算法拾遗三十六hash
- 哈希函数特点
- hash表设计
- 布隆过滤器
- 布隆过滤器三大公式
- 最终求解公式
- 一致性哈希
- 经典数据存储
- 经典hash缺点及解决方案
- 虚拟节点
哈希函数特点
输入:任意长度字符串(输入域无穷大)
输出:相对有限
哈希函数无任何随机成分(输入相同,一定导致每次都一样的输出)相同的输入一定有相同的输出
问题点:
哈希碰撞:输入不同,但是出现的输出结果相同
对于大量的输入,它会非常离散的分布在整个输出域上面。固定长度命中点数量差不多。【此时需要hash函数根元数据的输入状况给解耦掉】
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.security.Security;
import javax.xml.bind.DatatypeConverter;
public class Hash {
private MessageDigest hash;
public Hash(String algorithm) {
try {
hash = MessageDigest.getInstance(algorithm);
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
}
public String hashCode(String input) {
return DatatypeConverter.printHexBinary(hash.digest(input.getBytes())).toUpperCase();
}
public static void main(String[] args) {
System.out.println("支持的算法 : ");
for (String str : Security.getAlgorithms("MessageDigest")) {
System.out.println(str);
}
System.out.println("=======");
String algorithm = "MD5";
Hash hash = new Hash(algorithm);
String input1 = "lsdlsdlsdlsdtest1";
String input2 = "lsdlsdlsdlsdtest2";
String input3 = "lsdlsdlsdlsdtest3";
String input4 = "lsdlsdlsdlsdtest4";
String input5 = "lsdlsdlsdlsdtest5";
System.out.println(hash.hashCode(input1));
System.out.println(hash.hashCode(input2));
System.out.println(hash.hashCode(input3));
System.out.println(hash.hashCode(input4));
System.out.println(hash.hashCode(input5));
}
}
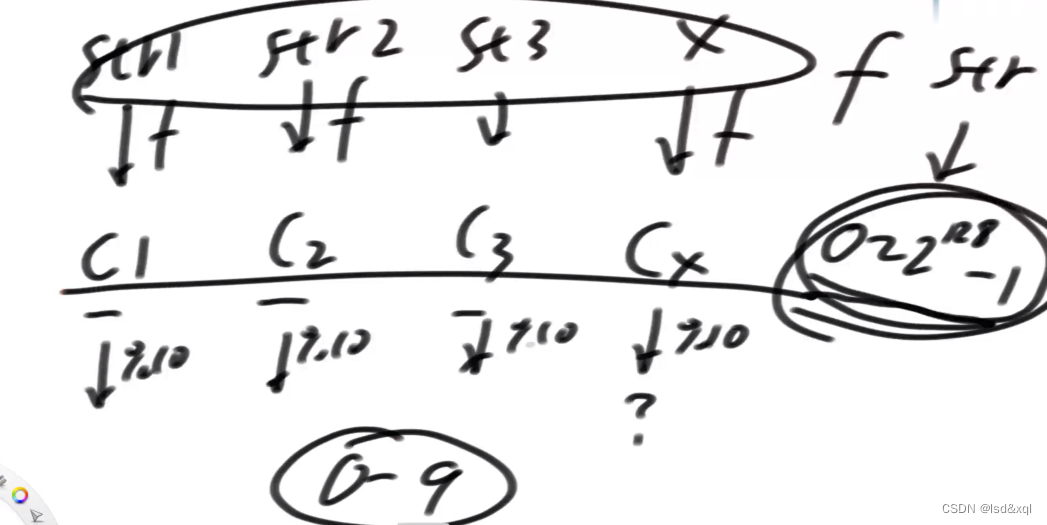
给定字符串str1和str2以及str3,分别经过一个hash函数得到c1,c2,c3,在0-2的128次方减一上均匀分布,那么我对c1,c2,c3都进行取模运算,得到结果也会在0-9上面均匀分布。
hash表设计
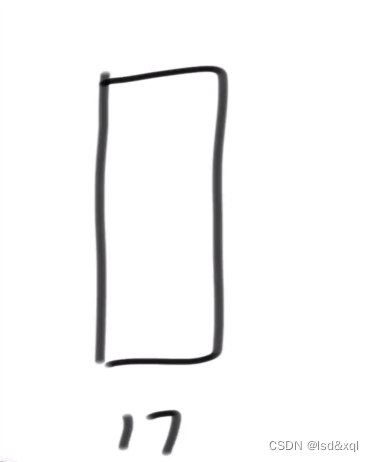
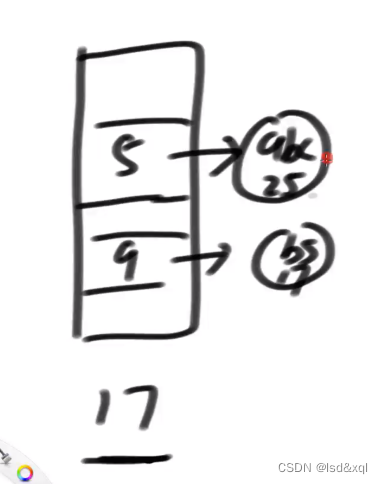
hash表有个初始的桶区域假设为17
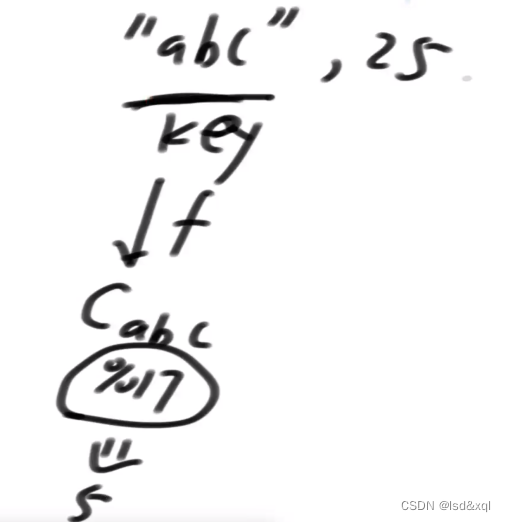
假设插入"abc",25,key是"abc"->计算一个hash值再模一个17得到结果为5
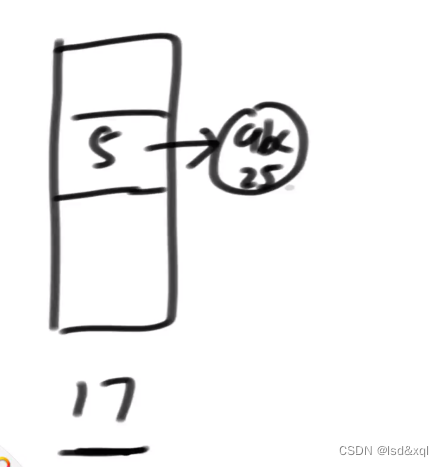
然后就把"abc"这条记录挂在5号桶里,然后桶通过单链表去放记录:
假设再来一条记录"bs",17,再通过hash函数计算再模一个17得到9
如果hash冲突了则顺着值往下挂:
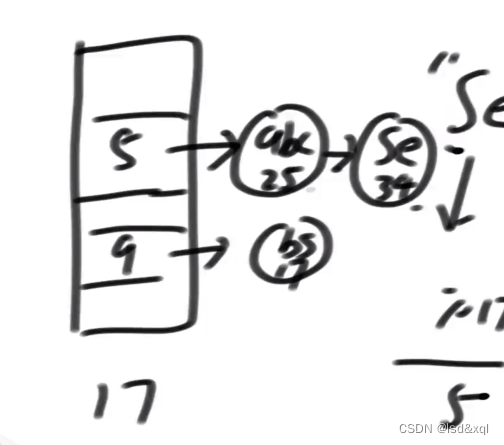
0-16号桶一定均匀增长,查询的话则通过key的hash值去找对应的桶,再去桶里面找到相应的记录。随着数据的逐步加入,每个桶挂载的数据会越来越多,一定会存在某个时刻觉得查询很慢,这里假设链长度超过6的时候是我觉得慢的时候,那么当我一个桶里面的链长度为6了那么也可以通过hash均匀分布得到其他桶的链长也为6了,那么则直接将桶空间的长度扩展两倍,然后重新计算hash重新挂桶。
布隆过滤器
有一个大集合,集合里面有很多URL黑名单,然后集合非常大,有一百亿的大小,然后每个URL不超过64个字节,然后需要把这个集合抽取成一个服务,以后出现一个URL我都查询一下这个URL是不是黑名单里面的,如果是黑名单里面的就不给用户展示,如果不在黑名单里面就展示。
如果是存入HashSet则需要6400亿字节的空间,就是640G的空间。
这种情况布隆过滤器就正常了,它能节省很多空间,但是布隆过滤器一定有失误率,我们需要通过程序控制失误率【失误率来自于我的URL如果不是黑名单里面的一份子,那么有几率会出现误报,如果我的URL本身就是黑名单里面的一份子那么不会失误】
再举一个例子:
比如说各个搜索引擎公司都要去做爬虫,比如说有一百个爬虫,爬虫1爬取了一个URL那么我需要一个服务去存这个URL,并让其他的爬虫不再爬取这个URL了,后面的爬虫就需要判断我是否爬取了这个URL,如果爬过就不爬了避免资源浪费
布隆过滤器三大公式
布隆过滤器可以看作是一系列逻辑加位图的整体,假设准备长度为m的bit类型数组,则占用m/8Byte空间,假设准备了三个hash函数,如果此时来了一个str1,str1会先执行hash函数1,将执行的结果对m取模,将得到的结果在bit数组上的某个位置标记,然后str1先执行hash函数2,将执行的结果对m取模,将得到的结果在bit数组上的某个位置标记,最后str1会执行hash函数3,将执行的结果对m取模,将得到的结果在bit数组上的某个位置标记。【三个hash函数是独立的不相互影响的】
查询则需要str重新计算3个hash函数看得到的最终位置是否都被标记过。
为防止m数组全被标黑那么m应该定多大?还有为了防止hash碰撞hash函数应该定几个?
如果m定很小,那么当黑名单多了以后,m的每个位置都是被标记了的,如果m定的很大又会存在浪费空间的问题。
布隆过滤器m大小应该考虑三个因素:
1、样本量
2、失误率
3、单样本大小
比如说上面那个黑名单:
样本量:100亿 失误率:1/10000 单样本大小(64个字节)
hash函数和单样本大小无关(因为任何一个样本只要我的hash函数能算一个hash值就行了),也根m的大小无关。
布隆过滤器m的大小求解方式:
给定横坐标m的大小,给定纵坐标表示失误率
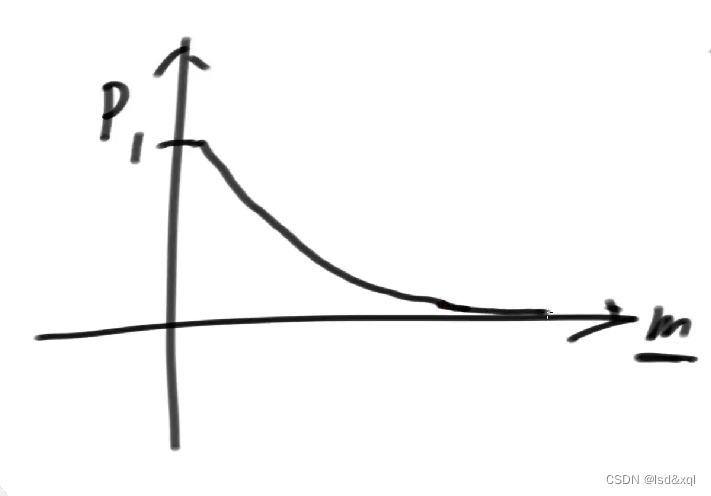
失误率会随着m增加无限变小,那么我需要求得一个多大的m能拿下我业务要求的一个失误率。
hansh函数个数求解:
如果hash函数过少,那么会出现采样不足的问题,导致失误率上升,如果hash函数过多,那么m会被迅速耗尽,失误率也会迅速上升。
当我的n【样本量】和m【布隆过滤器数组大小】都确定了:
我们确定横坐标表示hash函数个数以及纵坐标表示失误率:
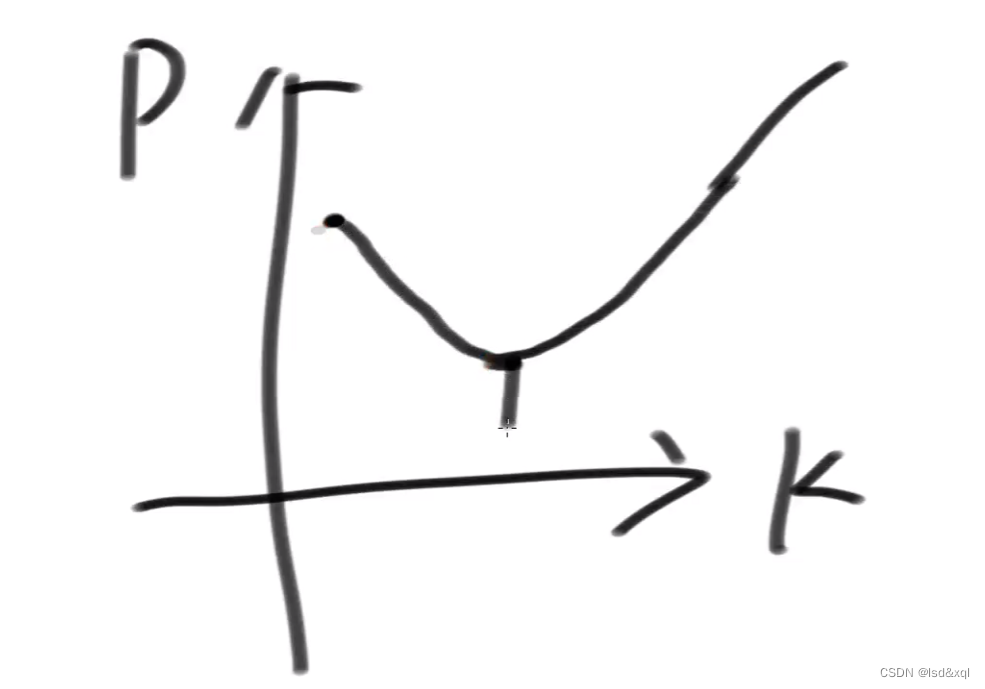
K过少失误率会上去,K过多失误率也会升高,我就取中间的最小。
真实失误率,则是我对前面第一个公式和第二个公式向上取整的结果算的失误率一定比给定的失误率小。
最终求解公式

当面试官问的时候需要:
你知道三个公式
1、知道m
2、知道K
3、算出p真
面试官会给出样本量,假设是100亿,给出样本量大小64个字节,这个是无关项不用的,先问面试官是否允许有失误率(如果允许则需要知道失误率的大小),从而求得m的大小,同时再问是否支持向上取整,从而得出一个m真实,再通过m真实算出一个向上取整的k真,然后求出一个p真,一定比面试官规定的失误率更低。
K个hash函数在哪找:
需要知道两个hash函数(f1,f2),那么只需要
1)1Xf(1)+f2
2)2Xf(1)+f2
3)3Xf(1)+f2
…
这样求下去,上面的函数几乎独立的。
一致性哈希
分布式存储结构最常见的结构:
1)哈希域变成环的设计
1)虚拟节点技术
经典数据存储
假设发起一个请求打在某个前端机器,然后前端再将请求的数据打在某个逻辑端的服务器【程序员是在逻辑端做数据存储,不会说某个服务器只存特定的数据】,然后再将请求给存储下来,将数据发送到数据服务器,如果我数据端服务器有三台,那么我的数据应存在哪台数据端服务器,常见是通过hash函数去取模知道存入哪台数据服务器,那么我所有不同的key都会负载均衡的到数据服务器中。则需要选择合适的hashKey做数据存储取模让数据均匀分布,高频的key有一定的量,中频有一定的量,低频有一定的量,这些需要从业务上面去确认
经典hash缺点及解决方案
如果需要对数据端服务器进行扩容,那么则需要对原数据进行迁移,这会非常难受的,原来取模过的信息现在会需要重新取模,数据迁移是全量的,一致性hash可以让它增加减少机器数据迁移不是全量的,而且还能做到负载均衡,现在将hash返回的结果想象成一个环。
比如说hash结果范围为0-2的64次方减一。
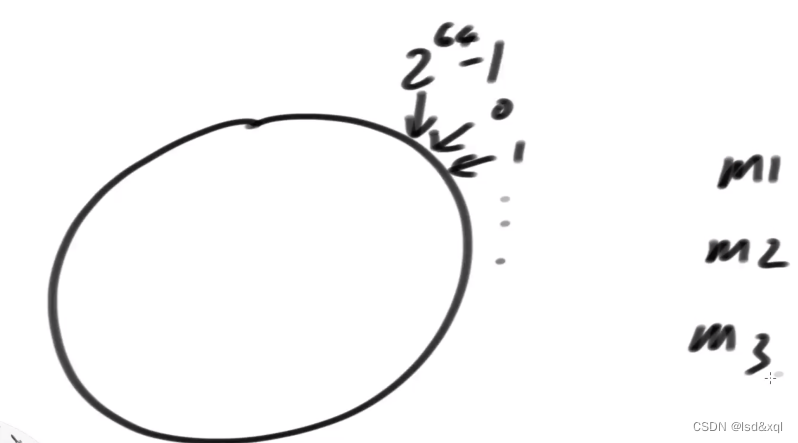
假设一开始有三台机器,每台机器都有它自己的信息【比如IP,HostName,Mac地址】,假设先拿IP来说,可以把IP认为是字符串,我可以用我唯一的hash函数让我的m1,m2,m3上环
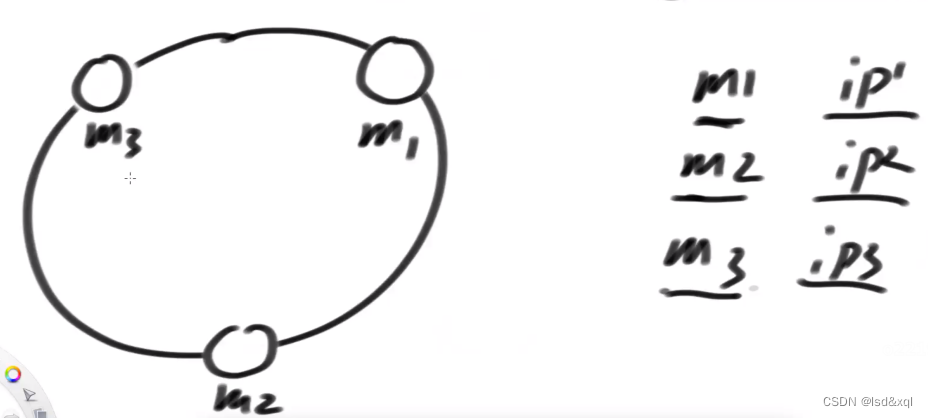
那么我前端请求,发送的数据存入后台的数据服务器上面,那么就将数据通过hash函数进行处理,将数据存入hash环,那么这个数据会存在它顺时针遇到的第一个机器里面。
如果新加一个机器m4,数据迁移的代价则不是全量了
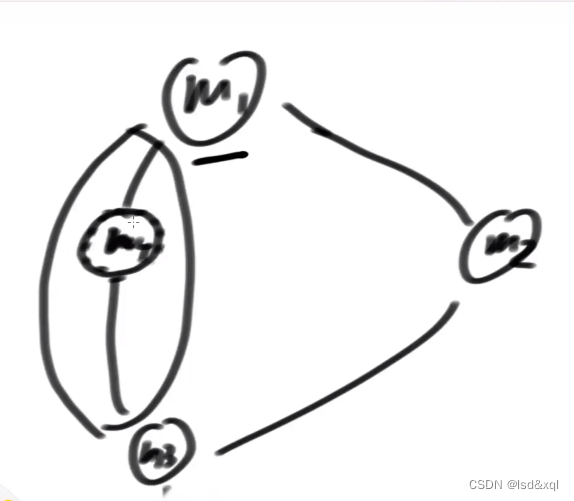
则只需要迁移原来在m1上面,顺时针调用找最近的是m4的那段数据就好了,数据迁移的代价就很少。
实际业务使用中:
则可以将我数据服务器的机器计算hash,然后做排序,在我的业务逻辑层采用二分法做处理,在最短时间复杂度找到我应该将数据放入哪个数据服务器。
虚拟节点
上面方案一致性hash的问题点:
假设有三台机器,如何一上来就把三台机器的哈希值在环上均分【因为少量hash的时候有可能我算出来的hash值上来就不均,导致数据存储分配不均】
解决方案:
采用虚拟节点技术:
还是三台机器:
给m1分配一千个字符串(a1-a1000)
给m2分配一千个字符串(b-b1000)
给m3分配一千个字符串(c1-c1000)
然后m1,m2,m3有哪些字符串可以查询到,然后哪些字符串属于哪台机器我也可以查到【互相查都方便】
我让m1,m2,m3中的虚拟节点去帮我抢环,环上只放虚拟节点抢来的数据。然后再通过上面一致性hash变成环的方式做数据存储,就能保证数据几乎均分。