About ARTS - Complete one ARTS per week:
● Algorithm: Do at least one LeetCode algorithm per week
Review: Read and comment on at least one technical article in English
● Tips: Learn at least one technical trick
● Share: Share a technical article with opinions and thoughts
It is hoped that this event will gather a wave of people who love technology and continue the spirit of curiosity, exploration, practice and sharing.
---------------------------------------------------------------------------------------------------------------------------------
1. First, the content of learning
142. 环形链表 II - 力扣(LeetCode)
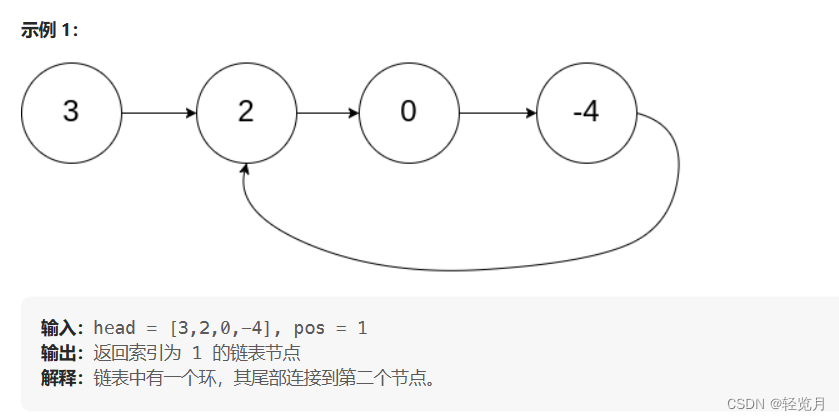
Given the head node of a linked list, return the first node from which the linked list began entering the ring. If the list is loopless, null is returned.
If there is a node in the linked list that can be reached again by continuously tracking the next pointer, then there is a ring in the linked list.To represent a ring in a given list, the evaluation system internally uses the integer pos to indicate the position in the list where the end of the list is connected (the index starts at 0). If pos is -1, then there are no rings in the list. Note: pos is not passed as a parameter, only to identify the actual condition of the linked list.
The linked list cannot be modified.
Read and comment on at least one technical article in English:
Joint global metric learning and local manifold preservation for scene recognition

Share a technical article with opinions and thoughts:
Joint global metric learning and local manifold preservation for scene recognition

With the rapid development of deep learning, a large number of scene recognition approaches have been proposed by exploring the deep features extracted from convolutional layers or fully connected layers. Liu et al. employed deep convolutional features to construct a mid-level dictionary based on sparse coding and a discriminative regularization. Khan et al. transformed the structured convolutional activations into a more discriminative feature space. Wang et al. proposed a multi-resolution CNN architecture aiming to capture visual content and structure from multiple levels. Tang et al. used the GoogleNet model to make a deeper investigation of multi-stage CNN features, where both the top layer features and lower layer features are employed for scene representations. Different from the above methods, in this paper, we propose a joint learning framework by taking advantage of both global metric learning and local manifold preservation, aiming to explore more informative deep features for scene recognition
2. Difficulties encountered and solutions
Convergence study In order to demonstrate the efficiency of JGML-LMP, we also investigate the recognition accuracies in terms of the number of iterations for the four scene datasets. Fig. 13 (a)–(d) shows the recognition accuracies of JGML-LMP with 10 iterations. We can observe that JGML-LMP reaches convergence within less than five iterations for the four datasets. This may be attributed to an appropriate initialization of W in Algorithm1. Although scene images show large variations in spatial position, illumination, and scale, the proposed joint learning framework is efficient for scene recognition.
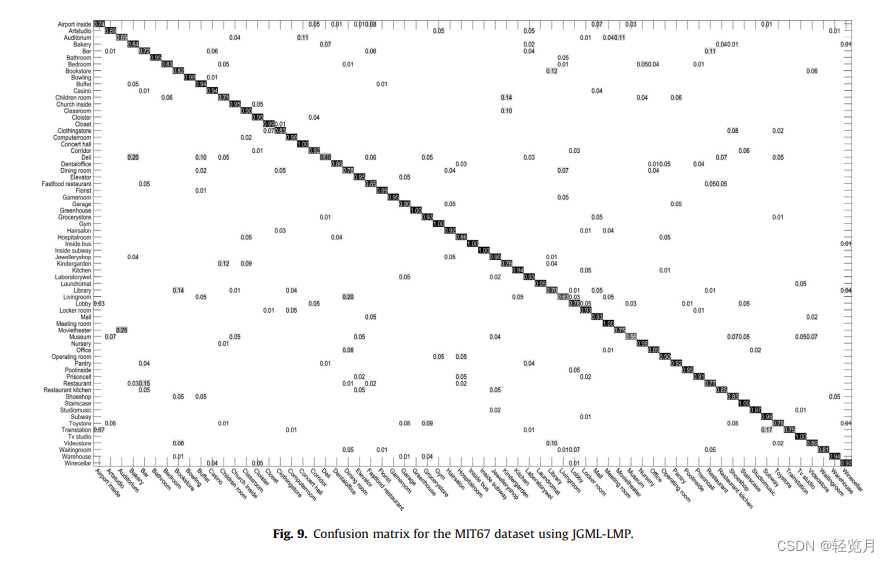
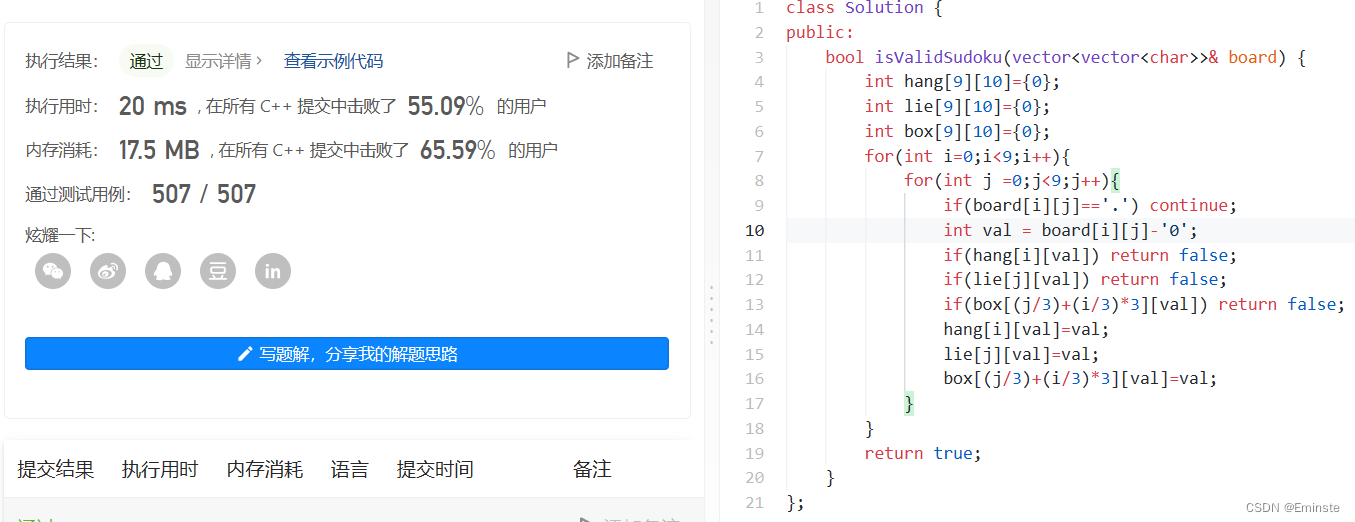
3. Three, learning to punch the results display
public class Solution { public ListNode detectCycle(ListNode head) { ListNode pos = head; Set<ListNode> visited = new HashSet<ListNode>(); while(pos != null) { if (visited.contains(pos)) { return pos; } else { visited.add(pos); } pos = pos.next; } return null; } }One is to use a hash table:
Traverse each node in the linked list and record it; Once a node that has been traversed before is encountered, it can be determined that there is a ring in the linked list. This can be easily achieved with the help of hash tables.
public class Solution { public ListNode detectCycle(ListNode head) { if (head == null) { return null; } ListNode slow = head, fast = head; while (fast != null) { slow = slow.next; if (fast.next != null) { fast = fast.next.next; } else { return null; } if (fast == slow) { ListNode ptr = head; while (ptr != slow) { ptr = ptr.next; slow = slow.next; } return ptr; } } return null; } }The other is the speed indicator:
We use two Pointers, fast and slow. They all start at the head of the list. Subsequently, the slow pointer moves back one position at a time, while the fast pointer moves back two positions. If there is a ring in the linked list, the fast pointer will eventually meet the slow pointer again in the ring.
4. Summary of learning skills
In this paper, I have proposed a joint global metric learning and local manifold preservation method for scene recognition. By generating cluster centers for each specific class, I have formulated a new global metric learning problem, which not only helps to sufficiently capture the global discriminative information from training images, but also guarantees a lower computational cost. By introducing an adaptive nearest neighbors constraint, we have learned the local neighborships in a more appropriate metric space instead of the Euclidean space, which allows to preserve the local manifold information as much as possible. By taking full advantage of both global and local information, our method has great potential to produce more discriminative and robust feature presentations, thus achieving a promising performance for scene recognition. Extensive experiments on four benchmark scene datasets have demonstrated the superiority of the proposed method over stateof-the-art methods.
Although our joint learning model has performed well on the four scene datasets, there remain some shortcomings that need to be further improved. In the local manifold preservation part, we find adaptive nearest neighbors in the new metric space. However, in the global metric learning part, the cluster centers are still pre-calculated in the Euclidean space. This may be the most critical problem in metric learning, which should be taken into account in future work. Since the proposed method is not suited for large-scale scene datasets, we also intend to explore deep metric learning to further improve the recognition performance for such datasets