文章目录
- 1、Mapping 简介
- 1.1 mapping 是啥?
- 1.2 如何查看索引映射
- 2、自动映射:dynamic mapping
- 2.1 自动类型推断规则
- 2.2 mapping 的使用禁忌
- 2.3 自动映射器的意义是什么?
- 3、手动映射:Explicit mapping
- 3.1 创建索引的 mapping
- 3.2 修改 mapping 属性
- 4、ES 数据类型 ★:field data type
- 4.1 概述
- 4.2 ES 支持的数据类型
- 4.2.1 基本数据类型 ★
- 4.2.2 对象关系类型(复杂类型)
- 4.2.3 结构化类型
- 4.2.4 聚合数据类型
- 4.2.5 文本搜索字段
- 4.2.6 文档排名类型
- 4.2.7 空间数据类型 ★
- 4.2.8 其他类型
- 5、映射参数
- 5.1 支持的映射参数
- 5、Text 类型 ★★
- 6、keyword 类型 ★
- 7、Date 类型 ★
- 7.1 案例
- 7.2 原理
- 7.3 采用手工映射
- 7.4 总结
- 7.5 解决方案
- 8、Nested 类型 ★
1、Mapping 简介
1.1 mapping 是啥?
ES 中的 mapping 有点类似与关系数据库中表结构的概念,在 MySQL 中,表结构里包含了字段名称,字段的类型还有索引信息等。在 Mapping 里也包含了一些属性,比如字段名称、类型、字段使用的分词器、是否评分、是否创建索引等属性,并且在 ES 中一个字段可以有对个类型。
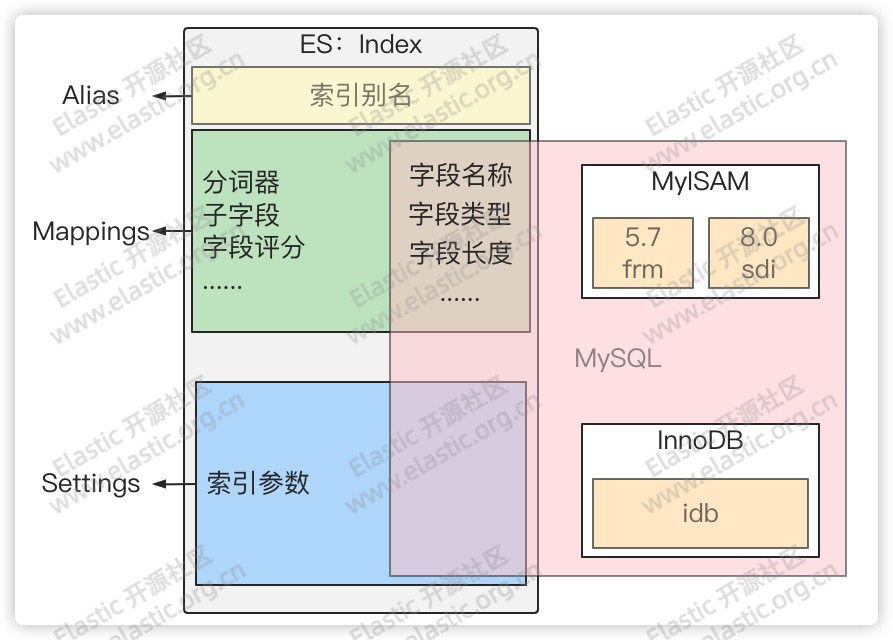
1.2 如何查看索引映射
查看完整的索引 mapping
GET /<index_name>/_mappings
查看索引中指定字段的 mapping
GET /<index_name>/_mappings/field/<field_name>
2、自动映射:dynamic mapping
自动映射也叫动态映射,是 ES 在索引文档写入发生时自动创建 mapping 的一种机制。
ES 在创建索引之前,并不强制要求创建索引的 mapping,ES 会根据字段的值来推断字段类型,进而自动创建并指定索引类型。
2.1 自动类型推断规则
下面是自动映射器推断字段类型的规则

自动映射器会尽可能的把字段映射为宽字段类型。
2.2 mapping 的使用禁忌
- ES 没有隐式类型转换
- ES 不支持类型修改
- 生产环境尽可能的避免使用 dynamic mapping
2.3 自动映射器的意义是什么?
官方的解释是为了照顾入门学习者,但实际上我更建议初学者尽量避免使用自动映射器,而尽可能多的显式声明 mapping,因为显式创建 mapping 是生产环境必须的,所以这是必须掌握的技能。
反而是老手,在非生产环境中,使用自动映射会比较方便。
3、手动映射:Explicit mapping
手动映射也叫做显式映射,即:在索引文档写入之前,认为的创建索引并且指定索引中每个字段类型、分词器等参数。
3.1 创建索引的 mapping
PUT /<index_name>
{
"mappings": {
"properties": {
"field_a": {
"<parameter_name>": "<parameter_value>"
},
...
}
}
}
3.2 修改 mapping 属性
注意和创建 mapping 时的语法区别。
PUT <index_name>/_mapping
{
"properties": {
"<field_name>": {
"type": "text", // 必须和原字段类型相同,切不许显式声明
"analyzer":"ik_max_word", // 必须和元原词器类型相同,切必须显式声明
"fielddata": false
}
}
}
**注意:**并非所有字段参数都可以修改。
- 字段类型不可修改
- 字段分词器不可修改
4、ES 数据类型 ★:field data type
4.1 概述
每个字段都有字段数据类型或字段类型。其大致分为两种:会被分词的字段类型和不会被分词的字段类型。
- 会被分词的类型:text、match_only_text 等。
- 不会被分词类型:keyword、数值类型等。
当然数据类型的划分可以分为很多种,比如按照基本数据类型和复杂数据类型来划分。
4.2 ES 支持的数据类型
注意
- 标注颜色为浅灰色代表非常用数据类型
- 标注 ★ 为非常重要的数据类型,会单独用一节课来讲
4.2.1 基本数据类型 ★
-
Numbers:数字类型,包含很多具体的基本数据类型

-
binary:编码为 Base64 字符串的二进制值。
-
boolean:即布尔类型,接受 true 和 false。
-
alias:字段别名。
-
Keywords:包含 keyword ★、constant_keyword 和 wildcard。
-
Dates:日期类型,包括 data ★ 和 data_nanos,两种类型
4.2.2 对象关系类型(复杂类型)
- object:非基本数据类型之外,默认的 json 对象为 object 类型。
- flattened:单映射对象类型,其值为 json 对象。
- nested ★:嵌套类型。
- join:父子级关系类型。
4.2.3 结构化类型
- Range:范围类型,比如 long_range,double_range,data_range 等
- ip:ipv4 或 ipv6 地址
- version:版本号
- murmur3:计算和存储值的散列
4.2.4 聚合数据类型
- aggregate_metric_double:
- histogram:
4.2.5 文本搜索字段
- text ★:文本数据类型,用于全文检索。
- annotated-text:
- completion ★**:**
- search_as_you_type:
- token_count:
4.2.6 文档排名类型
- dense_vector:记录浮点值的密集向量。
- rank_feature:记录数字特征以提高查询时的命中率。
- rank_features:记录数字特征以提高查询时的命中率。
4.2.7 空间数据类型 ★
- geo_point:纬度和经度点。
- geo_shape:复杂的形状,例如多边形。
- point:任意笛卡尔点。
- shape:任意笛卡尔几何。
4.2.8 其他类型
- percolator:用Query DSL 编写的索引查询。
5、映射参数
5.1 支持的映射参数
以下是 ES 中说所有支持的映射参数
| 参数名称 | 释义 |
|---|---|
| analyzer ★ | 指定分析器,只有 text 类型字段支持。 |
| coerce | 是否允许强制类型转换,支持对字段段度设置或者对整个索引设置。 true: “1” => 1 false: “1” =< 1 索引级设置  字段级设置 字段级设置 |
| copy_to | 该参数允许将多个字段的值复制到组字段中,然后可以将其作为单个字段进行查询 |
| doc_values ★ | 为了提升排序和聚合效率,默认true,如果确定不需要对字段进行排序或聚合,也不需要通过脚本访问字段值,则可以禁用doc值以节省磁盘空间(不支持 text 和 annotated_text)在开源社区 ES 8.x:进阶篇 - 深入聚合原理章节中会深入讲解 |
| dynamic ★ | 控制是否可以动态添加新字段,支持以下四个选项:true:(默认)允许动态映射false:忽略新字段。这些字段不会被索引或搜索,但仍会出现在_source返回的命中字段中。这些字段不会添加到映射中,必须显式添加新字段。runtime:新字段作为运行时字段添加到索引中,这些字段没有索引,是_source在查询时加载的。strict:如果检测到新字段,则会抛出异常并拒绝文档。必须将新字段显式添加到映射中。 |
| eager_global_ordinals | **用于聚合的字段上,优化聚合性能。例如: |
| enabled | **是否创建倒排索引,可以对字段操作,也可以对索引操作,如果不创建索引,让然可以检索并在_source元数据中展示,谨慎使用,该状态无法修改。 |
| fielddata ★ | 查询时内存数据结构,在首次用当前字段聚合、排序或者在脚本中使用时,需要字段为fielddata数据结构,并且创建倒排索引保存到堆中 |
| fields ★ | 给 field 创建多字段,用于不同目的(全文检索或者聚合分析排序) |
| format ★ | **用于格式化代码,如: |
| ignore_above ★ | 超过长度将被忽略 |
| ignore_malformed | 忽略类型错误 |
| index_options | 控制将哪些信息添加到反向索引中以进行搜索和突出显示。仅用于text 字段 |
| index_phrases | 提升exact_value查询速度,但是要消耗更多磁盘空间 |
| index_prefixes | 前缀搜索:min_chars:前缀最小长度,>0,默认2(包含)max_chars:前缀最大长度,<20,默认5(包含) |
| index ★ | 是否对创建对当前字段创建倒排索引,默认 true,如果不创建索引,该字段不会通过索引被搜索到,但是仍然会在 source 元数据中展示true 新检测到的字段将添加到映射中。(默认)false 新检测到的字段将被忽略。这些字段将不会被索引,因此将无法搜索,但仍会出现在_source返回的匹配项中。这些字段不会添加到映射中,必须显式添加新字段。strict 如果检测到新字段,则会引发异常并拒绝文档。必须将新字段显式添加到映射中 |
| meta | 附加到元字段 |
| normalizer | 文档归一化器 |
| norms ★ | 是否禁用评分(在filter和聚合字段上应该禁用)。 |
| null_value ★ | 为 null 值设置默认值 |
| position_increment_gap | 用于数组中相邻搜索中的搜索间隙,slop 默认 100 见:代码块 1 |
| properties ★ | 除了mapping还可用于object的属性设置 |
| search_analyzer ★ | 设置单独的查询时分析器 |
| similarity | 为字段设置相关度算法,支持:BM25boolean注意:classic(TF-IDF)在 ES 8.x 中已不再支持! |
| subobjects | ES 8 新增,subobjects 设置为 false 的字段的值,其子字段的值不被扩展为对象。 |
| store | 设置字段是否仅查询 |
| term_vector | 运维参数,在运维篇会详细讲解。 |
代码块 1
# slop 默认 100
PUT position_increment_gap_index
{
"mappings" : {
"properties" : {
"title" : {
"type" : "text", // slop 默认 100
"fields" : {
"slop_0" : {
"type": "text",
"position_increment_gap" : 0
},
"slop_10" : {
"type": "text",
"position_increment_gap" :10
}
}
}
}
}
}
# 写入数据
POST /position_increment_gap_index/_doc/1
{
"title" : ["hello word", "Elastic Go"]
}
# 默认无数据
GET position_increment_gap_index/_search
{
"query": {
"match_phrase": {
"title": {
"query": "word hello"
}
}
}
}
# slop 配置 100 有数据
GET position_increment_gap_index/_search
{
"query": {
"match_phrase": {
"title": {
"query": "word elastic",
"slop": 100
}
}
}
}
# slop_0 默认有数据
GET position_increment_gap_index/_search
{
"query": {
"match_phrase": {
"title.slop_0": {
"query": "word elastic"
}
}
}
}
# slop_10 需要设置 slop:10以上才有数据
GET position_increment_gap_index/_search
{
"query": {
"match_phrase": {
"title.slop_10": {
"query": "word elastic",
"slop": 10
}
}
}
}
5、Text 类型 ★★
当一个字段是要被全文搜索的,比如邮件内容、产品描述等长文本,这些字段应该使用 text 类型。设置 text 类型以后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项。text 类型的字段不用于排序,很少用于聚合。(解释一下为啥不会为 text 创建正排索引:大量堆空间,尤其是在加载高基数 text 字段时。字段数据一旦加载到堆中,就在该段的生命周期内保持在那里。同样,加载字段数据是一个昂贵的过程,可能导致用户遇到延迟问题。这就是默认情况下禁用字段数据的原因)
总的来说,text 用于长文本字段,可以说是 ES 体系中最重要也是最常见的数据类型。
注意:
在基础课程中,仅需掌握 text 类型用于哪些应用场景下,以及用法即可,其深层次原理及全文检索相关内容,会在进阶课程中倒排索引的章节中体现。
6、keyword 类型 ★
keyword使用序号映射存储它们的文档值以获得更紧凑的表示。 此映射的工作原理是根据其词典顺序为每个术语分配一个增量整数或*序数。*该字段的文档值仅存储每个文档的序数而不是原始术语,并使用单独的查找结构在序数和术语之间进行转换。
一般用于精确匹配和聚合字段,例如 ID、电子邮件地址、主机名、状态代码、邮政编码或标签。包括范围查找。和 term 查询一起使用频率是最高的。
- keyword 类型字段不会被分词。
- keyword 一般用于精确查找或者聚合字段
- keyword 类型超过阈值长度会直接被丢弃
概括来说,就是用于“不分词”的字段,不需要“模糊检索”的字段,所以常和 term 一起使用,用于精准查询。
GET
7、Date 类型 ★
时间和日期类型是我们作为开发每天都会遇到的一种常见数据类型。和 Java 中有所不同,Elasticsearch 在索引创建之前并不是必须要创建索引的 mapping。
Elasticsearch 会根据你写入的字段的内容动态去判定字段的数据类型,不过这种自动映射的机制存在一些缺陷,比如在 Elasticsearch 中没有隐式类型转换,所以在自动映射的时候就会把字段映射为较宽的数据类型。比如你写入一个数字 50,系统就会自动给你映射成 long 类型,而不是 int 。一般企业中用于生产的环境都是使用手工映射,能保证按需创建以节省资源和达到更高的性能。
在 Elasticsearch 中,时间类型是一个非常容易踩坑的数据类型,通过一个例子向大家展示这个时间类型的用法和避坑指南
7.1 案例
假如我们有如下索引 tax ,保存了一些公司的纳税或资产信息,单位为“万元”。当然这里面的数据是随意填写的。多少为数据统计的时间,当前这个例子里。索引达的含义并不重要。关键点在于字段的内容格式。我们看到date字段其中包含了多种日期的格式:“yyyy-MM-dd”,“yyyy-MM-dd”还有时间戳。如果按照 dynamic mapping,采取自动映射器来映射索引。我们自然而然的都会感觉字段应该是一个date类型。
POST tax/_bulk
{"index":{}}
{"date": "2021-01-25 10:01:12", "company": "中国烟草", "ratal": 5700000}
{"index":{}}
{"date": "2021-01-25 10:01:13", "company": "华为", "ratal": 4034113.182}
{"index":{}}
{"date": "2021-01-26 10:02:11", "company": "苹果", "ratal": 7784.7252}
{"index":{}}
{"date": "2021-01-26 10:02:15", "company": "小米", "ratal": 185000}
{"index":{}}
{"date": "2021-01-26 10:01:23", "company": "阿里", "ratal": 1072526}
{"index":{}}
{"date": "2021-01-27 10:01:54", "company": "腾讯", "ratal": 6500}
{"index":{}}
{"date": "2021-01-28 10:01:32", "company": "蚂蚁金服", "ratal": 5000}
{"index":{}}
{"date": "2021-01-29 10:01:21", "company": "字节跳动", "ratal": 10000}
{"index":{}}
{"date": "2021-01-30 10:02:07", "company": "中国石油", "ratal": 18302097}
{"index":{}}
{"date": "1648100904", "company": "中国石化", "ratal": 32654722}
{"index":{}}
{"date": "2021-11-1 12:20:00", "company": "国家电网", "ratal": 82950000}
然而我们以上代码查看 tax 索引的 mapping,会惊奇的发现 date 居然是一个 text 类型。
7.2 原理
原因就在于对时间类型的格式的要求是绝对严格的。要求必须是一个标准的 UTC 时间类型。上述字段的数据格式如果想要使用,就必须使用yyyy-MM-ddTHH:mm:ssZ格式(其中T个间隔符,Z代表 0 时区),以下均为错误的时间格式(均无法被自动映射器识别为日期时间类型):
- yyyy-MM-dd HH:mm:ss
- yyyy-MM-dd
- 时间戳
注意:需要注意的是时间说是必须的时间格式,但是需要通过手工映射方式在索引创建之前指定为日期类型,使用自动映射器无法映射为日期类型。
7.3 采用手工映射
如果我们换一个思路,使用手工映射提前指定日期类型,那会又是一个什么结果呢?
PUT tax
{
"mappings": {
"properties": {
"date": {
"type": "date"
}
}
}
}
POST tax/_bulk
{"index":{}}
{"date": "2021-01-30 10:02:07", "company": "中国石油", "ratal": 18302097}
{"index":{}}
{"date": "1648100904", "company": "中国石化", "ratal": 32654722}
{"index":{}}
{"date": "2021-11-1T12:20:00Z", "company": "国家电网", "ratal": 82950000}
{"index":{}}
{"date": "2021-01-30T10:02:07Z", "company": "中国石油", "ratal": 18302097}
{"index":{}}
{"date": "2021-01-25", "company": "中国烟草", "ratal": 5700000}
执行以上代码,以下为完整的执行结果:
{
"took" : 17,
"errors" : true,
"items" : [
{
"index" : {
"_index" : "tax",
"_type" : "_doc",
"_id" : "f4uyun8B1ovRQq6Sn9Qg",
"status" : 400,
"error" : {
"type" : "mapper_parsing_exception",
"reason" : "failed to parse field [date] of type [date] in document with id 'f4uyun8B1ovRQq6Sn9Qg'. Preview of field's value: '2021-01-30 10:02:07'",
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "failed to parse date field [2021-01-30 10:02:07] with format [strict_date_optional_time||epoch_millis]",
"caused_by" : {
"type" : "date_time_parse_exception",
"reason" : "date_time_parse_exception: Failed to parse with all enclosed parsers"
}
}
}
}
},
{
"index" : {
"_index" : "tax",
"_type" : "_doc",
"_id" : "gIuyun8B1ovRQq6Sn9Qg",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "tax",
"_type" : "_doc",
"_id" : "gYuyun8B1ovRQq6Sn9Qg",
"status" : 400,
"error" : {
"type" : "mapper_parsing_exception",
"reason" : "failed to parse field [date] of type [date] in document with id 'gYuyun8B1ovRQq6Sn9Qg'. Preview of field's value: '2021-11-1T12:20:00Z'",
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "failed to parse date field [2021-11-1T12:20:00Z] with format [strict_date_optional_time||epoch_millis]",
"caused_by" : {
"type" : "date_time_parse_exception",
"reason" : "date_time_parse_exception: Failed to parse with all enclosed parsers"
}
}
}
}
},
{
"index" : {
"_index" : "tax",
"_type" : "_doc",
"_id" : "gouyun8B1ovRQq6Sn9Qg",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "tax",
"_type" : "_doc",
"_id" : "g4uyun8B1ovRQq6Sn9Qg",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 5,
"_primary_term" : 1,
"status" : 201
}
}
]
}
分析结果:
- 第一个(写入失败):2021-01-30 10:02:07
- 第二个(写入成功):1648100904
- 第三个(写入失败):2021-11-1T12:20:00Z
- 第四个(写入成功):2021-01-30T10:02:07Z
- 第五个(写入成功):2021-01-25
7.4 总结
- 对于
yyyy-MM-dd HH:mm:ss或2021-11-1T12:20:00Z,ES 的自动映射器完全无法识别,即便是事先声明日期类型,数据强行写入也会失败。 - 对于时间戳和
yyyy-MM-dd这样的时间格式,ES 自动映射器无法识别,但是如果事先说明了日期类型是可以正常写入的。 - 对于标准的日期时间类型是可以正常自动识别为日期类型,并且也可以通过手工映射来实现声明字段类型。
7.5 解决方案
其实解决办法非常简单。只需要在字段属性中添加一个参数:“format”: “yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis”,这样就可以避免因为数据格式不统一而导致数据无法写入的窘境。
代码如下:
PUT test_index
{
"mappings": {
"properties": {
"time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
8、Nested 类型 ★
由于前置知识所限,本章将不再对 Nested 进行深入的讲解,扩展学习请参考以下文章讲解。
参考:ES 中 Nested 类型的用法及原理