ControlNet 是 Stable Diffusion中的一种扩展模型,通过这种扩展模型,我们能够将参考图像的构图(compositions )或者人体姿势迁移到目标图像。
资深 Stable Diffusion 用户都知道,很难精准控制Stable Diffusion生成的图像,比如如何在不同场景中保持原来的构图(compositions )或者人物形象,但是有了ControlNet ,这些问题变得轻松多了。
这篇文章,我带你系统了解:
-
什么是ControlNet;
-
ControlNet的工作原理
-
ControlNet 常用preprocessing
-
如何部署和使用ControlNet
ControlNet 是用来控制Stable Diffusion 模型的一种神经网络模型。Stable Diffusion 本身是一种根据文本或者图像用来生成图像的扩散模型,在生成图像过程中,可以通过 ControlNet 引入更多条件来干预图像生成过程,它可以(也需要) 跟现有 任何 Stable Diffusion 模型搭配使用。
下面举两个例子来说明ControlNet 如何来干预图像生成:
1. 使用canny边缘检测 来控制图像生成
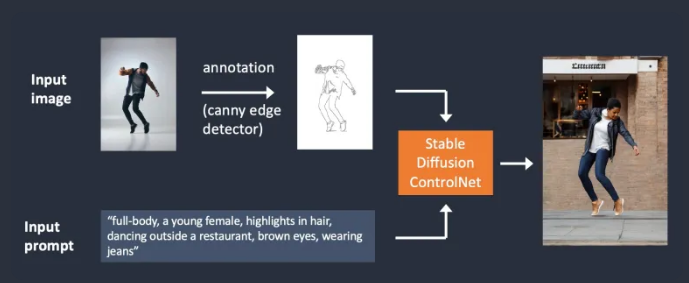
在这个示例图中,有两种条件来控制最终的图像生成:文本条件和canny边缘检测结果(control map)。前者是prompt,大家都很熟悉了,后者需要额外提供参考图像,示例中通过canny 边缘检测器,提取参考图像的边缘信息。两者共同作用于目标图像。
从参考图像中提取额外信息的过程,在Stable Diffusion中有专门的术语叫:preprocessing。
2. 使用OpenPose来迁移人物姿势特征
OpenPose是一种快速检测人体特征的模型,包括手,脚,肩膀,头和眼睛等位置特征。
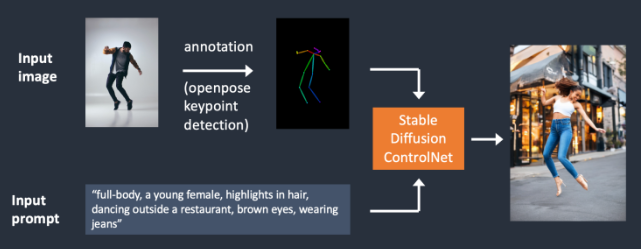
从上面示例,大家能够看到边缘检测器和OpenPose的一些区别,前者勾勒人物轮廓,目标图像会保留原图中的头发,衣服等轮廓,适合于一些富含边缘信息的主题和背景迁移,而后者更自由,它关注人物的关键姿势特征,但是不会保留那些衣服,头发等的轮廓信息。
实际上,OpenPose相关的有多种preprocessing,比如:
OpenPose: ,nose, eyes, neck, shoulder, elbow, wrist, knees, and ankles.
OpenPose_face: OpenPose + facial details
OpenPose_hand: OpenPose + hands and fingers
OpenPose_faceonly: facial details only
OpenPose_full: All of the above
OpenPose有专门提取脸部特征,手部特征,关节,膝盖,脚踝以及以上特征的组合等多种模型。这么看,OpenPose 也并不是那么粗枝大叶,也可以做到精细控制,为什么有专门针对脸和手的模型呢?因为没有这些模型,Stable Diffusion对手的生成 不在行,经常出现 多手指或者手指变形等情况,人脸的重要性更不用说了,脸部细节直接关系结果图像的成败。
关于OpenPose提取人体特征,我们看几个例子:


这里是根据脸部表情特征 生成的目标图像:

可见,这个模型处理好的话,可以用于那些对人物角色形象相似度度要求不高,但是又要求是同一人物的场景。
Reference
跟OpenPose相似的另一个preprocessing是Reference。Reference能够生成跟参考图像相似的图像,这个特性经常用于在不同场景中生成同一人物形象,比如绘本创作中,至少要求是同一张脸。OpenPose 虽然也能精细控制脸,但是 相比 Reference,OpenPose 主要是保证脸部,包括眼睛,鼻子等的相似,但是 整体脸部效果 还是不能保证。
使用 Reference 只需要选择 preprocessing,不需要搭配模型,在SD web Ui中,选择模型选项自动不可用。
有3个Reference相关的preprocessing:
Reference adain: Style transfer via Adaptive Instance Normalization. (paper【https://arxiv.org/abs/1703.06868】)
Reference only: Link the reference image directly to the attention layers.
Reference adain+attn: Combination of above.
Reference adain 在github中有关讨论:
https://github.com/Mikubill/sd-webui-controlnet/discussions/1280
Reference only 在github中有关讨论:
https://github.com/Mikubill/sd-webui-controlnet/discussions/1236】
结合作者的评论,使用中推荐Reference only。
ControlNet Inpainting
ControlNet Inpainting 其实是借助类似蒙版的概念,能够对图像的部分进行修改,而保持其他部分不变。举个例子,将下面美女的脸换一下,同时保持图像其他整体风格和内容不变。
这是原图:

我们在原图中将脸打上掩码:

选择重新生成掩码部分,将得到新的脸:

这一步你也可以选择保持掩码部分不变,而改变其他地方。
inpainting preprocessors 相关的有3种:
Inpaint_global_harmonious: Improve global consistency and allow you to use high denoising strength.
Inpaint_only: Won’t change unmasked area. It is the same as Inpaint_global_harmonious in AUTOMATIC1111.
Inpaint_only+lama: Process the image with the lama model. It tends to produce cleaner results and is good for object removal.
前两个作用是一样的,都保持掩码区域内容不变。Inpaint_only+lama 能够生成更干净的图像,luma 在这里有详细介绍:
https://github.com/advimman/lama
它利用傅里叶变换进行inpainting,能够生成更高分辨率的图像。可用于对象清除,比如下面示例:

|
|
|


Depth
ControlNet 深度预处理器是用于处理图像中的深度信息的工具。它可以用于计算图像中物体的距离、深度图等。
depth map是跟原图大小一样的存储了深度信息的灰色尺度( gray scale )图像,白色表示图像距离更近,黑色表示距离更远。
举个例子,原图和它的depth map 深度信息图(MIDaS编码):

Depth-to-image (Depth2img)
可以看作是 image-to-image (img2img) 的加强版,是一个在 Stable Diffusion v2 中未受重视的模型。
相比img2img,Depth2img 不仅能够利用 文本prompt,原来的图像,还可以使用原来图像的深度信息来控制图像的生成,也就是说,相比前者,他有3维参考信息。使用Depth-to-image 可以独立地控制合成图像中的物体和背景,从而得到更好的结果图像。但是 使用方式跟 前者一样,深度信息是自动进行的。
为了直观地比较两种模型生成的图像质量,我们以一张原始图,来看两者的输出结果:

现在我们拿这张图做参考图,输入:
photo of two men wrestling生成两个男人摔跤的图像:

分别调节去噪强度参数,可以发现,imgimg明显丢失了原图信息,而depth2img较好地保留了原图中的信息。
注:depth2img 也可以用于inpainting。
Segmentation
Segmentation preprocessors 能够识别出图像中的各种对象,比如下例中,能够将图中不同的对象,建筑,行人,天空,树木等用不同的颜色标出:

然后用同样的提示词,可以生成新的图像:
Futuristic city, tree, buildings, cyberpunk
T2I adapter
t2ia_style_clipvision preprocessor 能够将参考图像转换为包含原图中丰富的内容和样式的CLIP vision embedding。
|
|
|


而如果没有使用该模型,则产生的新的图像跟原图差距很大,这一模型相比Reference preporocssor 效果更好。感兴趣的读者可以试试。
MLSD
M-LSD (Mobile Line Segment Detection)是一个直线检测器,它很擅长提取直线边缘的轮廓信息,比如建筑,街区,相框等,可以用于室内设计,比如提供这样的参考图:

输入:
award winning living room可以生成下面的目标图像:

Stable Diffusion 部署与使用ControlNet
接下来,简单过一遍,如何部署和使用Stable Diffusion ControlNet。假设你已经下载并成功启动了AUTOMATIC1111 WebUi,接下来我详细介绍下如何安装ControlNet扩展。
导航到extensions,选择从URL安装,输入下面网址:
https://github.com/Mikubill/sd-webui-controlnet

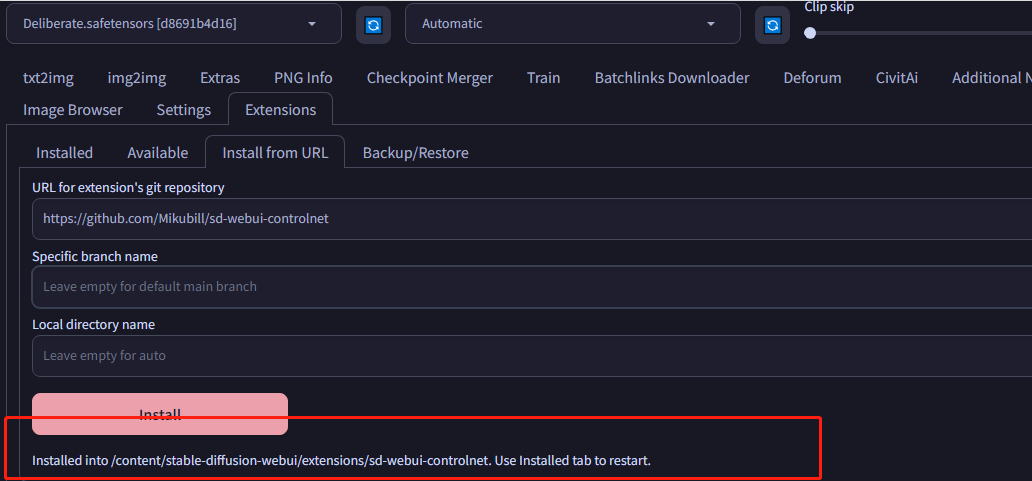
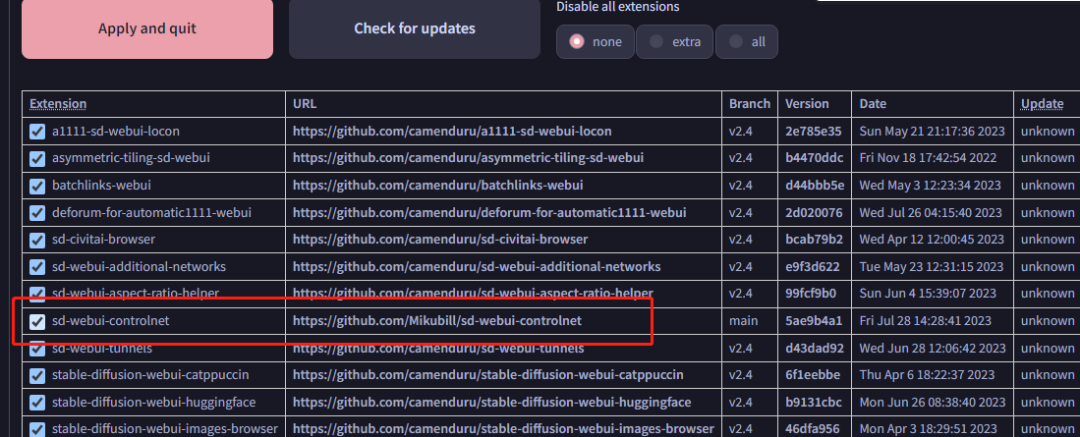
点击安装,安装完成之后,回到Installed tab,确认勾选了 contrlnet extension,然后重启。
重启之后,如果能够看到 ControlNet tab 说明一切正常。将下面图片上传到图像面板:

就可以使用上面介绍的任意preprocessing来预览提起的特征,比如以OpenPose为例:
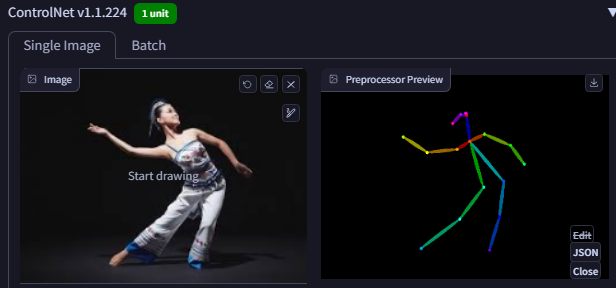
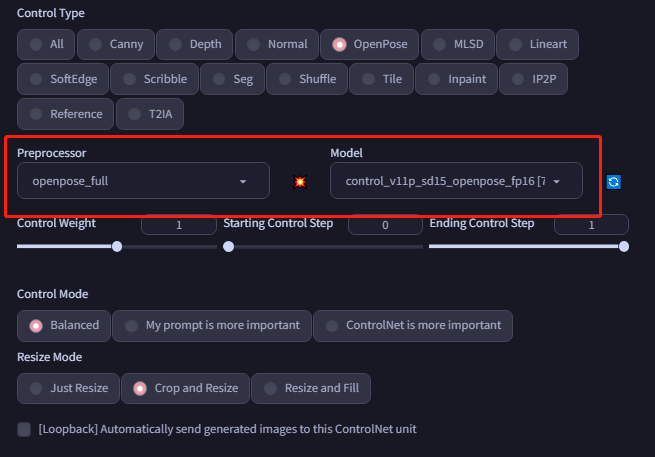
输入prompt就可以将原图的姿势迁移到目标图像中:

还可以使用canny 边缘检测:
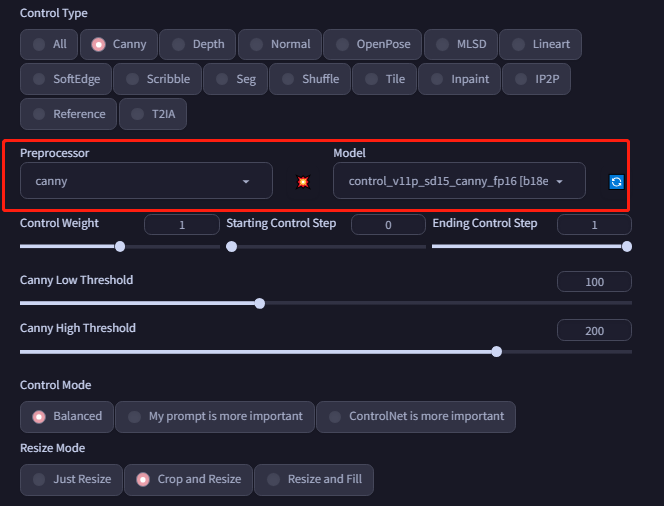

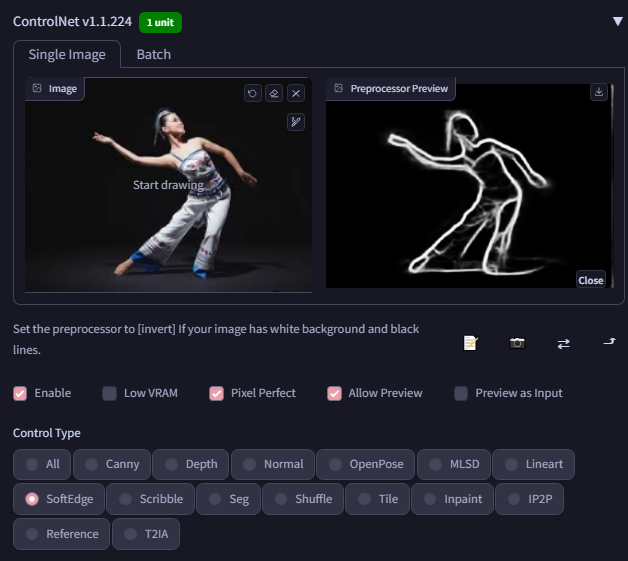
其他特征提取都可以类似下面勾选不同的方法来预览。
关于ControNet的总体知识,我基本介绍完了,关于ControlNet的知识还有很多,限于篇幅无法一一介绍,最后我再给一个效果案例,感兴趣的可以去测试下能否复现,这里是原图:

效果图如下:

如果有任何问题欢迎评论和加群交流。
| 公开微信交流群 | 私密知识星球群 |
 |  |