hive函数大全
- 一级目录
- !
- !=
- %
- &
- *
- +
- -
- /
- <
- <=
- <=>
- <>
- =
- ==
- >
- >=
- ^
- abs
- acos
- add_months
- and
- array
- array_contains
- ascii
- asin
- assert_true
- atan
- avg
- base64
- between
- bin
- bround
- case
- cbrt
- ceil
- ceiling
- chr
- coalesce
- collect_list
- collect_set
- concat
- concat_ws
- context_ngrams
- conv
- corr
- cos
- count
- covar_pop
- covar_samp
- crc32
- create_union
- cume_dist()
- current_database
- current_date
- current_timestamp
- current_user
- date_add
- date_format
- date_sub
- datediff
- day
- dayofmonth
- dayofweek
- decode
- degrees
- dense_rank
- div
- e
- elt
- encode
- ewah_bitmap
- ewah_bitmap_and
- ewah_bitmap_empty
- ewah_bitmap_or
- exp
- explode
- factorial
- field
- find_in_set
- first_value
- floor
- floor_day
- floor_hour
- floor_minute
- floor_month
- floor_quarter
- floor_second
- floor_week
- floor_year
- format_number
- from_unixtime
- from_utc_timestamp
- get_json_object
- get_splits
- greatest
- grouping
- hash
- hex
- histogram_numeric
- hour
- if
- in
- in_file
- initcap
- inline
- instr
- internal_interval
- isnotnull
- isnull
- java_method
- json_tuple
- lag
- last_day
- last_value
- lcase
- lead
- least
- length
- levenshtein
- like
- ln
- locate
- log
- log10
- log2
- logged_in_user
- lower
- lpad
- ltrim
- map
- map_keys
- map_values
- mask
- mask_first_n
- mask_hash
- mask_last_n
- mask_show_first_n
- mask_show_last_n
- matchpath
- max
- md5
- min
- minute
- month
- months_between
- named_struct
- negative
- next_day
- ngrams
- not
- ntile
- nvl
- or
- parse_url
- parse_url_tuple
- percent_rank
- percentile
- percentile_approx
- pi
- pmod
- posexplode
- positive
- pow
- power
- printf
- quarter
- radians
- rand
- rank
- reflect
- regexp
- regexp_extract
- regexp_replace
- repeat
- replace
- reverse
- rlike
- round
- row_number
- rpad
- rtrim
- second
- sentences
- sha
- sha1
- sha2
- shiftleft
- shiftright
- shiftrightunsigned
- sign
- sin
- size
- sort_array
- soundex
- space
- split
- sqrt
- stack
- std
- stddev
- stddev_pop
- stddev_samp
- str_to_map
- struct
- substr
- substring
- substring_index
- sum
- tan
- to_date
- to_unix_timestamp
- to_utc_timestamp
- translate
- trim
- trunc
- ucase
- unbase64
- unhex
- unix_timestamp
- upper
- uuid
- var_pop
- var_samp
- variance
- version
- weekofyear
- when
- windowingtablefunction
- xpath
- xpath_boolean
- xpath_int/xpath_long/xpath_short/xpath_number/xpath_float/xpath_double
- xpath_string
- year
- |
一级目录
!
取反
select !(1=1);
>false
!=
不等于号,示例:
select 1 from dul where 2!=1;
>1
%
取余操作,示例:
select 41%5
>1
&
按位与操作,示例:
select 4&8
>0
*
数据运算符乘,示例:
select 2*3
>6
+
数学运算符加号,实例:
select 1=+2
>3
-
数学运算符加号,实例:
select 3-1
>2
/
数学运算符除号,实例
select 4/2
>2
<
表达式A小于表达式B为true,否则为false
select 1 from dul where 0<1
>1
<=
表达式A小于等于表达式B为true,否则为false
select 1 from dul where 0<1
>1
<=>
可以用来判断null值,如果两个值都为null, 则为true;
select null<=>1;
>false
<>
不等号比较
select * from test where 1 <> 2
=
表达式A和表达式B相等,则为true,否则未false
select 1 from dul where 1=1
>1
==
select 1=='1';
>true
>
表达式A大于表达式B为true,否则为false
select 1 from dul where 2>1
>1
>=
表达式A大于等于表达式B为true,否则为false
select 1 from dul where 1>=1
>1
^
按位异或操作,示例:
select 4^8
>12
abs
取数字的绝对值
select abs('-1')
>1
acos
如果-1<=X<=1,返回X的反余弦值。否则返回NaN
select acos(0.6216099682706644)
>0.9
add_months
select add_months('2022-10-21 12',1)
>2022-11-21
and
逻辑并运算符,示例:
select 1 from dul where 1=1 and 2=2;
>1
array
使用给定的表达式,构造一个 array 数据结构
select array(1,2,3)
>[1,2,3]
array_contains
array_contains(数组,值)
select array_contains(array(1,2,3),1);
>true
ascii
返回字符串str的第一个字符的ascii码,示例:
select ascii('abcde');
>97
asin
返回a的反正弦值,示例:
select asin(0.7173560908995228);
>0.8
assert_true
select assert_true(1<2) -- 返回null
select assert_true(1>2) -- 抛出异常
atan
返回a的反正切值,示例:
select atan(1.0296385570503641);
>0.8
avg
计算平均值,实例
select avg(a) from (select 1 union all select 2 union all select 3) t
>2
base64
将二进制bin转换成64位字符串
select base64(cast('abc:123' as binary));
>YWJjOjEyMw==
between
作为条件两边包含的,示例:
select 1 from dul where 1 between 1 and 2;
>1
bin
返回a的二进制代码表示,a为bigint类型,示例:
select bin(7);
>111
bround
bround(double a),bround(double a, int d)
银行家舍入法(1-4:舍,6-9:进,5->前位数是奇数:进,5->前位数是偶:舍)
select bround(3.215);
>3
select bround(3.25,1);
>3.2
case
Select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end from dual;
>'mary'
cbrt
求a的立方根
select cbrt(8);
>2
ceil
说明:返回等于或者大于该double变量的最小的整数,举例:
select ceil(3.1415926) ;
> 4
ceiling
向上取整
select ceil(2.3);
>3
chr
返回指定数字对应的ASCII 字符,如果指定的数字大于256,将对该数字对256取模,示例:
select chr(97);
>a
coalesce
如果第一个参数为空,那就取第二个值
select coalesce(null,null,1,2)
>1
collect_list
将一列的数据进行聚合,最后结果为一个不去重的数组,实例:
select collect_list(a) from (select 1 as a union select 2 union select 3) t
>[1,2,3]
collect_set
将一列的数据进行聚合,最后结果为一个不去重的集合,实例:
select collect_set(a) from (select 1 as a union select 2 union select 2) t
>[1,2]
compute_stats
ANALYZE TABLE table_name PARTITION(dt='20230728') COMPUTE STATISTICS;
#查看结果
DESCRIBE extended table_name PARTITION(dt='20230728');
concat
将字符串按照顺序进行拼接
select concat('a','b','c')
>'abc'
concat_ws
所有的字符串按照指定的拼接符进行拼接,实例:
select concat_ws(',','a','b','c')
>'a,b,c'
context_ngrams
context_ngrams(array<array< string>>) arr,array< string>,int k) — 在第一个参数集合里,第二个参数中指定单词之后的单词出现频次,倒序取TOP K,第二个参数指定一个单词字符串,该字符串指定n-gram元素的位置,其中一个null代表必须由n-gram元素填充的“空白”
select context_ngrams(sentences('hello word!hello hive,hi hive,hello hive'),array('hello',null),1) ;
>[{"ngram":["hive"],"estfrequency":2.0}]
conv
conv(BIGINT/string num, int from_base, int to_base)
将bigint/string数据num从from_base进制转化到to_base进制
select conv(17,10,16)
>11
corr
返回两列数值的相关系数
cos
返回a的余弦值,示例:
select cos(0.9);
>0.6216099682706644
count
个数统计函数,示例
select count(*) from (select 1 union all select 2) t;
>2
covar_pop
求指定列数值的协方差
covar_samp
求指定列数值的样本协方差
crc32
加密
select crc32('abc');
>891568578
create_union
使用给定的 tag 和表达式,构造一个 uniontype 数据结构。tag 表示使用第 tag 个
表达式作为 uniontype 的 value
select create_union(0,'ss',array(1,2,3)) from iteblog;
> {0:"ss"}
select create_union(1,'ss',array(1,2,3)) from iteblog;
>{1:[1,2,3]}
select create_union(2,'ss',array(1,2,3),'aa') from iteblog;
> {2:'aa'}
cume_dist()
开窗函数,不常用
current_database
获取当前所在的database空间,示例:
select current_database()
>test
current_date
获取当前的日期,示例:
select current_date()
>20220-01-02
current_timestamp
获取当前时间的时间戳
select current_timestamp()
>
current_user
获取当前的用户,示例:
select current_user()
>hive
date_add
日期计算函数,在第一个日期上加对应日期,示例:
select date_add('2022-01-03',)
date_format
格式化日期,示例:
select date_format('2019-1-1', 'yyyy-MM-dd');
>'2019-01-01'
date_sub
返回开始日期startdate减少days天后的日期,举例:
select date_sub('2012-12-08',10);
>2012-11-28
datediff
返回结束日期减去开始日期的天数。
select datediff('2012-12-08','2012-05-09');
>213
day
返回日期中的天。
select day('2011-12-08 10:03:01');
>8
dayofmonth
返回当前日期是当月的第几天
select dayofmonth('2022-12-13');
>13
dayofweek
返回日期那天的周几,
select dayofweek('2023-07-28');
>6
decode
使⽤指定的字符集charset将⼆进制值bin解码成字符串,⽀持的字符集有:‘US-ASCII’, ‘ISO-8859-1’, ‘UTF-8’, ‘UTF-
16BE’, ‘UTF-16LE’, ‘UTF-16’,如果任意输⼊参数为NULL都将返回NULL
select decode(cast('abc:123' as binary),'US-ASCII');
>abc:123
degrees
弧度值转角度值,返回a的角度值,示例:
select degrees(1);
>57.29577951308232
dense_rank
排序字段值相同时,序号相同,下一个序号顺序自增
div
两数相除取商,与%相反;
SELECT -10 div 3;
>-3
e
数学常数e
select e();
>2.718281828459045
elt
返回给定字符串集中的第N个,若不存在则返回null。例如:
select elt(2,'hello','world')
>'world'
encode
使用charset方式,将字符串src编码为二进制bin。支持的字符集有:‘US-ASCII’, ‘ISO-8859-1’, ‘UTF-8’, ‘UTF-16BE’, ‘UTF-16LE’, ‘UTF-16’
ewah_bitmap
返回一个ewah压缩的列的位图表示.
ewah_bitmap_and
返回ewah压缩的位图,即两个位图的按位和。
ewah_bitmap_empty
测试ewah压缩位图是否全是零的谓词
ewah_bitmap_or
返回一个ewah压缩的位图,即两个位图的按位或。
exp
返回自然对数e的a次方,a为小数,示例:
select exp(3);
>20.085536923187668
explode
对于a中每个元素,将生成一行且包含改元素
factorial
求a的阶乘,3!=321 ,示例:
select factorial(3);
>6
field
返回val在val1,val2…的位置。若不存在则返回0。例如:
select field('world','say','hello','world')
>3
find_in_set
find_in_set(string str, string strList),返回str在strlist第一次出现的位置,strlist是用逗号分割的字符串。如果没有找该str字符,则返回0
select find_in_set('ab','ef,ab,de') from lxw_dual:
>2
first_value
first_value—最多接受两个参数。第一个参数是你想要的列的第一个值,第二个参数必须是一个布尔值(可选),默认是假的。如果设置为真,它跳过null值
select a,first_value(a)over(order by a) from (select null a union all select 1 union all select 3) t
>null,null
> 1 ,null
> 2 ,null
floor
说明:返回等于或者小于该double变量的最大的整数,举例:
select floor(3.1415926);
> 3
floor_day
入参必须是timestamp,示例:
select floor_day(CURRENT_TIMESTAMP())
>2023-07-28 00:00:00
floor_hour
入参必须是timestamp,示例:
select floor_hour(CURRENT_TIMESTAMP())
>2023-07-28 10:00:00
floor_minute
入参必须是timestamp,示例:
select floor_minute(CURRENT_TIMESTAMP())
>2023-07-28 10:06:00
floor_month
入参必须是timestamp,示例:
select floor_month(CURRENT_TIMESTAMP())
>2023-07-01 00:00:00
floor_quarter
入参必须是timestamp,返回四分之一粒度
param的时间戳,示例:
select floor_quarter(CURRENT_TIMESTAMP())
>2023-01-01 00:00:00
floor_second
入参必须是timestamp,示例:
select floor_second(CURRENT_TIMESTAMP())
>2023-07-28 10:06:12
floor_week
入参必须是timestamp, 返回的是当前所在周周一的日期 ,示例:
select floor_week(CURRENT_TIMESTAMP())
>2023-07-24 00:00:00
floor_year
入参必须是timestamp,示例:
select floor_year(CURRENT_TIMESTAMP())
>2023-01-01 00:00:00
format_number
将数字精确到d位小数,例如:
select format_number(5.123456, 4)
>5.1235
from_unixtime
转化UNIX时间戳(从1970-01-01 00:00:00 UTC到指定时间的秒数)到当前时区的时间格式
select from_unixtime(1598079966,'yyyy-MM-dd HH:mm:ss');
>2020-08-22 15:06:06
from_utc_timestamp
如果给定的时间戳并非UTC,则将其转化成指定时区下的时间戳,示例:
select from_utc_timestamp('1970-01-01 08:00:00','PST');
>1970-01-01
get_json_object
解析json的字符串json_string,返回path指定内容。如果输⼊的json字符串⽆效,那么返回NULL。注意此路径上JSON字符串只
能由数字 字母 下划线组成且不能有⼤写字母和特殊字符,且key不能由数字开头,这是由于Hive对列名的限制
select get_json_object('{
"store": {
"fruit": [
{
"weight": 8,
"type": "apple"
},
{
"weight": 9,
"type": "pear"
}
],
"bicycle": {
"price": 19.95,
"color": "red"
}
},
"email": "amy@only_for_json_udf_test.net",
"owner": "amy"
}','$.owner')
>amy
get_splits
greatest
求最大值,示例:
select greatest(1,2,3);
>3
grouping
分组,sql基本都会用到不做介绍
hash
取str的hash值
select hash('abc');
>96354
hex
hex(bigint a),hex(string a)
如果变量是int类型,那么返回a的十六进制表示,如果变量是string类型则返回字符串的16进制表示,示例:
select hex(17);
>11
select hex('abc');
>616263
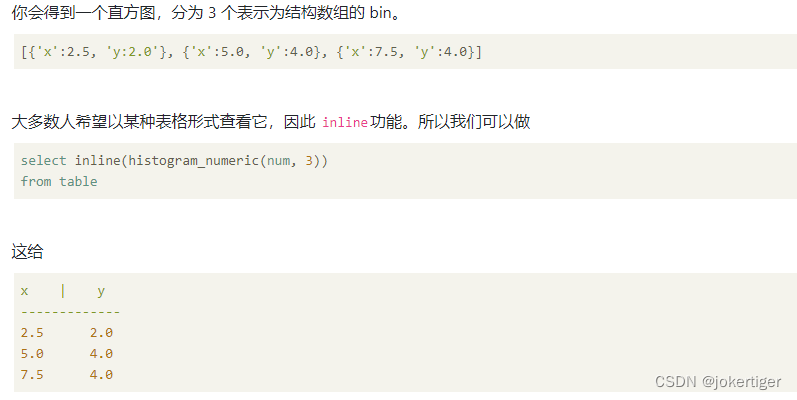
histogram_numeric
已b为基准计算col的直方图信息,示例:
select histogram_numeric(100,5);
>[{"x":100.0,"y":1.0}]
hour
返回日期中的小时,示例:
select hour('2021-10-01 12:22:23');
>12
if
条件判断,实例
select if(1=2,'a','b')
>'b'
in
判断是否包含,示例
select 1 from dual where 1 in (1,2,3,4);
>1
in_file
in_file(string str, string filename)
如果文件名为filename的文件中有一行数据与字符串str匹配成功就返回TRUE
index
initcap
返回字符串,每个单词的第一个字母为大写,所有其他字母为小写。单词由空格分隔
select initcap('abc');
>'Abc'
inline
一行变多行
instr
查找字符串str中子字符串sbustr出现的位置,如果查找失败将返回0;
select instr('dvfgefggdgaa,'aa'');
>11
internal_interval
该方法不是直接调用它来使用的,它为“INTERVAL(intervalArg)intervalType”构造提供了内部支持
isnotnull
如果a为非null就返回true,示例:
select isnotnull(5)
>true
isnull
表达式A为null,则为true,否则为false
select 1 from dul where null is null
>1
java_method
– hive调用java方法
select java_method("java.lang.Math","max",100,200);
>200
json_tuple
jsonStr是包含JSON数据的字符串,key1,key2等是我们要获取的JSON对象的键,如果我们查询的键不存在,json_tuple函数将返回NULL。例如:
SELECT json_tuple('{"name":"Alice","age":30}','name' as c1 ,'age'as c2);
> c1 c2
>Alice 30
lag
分析函数,开窗函数
last_day
返回这个月的最后一天的日期,精确到天,示例
select last_day('2022-07-01 10:01:00');
>2022-07-31
last_value
开窗函数
lcase
返回字符串小写格式
select lcase('abSEd');
>absed
lead
开窗函数
least
求最小值,示例:
select least(1,2,3);
>1
length
返回字符串A的长度,举例:
select length('abcedfg');
> 7
levenshtein
返回两个字符串之间的Levenshtein距离。(Levenshtein 距离,又称编辑距离,指的是两个字符串之间,由一个转换成另一个所需的最少编辑操作次数。编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符)
select levenshtein('kitten', 'sitting')
>3
like
简单模糊匹配,示例:
select 1 from dul where 'abcd' like '%b%';
>1
ln
返回a的自然对数
select ln(7.38905609893065);
>2.0
locate
返回substr在str的pos位置后,第一次出现的位置,pos非必传。例如l:
select locate('a', 'abcabc')
>1
select locate('a', 'abcabc',1)
>1
select locate('a', 'abcabc',2)
>4
log
以base为底a的对数,示例:
select log(4256);
>4.0
log10
返回以10为底a的对数,示例:
select log10(100);
>2.0
log2
返回以2为底的a的对数,a为可视小数,示例:
select log2(8);
>3.0
logged_in_user
返回当前会话的用户,示例:
select logged_in_user()
>test
lower
返回字符串的小写形式,示例:
select lower('ABC');
>'abc'
lpad
将str进⾏⽤pad进⾏左补⾜到len位,从左边开始对字符串str使⽤字符串pad填充,最终len长度为⽌,如果字符串str本⾝长度⽐len
⼤的话,将去掉多余的部分
select lpad('abc',10,'td');
>tdtdtdtabc
ltrim
去掉字符串A前面的空格
select ltrim(' abc fg');
>abc fg
map
使用给定的 key-value 对,构造一个 map 数据结构
select map('k1','v1','k2','v2') from iteblog;
>{"k2":"v2","k1":"v1"}
map_keys
返回map结构所有的key,结果为数组
select map_keys(map('k1','v1','k2','v2'));
>["k1","k2"]
map_values
返回map结构所有的value,结果为数组
select map_keys(map('k1','v1','k2','v2'));
>["v1","v2"]
mask
输出默认脱敏后的结果
select mask(要加密字段) from 表名;
select mask(要加密字段,'X','x','#') from 表名 -- 输出自定义脱敏后的结果
mask_first_n
对前n个字符进行脱敏
select mask_first_n(要加密的字段,n) from 表名
mask_hash
对字段进行hash操作,若是非string类型的字段此函数就返回null
select mask_hash(字段) from 表名;
mask_last_n
对后n个字符进行脱敏,示例:
select mask_last_n(要加密的字段,n) from 表名;
mask_show_first_n
对除了前n个字符之外的字符进行脱敏,示例:
select mask_show_first_n(要加密的字段,n) from 表名;
mask_show_last_n
对除了后n个字符之外的字符进行脱敏
select mask_show_last_n(要加密的字段,n) from 表名;
matchpath
暂时没弄明白
select
tpath
,tpath[0]
,tpath[0].user_id
,tpath[0].visit_time
,concat(tpath[0].user_id,"_",unix_timestamp(tpath[0].visit_time)) as session_id
from matchpath(
on
(select user_id,visit_time
from user_visit
) a
distribute by user_id sort by visit_time
arg1("A.B*"),
arg2("A"),
arg3(floor((unix_timestamp(visit_time) - unix_timestamp(lag(visit_time,1,"1900-01-01 00:00:00")))/60) >= 30),
arg4("B"),
arg5(floor((unix_timestamp(visit_time) - unix_timestamp(lag(visit_time,1,"1900-01-01 00:00:00")))/60) < 30),
arg6('user_id,visit_time,tpath')
)
max
获取最大值,示例:
select max(a) from (select 1 as a union select 4 union all select 3) t
>4
md5
返回md5码,算是简单的加密
select md5('abc')
900150983cd24fb0d6963f7d28e17f72
min
获取最小值,示例:
select min(a) from (select 1 as a union select 4 union all select 3) t
>1
minute
返回日期中的分钟
select minute('2022-10-01 12:22:23'):
>22
month
返回日期中的月份
select month('2011-12-08 10:03:01');
>12
months_between
返回date1和date2之间相差的月份
select months_between('2020-06-01','2020-07-01');
>-1
named_struct
相比struct可以取别名,示例:
select named_struct('a',1,'b','aaa','c',FALSE) from tablename;
>{"a":1,"b":"aaa","c":false}
negative
返回 a的相反数,示例:
select negative(-5);
>5
next_day
返回当前时间的下一个星期X所对应的日期,示例
select next_day('2015-01-14','TU');
>2015-01-20
ngrams
统计相同单词数量,倒序取top k,示例:
select ngrams(sentences('hello word!hello hive,hi hive,hello hive'),1,1);
>[{"ngram":["hive"],"estfrequency":3.0}]
/*
noop
noopstreaming
noopwithmap
noopwithmapstreaming
**/ 无意义函数
not
如果A为false,或者A为null,则为true,否则为false
select 1 from dul where not 1=2
>1
ntile
将有序分区划分为x个称为存储桶的组,并为该分区中的每一行分配存储桶编号。 (此方式存储可以快速计算分位数)
nvl
如果value值为null,就返回default_value,示例:
select nvl(null,5);
>5
or
A与B,任意一个或2个为true,则为true,否则为false
select 1 from dul where 1=2 or 2=2
>1
parse_url
返回URL中指定的部分。partToExtract的有效值为:HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, and USERINFO.
select select parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'HOST');
>facebook.com
select parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'QUERY','k1');
>v1
select parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'PATH');
>/path1/p.php
parse_url_tuple
返回从URL中抽取指定N部分的内容,参数url是URL字符串,⽽参数p1,p2,…是要抽取的部分,这个参数包含HOST, PATH,
QUERY, REF, PROTOCOL, AUTHORITY, FILE, USERINFO, QUERY:
percent_rank
含义就是 当前行-1 / 当前组总行数-1
percentile
求准确的第pth个百分位数,p必须介于0和1之间,但col字段目前只支持整数,
percentile_approx
求近似的第pth个百分位数,p必须介于0和1之间,返回类型为double,但是col字段⽀持浮点类型。参数B控制内存消耗的近似精
度,B越⼤,结果的准确度越⾼。默认为10,000。当col字段中的distinct值的个数⼩于B时,结果为准确的百分位数。
之后后⾯可以输⼊多个百分位数,返回类型也为array,其中为对应的百分位数
pi
圆周率π
select pi();
>3.141592653589793
pmod
返回正的a除以b的余数,a,b可为int/double
select pmod(9,4);
>1
posexplode
对于a中每个元素,将生成一行且包含改元素,同时还返回各元素的行号,通常用来炸裂多列
positive
返回a
select positive(-10);
>-10
pow
返回a的p次幂,举例:
select pow(2,4) ;
> 16.0
power
返回以 a 的 p 次幂,与 pow 功能相同
select power(2,4) ;
> 16.0
printf
按照printf风格格式输出字符串,示例:
select printf('abfhg');
>abfhg
quarter
返回当前时间属于哪个季度
select quarter('2015-04-08');
>2
radians
角度值转换成弧度值,返回a的弧度值
select radians(57.29577951308232);
>1.0
rand
返回一个0到1范围内的随机数。如果指定种子seed,则会返回固定的随机数,示例:
select rand();
>0.5577432776034763
rank
开窗排序函数
reflect
– 反射调用
select reflect("java.lang.Math","min",100,200);
>100
/*
reflect2
*/
regexp
如果字符串A或者字符串B为NULL,则返回NULL;如果字符串A符合JAVA正则表达式B的正则语法,则为TRUE;否则为FALSE。
select 'football' regexp '^footba';
>true;
select regexp('football', 'ba');
>true
regexp_extract
返回字符串subject与正则表达式pattern匹配后的index部分。例如:
select regexp_extract('100-300', '(d+)-(d+)', 2)
>300
regexp_replace
将字符串subject与正则表达式pattern匹配上部分用REPLACEMENT进行替换并返回。例如:
select regexp_replace('100-200', '(d+)', 'num')
>'num-num'
repeat
将字符串str重复n次,示例:
select repeat('a',3);
>'aaa'
replace
替换字符串中指定的字符串,示例:
select replace('abcdefg','d','')
>'abcefg'
reverse
反转字符串,示例:
select reverse("abcedfg");
>gfdecba
rlike
rlike 相比于like 支持正则表达式,示例:
select 'foobar' rlike 'foo';
>true
round
返回指定精度d的double类型
select round(3.1415926,4);
> 3.1416
row_number
开窗排序函数
rpad
与lpad对应,将str截取长度len位,若str长度不足len则,右用pad补充。例如:
select rpad('abcdef', 5, 'a')
>'abcde'
select rpad('abc', 5, 'a')
>'abcaa'
rtrim
出去字符串右边的空格,示例:
select rtrim('abc ');
>'abc'
second
返回日期中的秒
select second('2022-10-01 12:22:23');
>23
sentences
entences(string str, string lang, string locale)
将字符串str按照句子划分成单词。其中每个句子为一个数组,句子中单词为数组中元素。lang和locale为可选参数。其中lang为语言选项(如:'en’代表英文),locale代表地区。例子:
select sentences('Hello there! How are you?')
>( ('Hello', 'there'), ('How', 'are', 'you') )
sha
Hive1.3.0起,计算字符串或二进制的SHA-1摘要,并以十六进制字符串的形式返回。
sha1
Hive1.3.0起,计算字符串或二进制的SHA-1摘要,并以十六进制字符串的形式返回。
sha2
Hive1.3.0起,计算SHA-2系列哈希函数(SHA-224, SHA-256, SHA-384, and SHA-512)。第二个参数为结果的位数,只能是224、256(0)、384或512.java8+支持224。如果参数为null或位数不合法则返回null。
shiftleft
按位左移
select shiftleft(1,3)
>8
shiftright
按位右移
select shiftright(8,3)
>1
shiftrightunsigned
无符号按位右移动
select shiftrightunsigned(8,3)
>1
sign
如果a是整数则返回1.0,是负数则返回-1.0,否则返回0.0
select sign(-4);
>-1.0
sin
返回a的正弦值,示例:
select sin(0.8);
>0.7173560908995228
size
返回array类型的长度
select size(array('100','101','102','103'))
>4
sort_array
按照自然顺序对数组进行排序并返回
soundex
返回字符串的soundex代码。例如:
select soundex('Miller');
>M460
space
返回指定的空格个数
select space(3);
>' '
split
按照正则表达式pat拆分字符串str。例如:
select split('a,b,c,d',',');
>['a','b','c','d']
sqrt
返回a的平方根,示例
select sqrt(16);
>4
stack
stack(int n,k1,…)
n设为3,将后面6个元素按顺序分为3行2列
select stack(3,1,2,3,4,5,6);
col0 col1
1 2
3 4
5 6
n设为3,将后面7个元素按顺序分为3行3列
select stack(3,1,2,3,4,5,6,7);
col0 col1 col2
1 2 3
4 5 6
7 NULL NULL
std
std函数计算一组数据的样本标准差,用于估计整个数据集的标准差。它基于一组样本数据,将每个数据点与数据集的平均值之差的平方求和,然后除以样本数量减一,最后取平方根。
stddev
stddev函数计算一组数据的总体标准差,用于准确估计整个数据集的标准差。它与std函数类似,但是将每个数据点与数据集的平均值之差的平方求和后直接取平方根,
stddev_pop
该函数计算总体标准偏离,并返回总体变量的平⽅根,其返回值与VAR_POP函数的平⽅根相同(求指定列数值的标准偏差)
stddev_samp
该函数计算样本标准偏离,(求指定列数值的样本标准偏差)
str_to_map
将text分割为数个键值对。其中delimiter1和delimiter2为可选参数。delimiter1(默认为’:’)代表键k与值v的分隔符。delimiter2(默认为’,’)代表键值对k-v之间的分隔符。例如:
select str_to_map('column1:1,column2:2'},':',',')
>{'column1':'1','column2':'2'}
struct
使用给定的表达式,构造一个 struct 数据结构
substr
返回字符串A从start位置到结尾的字符串,举例:
select substr('abcde',3);
> cde
substring
返回字符串A从start位置开始,长度为len的字符串
举例:
hive> select substr('abcde',3,2);
cd
substring_index
截取第count分隔符之前的字符串,如count为正则从左边开始截取,如果为负则从右边开始截取
select substring_index('a,b,c',',',1);
>a
sum
聚合累加函数,示例
select sum(a) from (select 1 union all select 2) t
>3
tan
返回a的反正切值,示例:
select tan(0.8);
>1.0296385570503641
to_date
将标准格式时间戳转成日期格式,实例:
select to_date('2022-06-21 13:21:13') from dual;
>'2022-06-21'
to_unix_timestamp
unix时间戳timestamp转成当前时区时间格式format,示例:
select from_unixtime(1123240993,'yyyy-MM-dd HH:mm:ss') from dual;
> 2005-08-05 19:23:13
to_utc_timestamp
如果给定的时间戳指定的时区下时间戳,则将其转化成UTC下的时间戳
select to_utc_timestamp('1970-01-01 08:00:00','PST');
>1970-01-01 00:00:00
translate
translate(string|char|varchar input, string|char|varchar from, string|char|varchar to)
将input字符串中出现在from中的每个字符替换为to中的相应字符以后的字符串。 若from比to字符串长,那么在from中比to中多出的字符将会被删除。与PostgreSQL中对应函数等价。例如:
select translate('abcdefga','abc','wo')
>'wodefgw'
trim
去除左右空格
select trim(' abc ')
>'abc'
trunc
返回时间的最开始的年份或月份,示例:
select trunc('2016-6-26','MM');
>2016-06-01
select trunc('2016-6-26','YY');
>2016-01-01
ucase
将字符串转换成大写字母。示例:
select ucase('abc');
>ABC
unbase64
解码base64,示例:
select unbase64('YWJjOjEyMw==');
>abc:123
unhex
返回十六进制字符串代码的字符串,hex的逆方法,示例:
select unhex('616263');
>'abc'
unix_timestamp
获取当前时区的unix时间戳,示例
select unix_
upper
将小写转大写,示例
select upper('a')
>A
uuid
生成随机字符串函数,示例:
select uuid();
>42bd1f4d-b0a6-4b48-a5dc-6142ffab5ba1
var_pop
统计结果集中非空集合的总体变量(忽略null)
var_samp
统计结果集中非空集合的样本变量(忽略null)
variance
返回组内查询列的方差(也可称为总体方差),也可写成var_pop(col)
version
查看hive的版本
select version();
weekofyear
返回日期在当年的周数
select weekofyear('2019-06-21 12:11:22') from dual;
>25
when
条件判断,示例:
select case 1 when 1 then 'a' else 'b' end from dul;
>'a'
windowingtablefunction
所有开窗函数的基础
xpath
返回一个 Hive 字符串数组,UDF 与模式无关 - 不执行 XML 验证。 但是,格式错误的 xml(例如,1)将导致抛出运行时异常。
select xpath('<a><b>b1</b><b>b2</b></a>','a/*/text()');
>[b1","b2]
select xpath('<a><b id="foo">b1</b><b id="bar">b2</b></a>','//@id')
>['foo', 'bar']
SELECT xpath ('<a><b class="bb">b1</b><b>b2</b><b>b3</b><c class="bb">c1</c> <c>c2</c></a>', 'a/*[@class="bb"]/text()');
>[b1","c1]
xpath_boolean
如果 XPath 表达式的计算结果为 true,或者找到匹配的节点,则返回 true。
SELECT xpath_boolean ('<a><b>b</b></a>', 'a/b = "b"')
>true
SELECT xpath_boolean ('<a><b>b</b></a>', 'a/b')
>true
xpath_int/xpath_long/xpath_short/xpath_number/xpath_float/xpath_double
这些函数返回一个整数数值,如果没有找到匹配项,或者找到匹配项但该值不是数字,则返回零值。支持数学运算。如果值溢出返回类型,则返回该类型的最大值.
SELECT xpath_int ('<a><b class="odd">1</b><b class="even">2</b><b class="odd">4</b><c> 8</c></a>', 'sum(a/*)')
>15
SELECT xpath_int ('<a><b class="odd">1</b><b class="even">2</b><b class="odd">4</b><c> 8</c></a>', 'sum(a/b)')
>7
SELECT xpath_int ('<a><b class="odd">1</b><b class="even">2</b><b class="odd">4</b><c> 8</c></a>', 'sum(a/b[@class="odd"])')
>5
SELECT xpath_double ('<a><b>2000000000</b><c>40000000000</c></a>', 'a/b * a/c')
>8.0E19
SELECT xpath_double ('<a>这不是一个数字</a>', 'a')
>NaN
xpath_string
path_string() 函数返回第一个匹配节点的文本。
SELECT xpath_string ('<a><b>bb</b><c>cc</c></a>', 'a/b') #获取节点“a/b”的文本:
>bb
SELECT xpath_string ('<a><b>bb</b><c>cc</c></a>', 'a')#获取节点“a”的文本。因为 'a' 有带有文本的子节点,所以结果是来自子节点的文本的组合。
>bbcc
SELECT xpath_string ('<a><b>b1</b><b>b2</b></a>', '//b')#获取匹配 '//b' 的第一个节点的文本
>b1
SELECT xpath_string ('<a><b>b1</b><b>b2</b></a>', 'a/b[2]');#获取第二个匹配节点
>b2
SELECT xpath_string ('<a><b>b1</b><b id="b_2">b2</b></a>', 'a/b[@id="b_2"]');#从第一个具有属性 'id' 和值 'b_2' 的节点获取文本:
>b2
year
计算日期的年份,实例:
select year(2022-11-01)
>2022
|
逻辑运算符,实例:
select 1=1|2=1
>false
~