文章目录
- 前言
-
- 资源
- deepspeed
- 一、训练的坑
- 二、推理的坑
- 三、继续训练的坑
- 总结
前言
资源
单机两4090,如图
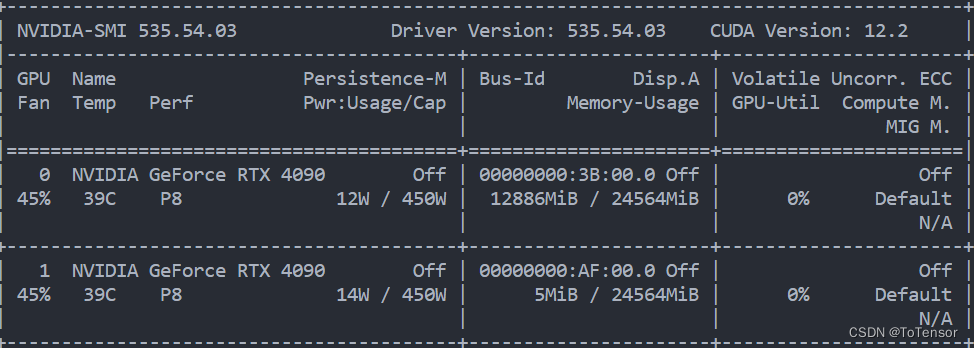
单卡24G,baichuan-13b-chat单卡推理需要至少26G,因此仅用一张卡,我们是无法加载百川13B的模型,所以,无论是推理还是训练,我们都必须并行!
deepspeed
核心思想:GPU显存不够,CPU内存来凑
虽然我们两张卡加起来有48G,按理说显存是足够的,实则不是。
就两张卡而言,分别为GPU0和GPU1,两块GPU上分别有一半模型参数,即6.5B,占用13G,在使用deepspeed的参数并行进行前向传播时,GPU0需要把自己身上的参数传给GPU1临时保存起来,参与前向传播,这时,GPU1身上的参数即为整个模型的参数