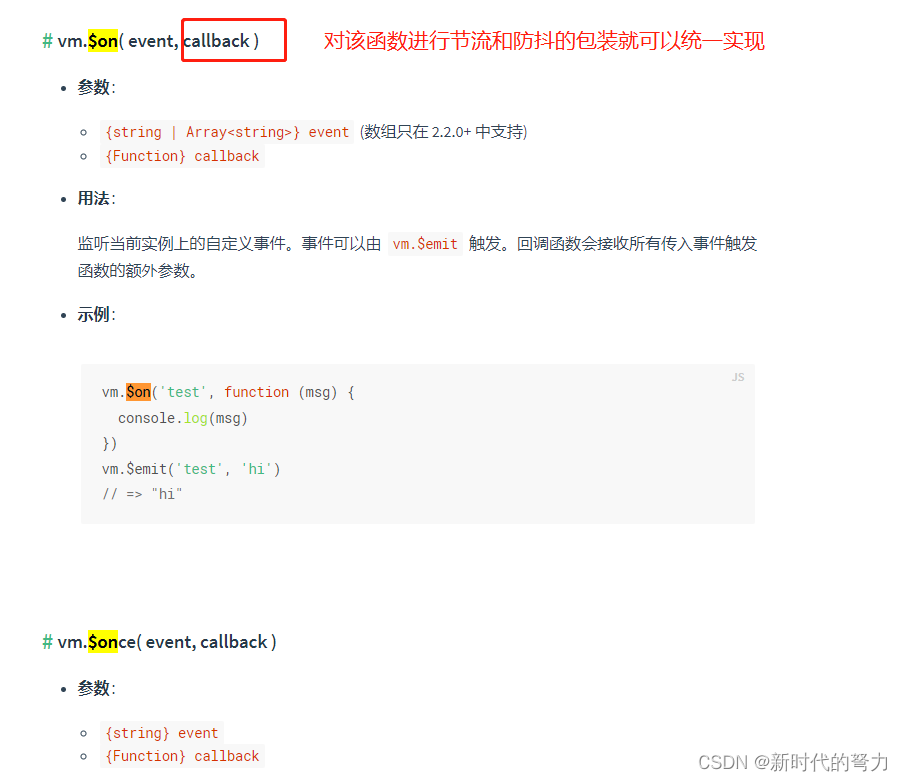
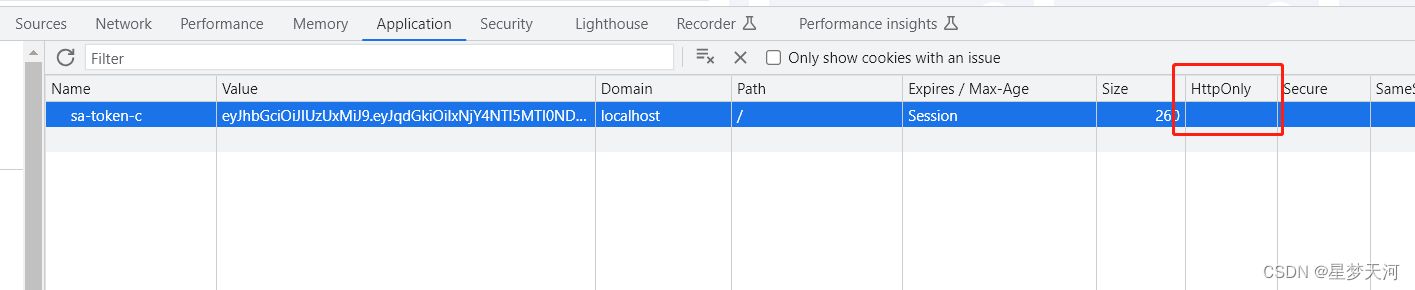
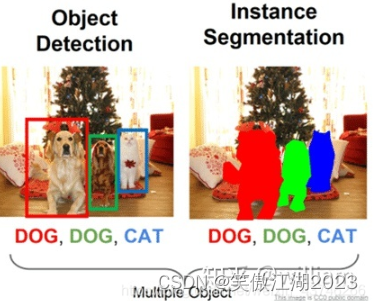
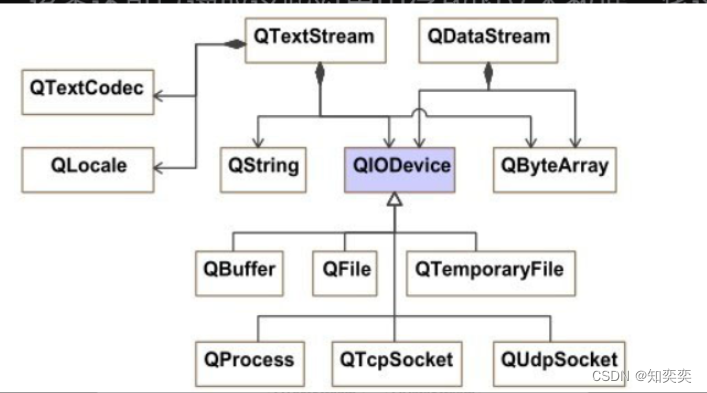
问题定义

anomaly,outlier, novelty, exceptions
不同的方法使用不同的名词定义这类问题。

应用

二分类

假如只有正常的数据,而异常的数据的范围非常广的话(无法穷举),二分类这些不好做。另外就是异常资料不太好收集。
分类
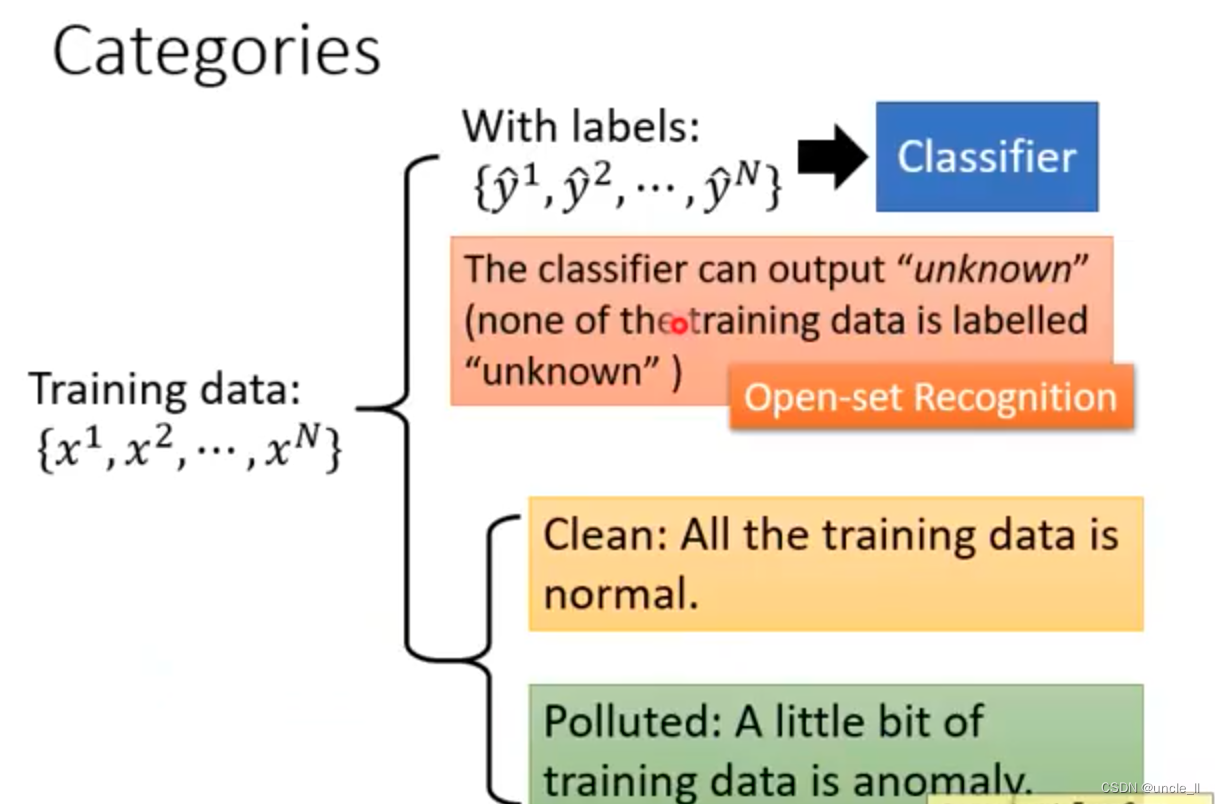

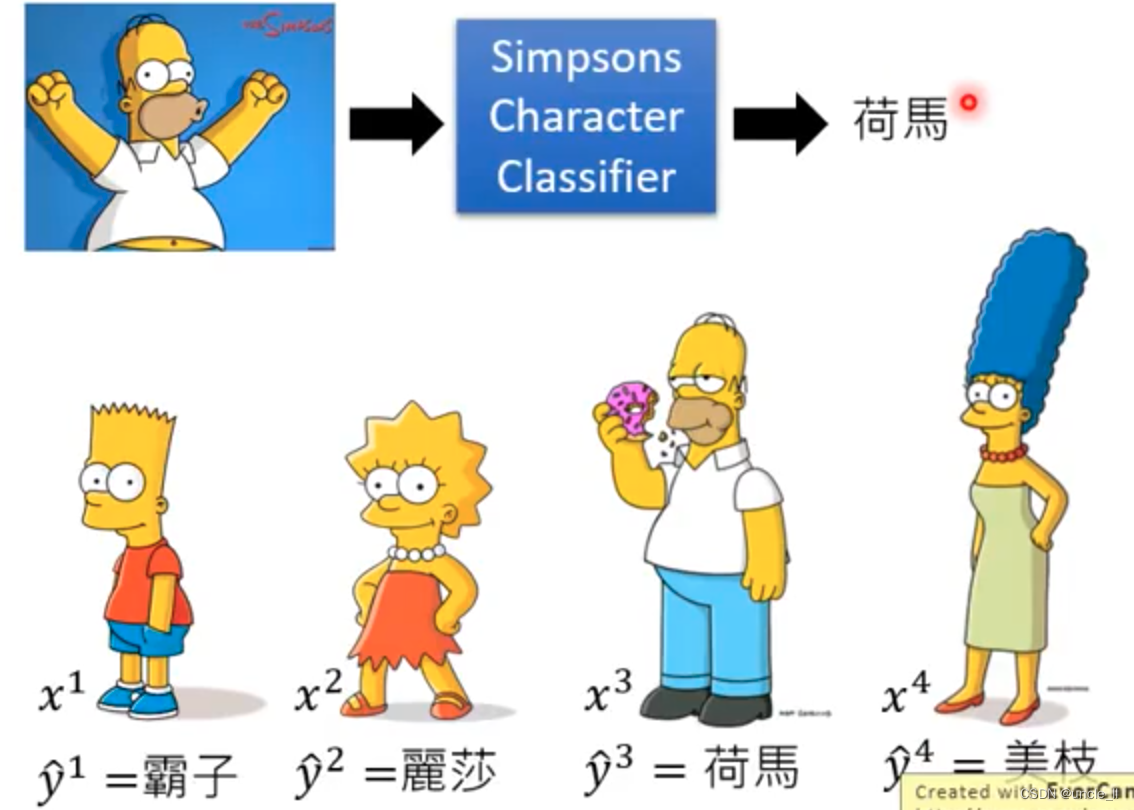
每张图片都有标注,就可以来训练一个辛普森家族的成员分类器。

基于classifer来做异常检测。
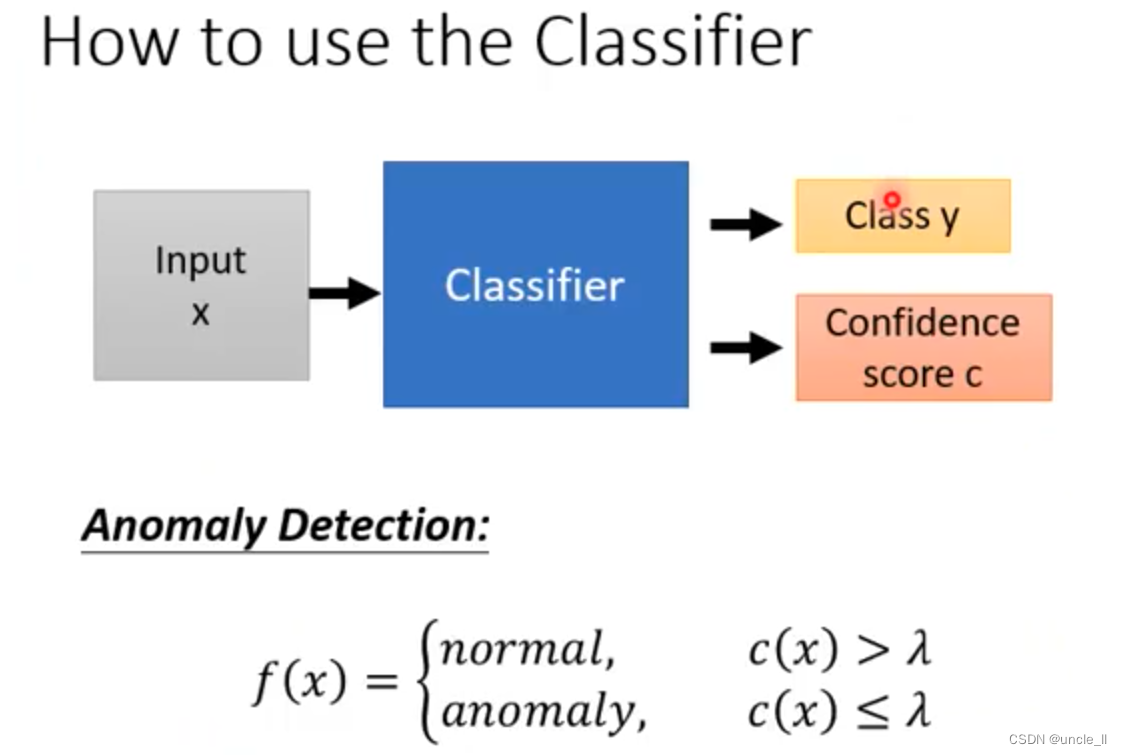
基于信心分数来做异常问题,大于某值就是正常,小于某值就是异常

最大分数作为confidence


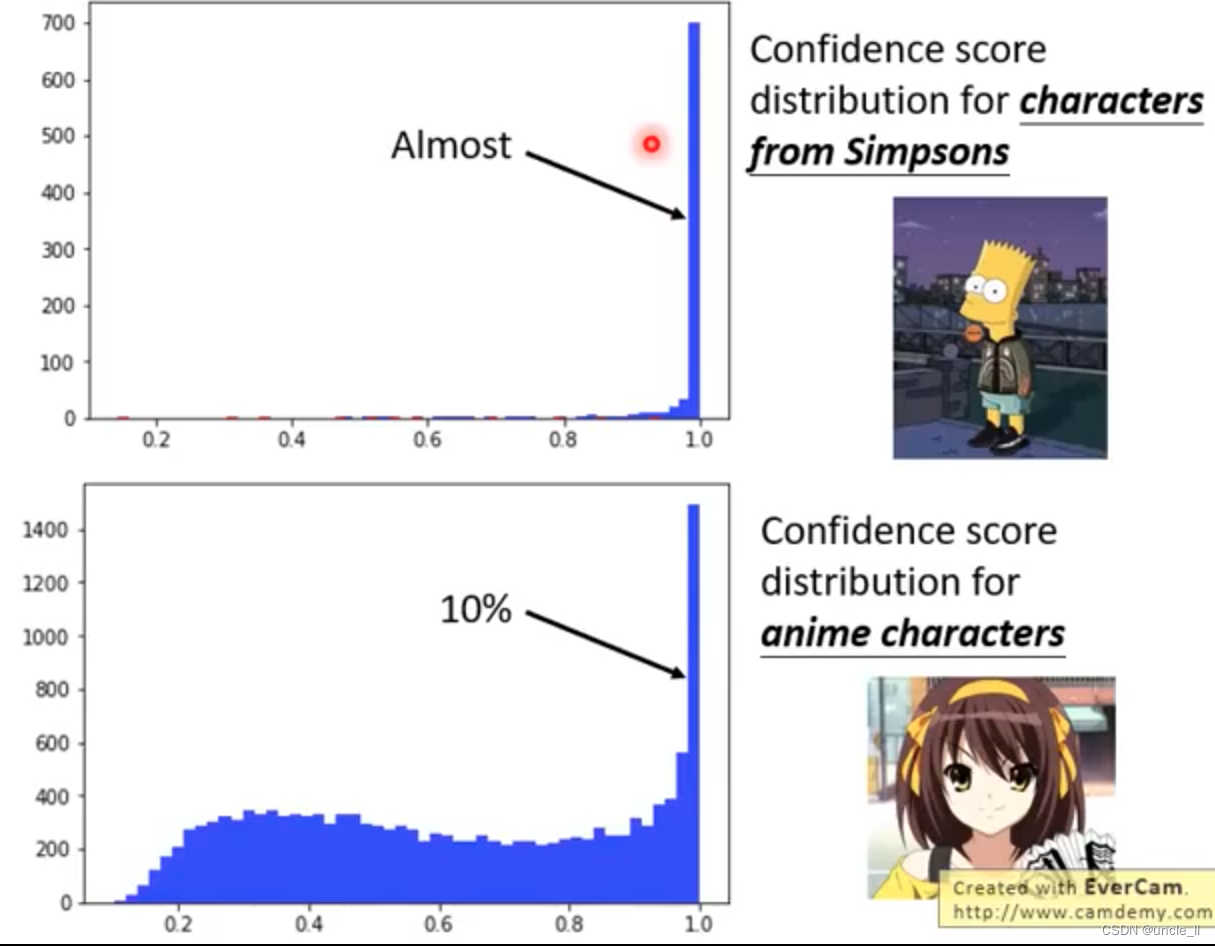
部分数据会有误判的情况
信心分估计

直接教网络信心分数,不仅是做分类任务C,也会给出信心分P
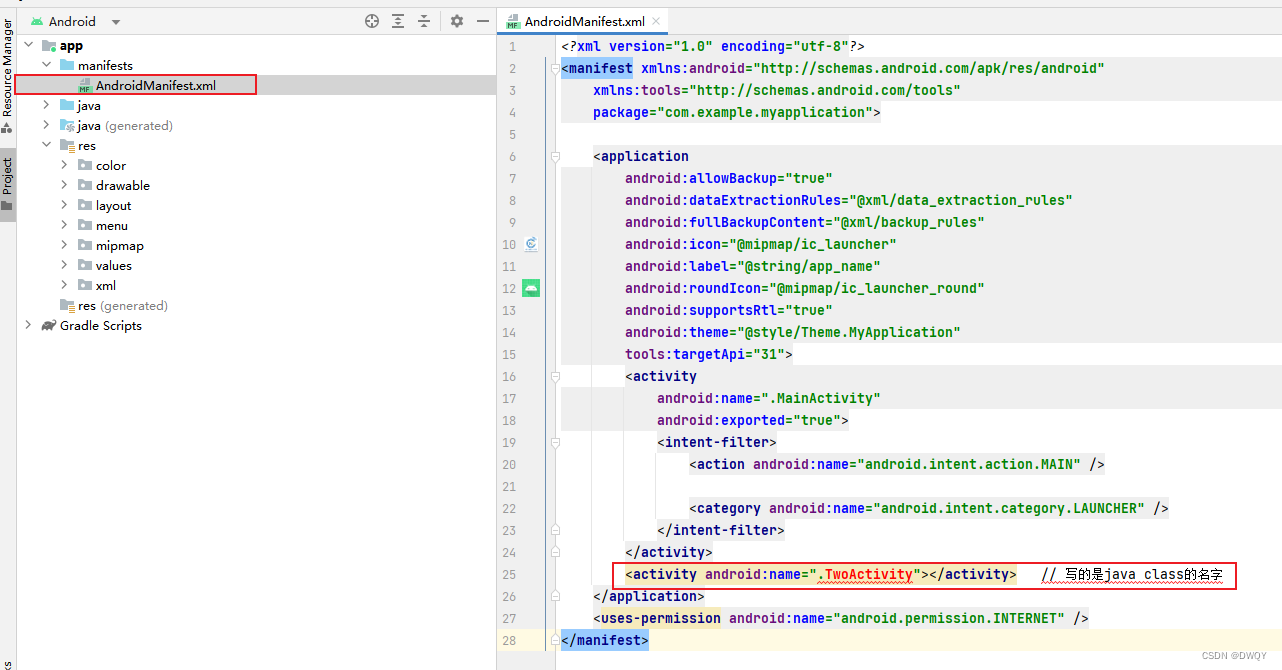
Train 和 Eval

100张辛普森家族图片,5张异常图片
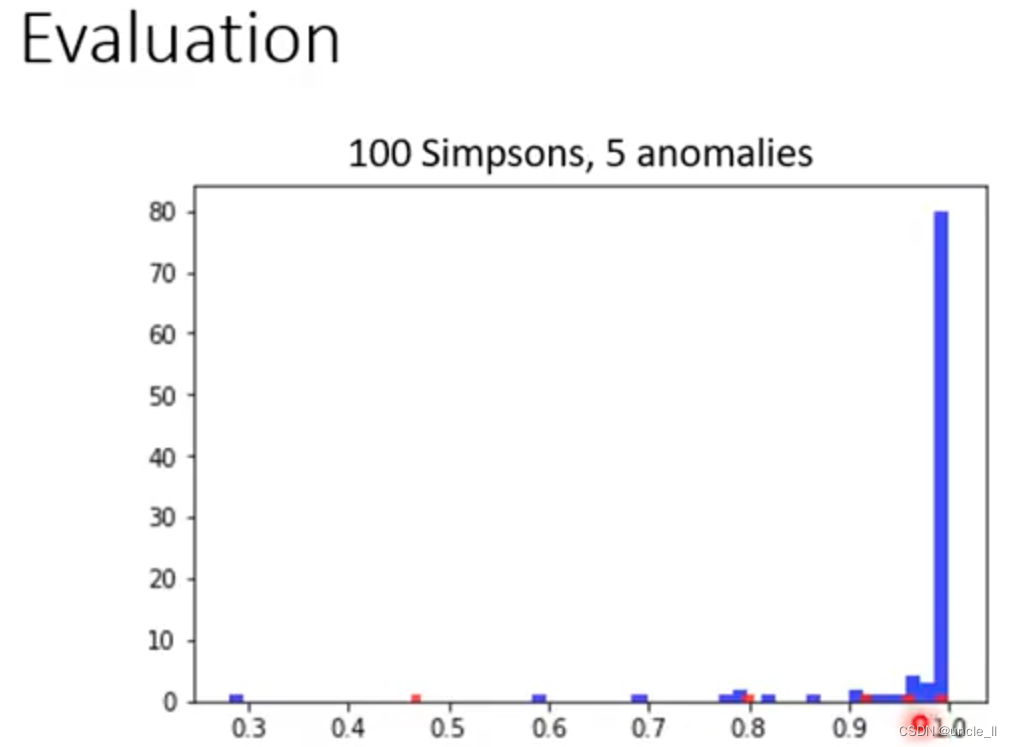
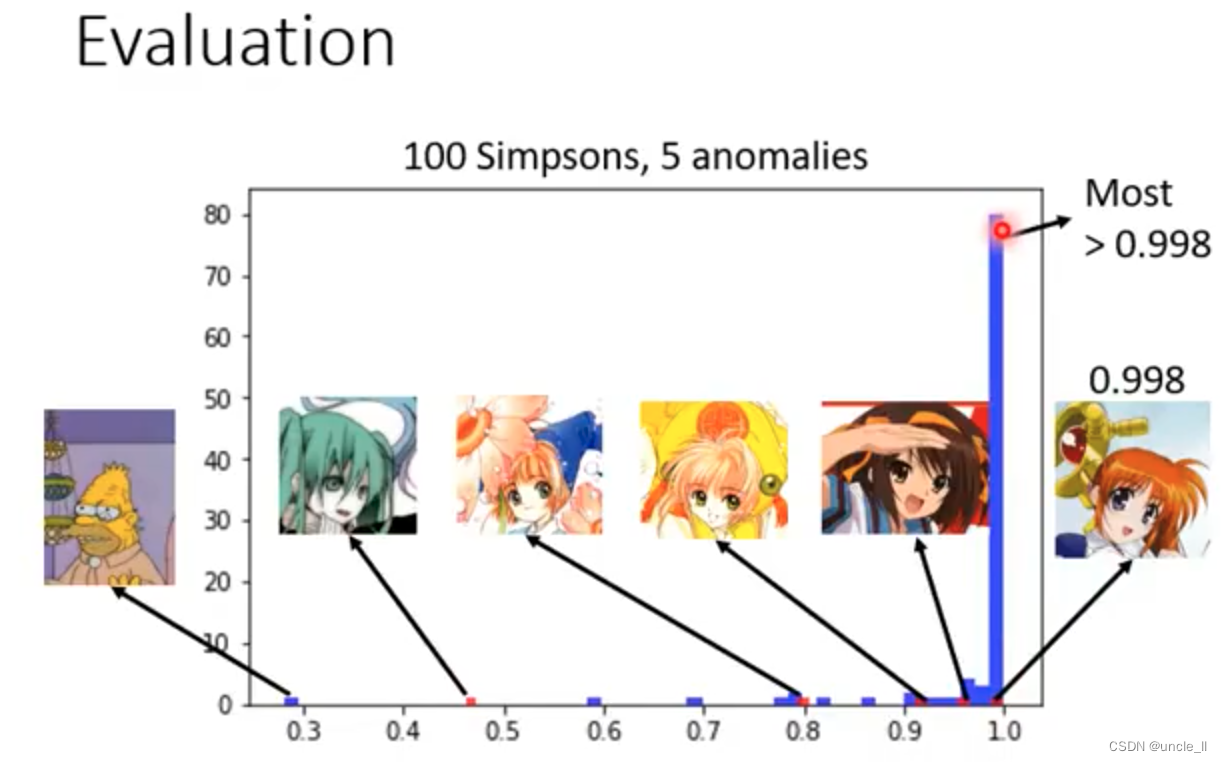
- 有蓝色的正常图被错误分类成异常
- 有红色的异常图被错误分类成正常
这个时候用dev set上评估系统,这是一个二元分类问题。
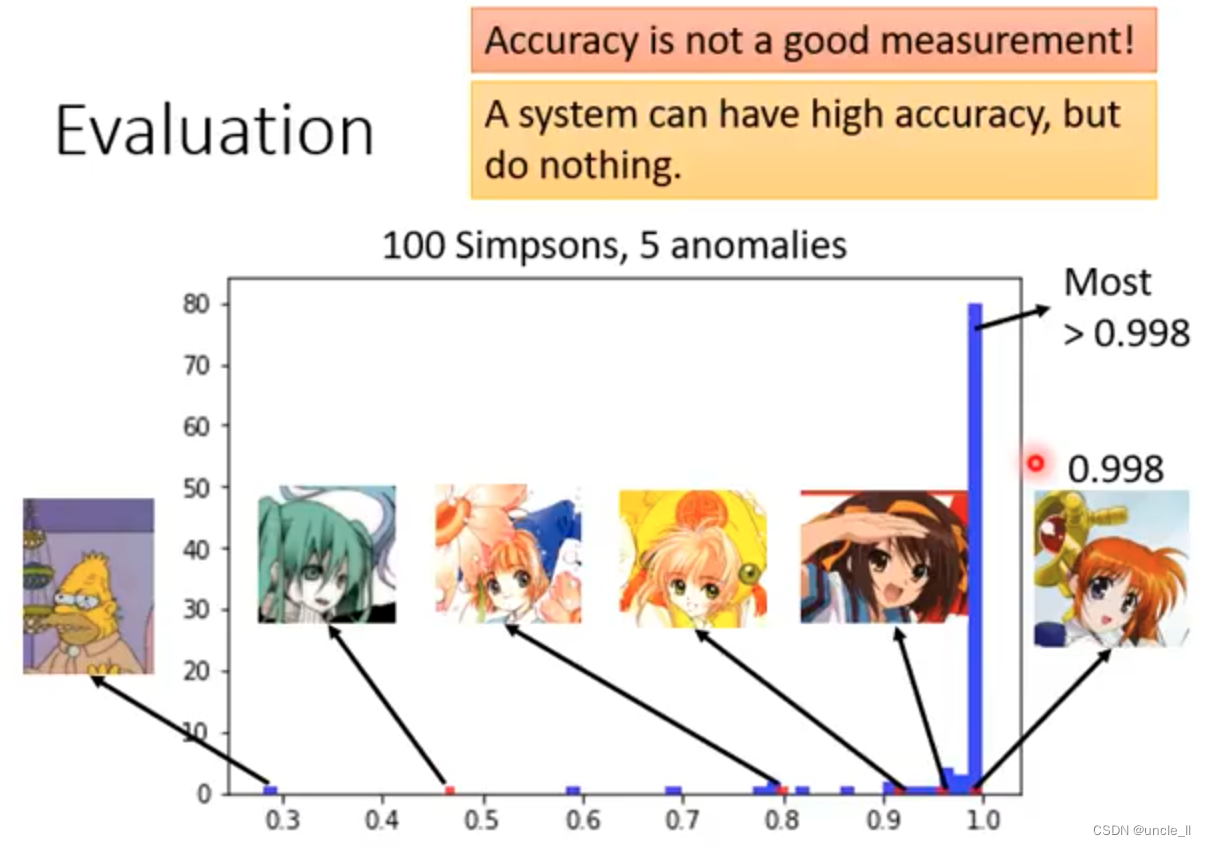
正常异常比例的分布是非常悬殊的,这个系统可以有很高的准确率,但是没有做什么事,用acc准确率分类是没有意义的。

使用混淆矩阵:
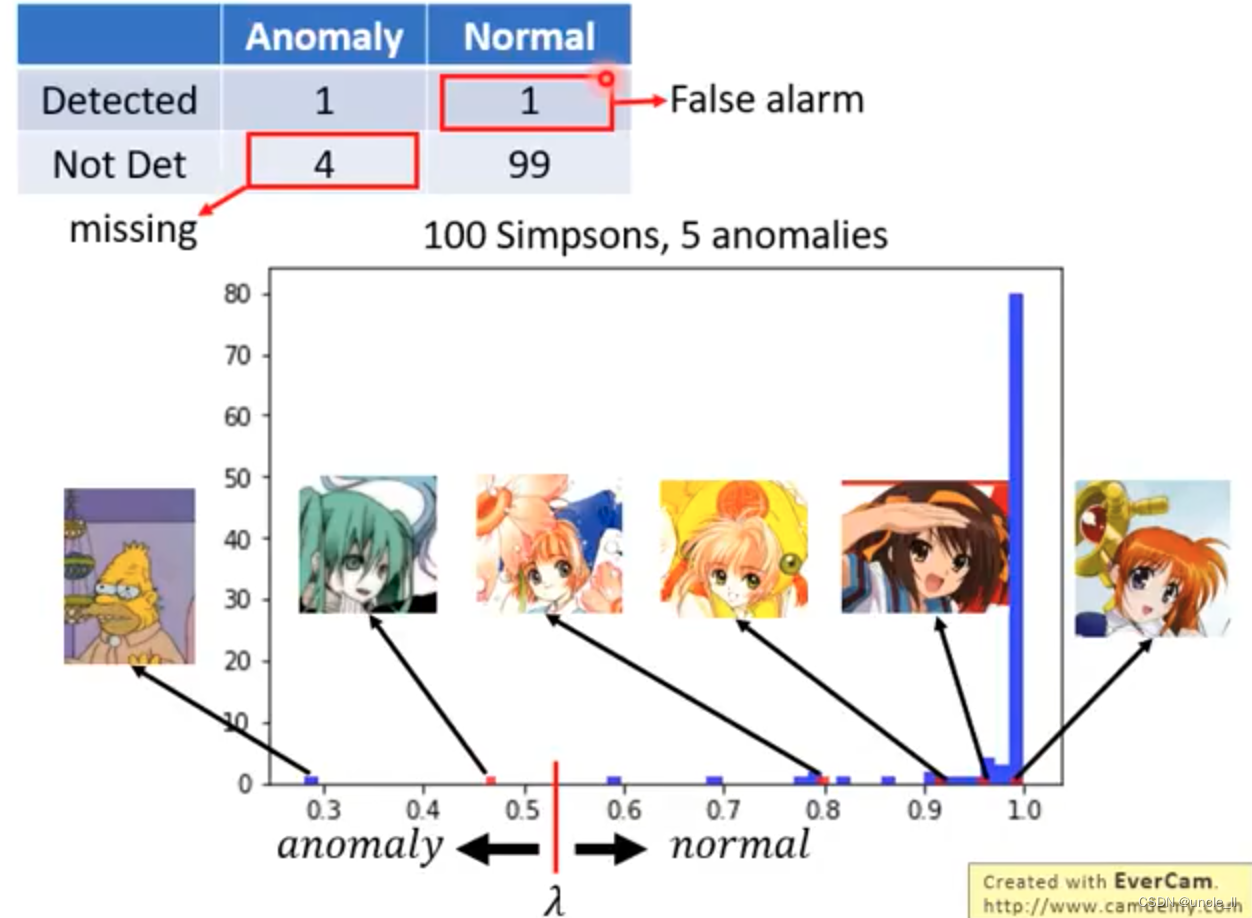

cost table,做错的行为的代价,算一个分数:
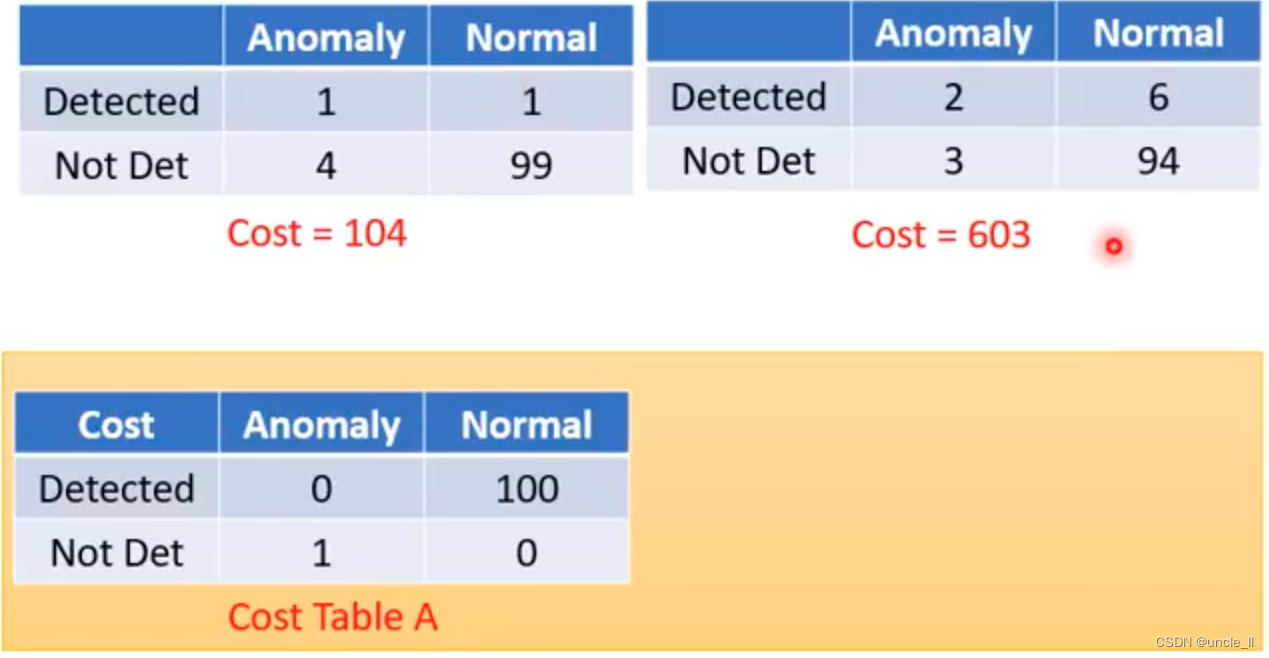
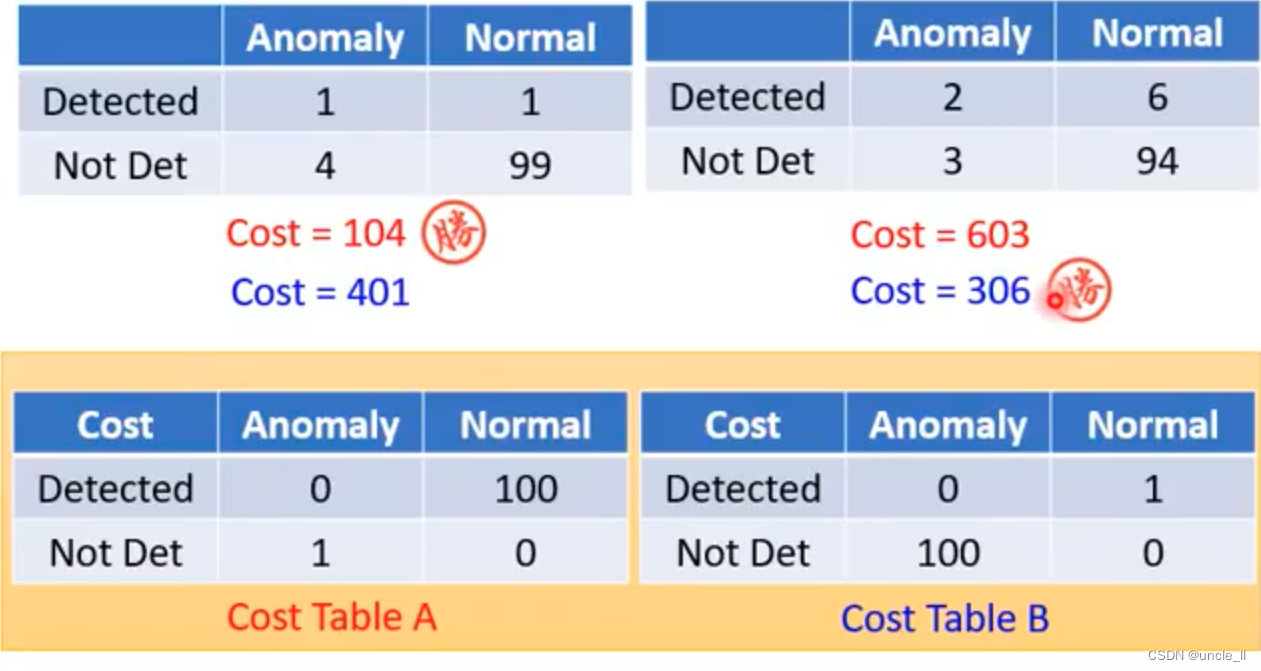
针对自己的任务设定cost table。还有一些方法来衡量,比如AUC(roc曲线的面积)。
问题


脸上是黄的,然后系统给的分数就高,说明这个分类系统学到的并不是认清人,而是脸是否是黄的。

假设可以收到一些异常资料,可以学习在分类的同时,也给出异常的分数,但是这类数据不易收集。可以考虑使用GAN生成异常数据。
没有标签的场景
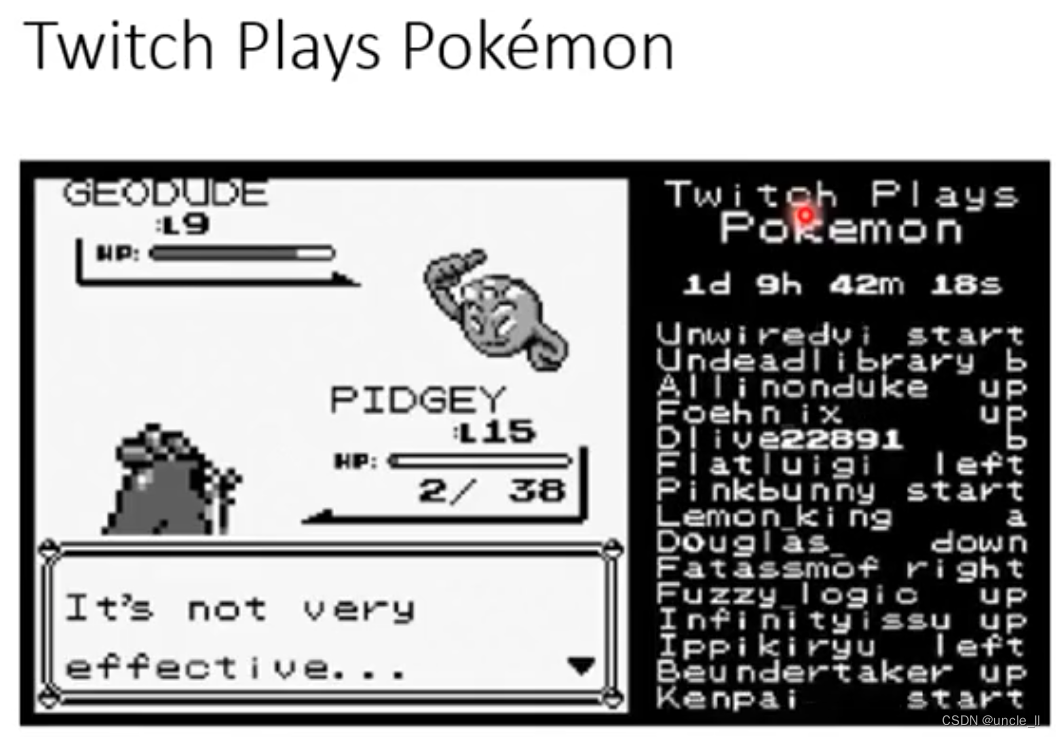

正常玩家和异常玩家(小白)
问题定义
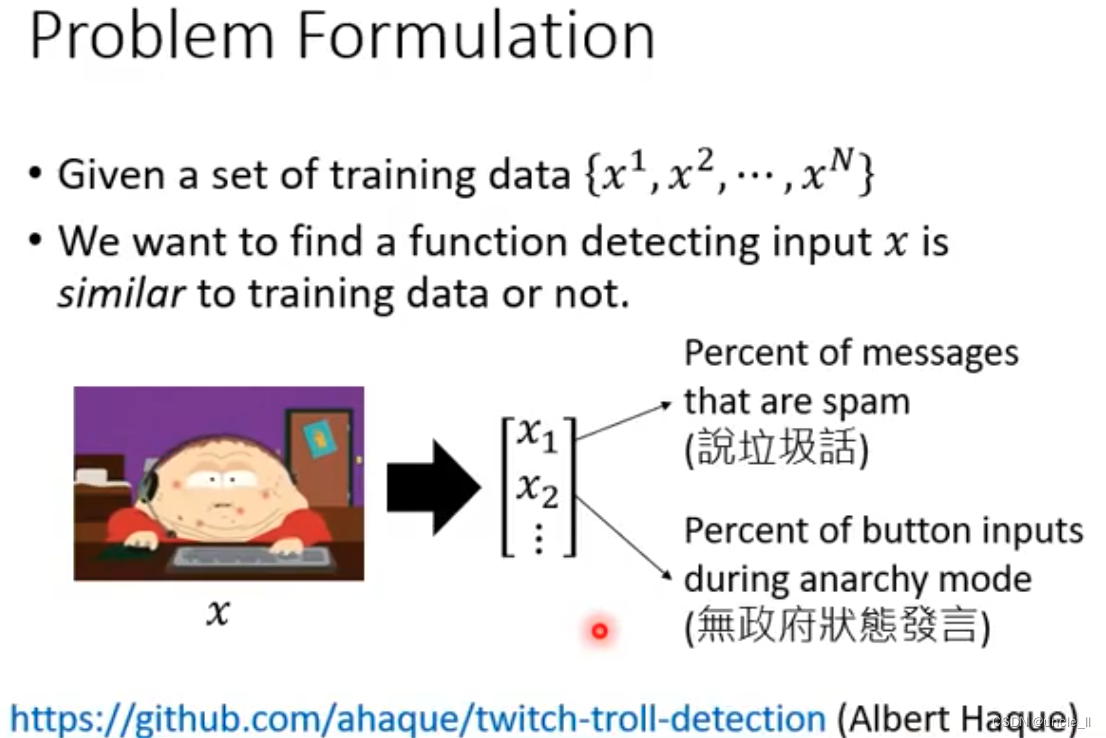
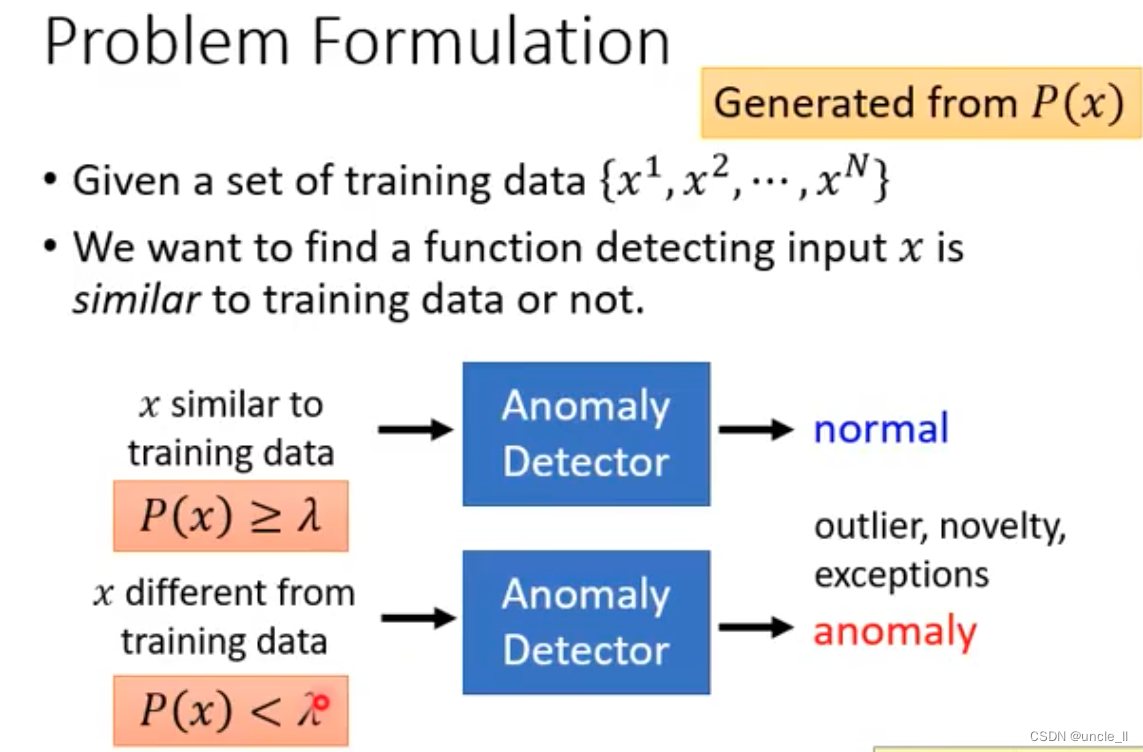
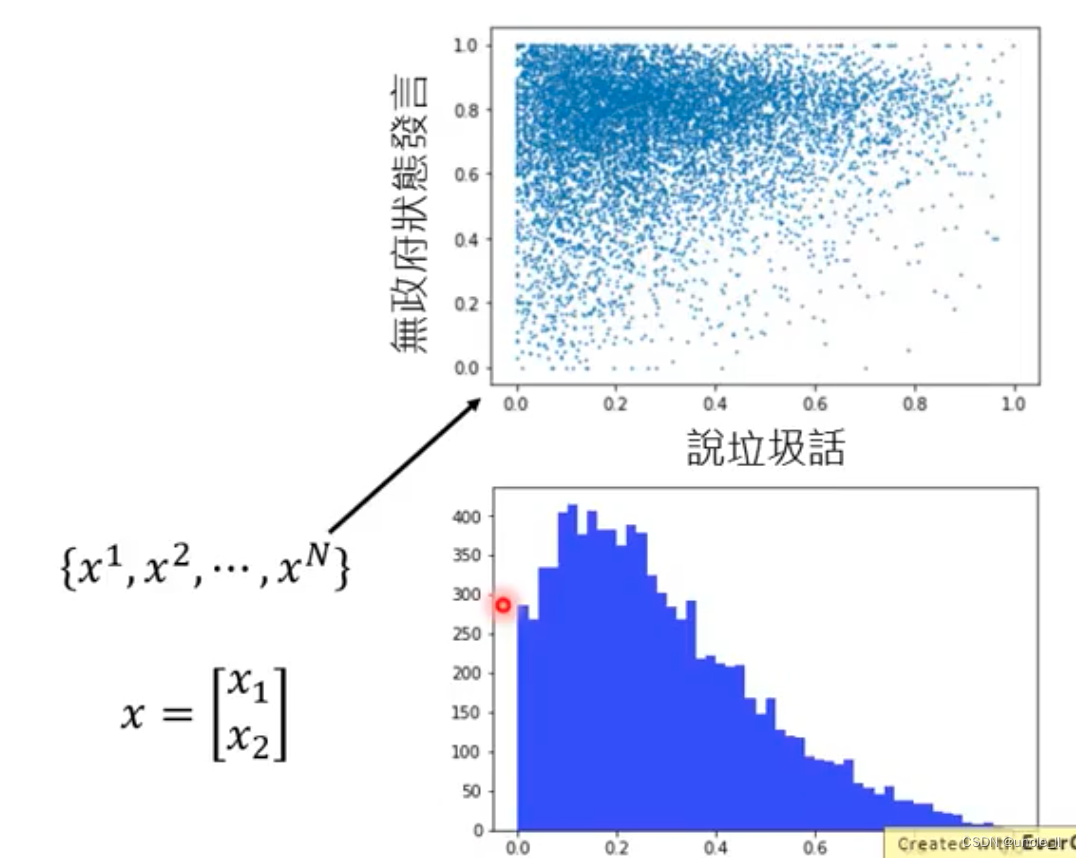
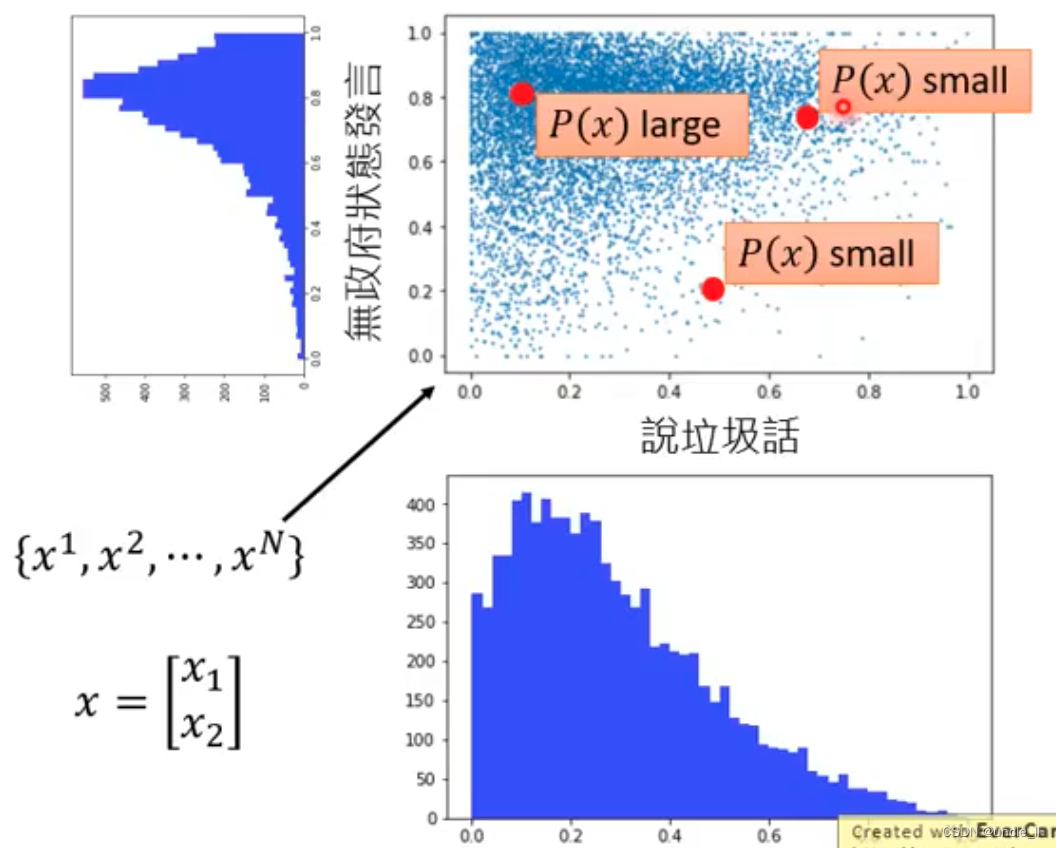
需要数值化的方法来给每一个玩家的分数。
f
(
斯塔
)
f(斯塔)
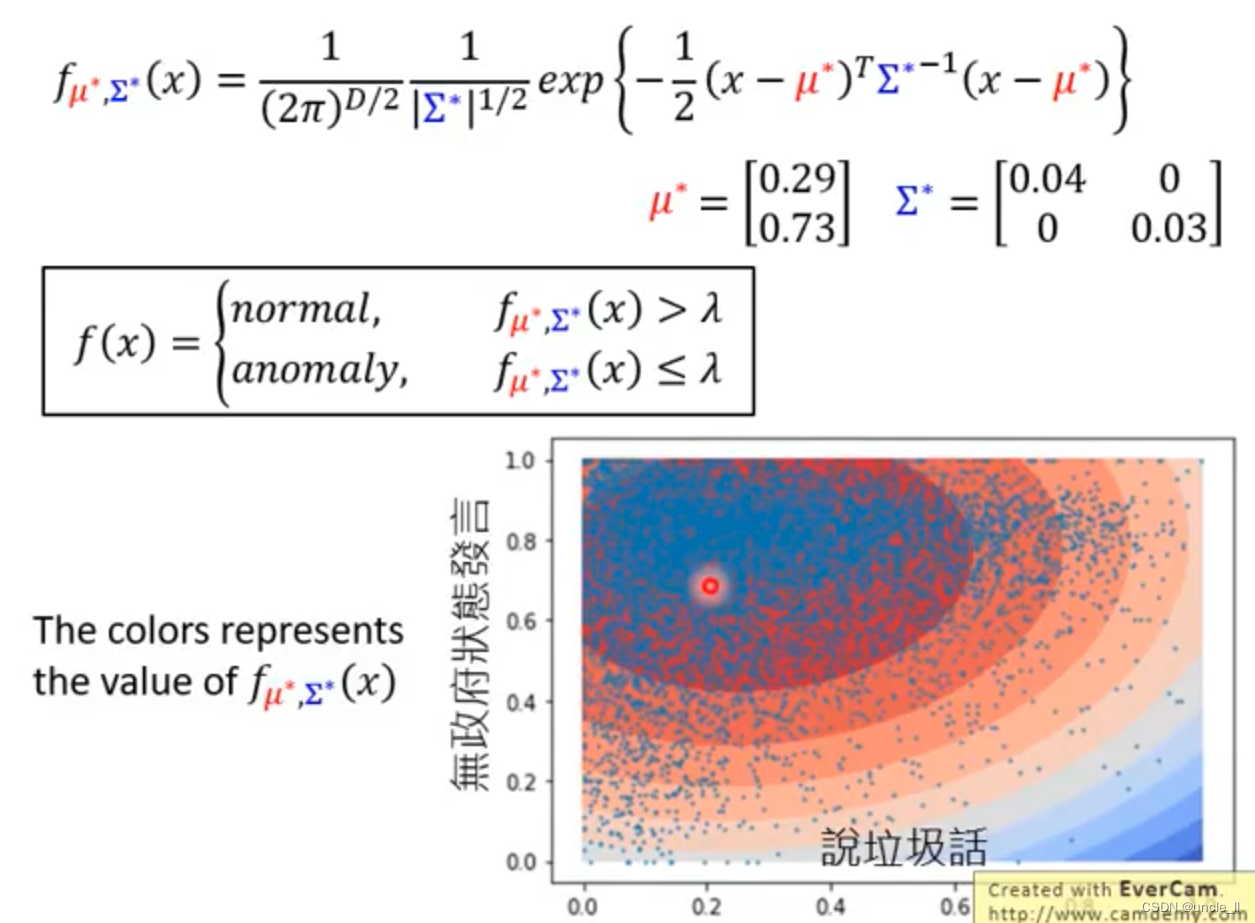
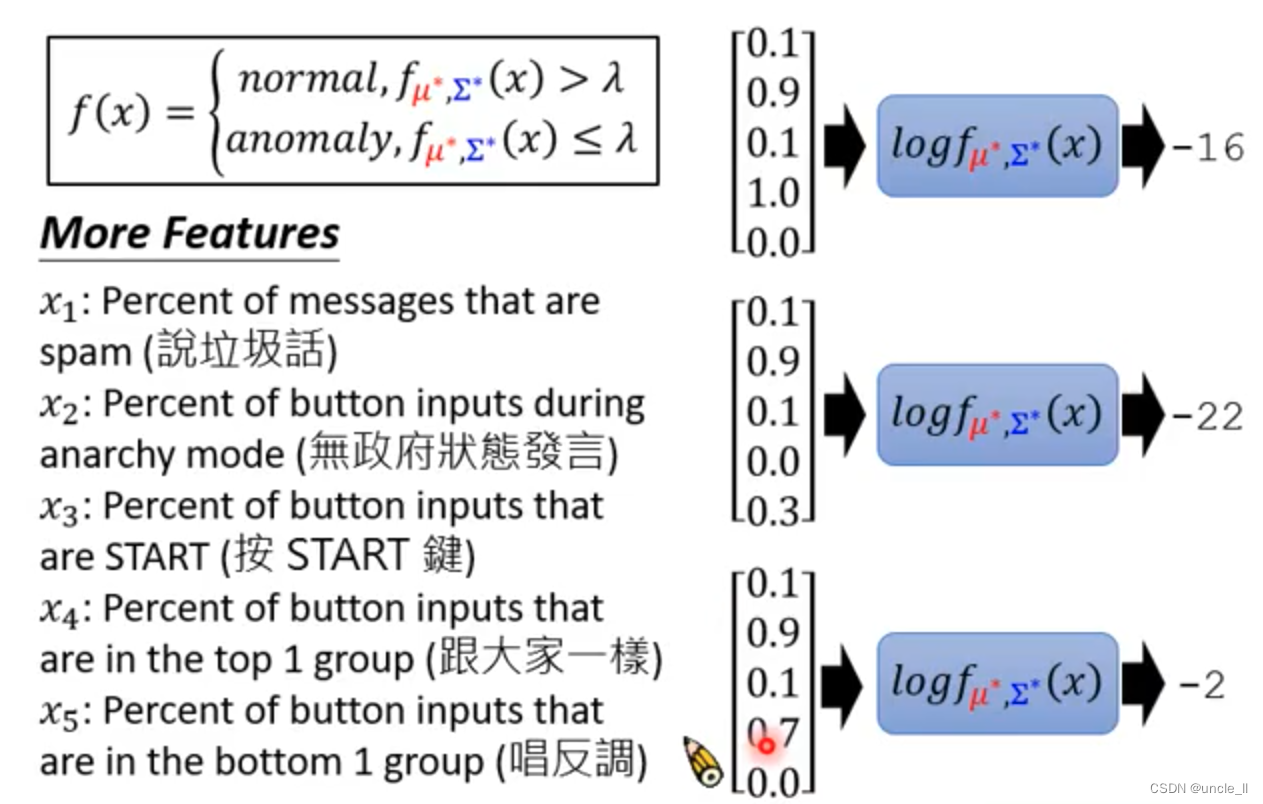
f(斯塔) 概率密度估计

高斯分布







![[计算机入门] 回收站](https://img-blog.csdnimg.cn/635ac290b1664de68a5ad97208d75901.png)