博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持!
博主链接
本人就职于国际知名终端厂商,负责modem芯片研发。
在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G算力网络技术标准研究。
博客内容主要围绕:
5G/6G协议讲解
算力网络讲解(云计算,边缘计算,端计算)
高级C语言讲解
Rust语言讲解
文章目录
- CUDA编程模型
- 一、异构计算术语
- 二、CUDA安装
- 2.1 适用设备
- 2.2 软件安装
- 2.3 查看当前设备参数
- 2.4 CUDA程序示例
- 三、CUDA程序的编写
- 四、CUDA关键字介绍
- 4.1 \_\_global__关键字
- 4.2 \_\_device__关键字
- 4.3 \_\_host__关键字
- 五、CUDA程序的编写
- 五、CUDA线程层次
- 六、CUDA内存操作
- 6.1 内存分配
- 6.2 内存拷贝
- 6.3 内存释放
- 七、获取CUDA线程索引
- 八、CUDA 的线程分配
- 九、GPU的存储单元
- 十、CUDA错误检测
- 十一、CUDA统一内存(Unified Memory)
- 十二、CUDA事件
- 十三、NVPROF
CUDA编程模型
一、异构计算术语
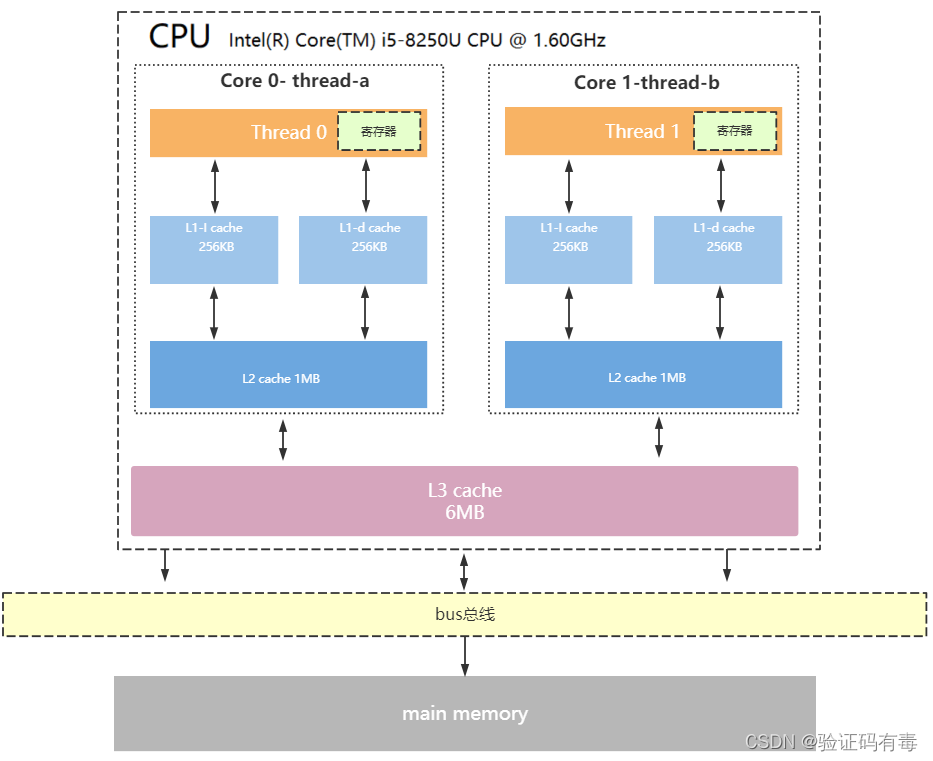
Host:CPU和内存(host memory)
Device:CPU和内存(host memory)

二、CUDA安装
2.1 适用设备
所有包含NVIDIA GPU的服务器,工作站,个人电脑,嵌入式设备等电子设备
2.2 软件安装
- Windows:https://docs.nvidia.com/cuda/cuda-installation-guide-microsoft-windows/index.html
只需安装一个.exe的可执行程序 - Linux:https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html
按照上面的教程,需要6 / 7 个步骤即可 - Jetson: https://developer.nvidia.com/embedded/jetpack
直接利用NVIDIA SDK Manager 或者 SD image进行刷机即可
2.3 查看当前设备参数
在CUDA sample中1_Utilities/deviceQuery文件夹下的deviceQuery程序。以Ubuntu为例,deviceQuery 程序
在:/usr/local/cuda/samples/1_Utilities/deviceQu
2.4 CUDA程序示例
https://github.com/NVIDIA/cuda-samples
三、CUDA程序的编写
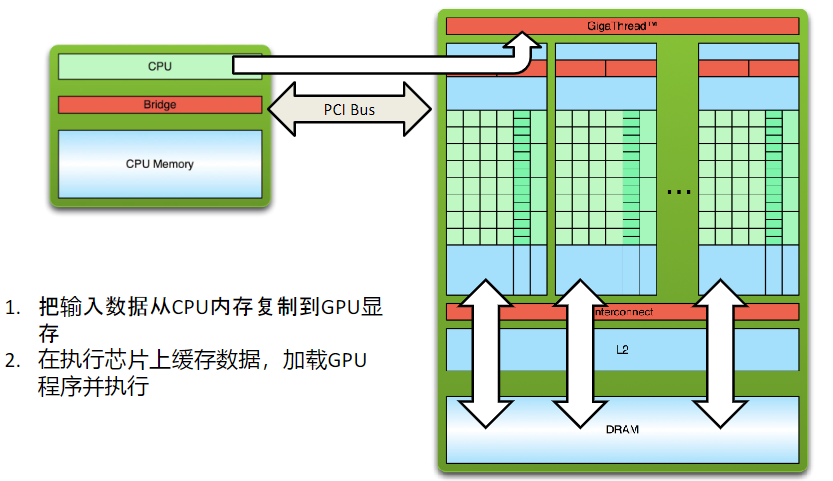
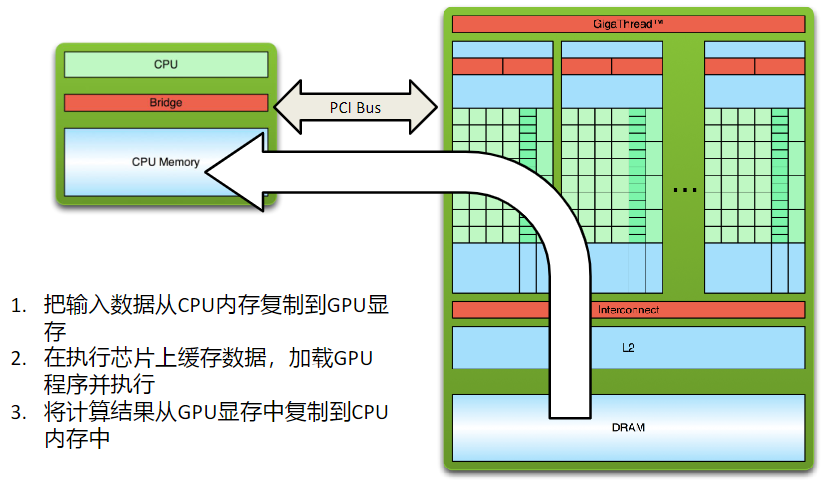
四、CUDA关键字介绍
4.1 __global__关键字
__global__执行空间说明符将函数声明为内核。 它的功能是:
- 在设备上执行;
- 可从主机调用,可在计算能力为 3.2或更高的设备调用;
- __global__ 函数必须具有 void 返回类型,并且不能是类的成员;
- 对 global 函数的任何调用都必须指定其执行配置;
- 对 global 函数的调用是异步的,这意味着它在设备完成执行之前返回;
4.2 __device__关键字
__device__ 执行空间说明符声明了一个函数:
- 在设备上执行;
- 只能从设备调用;
- __global__ 和 __device__ 执行空间说明符不能一起使用;
4.3 __host__关键字
__host__ 执行空间说明符声明了一个函数:
- 在主机上执行;
- 只能从主机调用;
- __global__ 和 __host__ 执行空间说明符不能一起使用。但是, __device__ 和 __host__ 执行空间说明
符可以一起使用,在这种情况下,该函数是为主机和设备编译的;
五、CUDA程序的编写
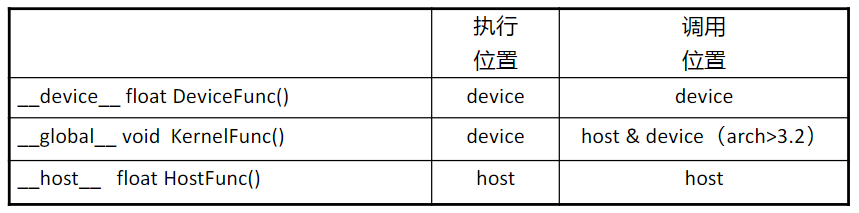
- __global__ 定义一个 kernel 函数
- 入口函数,CPU上调用,GPU上执行;
- 必须返回void;
- __device__ and __host__ 可以同时使用

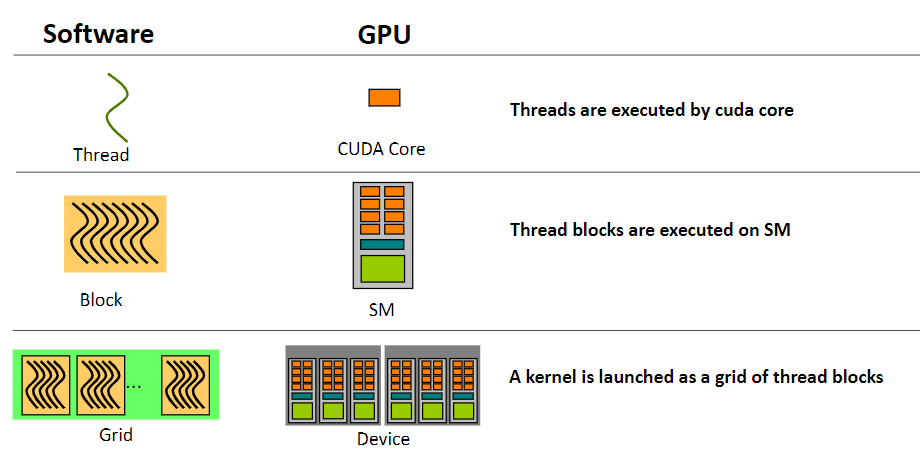
五、CUDA线程层次
HelloFromGPU <<<grid_size, block_size>>>();
- Thread: sequential execution unit
- 所有线程执行相同的核函数
- 并行执行
- Thread Block: a group of threads
- 执行在一个Streaming Multiprocessor (SM)
- 同一个Block中的线程可以协作
- Thread Grid: a collection of thread blocks
- 一个Grid当中的Block可以在多个SM中执行
- 内建变量
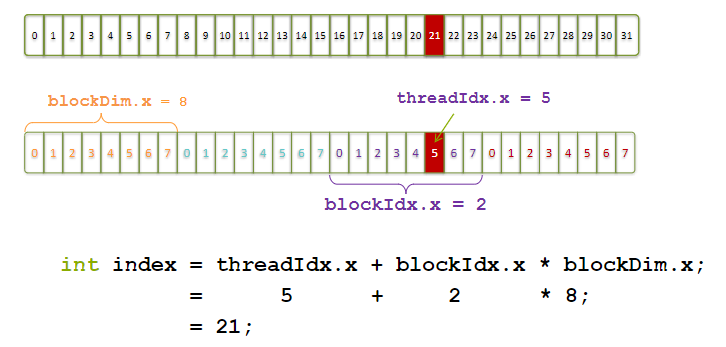
- threadIdx.[x y z]:是执行当前kernel函数的线程在block中的索引值;
- blockIdx.[x y z]:是指执行当前kernel函数的线程所在block,在grid中的索引值;
- blockDim.[x y z]:表示一个block中包含多少个线程;
- gridDim.[x y z]:表示一个grid中包含多少个block;
例如,dim3 grid(3,2,1), block(5,3,1)的线程分布示意图:
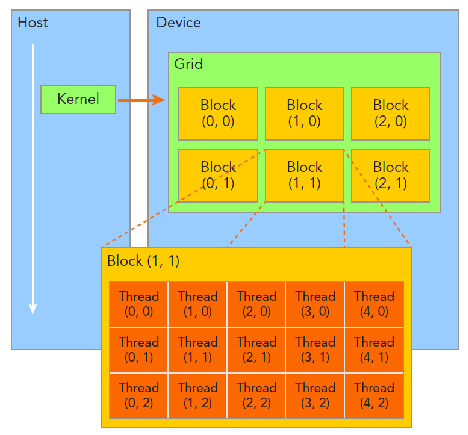
一个cuda线程在一个cuda core上执行,一个block在一个sm上执行,一个grid在整个device上执行,但是反之不成立。
六、CUDA内存操作
6.1 内存分配
__host__ __device__ cudaError_t cudaMalloc(void** devPtr, size_t size)
- devPtr:Pointer to allocated device memory
- Size:Requested allocation size in bytes
6.2 内存拷贝
cudaMemcpy(void *dst, const void *src, size_t count, cudaMemcpyKind kind)
- dst: destination memory address
- src: source memory address
- count: size in bytes to copy
- kind: direction of the copy
- cudaMemcpyKind
- cudaMemcpyHostToDevice
- cudaMemcpyDeviceToHost
- cudaMemcpyDeviceToDevice
- cudaMemcpyHostToHost
- cudaMemcpyKind
6.3 内存释放
cudaFree()
七、获取CUDA线程索引
对于一维数据来说:
对于二维数据来说:
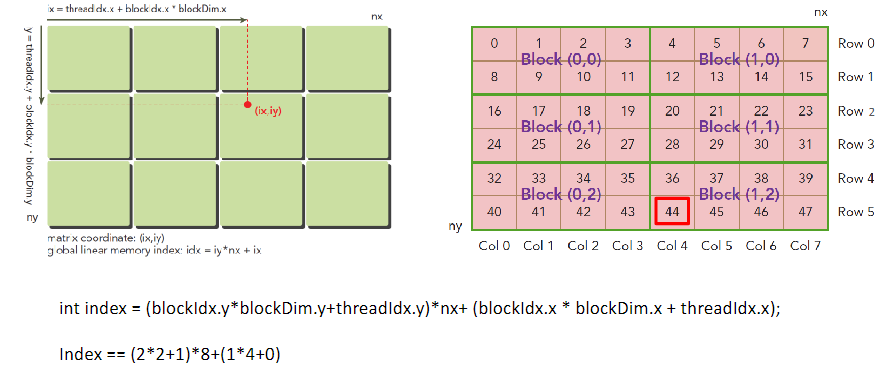
八、CUDA 的线程分配
一个warp包含32个cuda线程,所以一个block会被分成一个或多个warp执行。

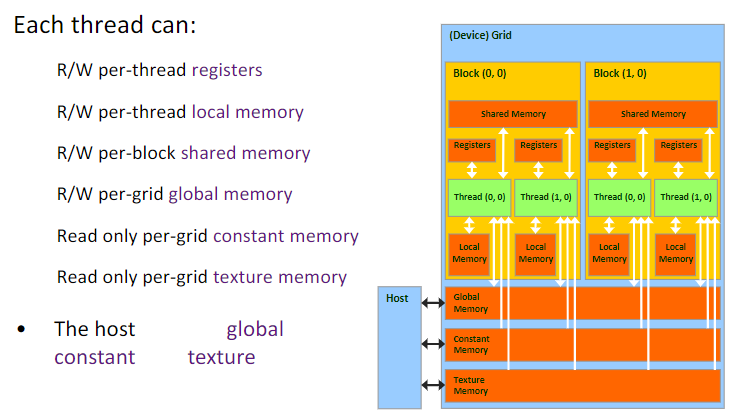
九、GPU的存储单元
十、CUDA错误检测
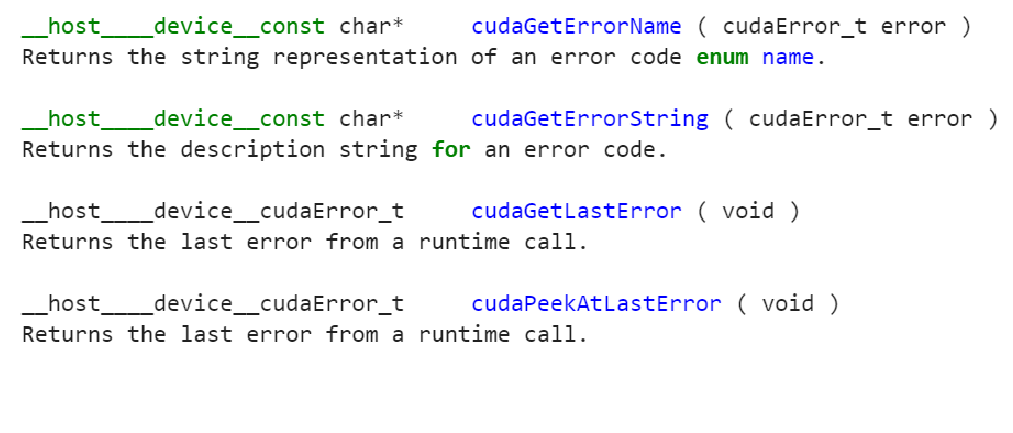

注意:
cudaGetLastError(void)与cudaPeekAtLastError(void)的区别是,调用cudaGetLastError(void)之后,会将错误类型重置为cudaSuccess,然后调用cudaPeekAtLastError(void)后不会修改cudaError_t的状态。可以从下面的例子中看出来:

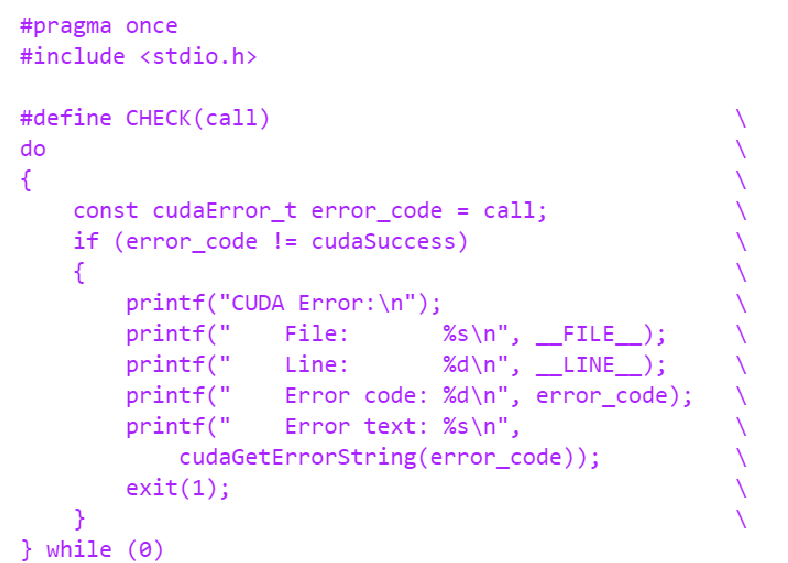
一个通用的cuda error检测宏:
十一、CUDA统一内存(Unified Memory)
统一内存是可从系统中的任何处理器访问的单个内存地址空间。这种硬件/软件技术允许应用程序分配可以从
CPU s 或 GPUs 上运行的代码读取或写入的数据。分配统一内存非常简单,只需将对 malloc() 或 new 的调用替换
为对 cudaMallocManaged() 的调用,这是一个分配函数,返回可从任何处理器访问的指针。

分配Unified Memory有两种方法:
-
cudaError_t cudaMallocManaged(void **devPtr, size_t size, unsigned int flags=0);
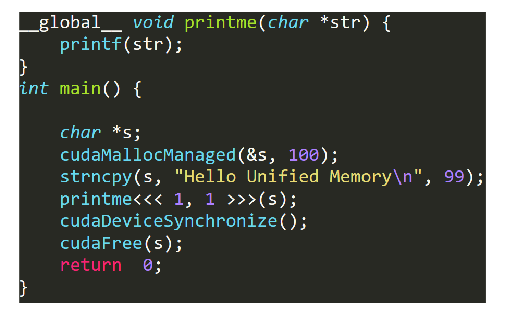
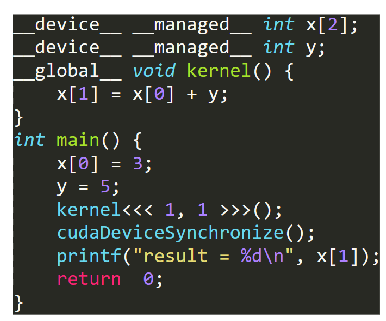
-
使用关键字
__managed__;
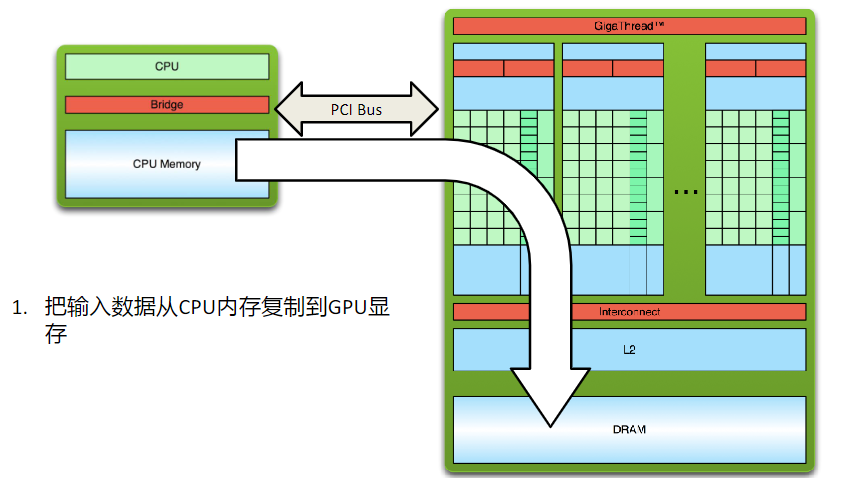
使用了统一内存之后并不意味之CPU和GPU使用了同一块内存空间。如下图所示,如果GPU要访问的页面已经在GPU Memory中,则没有任何异常;如果GPU要访问的页面不在当前的GPU Memory中,则将CPU Memory中的page迁移到GPU Memory中。

统一内存的优势:
- 可直接访问CPU内存、GPU显存,不需要手动拷贝数据;
- CUDA 在现有的内存池结构上增加了一个统一内存系统,程序员可以直接访问任何内存/显存资源,或者在合法
的内存空间内寻址,而不用管涉及到的到底是内存还是显存; - CUDA 的数据拷贝由程序员的手动转移,变成自动执行,因此,它仍然受制于PCI-E的带宽和延迟;
十二、CUDA事件
CUDA event本质是一个GPU时间戳,这个时间戳是在用户指定的时间点上记录的。由于GPU本身支持记录时间戳,因此就避免了当使用CPU定时器来统计GPU执行时间可能遇到的诸多问题。

如何使用上述事件函数:
-
声明:
cudaEvent_t event; -
创建:
cudaError_t cudaEventCreate(cudaEvent_t* event); -
添加事件到当前执行流:
cudaError_t cudaEventRecord(cudaEvent_t event, cudaStream_t stream
= 0); -
等待事件完成,设立flag:
cudaError_t cudaEventSynchronize(cudaEvent_t event);//阻塞
cudaError_t cudaEventQuery(cudaEvent_t event);//非阻塞当然,我们也可以用它来记录执行的事件:
cudaError_t cudaEventElapsedTime(float* ms, cudaEvent_t start,
cudaEvent_t stop);cudaEventRecord()视为一条记录当前时间的语句,并且把这条语句放入GPU的未完成队列中。因为直到GPU执行完了再调用 cudaEventRecord()之前的所有语句时,事件才会被记录下来。且仅当GPU完成了之前的工作并且记录了stop事件后,才能安全地读取stop时间值。
-
销毁:
cudaError_t cudaEventDestroy(cudaEvent_t event);
代码示例:
cudaEvent_t start, stop;
cudaEventCreate( &start );
cudaEventCreate( &stop ) ;
cudaEventRecord( start) ;
// GPU
//
//.........................
cudaEventRecord( stop)
cudaEventSynchronize( stop );
float elapsedTime;
cudaEventElapsedTime( &elapsedTime,start, stop ) );
printf( "Time to generate: %.2f ms\n", elapsedTime );
cudaEventDestroy( start );
cudaEventDestroy( stop );
十三、NVPROF
Kernel Timeline 输出的是以gpu kernel 为单位的一段时间的运行时间线,我们可以通过它观察GPU在什么时候有闲置或者利用不够充分的行为,更准确地定位优化问题。nvprof是nvidia提供的用于生成gpu timeline的工具,其为cuda toolkit的自带工具。
非常方便的分析工具!
nvprof -o out.nvvp a.exe
可以结合nvvp或者nsight进行可视化分析
https://docs.nvidia.com/cuda/profiler-users-guide/index.html#nvprof-overview