一、ChatGPT结合知识图谱
上篇文章对医疗数据集进行了整理,并写入了知识图谱中,本篇文章将结合 ChatGPT 构建基于知识图谱的问答应用。
下面是上篇文章的地址:
ChatGPT结合知识图谱构建医疗问答应用 (一) - 构建知识图谱
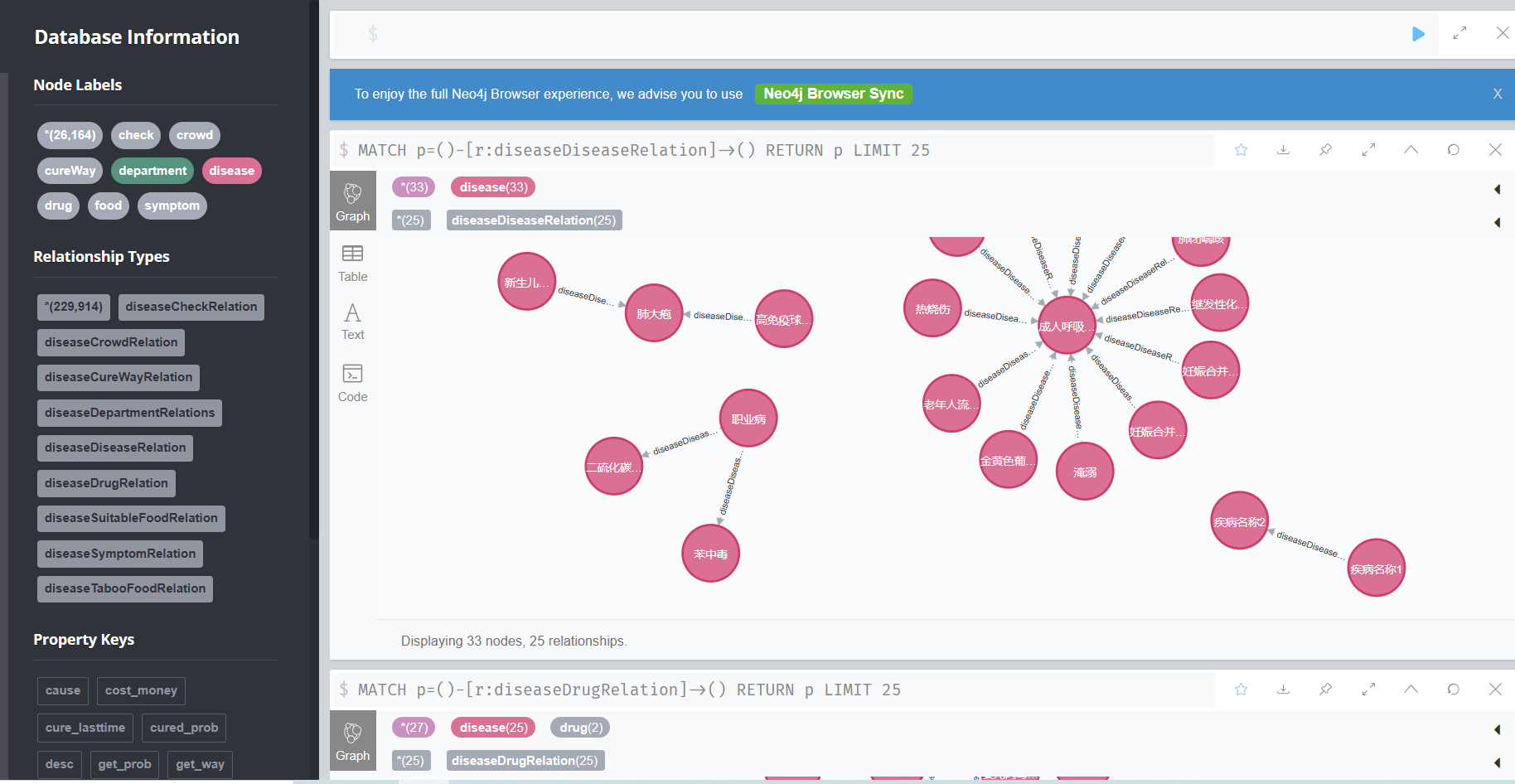
这里实现问答的流程如下所示:
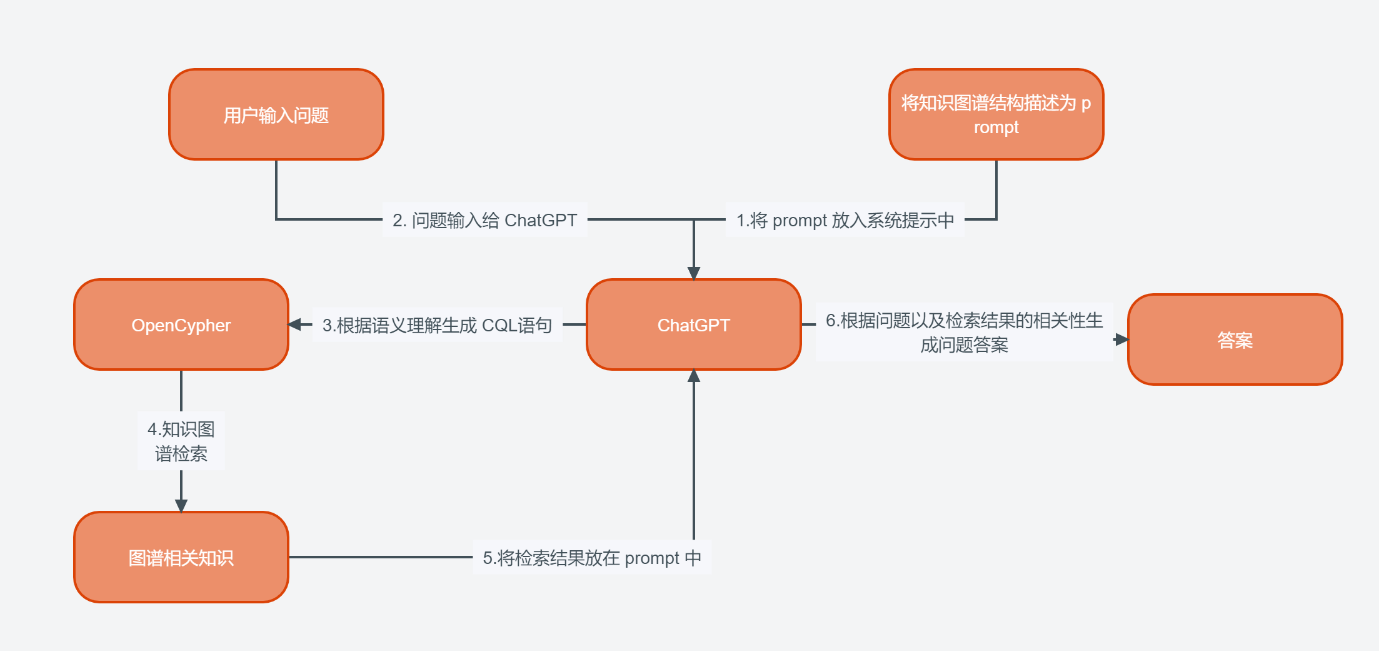
二、问答流程构建
opencypher_llm.py 根据问题理解生成 opencypher 语句
import os
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
import json
class OpenCypherLLM():
def __init__(self):
# 输出格式化
self.response_schemas = [
ResponseSchema(name="openCypher", description="生成的 OpenCypher 检索语句")
]
self.output_parser = StructuredOutputParser.from_response_schemas(self.response_schemas)
self.format_instructions = self.output_parser.get_format_instructions()
# prompt 模版
self.prompt = """
你是一个知识图谱方面的专家, 现有一个医疗相关的知识图谱,图谱中的实体解释如下:\n
--------------
disease:疾病,存储着各种疾病的基础信息\n
department:科室,疾病所对应的科室\n
symptom:疾病的症状\n
cureWay:疾病的治疗方式\n
check:疾病的检查项目\n
drug:疾病的用药\n
crowd:疾病易感染人群\n
food:食物,包括宜吃和忌吃食物\n
--------------\n
实体与实体之间的关系如下,每个关系都可以是双向的,v表示实体、e表示关系:\n
--------------\n
疾病科室关系:(v:disease)-[e:diseaseDepartmentRelations]->(v:department);
疾病症状关系:(v:disease)-[e:diseaseSymptomRelation]->(v:symptom);
疾病治疗关系:(v:disease)-[e:diseaseCureWayRelation]->(v:cureWay);
疾病检查项目关系:(v:disease)-[e:diseaseCheckRelation]->(v:check);
疾病用药关系:(v:disease)-[e:diseaseDrugRelation]->(v:drug);
疾病易感染人群关系:(v:disease)-[e:diseaseCrowdRelation]->(v:crowd);
疾病宜吃食物关系:(v:disease)-[e:diseaseSuitableFoodRelation]->(v:food);
疾病忌吃食物关系:(v:disease)-[e:diseaseTabooFoodRelation]->(v:food);
疾病并发症关系:(v:disease)-[e:diseaseDiseaseRelation]->(v:disease);
--------------\n
实体中的主要属性信息如下:\n
--------------\n
disease: {name:疾病名称,desc:疾病简介,prevent:预防措施,cause:疾病病因,get_prob:发病率,get_way:传染性,cure_lasttime:治疗周期,cured_prob:治愈概率,cost_money:大概花费}\n
department: {name:科室名称}\n
symptom: {name:疾病症状}\n
cureWay: {name:治疗方式}\n
check: {name:检查项目}\n
drug: {name:药物名称}\n
crowd: {name:感染人群}\n
food: {name:食物}\n
--------------
根据以上背景结合用户输入的问题,生成 OpenCypher 图谱检索语句,可以精准检索到相关的知识信息作为背景。\n
注意: 仅使用上述提供的实体、关系、属性信息,不要使用额外未提供的内容。实体与实体之间的关系仅使用背景给出的关系\n
"""
self.prompt = self.prompt + self.format_instructions
self.chat = ChatOpenAI(temperature=1, model_name="gpt-3.5-turbo")
def run(self, questions):
res = self.chat(
[
SystemMessage(content=self.prompt),
HumanMessage(content="用户输入问题:" + questions)
]
)
res = res.content
res = res.replace("```json", "").replace("```", "")
res = json.loads(res)
return res["openCypher"]
gc_llm.py 根据检索结果总结答案
import os
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage
from langchain import PromptTemplate
class GCLLM():
def __init__(self):
# prompt 模版
self.template = """
你是一个知识图谱方面的专家,图谱中的基本信息如下:\n
--------------
disease:疾病实体,存储着各种疾病的基础信息\n
department:科室,疾病所对应的科室\n
symptom:疾病的症状\n
cureWay:疾病的治疗方式\n
check:疾病的检查项目\n
drug:疾病的用药\n
crowd:疾病易感染人群\n
food:食物,存吃包括宜吃和忌吃食物\n
--------------\n
上一步你生成的 OpenCypher 语句为:
--------------\n
{OpenCypher}
--------------\n
OpenCypher 语句查询的结果如下:
--------------\n
{content}
--------------\n
结合上述背景,并回答用户问题,如果提供的背景和用户问题没有相关性,则回答 “这个问题我还不知道怎么回答”
注意:最后直接回复用户问题即可,不要添加 "根据查询结果" 等类似的修饰词
"""
self.prompt = PromptTemplate(
input_variables=["OpenCypher", "content"],
template=self.template,
)
self.chat = ChatOpenAI(temperature=1, model_name="gpt-3.5-turbo")
def run(self, OpenCypher, content, questions):
res = self.chat(
[
SystemMessage(content=self.prompt.format(OpenCypher=OpenCypher, content=content)),
HumanMessage(content="用户输入问题:" + questions)
]
)
return res.content
过程整合
from py2neo import Graph
from opencypher_llm import OpenCypherLLM
from gc_llm import GCLLM
import os
class QA():
def __init__(self, kg_host, kg_port, kg_user, kg_password):
self.graph = Graph(
host=kg_host,
http_port=kg_port,
user=kg_user,
password=kg_password)
self.openCypherLLM = OpenCypherLLM()
self.gcLLM = GCLLM()
def execOpenCypher(self, cql):
if "limit" not in cql and "LIMIT" not in cql:
cql = cql + " LIMIT 10 "
res = self.graph.run(cql)
list = []
for record in res:
list.append(str(record))
if len(list) == 0:
return ""
return "\n".join(list)
def run(self, questions):
if not questions or questions == '':
return "输入问题为空,无法做出回答!"
# 生成检索语句
openCypher = self.openCypherLLM.run(questions)
if not openCypher or openCypher == '':
return "这个问题我还不知道怎么回答"
print("========生成的CQL==========")
print(openCypher)
# 执行检索
res = self.execOpenCypher(openCypher)
print("========查询图谱结果==========")
print(res)
if not res or res == "":
return "这个问题我还不知道怎么回答"
return self.gcLLM.run(openCypher, res, questions)
if __name__ == '__main__':
kg_host = "127.0.0.1"
kg_port = 7474
kg_user = "neo4j"
kg_password = "123456"
qa = QA(kg_host, kg_port, kg_user, kg_password)
while True:
questions = input("请输入问题: \n ")
if questions == "q":
break
res = qa.run(questions)
print("========问题回答结果==========")
print(res)
三、效果测试
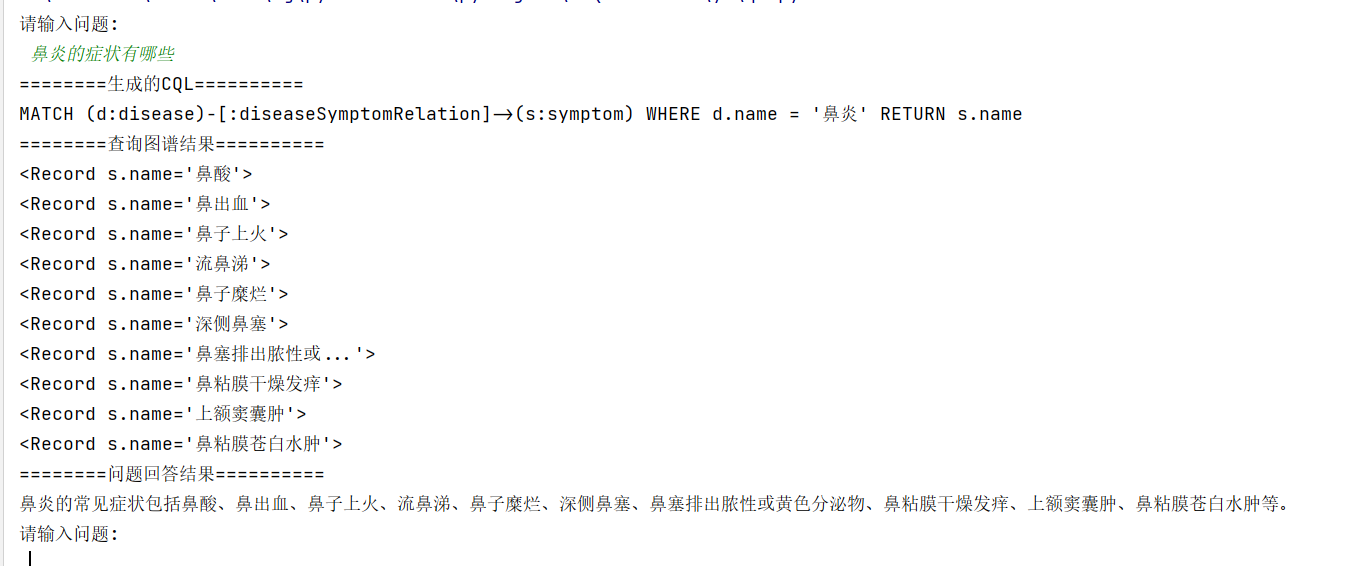
1. 鼻炎的症状有哪些
2. 鼻炎的治疗周期多久

3. 鼻炎不适合吃什么东西

3. 和鼻炎有类似症状的病有哪些

4. 鼻炎应该检查哪些项目

四、总结
上面基于医疗的知识图谱大致实现了问答的过程,可以感觉出加入ChatGPT后实现的流程非常简单,但上述流程也还有需要优化的地方,例如用户输入疾病错别字的情况如果 ChatGPT 没有更正有可能导致检索为空,还有就是有些疾病可能有多个名称但名称不在图谱中导致检索失败等等,后面可以考虑加入语义相似度的检索。