BIM 模型中的一个基本数据是对象的名称,尤其是房间。 没有专有名称,人们就不可能理解模型/设计的内容。 在本文中,我们尝试使用 Tensorflow 构建一个基于该数据识别房间的LSTM神经网络模型。

推荐:用 NSDT设计器 快速搭建可编程3D场景。
如果你只需单击一下即可确定建筑物包含哪些类型的空间,该怎么办? 这肯定会在工程方面实现良好的工作流程,特别是在暖通空调领域,你希望根据空间进行处理。 这也是投资者想要了解的事情,以便知道他将能够出售多少面积。
要实现这一目标,首先要做的是查看可用数据。 根据经验,BIM 模型中“空间/房间”对象中一致存在的唯一信息是标高名称、表面、周长和名称。 使用计算并根据软件的不同,还可以检测空间内和周围的物体以及其他信息。 这里采取的方法是选择包含最多“价值”(英特尔)的信息来确定空间的性质,因此选择空间的名称:理论上可以推断出空间的用途 空间。 我们还选择关注一种建筑类型(办公室)。
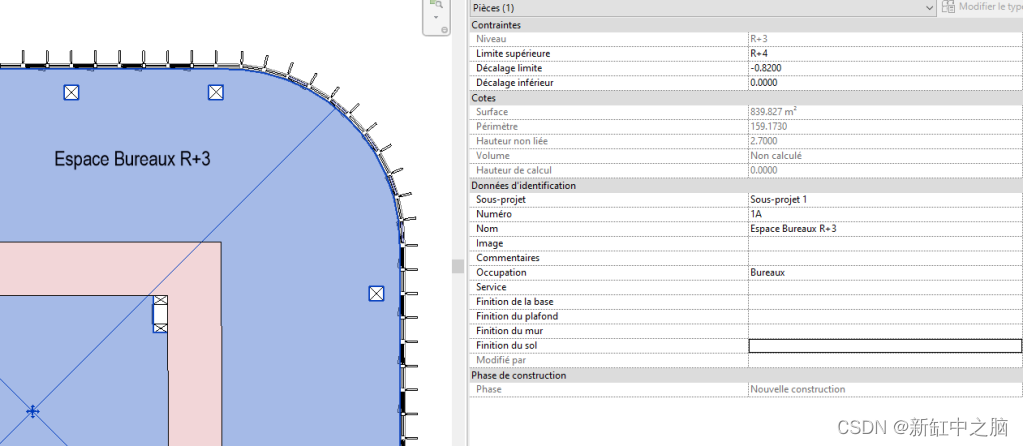
在 BIM 模型空间中找到的典型数据
名称是短字符串,通常没有任何空格(单个单词)。 因此,很难使用最常见的文本处理技术,这些技术应用于文本和句子并且基于单词。 然而,字符本身就是完全可用的单词特征。 通过对名称进行一些预处理(用普通字符替换特殊字符,用“0”替换数字…),可以使字符成为相关特征。
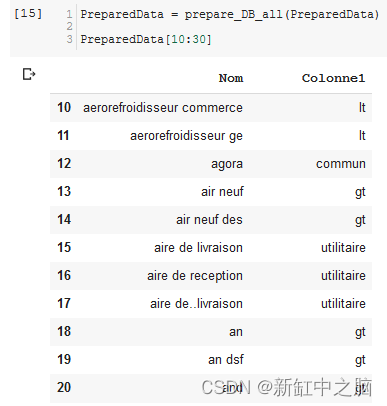
左边是空间的(法语)名称。 右边是我们想要将它们分类到的相应标签。
鉴于名称是字符序列,选择分析它们的模型是一个循环模型:它的预测基于它正在查看的字符,但也基于之前的字符以及它们之间的顺序。 为了更好地适应任务,使用 LSTM(将重要信息保存在内存中,并且在长序列中很有用)并使其双向(在序列上沿一个方向和反向运行)被证明是有益的。 最后,在大约 4000 个房间/空间的列表中,尝试将它们分为 14 个不同的类别(我们选择了办公楼:办公室、浴室、技术室……),该模型达到了大约 97% 的精度。 例如,向工程师提出建议似乎很好,而不是让他自己对所有内容进行分类。
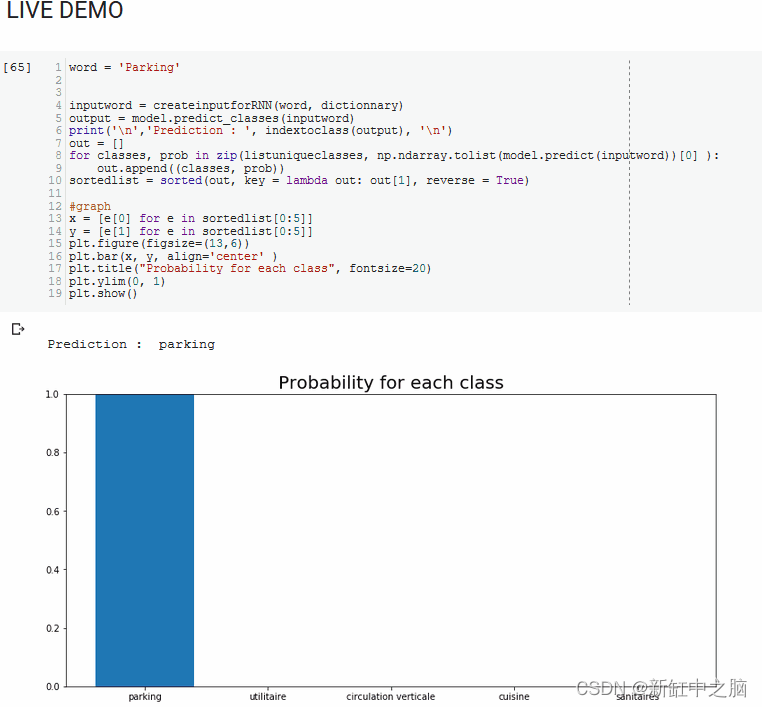
现场测试:提交一些(法语)房间名称,模型猜测它们可能是什么类型的房间
值得注意的是,很多房间名称都是重复的,这有助于获得良好的准确性。 修剪重复项会将空间名称数量减少到 1500 以下。在没有重复项的列表中,该模型达到约 80-85%。 “现实世界”的准确率将在 80% 到 97% 之间(因为在实际项目中也会出现重复)。
本文代码可以从github下载。
原文链接:基于LSTM的BIM对象识别 — BimAnt