文章目录
- 前言
- 修改点
- Preprocess
- Inference
- 总结
前言
之前写个yolov8的一个试用版,【深度学习】Yolov8追踪从0到1, 这要是做计数啥的,简单的一批,一套工程化的代码,给自己挖了个坑,说要实现一个基于yolov8的人/车流量统计.
现在要改进,想要做成能够处理多摄像头的,也就是多个摄像头共享一个算法来处理计数。
修改点
先修改最重要的点,前处理、推理和后处理,主要是吧原来单图片,修改成多图片的入参。yolov官方工程的track.py 注释的很清楚。Preprocess/Inference/Postprocess.

改造的整体思路是要搞清楚:
- 原输入是什么
- 原输出是什么
- 期望输入是什么
- 期望输入套到原方法是否工作良好
- 期望输出是什么
Preprocess
看150行
im0s 一个list,[array([[[125, 118, 1…ype=uint8)]
看一眼它的形状:HWC
im0s[0].shape
(1080, 1920, 3)
其输出im
im.shape
torch.Size([1, 3, 384, 640])
它的作用是将list的array 转成 torch.Tensor对象,并且转成BCHW的形状,注意这里应该是resize了,将最长边1920–>640,而短边等比例缩放到了384;
正常应该缩放到360,但不知道为啥它输出了384.(待定??)
经测试,im0s 输入修改成 [array([[[125, 118, 1…ype=uint8),array([[[125, 118, 1…ype=uint8)] 输出为:torch.Size([2, 3, 384, 640]) 满足预期。
Inference
来到了154行
input: im
im.shape
torch.Size([1, 3, 384, 640])
output:preds

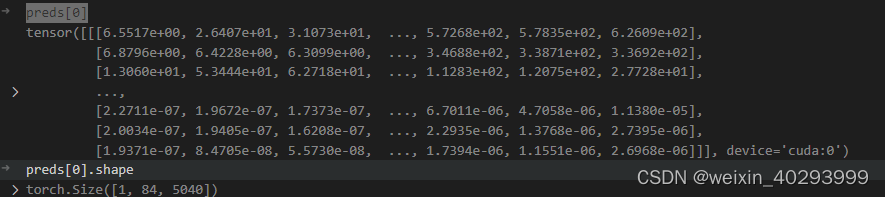
preds[0]
对于yolov8的结构和输出解析看这里ref:https://zhuanlan.zhihu.com/p/598566644
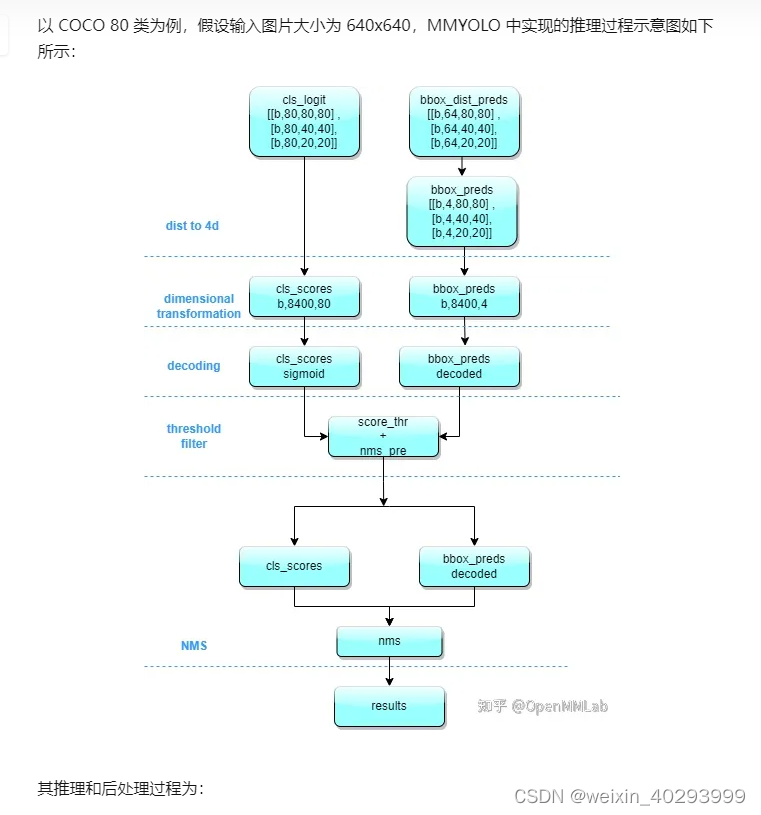
preds[0]是一个tensor, 第一维度是 bz,第二维度是 80类和矩形框位置,第三维度未知(todo)应该是融合后的特征,正常来说若输入图片是640640 则是8400=(8080 + 40*40 + 20 *20),这个知乎的解读也不一定对,起码和我打印的结果不一致。
总结
参考:
git:https://github.com/MuhammadMoinFaisal/YOLOv8-DeepSORT-Object-Tracking
blog:https://blog.csdn.net/liuxuan19901010/article/details/130555216