文章目录
- 一、Callable 接口
- 二、JUC的常见类
- 1. ReentrantLock
- 2. 原子类(简单知晓)
- 3.信号量 Semaphore
- 4.CountDownLatch(简单了解)
- 三、线程安全的集合类
- 1.多线程环境使用 ArrayList
- 2.多线程使用哈希表
一、Callable 接口
Callable 接口类似于 Runnable 接口
Runnable 接口用来描述一个任务。这个任务没有返回值。
Callable 也是用来描述一个任务,描述的任务有返回值。
如果要使用一个线程单独计算出某个结果,此时使用 Callable 比较合适。
Callable 的使用方式:
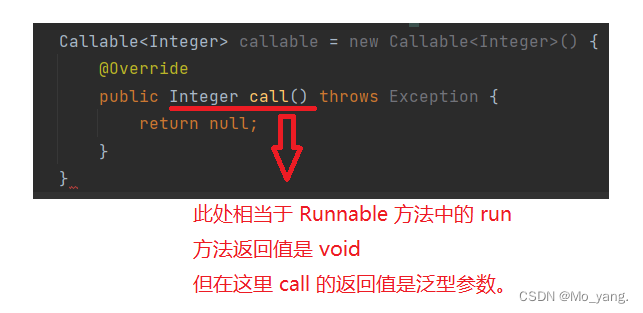
这里不能直接引用到线程中,如图:

要将 Callable 传入到 Thread 的构造方法中,这里需要加上一层辅助类。如图:

在外部套上一个未来任务的泛型类就可以传入到Thread中。

二、JUC的常见类
java.util.concurrent 简称为 JUC 其中含有多种并发编程(多线程)的相关组件。
1. ReentrantLock
这个锁和 synchronized 锁十分相似,都是可重入互斥锁。
这里的 ReentrantLock 使用起来更加传统,使用的是 lock 和 unlock 方法进行加锁解锁。
synchronized 是基于代码块的方式来加解锁的。
使用方法如图:
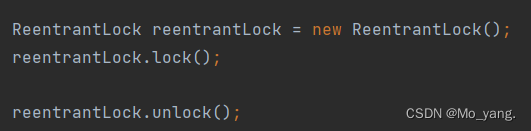
这样的写法内部有着很大的问题,有可能程序员最后忘记 unlock ,如果代码中存在 return 或者异常就执行不到 unlock。这都是影响代码安全的问题。
虽然这个锁有着很多的劣势,但是仍然还是可以克服的,除此之外,它还有下面的几点优势:
- synchronized 是非公平锁, ReentrantLock 默认是非公平锁. 可以通过构造方法传入一个 true 开启公平锁模式
- 对于 synchronized 来讲,提供的加锁操作就是 “死等”。
但是 ReentrantLock 提供了更加灵活的等待方式:tryLock,有下面两种版本。

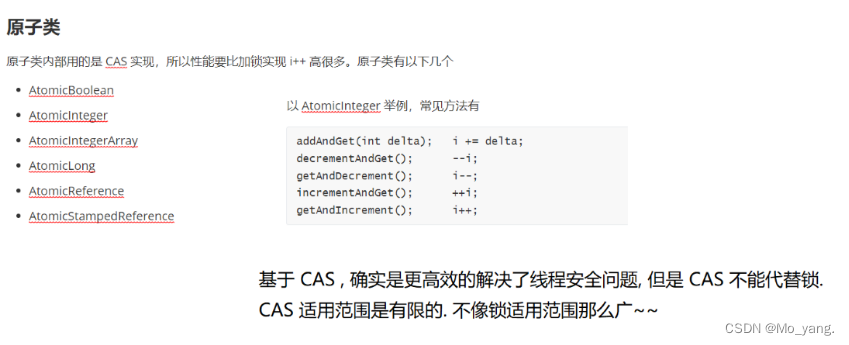
2. 原子类(简单知晓)
3.信号量 Semaphore
信号量,用来表示 “可用的资源个数”。本质上是一个计数器。
- P操作: 申请一个可用资源,计数器 -1.
- V操作: 释放一个可用资源,计数器+1.
当 P 操作时计数器为 0 ,继续 P 操作,就会出现阻塞等待的情况。
在这里设想一个停车场的场景简单解释一下,如图:


4.CountDownLatch(简单了解)
这个关键字表述的是,同时等待 N 个任务执行结束。
为了更好的理解这个关键字,这里在设想一个场景。
假设,有一个 4 人的跑步比赛。

- 这里跑步开始的时间是明确的(发令枪)
- 结束时间不明确(最后一个选手冲过重点线)
这里主要使用的方法有下面两个:
- await(): 主线程中使用 latch.await(); 阻塞等待所有任务执行完毕. 相当于计数器为 0 了.
需要注意的是,这里的 await中(wait 是等待,a => all 表示全部的意思)。
但是,在后面见到的很多术语中,a前缀的,大都表示 “异步”。
解释同步,异步:

- latch.countDown(): 在 CountDownLatch 内部的计数器同时自减.
四个选手同时比赛,await就会阻塞,前三次调用 countDown ,await 没有任何响应。当第四次调用 countDown ,await 就会被唤醒(解除阻塞)。此时认为比赛结束了。
三、线程安全的集合类
1.多线程环境使用 ArrayList
- 自己加锁,自己使用 synchronized 或者 ReentrantLock
- Collections.synchronizedList 这个会提供一些 ArrayList 的相关方法。同时是带锁的。使用方法如下:
Collections.synchronizedList(new ArrayList)
synchronizedList 的关键操作上都带有 synchronized
- CopyOnWriteArrayList,这个关键字也被称为 COW,也叫做 “写时拷贝”。
- 当针对这个 ArrayList 进行 读 操作,此时不做任何额外的工作。
- 如果进行 写 操作,则要拷贝一份新的 ArrayList,针对新的进行修改,此时,如果有读操作,就先继续读 旧 的数据。当修改完毕,此时新的数据替换旧的数据。
上面的写时拷贝有着很明显的优缺点:
优点: 在修改时不需要进行加锁。
缺点: 比较耗费空间,要求这个 ArrayList 不能太大。
这种方法可以运用到像,服务器的配置,维护,数据库的更新迭代等场景。
2.多线程使用哈希表
在这里,HashMap 是线程不安全的,HashTable 是线程安全的因为这里给关键方法添加了 synchronized。
这里更推荐使用的是 ConcurrentHashMap 这需要思考一下,ConcurrentHashMap 进行了那些优化,不 HashTable 好在哪里?两者之间有什么区别?
- 优化之处: ConcurrentHashMap 相比于 HashTable 大大缩小了锁冲突的概率。将一个大锁锁全部,改变成许多小锁共同操作。
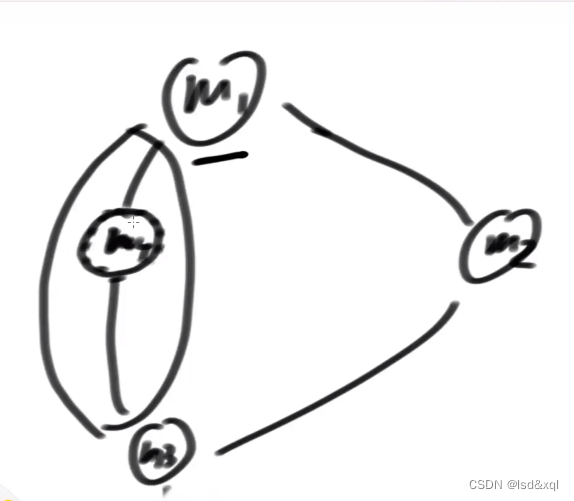
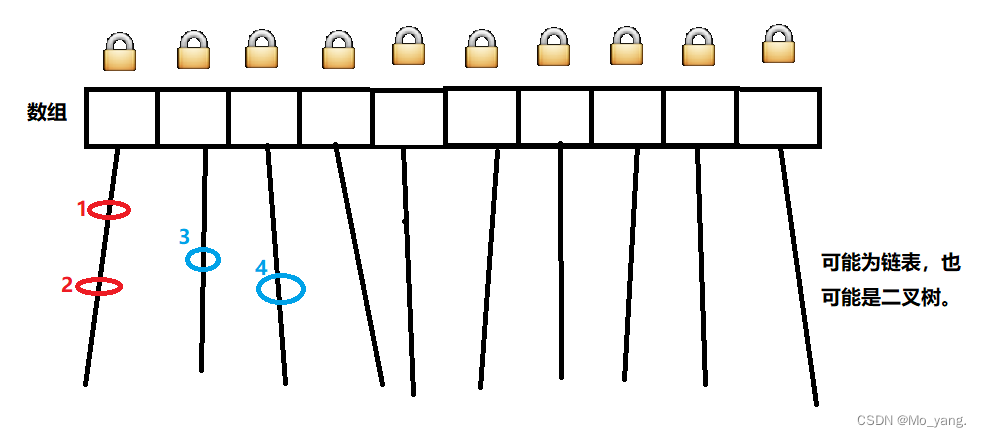
这里我大概展示一下 HashTable 的逻辑形式,如图:
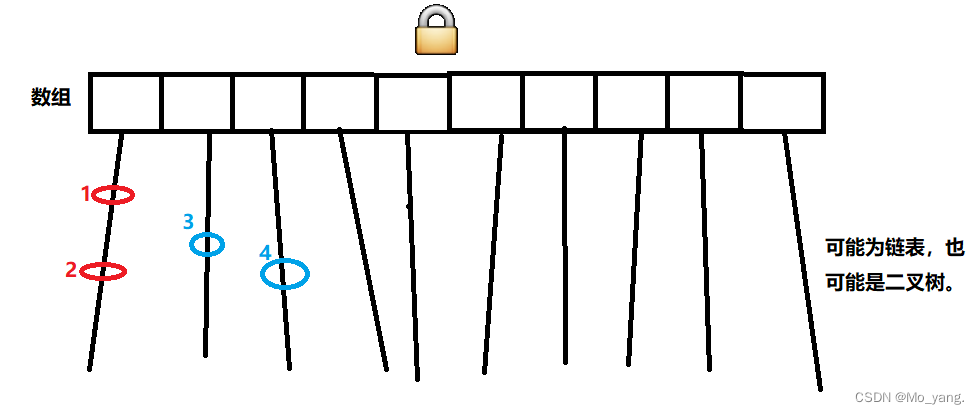
HashTable 的做法是直接在方法上添加 synchronized,就是给整体进行了加锁,只要操作哈希表上的任何数据都会进行加锁,也就会发生锁冲突。
情况1: 如上图所示,1,2 元素在同一个链表上。此时 A 线程修改元素1,B线程修改线程2 此时会存在线程问题,就需要进行加锁处理。
情况2: 此时,如果线程A修改元素3,线程B修改元素4,因为不在一个链表上这种情况就不需要加锁。
根据上述情况,不使用 HashTable 原因就很明确了,HashTable 的锁冲突率太大,任何的两个元素都会冲突即使在不同的两个链表。
ConcurrentHashMap 的逻辑形式,如图:
此时,锁的粒度减小了,面对 1,2 这样的情况会出现锁竞争,面对 3,4 这样的情况就不会竞争,这样就提高了代码的效率。
-
ConcurrentHashMap 有一个相对激进的操作,针对读操作不进行加锁,只针对写操作加锁
读和读,之间没有冲突。
写和写,之间存在冲突。
读和写,之间没有冲突。
但是要注意的是,这里的读和写虽然没有冲突,但是,如果读写之间不进行加锁操作,就有可能读到一个写了一半的元素,产生脏读。要处理这样的问题,还有一个办法就是将写操作设定为原子性的(使用 volatile 关键字)。 -
对于扩容,ConcurrentHashMap 使用了 “化整为零” 的方式。
HashTable 扩容:
创建一个更大的数组空间,将旧的数组上链表的元素搬运到新的数组上。此时当元素数量较多时,这样的搬运操作比较耗时!
ConcurrentHashMap 扩容方式:
这里采取的是每次搬运一小部分的方式。创建新的数组,旧的数组也保留,
每次 put 时,都在新的数组上添加,同时执行一部分搬运。
每次 get 时,旧数组和新数组都进行查询。
每次 remove 时,只是删除元素即可。
经过一段时间后,完全搬运完毕,释放就数组即可。 -
ConcurrentHashMap 内部使用了 CAS 通过这个办法来进一步削减加锁操作的数目。例如:维护元素的个数。