转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn]
文内若有错误,欢迎指出!

今天我想跟大家分享的是一篇虽然有点老,但是很经典的文章,这是一个在分布式训练中会用到的一项技术, 实际上叫ringallreduce。 为什么要叫这个吗?因为现在很多框架,比如像pytorch他内部的分布式训练用到的就是这个。 所以知道他的原理的话也方便我们后面给他进行改进和优化。他是一项来自HPC的技术,但实际上现在分布式机器学习上的很多技术都是借鉴自HPC。下面的内容一部分来自论文,另一部分是来自网络。

这里先介绍一点背景知识。
以数据并行为例,在分布式训练中,需要将数据分布到不同的GPU上面进行训练,然后训练一个epoch后进行梯度更新。这里的更新可以分为同步和异步,为了方便理解,这里我画了几张图。 同步比较好理解,每个GPU在完成之后,需要等其他GPU也完成才能进行梯度更新。异步的话,就是说每个GPU可以独自进行梯度更新,并且在一定的时间点进行梯度交换,因此并不需要等其他的GPU也完成。而这两种方式中的梯度交换也引申出了很多研究内容。
总的来说是基于两种方式,一种是使用参数服务器,另一种是通过reduce操作。 参数服务器的方式是通过指定一个服务器来协调计算每个GPU的梯度。他的缺点也很明显,随着GPU的增加,参数服务器的通信成为了瓶颈。 而reduce的方式是去除了参数服务器的存在,让每个GPU互相通信,他也分了map-reduce、all-reduce、ring-reduce、ring-allreduce等等。
https://zh.d2l.ai/chapter_computational-performance/parameterserver.html
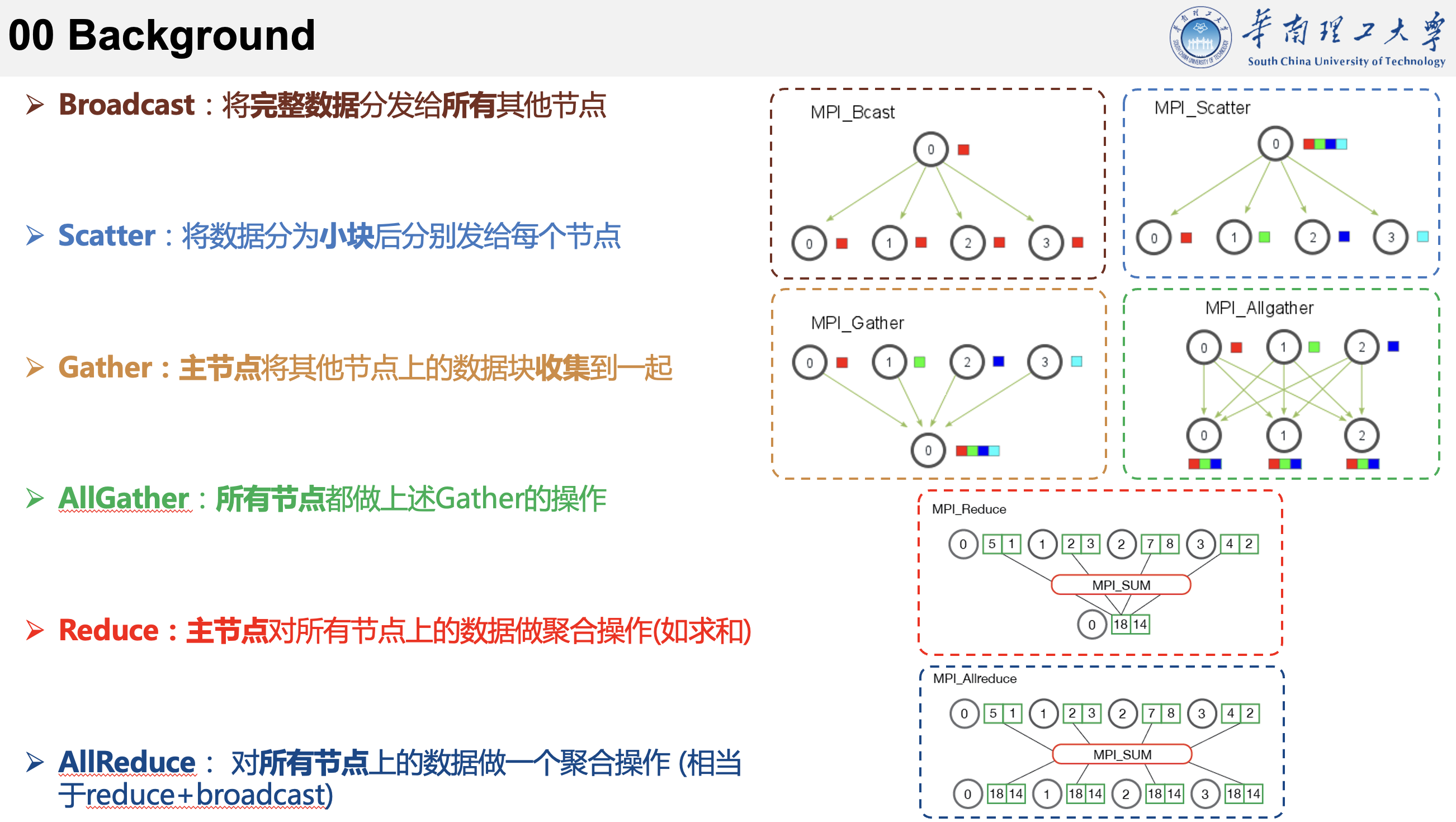
这里先介绍一下一些通信原语的概念,方便后面理解。
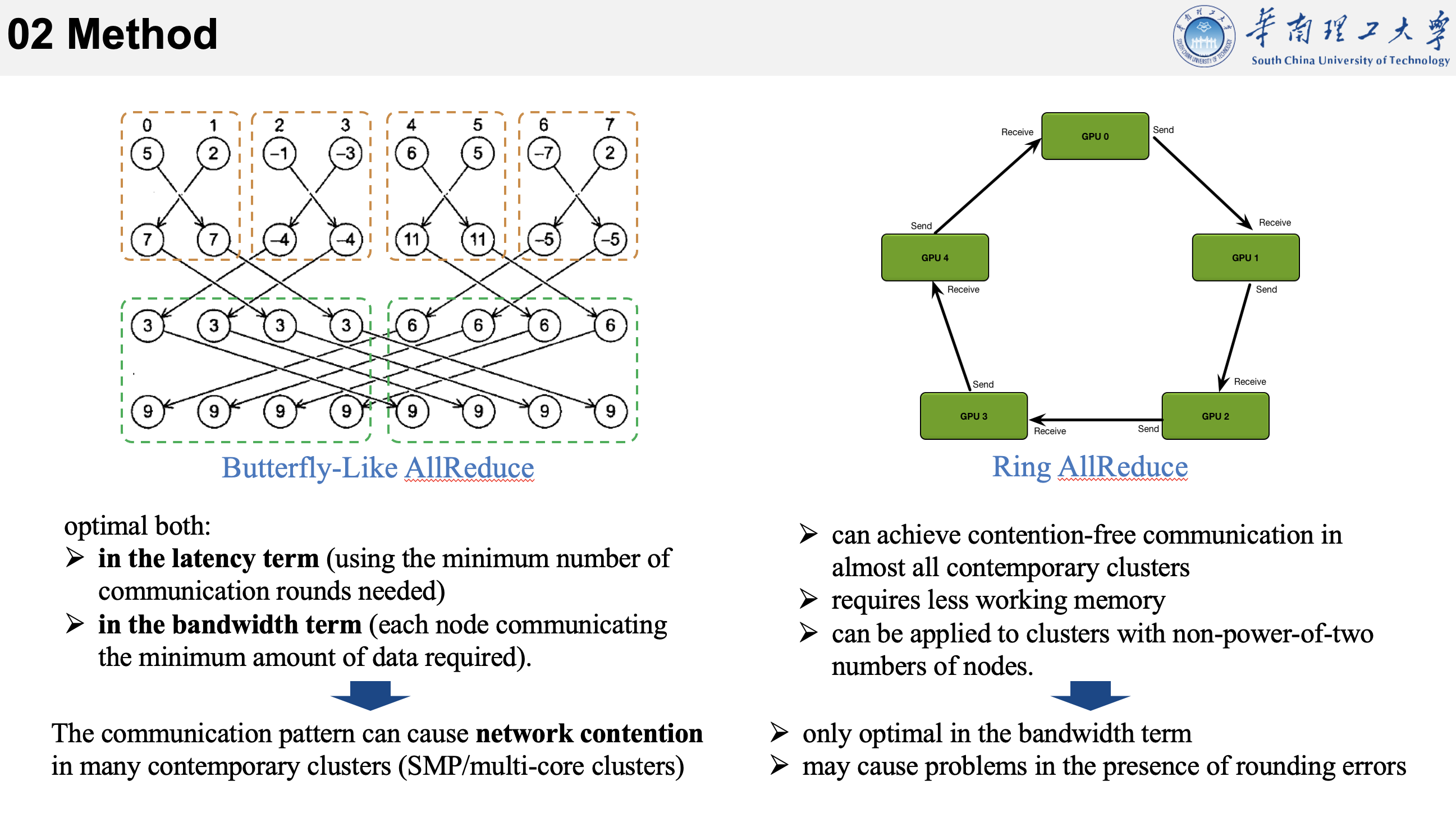
然后回到论文中来。
在allreduce中用的比较多的是蝶形算法。在没有网络竞争的情况下,这个算法在延迟和带宽中都是最优的,但是事实上,这种通信模式会导致在许多当代集群中产生网络竞争,如广泛部署的SMP/多核集群,因为这些集群往往共享了一些网络资源。
在没有网络竞争的情况下,蝶形算法之所以在延迟和带宽方面都表现最优,主要有以下几个原因:
1.对等通信模式: 蝶形算法采用了对等通信模式,即每个节点都与其他节点建立了直接连接。在没有网络竞争的情况下,节点之间的通信路径是独立的,不存在其他节点的干扰。这使得通信的延迟最小化,因为消息可以通过最短的路径尽快到达目标节点。
2.逐级通信: 蝶形算法通过多个通信阶段逐级地将数据进行聚合。每个阶段中,节点与距离它最近的节点进行通信,然后逐渐扩展到更远的节点。这种逐级通信方式使得数据的聚合过程更加高效,减少了通信的次数和总延迟。
3.负载平衡: 蝶形算法通过分阶段聚合数据,确保了在通信过程中负载的平衡。即使在节点之间的计算能力或带宽存在差异的情况下,蝶形算法仍能在通信过程中保持相对均衡的负载,最大限度地利用每个节点的计算资源。
4.带宽优化: 蝶形算法在每个阶段的通信中只传输部分数据,而不是直接传输全部数据。这样可以减少单次通信的数据量,从而更好地利用带宽资源。在没有网络竞争的情况下,节点之间的通信通常能够占用整个可用带宽,因此通过优化单次通信的数据量,蝶形算法可以最大程度地提高带宽利用率。
(蝶形全局求和的过程是,第一步将两个相邻的节点分作一组,互相通信他们的 sum,那么这个两节点小组的每个结点中的 sum 都是这个小组的局部和。第二步将四个节点分作一组,前半部分与后半部分相互通信,那么这个四节点小组的每个结点中的 sum 都是这个小组的局部和。循环进行这个步骤直到小组容量大于总进程数。)
而作者提出的基于环的方式,声称可以在几乎所有当代集群中实现无争用通信,并且可以需要比较少的内存需求,也不需要2的幂个节点。但它也存在一些问题,比如只在带宽上有优化;而且可能存在精度问题。这个精度问题是指,由于并行计算中涉及到浮点数运算,不同节点上进行计算的结果可能受到舍入误差的影响,因为不同节点对于浮点数计算的精度可能会有差异。此外,Ring算法虽然在中等规模的运算中非常有优势,较小的传输数据量,无瓶颈,带宽完全利用起来。不过在大型规模集群运算中,巨大的服务器内数据,极长的Ring环,Ring的这种切分数据块的方式就不再占优势。
这篇论文很长,而且数学公式较多,我们就不看数学证明,直接来看他的实现流程。不过他对流程介绍的也少,所以又从网上找了一些资料过来。
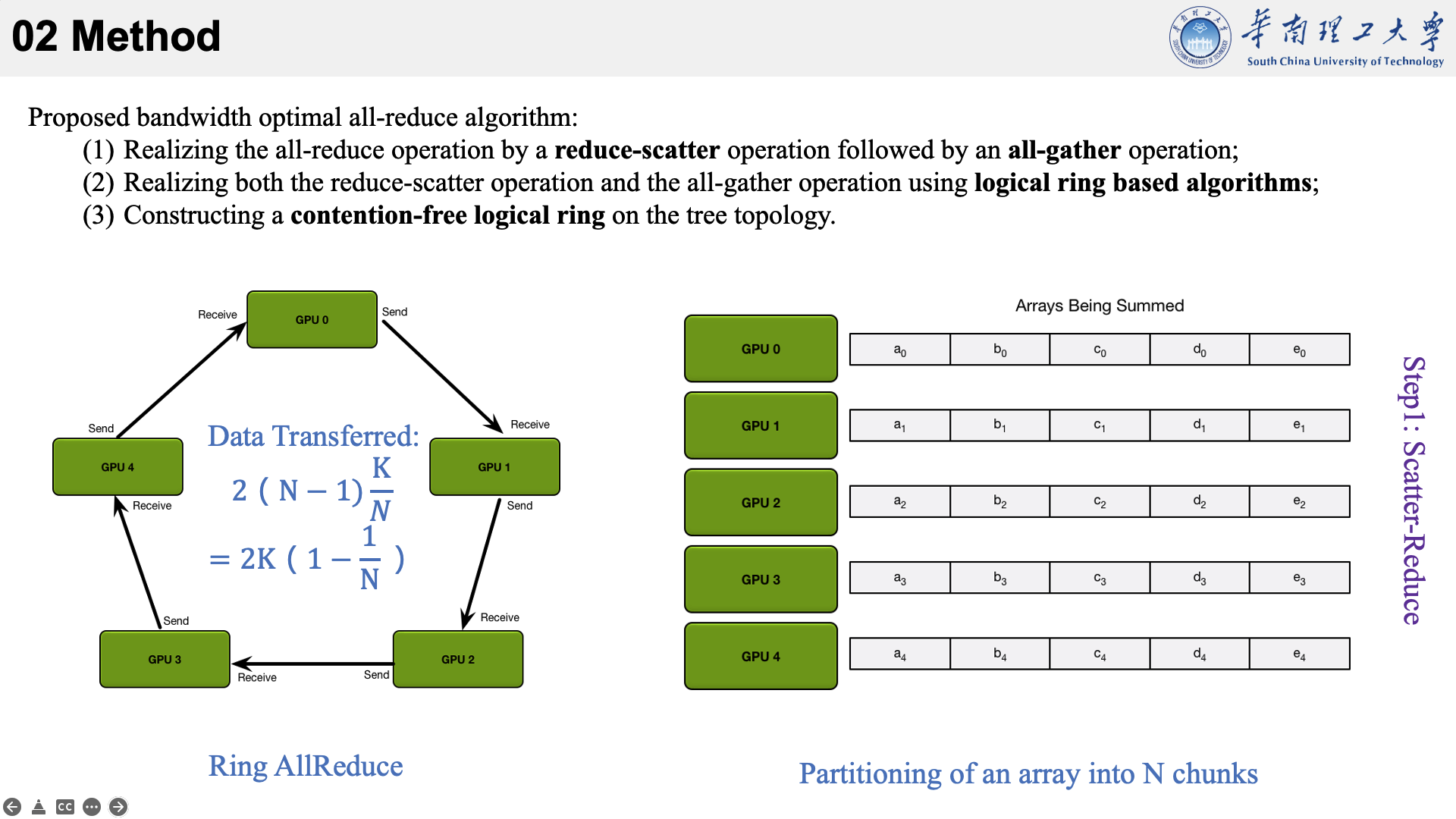
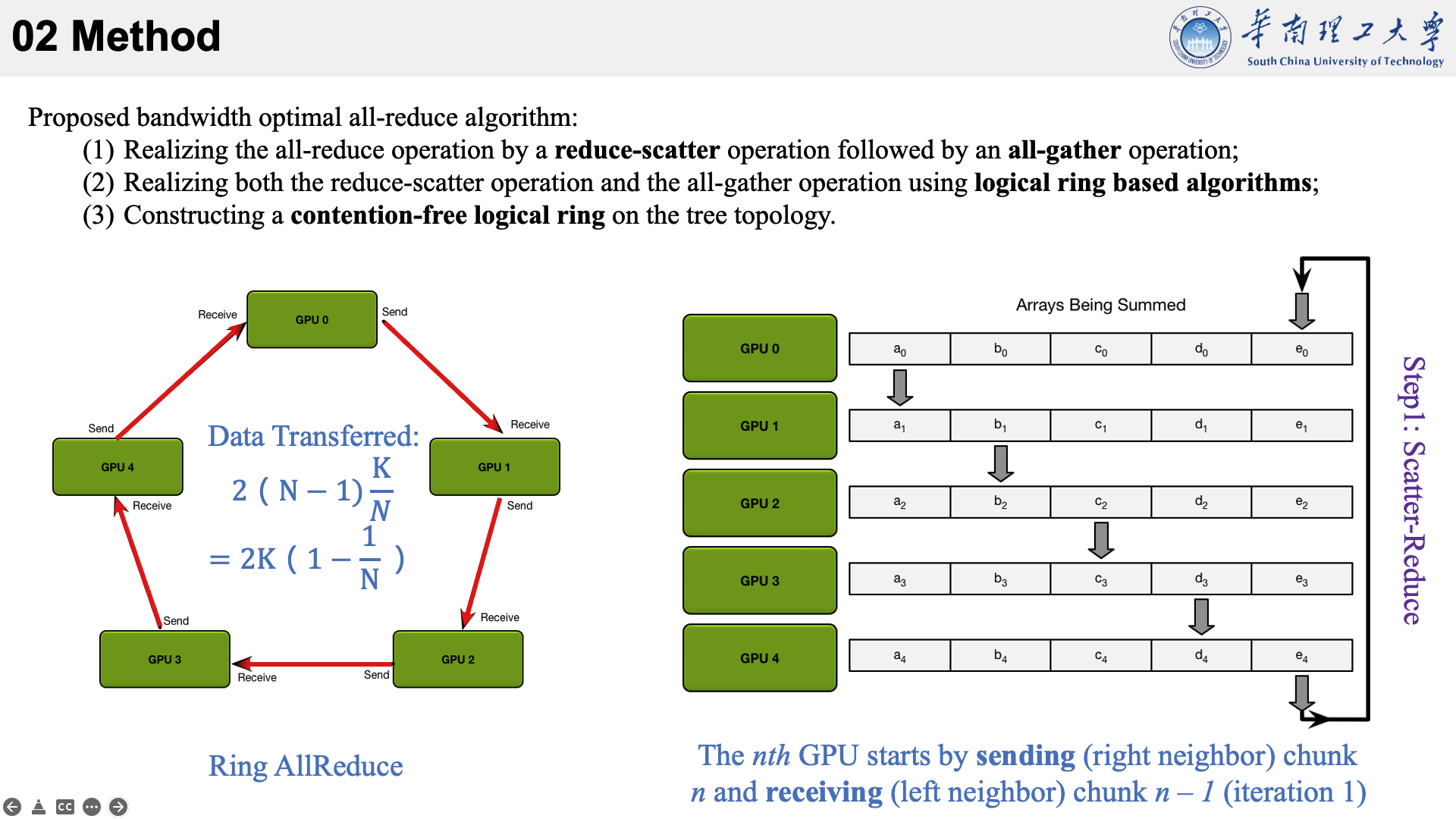
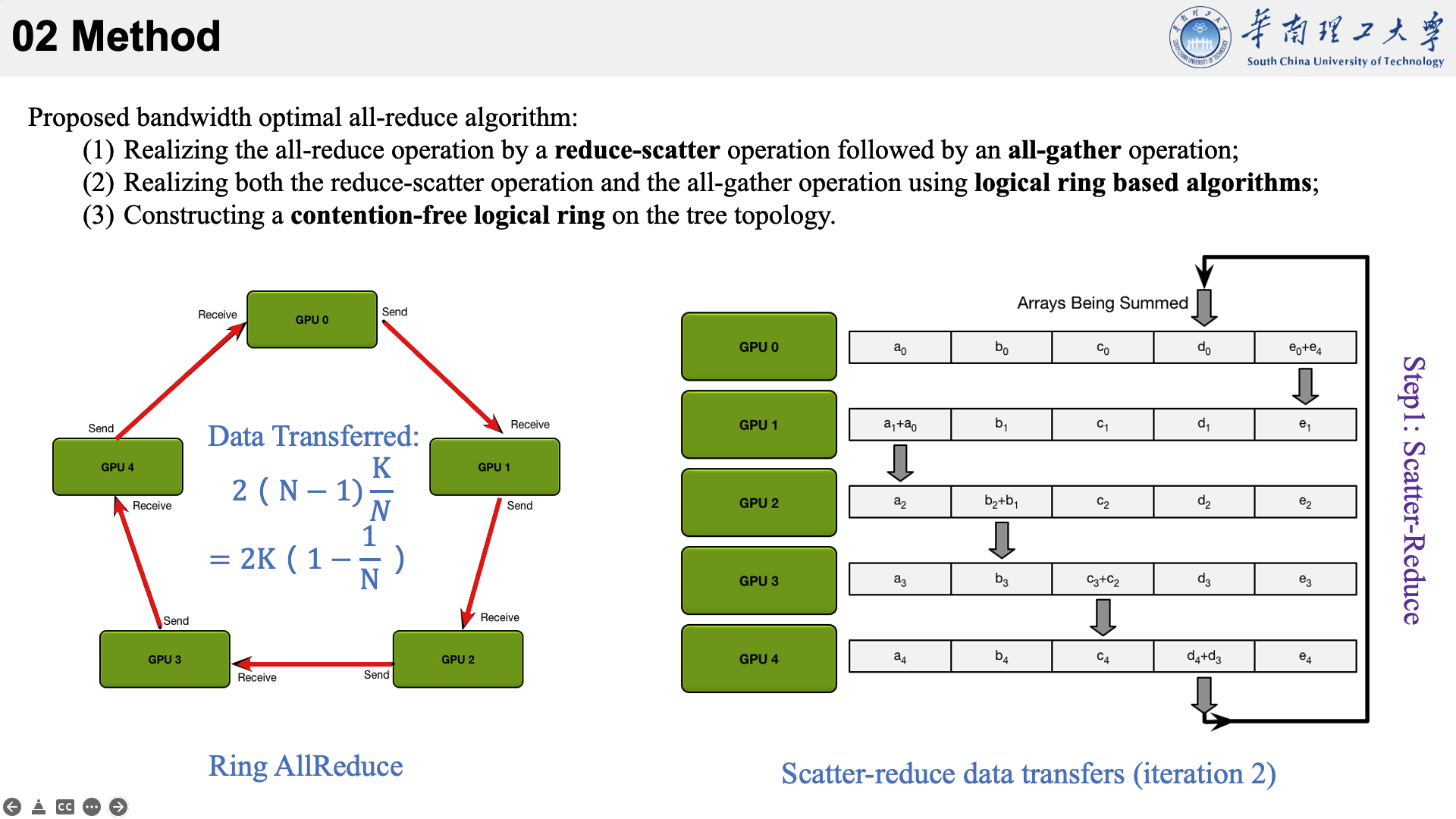
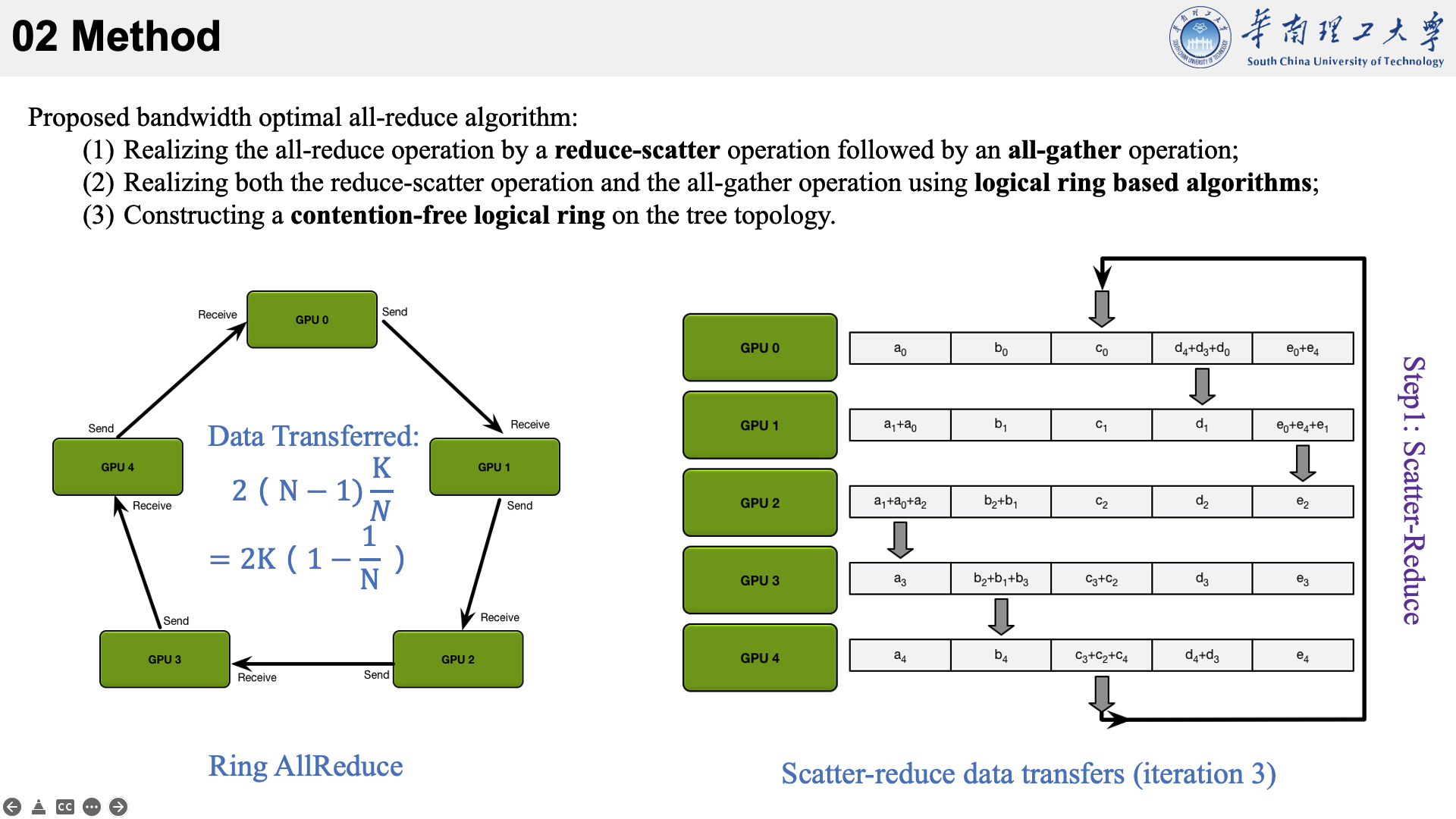
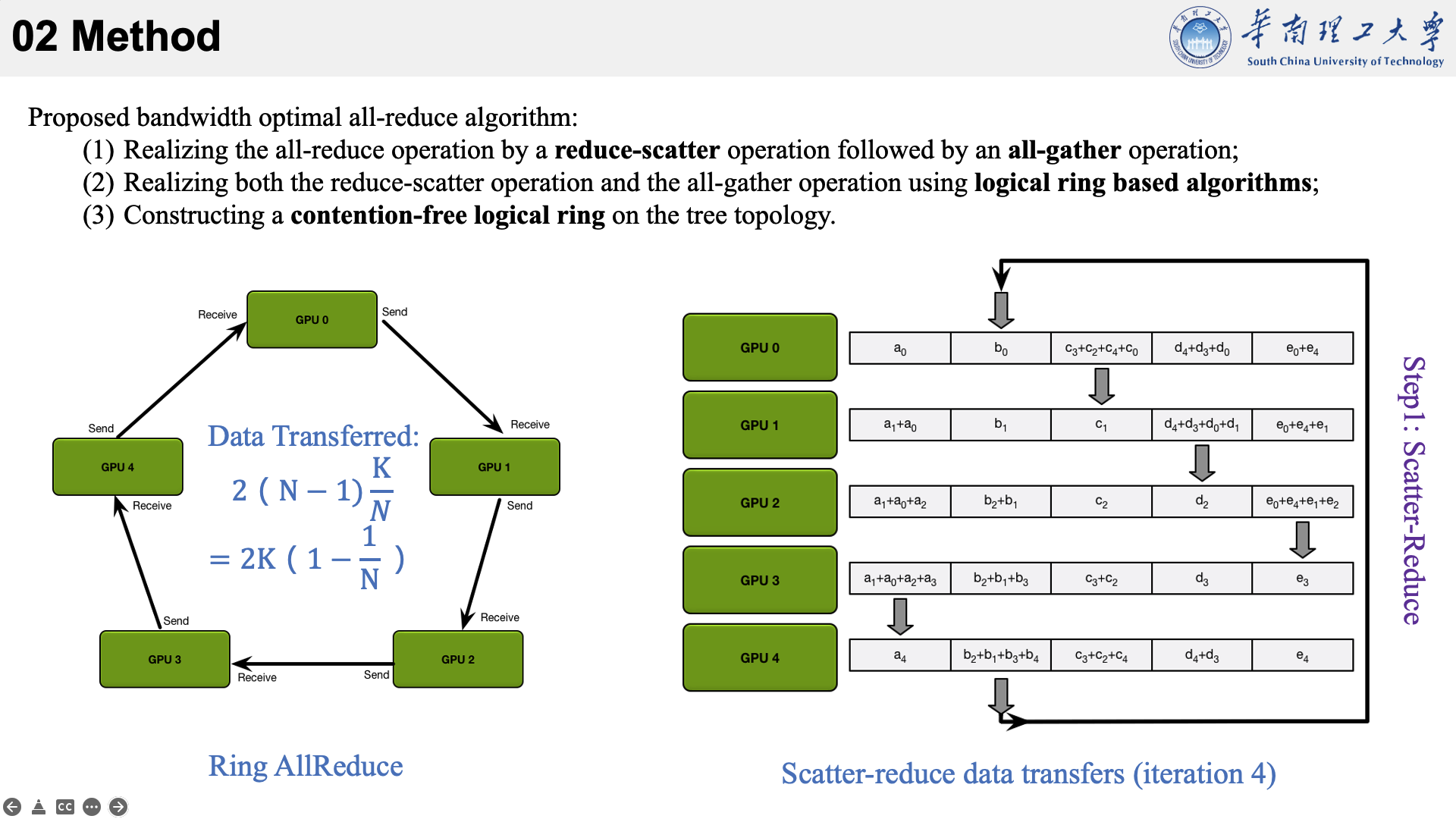
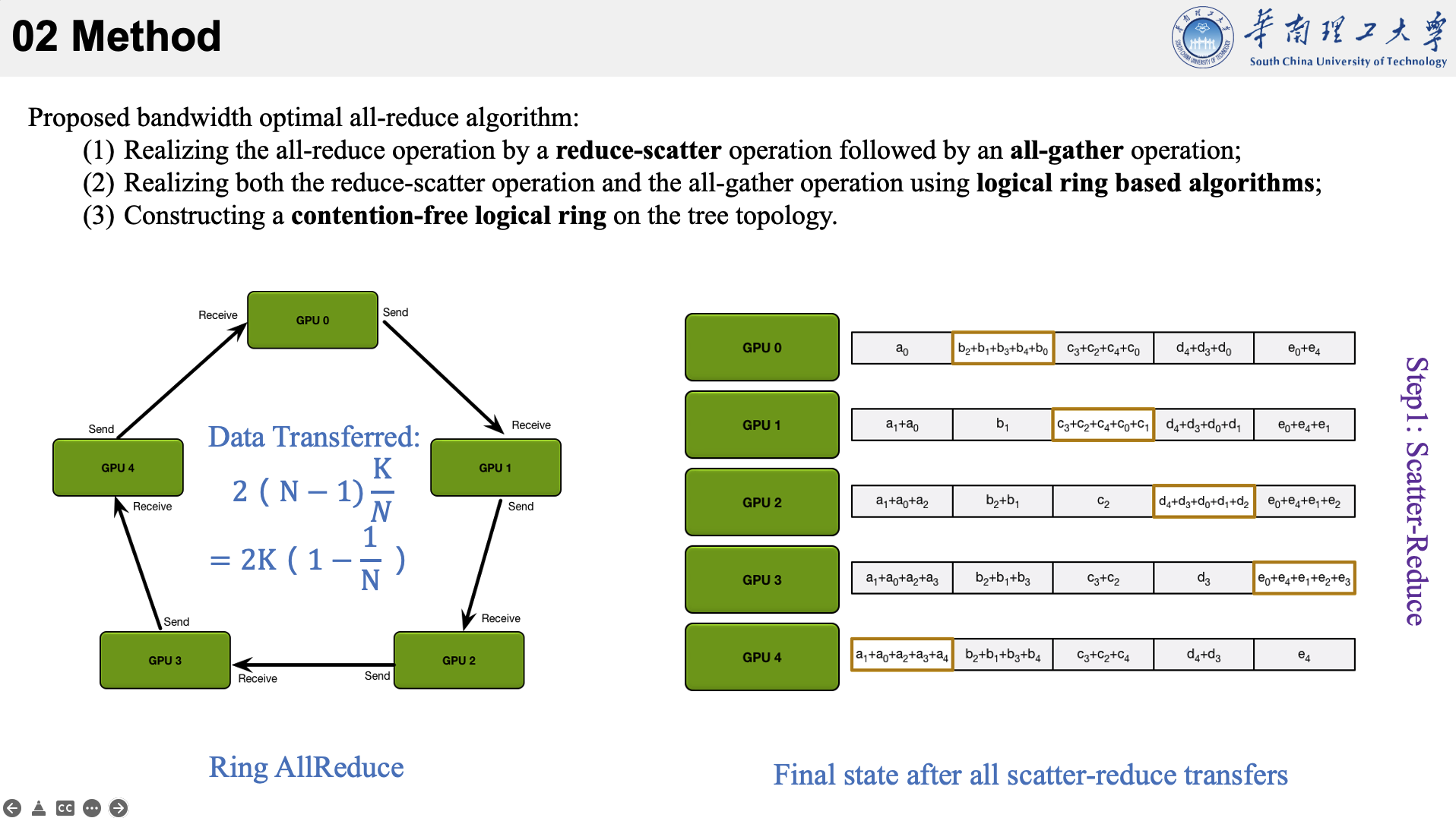
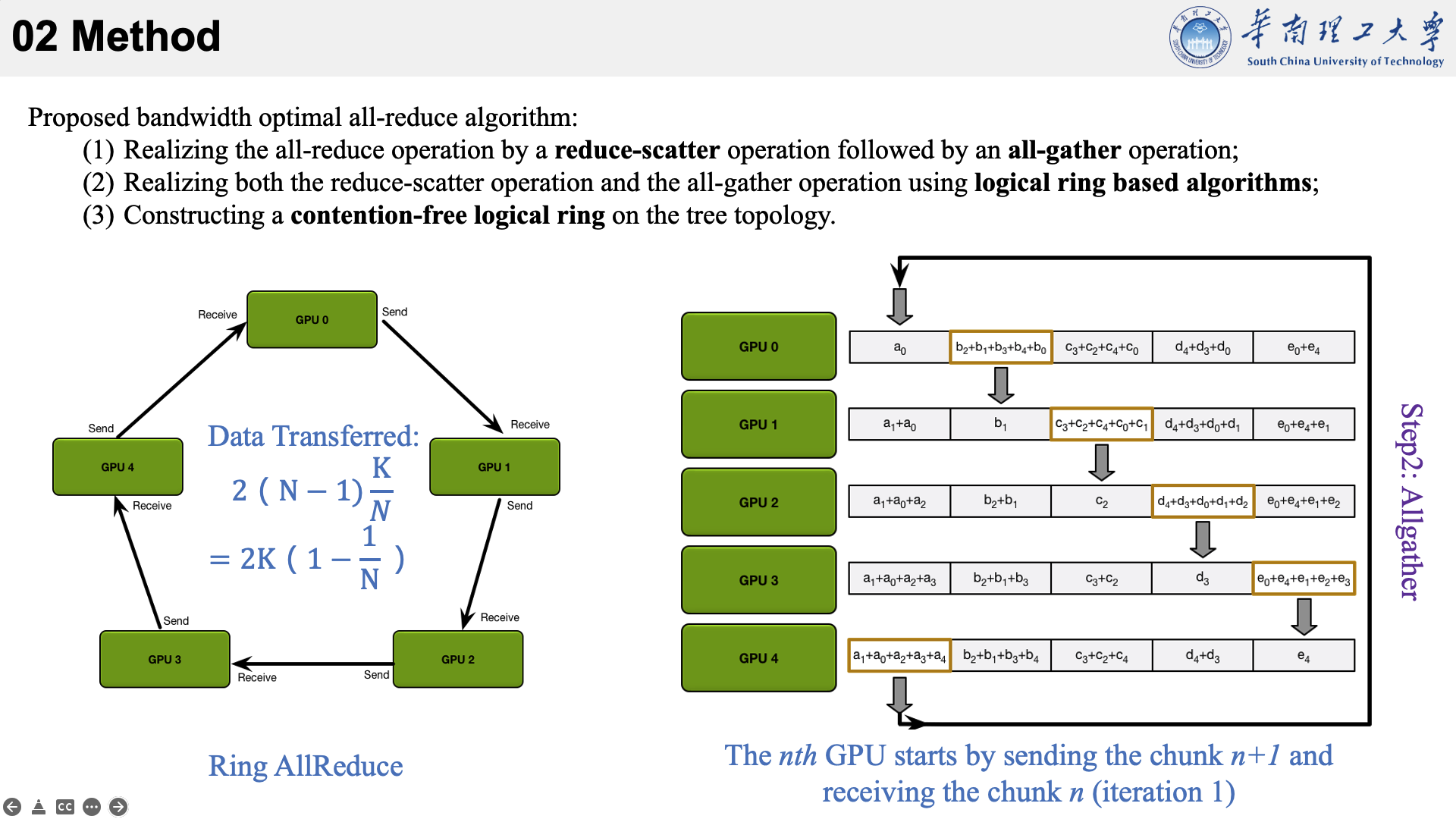
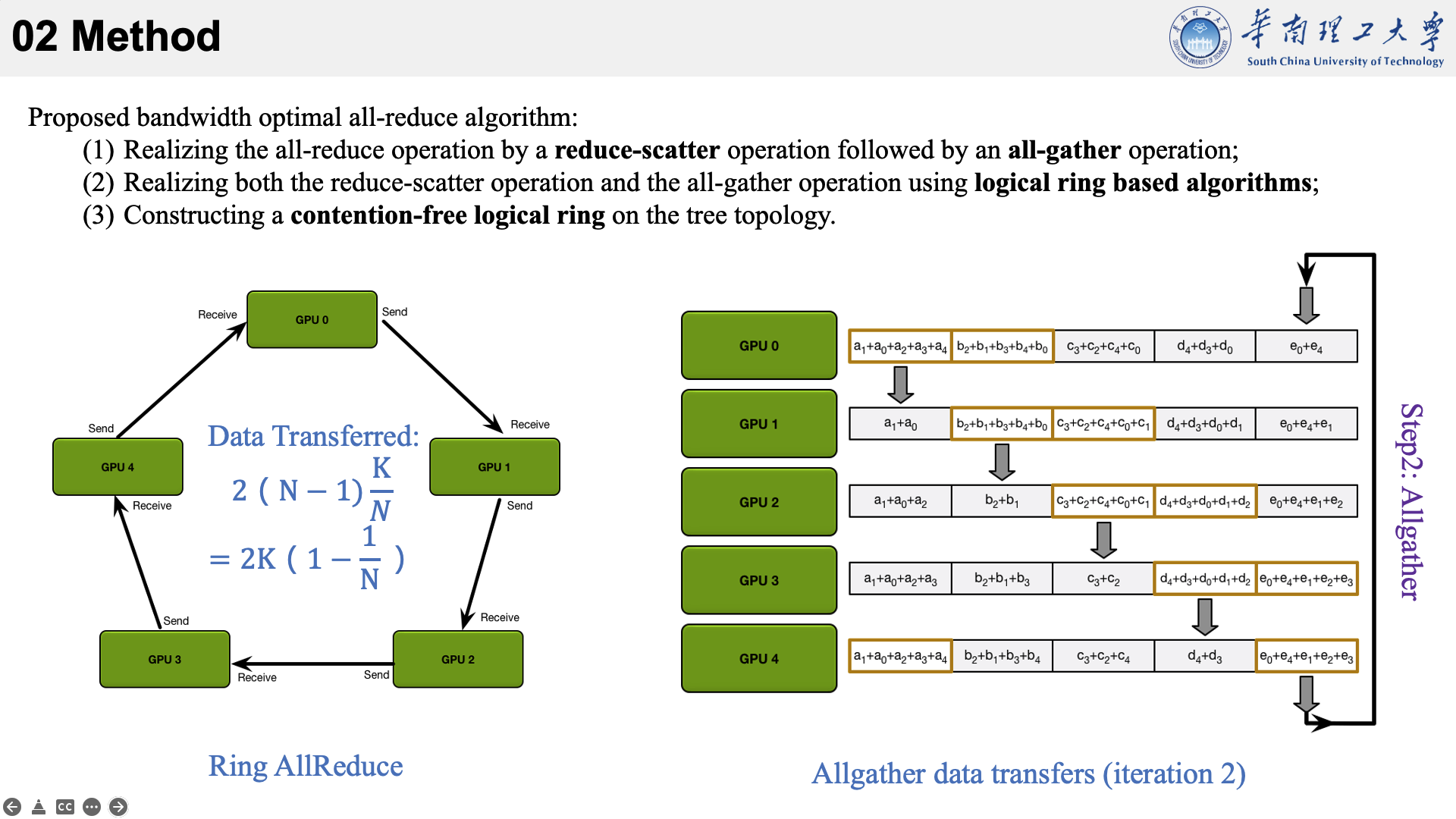
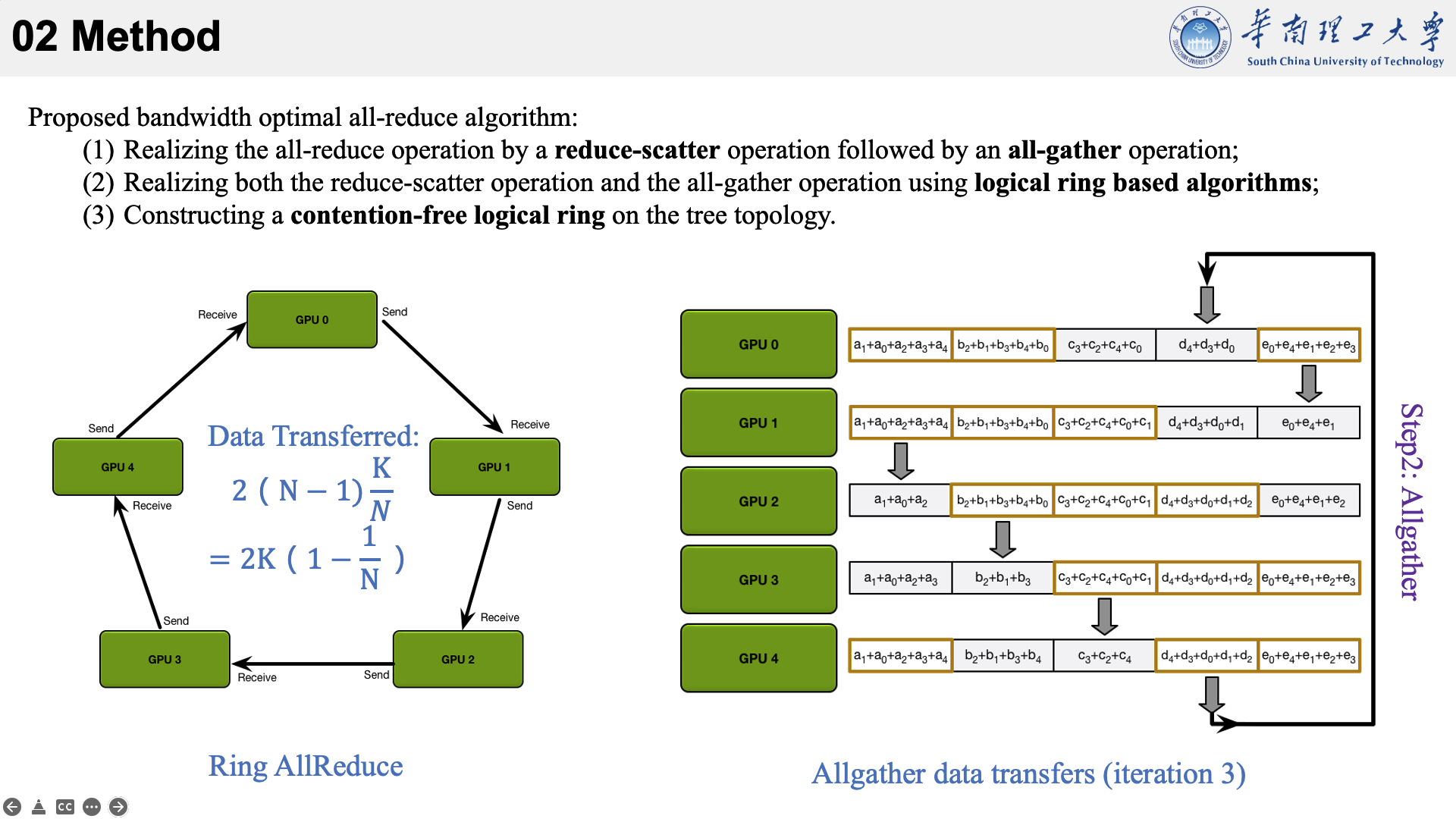
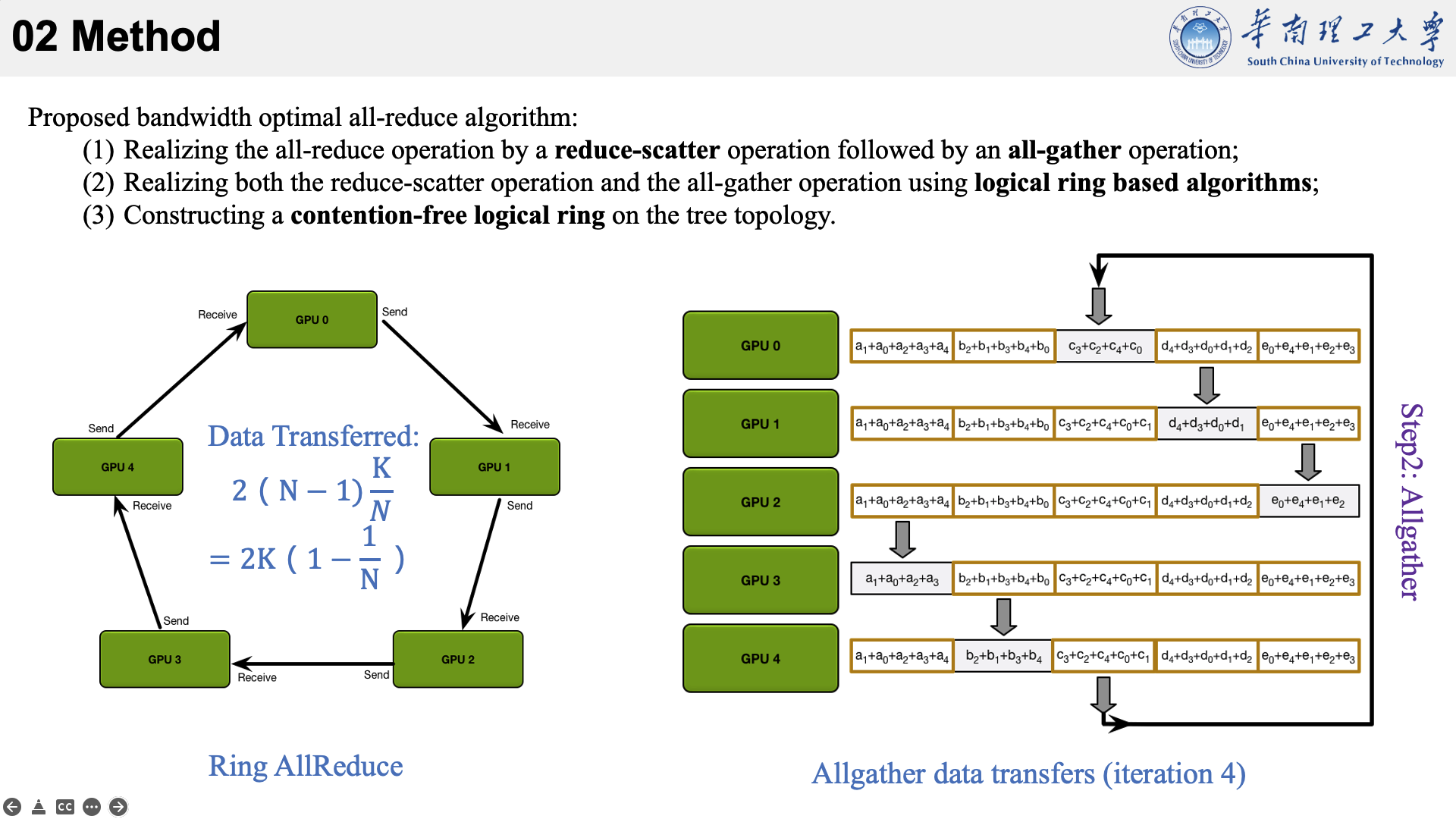
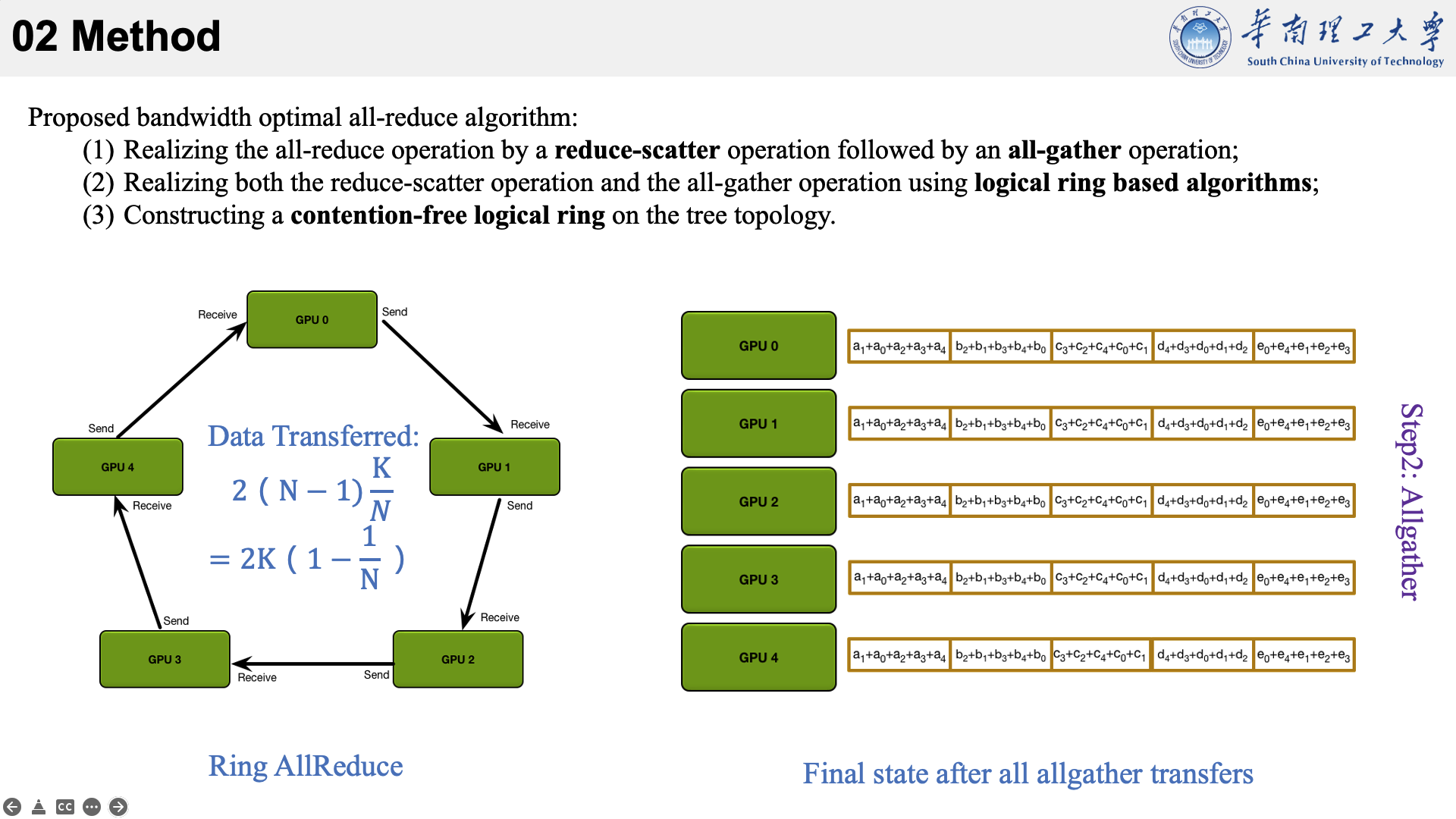
所提的方法主要是结合了三种现有技术于一身。以下图为例,看一下他的执行流程。
首先将数据分为 N 个块,每个GPU负责1个块。
然后,第N个GPU发送第N个块,并接收第N-1个块。
……
这么做有什么好处呢?
每个 GPU 在Scatter Reduce阶段,接收 N-1 次数据,N 是 GPU 数量;每个 GPU 在allgather 阶段,接收 N-1 次数据;每个 GPU 每次发送 K/N 大小数据块,K 是总数据大小;所以,每个GPU的Data Transferred=2(N−1)*K/N = (2(N−1)/N)*K,随着 GPU 数量 N 增加,总传输量恒定!(我的理解是,随着N变大,1/N不断减小,总传输量趋近于固定值?)总传输量恒定意味着通信成本不随 GPU 数量增长而增长,也就是说我们系统拥有理论上的线性加速能力。
allreduce的速度受到环中相邻GPU之间最慢(最低带宽)连接的限制。给定每个GPU的正确邻居选择,该算法是带宽最优的,并且是执行allreduce的最快算法(假设延迟成本与带宽相比可以忽略不计)。

在Pytorch中有两种实现分布式数据并行训练的方式,分别是DP和DDP。DP由于只在主进程中管理多个任务和更新参数,因此其计算量和通讯量都很重,训练效率很低。
现在普遍用的较多的是DDP的方式,简单来讲,DDP就是在每个计算节点上复制模型,并独立地生成梯度,然后在每次迭代中互相传递这些梯度并同步,以保持各节点模型的一致性。
而在pytorch中的DDP实际就是使用了Ring-ALLReduce来实现AllReduce算法。
DDP的执行流程大致如下:
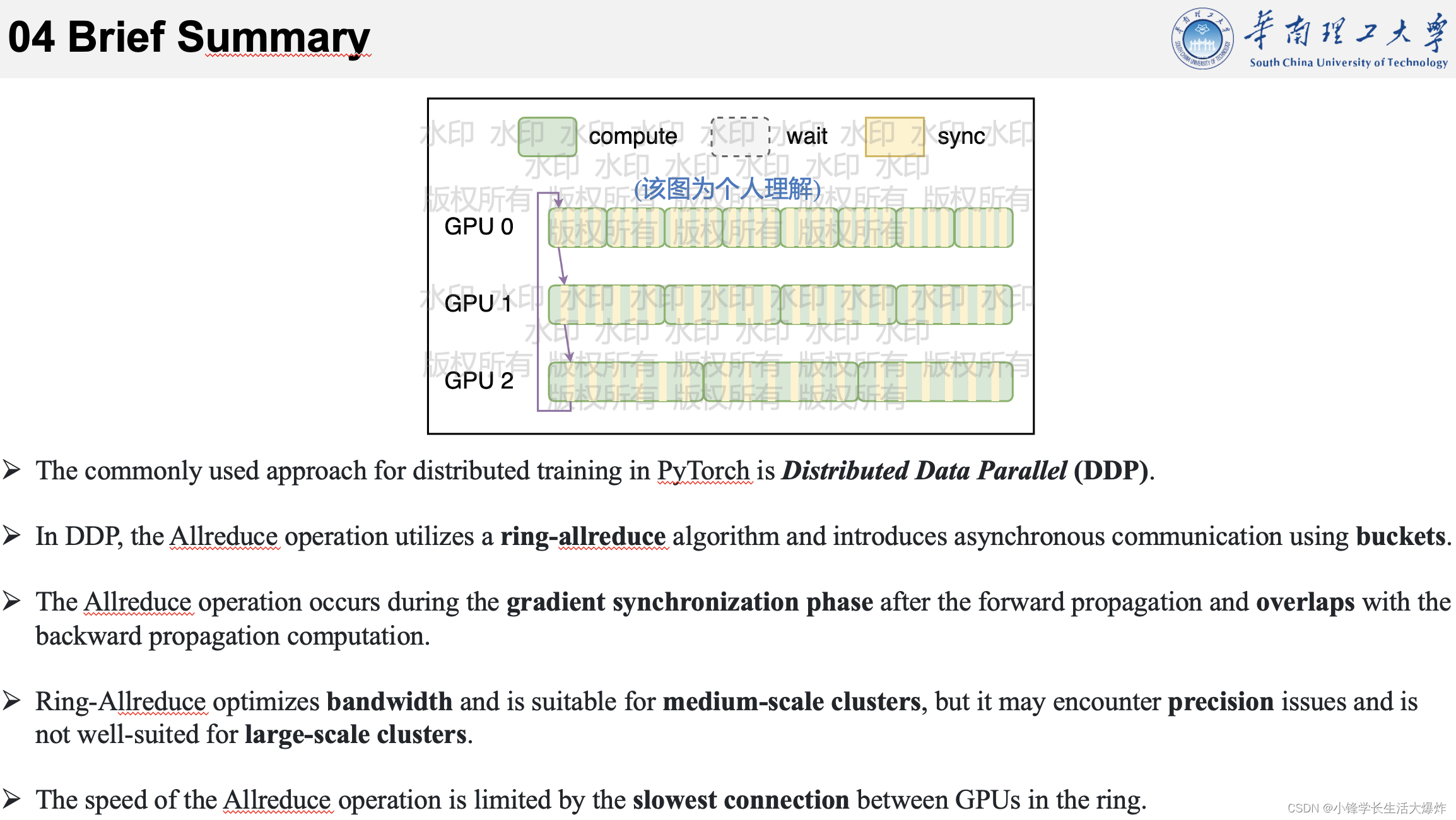
各个GPU首先进行环境初始化和模型的广播,使初始状态相同。然后初始化模型bucket和reducer。在训练阶段,通过采样获取数据,计算前向传播,然后进行反向传播和使用all-reduce进行梯度同步,最后完成参数的更新。
这里说明了allreduce是在前向传播完成后用于梯度同步的,并且提到了一个新词 bucket。
(模型参数以(大致)与给定模型 Model.parameters() 相反的顺序分配到存储桶中。使用相反顺序的原因是,DDP 期望梯度在向后传递期间大致按照该顺序准备就绪。)

实际上,DDP中的设计是通过将全部模型参数划分为无数个小的bucket,然后在bucket级别建立allreduce。比如当所有进程中bucket0的梯度计算完成后就立刻开始通信,而此时bucket1中梯度还在计算。
这样可以实现计算和通信过程的时间重叠。这种设计能够使得DDP的训练更高效,可以在参数量很大时,获得很好的加速效果。
简单总结一下前面的内容。
1、Pytorch中分布式训练用的比较多的是DDP;
2、DDP中的Allreduce使用的是ring-allreduce,并且使用bucket来引入异步;
3、Allreduce发生在前向传播后的梯度同步阶段,并且与反向传播计算重叠;
4、Ring-allreduce优化了带宽,适用于中规模的集群,但其可能存在精度问题,切不适合大规模的集群;
5、allreduce的速度受到环中相邻GPU之间最慢连接的限制;
![P5691 [NOI2001] 方程的解数](https://img-blog.csdnimg.cn/7d891b1824504d8ea8aea31eb8be8709.png)