特别细的小细节没和小伙伴们梳理,咱们有面有空松哥继续整文章和大家介绍