Gradient Descent for Linear Regression
- 1、梯度下降
- 2、梯度下降算法的实现
- (1) 计算梯度
- (2) 梯度下降
- (3) 梯度下降的cost与迭代次数
- (4) 预测
- 3、绘图
- 4、学习率
首先导入所需的库:
import math, copy
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('./deeplearning.mplstyle')
from lab_utils_uni import plt_house_x, plt_contour_wgrad, plt_divergence, plt_gradients
1、梯度下降
使用线性模型来预测
f
w
,
b
(
x
(
i
)
)
f_{w,b}(x^{(i)})
fw,b(x(i)):
f
w
,
b
(
x
(
i
)
)
=
w
x
(
i
)
+
b
(1)
f_{w,b}(x^{(i)}) = wx^{(i)} + b \tag{1}
fw,b(x(i))=wx(i)+b(1)
在线性回归中, 利用训练数据来拟合参数
w
w
w,
b
b
b,通过最小化预测值
f
w
,
b
(
x
(
i
)
)
f_{w,b}(x^{(i)})
fw,b(x(i)) 与实际数据
y
(
i
)
y^{(i)}
y(i) 之间的误差来实现。 这种衡量为 cost, 即
J
(
w
,
b
)
J(w,b)
J(w,b)。 在训练中,可以衡量所有样例
x
(
i
)
,
y
(
i
)
x^{(i)},y^{(i)}
x(i),y(i)的cost:
J
(
w
,
b
)
=
1
2
m
∑
i
=
0
m
−
1
(
f
w
,
b
(
x
(
i
)
)
−
y
(
i
)
)
2
(2)
J(w,b) = \frac{1}{2m} \sum\limits_{i = 0}^{m-1} (f_{w,b}(x^{(i)}) - y^{(i)})^2\tag{2}
J(w,b)=2m1i=0∑m−1(fw,b(x(i))−y(i))2(2)
梯度下降描述为:
repeat until convergence: { w = w − α ∂ J ( w , b ) ∂ w b = b − α ∂ J ( w , b ) ∂ b } \begin{align*} \text{repeat}&\text{ until convergence:} \; \lbrace \newline \; w &= w - \alpha \frac{\partial J(w,b)}{\partial w} \tag{3} \; \newline b &= b - \alpha \frac{\partial J(w,b)}{\partial b} \newline \rbrace \end{align*} repeatwb} until convergence:{=w−α∂w∂J(w,b)=b−α∂b∂J(w,b)(3)
其中,参数 w w w, b b b 同时更新。
梯度定义为:
∂
J
(
w
,
b
)
∂
w
=
1
m
∑
i
=
0
m
−
1
(
f
w
,
b
(
x
(
i
)
)
−
y
(
i
)
)
x
(
i
)
∂
J
(
w
,
b
)
∂
b
=
1
m
∑
i
=
0
m
−
1
(
f
w
,
b
(
x
(
i
)
)
−
y
(
i
)
)
\begin{align} \frac{\partial J(w,b)}{\partial w} &= \frac{1}{m} \sum\limits_{i = 0}^{m-1} (f_{w,b}(x^{(i)}) - y^{(i)})x^{(i)} \tag{4}\\ \frac{\partial J(w,b)}{\partial b} &= \frac{1}{m} \sum\limits_{i = 0}^{m-1} (f_{w,b}(x^{(i)}) - y^{(i)}) \tag{5}\\ \end{align}
∂w∂J(w,b)∂b∂J(w,b)=m1i=0∑m−1(fw,b(x(i))−y(i))x(i)=m1i=0∑m−1(fw,b(x(i))−y(i))(4)(5)
这里的 同时 意味着在更新任何一个参数之前,同时计算所有参数的偏导数。
2、梯度下降算法的实现
包含一个特征的梯度下降算法需要三个函数来实现:
compute_gradient执行上面的等式(4)和(5)compute_cost执行上面的等式(2)gradient_descent:利用compute_gradient和compute_cost
其中,包含偏导数的 Python 变量的命名遵循以下模式:
∂
J
(
w
,
b
)
∂
b
\frac{\partial J(w,b)}{\partial b}
∂b∂J(w,b) 为 dj_db.
(1) 计算梯度
compute_gradient 实现上面的 (4) 和 (5) ,返回
∂
J
(
w
,
b
)
∂
w
\frac{\partial J(w,b)}{\partial w}
∂w∂J(w,b),
∂
J
(
w
,
b
)
∂
b
\frac{\partial J(w,b)}{\partial b}
∂b∂J(w,b).
def compute_gradient(x, y, w, b):
"""
Computes the gradient for linear regression
Args:
x (ndarray (m,)): Data, m examples
y (ndarray (m,)): target values
w,b (scalar) : model parameters
Returns
dj_dw (scalar): The gradient of the cost w.r.t. the parameters w
dj_db (scalar): The gradient of the cost w.r.t. the parameter b
"""
# Number of training examples
m = x.shape[0]
dj_dw = 0
dj_db = 0
for i in range(m):
f_wb = w * x[i] + b
dj_dw_i = (f_wb - y[i]) * x[i]
dj_db_i = f_wb - y[i]
dj_db += dj_db_i
dj_dw += dj_dw_i
dj_dw = dj_dw / m
dj_db = dj_db / m
return dj_dw, dj_db
使用 compute_gradient 函数来找到并绘制cost函数相对于参数
w
0
w_0
w0 的一些偏导数。
plt_gradients(x_train,y_train, compute_cost, compute_gradient)
plt.show()
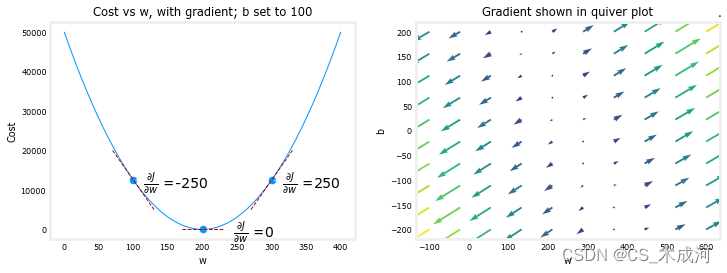
上面的左图显示了 ∂ J ( w , b ) ∂ w \frac{\partial J(w,b)}{\partial w} ∂w∂J(w,b),即在三个点处关于 w w w 的 cost 曲线的斜率。在图的右侧,导数为正,而在左侧为负。由于“碗形”的形状,导数将始终引导梯度下降朝着梯度为零的最低点前进。
左图中的 b b b 被固定为 100。梯度下降将同时利用 ∂ J ( w , b ) ∂ w \frac{\partial J(w,b)}{\partial w} ∂w∂J(w,b) 和 ∂ J ( w , b ) ∂ b \frac{\partial J(w,b)}{\partial b} ∂b∂J(w,b) 来更新参数。右侧的“矢量图”提供了查看两个参数梯度的方式。箭头的大小反映了该点梯度的大小。箭头的方向和斜率反映了该点处 ∂ J ( w , b ) ∂ w \frac{\partial J(w,b)}{\partial w} ∂w∂J(w,b) 和 ∂ J ( w , b ) ∂ b \frac{\partial J(w,b)}{\partial b} ∂b∂J(w,b) 的比例。梯度指向远离最小值的方向。将缩放后的梯度从当前的 w w w 或 b b b 值中减去,这将使参数朝着降低cost的方向移动。
(2) 梯度下降
现在可以计算梯度了,梯度下降方法(如上面公式(3)所描述)可以在下面的 gradient_descent 函数中实现。使用这个函数在训练数据上找到参数
w
w
w 和
b
b
b 的最优值。
def gradient_descent(x, y, w_in, b_in, alpha, num_iters, cost_function, gradient_function):
"""
Performs gradient descent to fit w,b. Updates w,b by taking
num_iters gradient steps with learning rate alpha
Args:
x (ndarray (m,)) : Data, m examples
y (ndarray (m,)) : target values
w_in,b_in (scalar): initial values of model parameters
alpha (float): Learning rate
num_iters (int): number of iterations to run gradient descent
cost_function: function to call to produce cost
gradient_function: function to call to produce gradient
Returns:
w (scalar): Updated value of parameter after running gradient descent
b (scalar): Updated value of parameter after running gradient descent
J_history (List): History of cost values
p_history (list): History of parameters [w,b]
"""
w = copy.deepcopy(w_in) # avoid modifying global w_in
# An array to store cost J and w's at each iteration primarily for graphing later
J_history = []
p_history = []
b = b_in
w = w_in
for i in range(num_iters):
# Calculate the gradient and update the parameters using gradient_function
dj_dw, dj_db = gradient_function(x, y, w , b)
# Update Parameters using equation (3) above
b = b - alpha * dj_db
w = w - alpha * dj_dw
# Save cost J at each iteration
if i<100000: # prevent resource exhaustion
J_history.append( cost_function(x, y, w , b))
p_history.append([w,b])
# Print cost every at intervals 10 times or as many iterations if < 10
if i% math.ceil(num_iters/10) == 0:
print(f"Iteration {i:4}: Cost {J_history[-1]:0.2e} ",
f"dj_dw: {dj_dw: 0.3e}, dj_db: {dj_db: 0.3e} ",
f"w: {w: 0.3e}, b:{b: 0.5e}")
return w, b, J_history, p_history #return w and J,w history for graphing
# initialize parameters
w_init = 0
b_init = 0
# some gradient descent settings
iterations = 10000
tmp_alpha = 1.0e-2
# run gradient descent
w_final, b_final, J_hist, p_hist = gradient_descent(x_train ,y_train, w_init, b_init, tmp_alpha, iterations, compute_cost, compute_gradient)
print(f"(w,b) found by gradient descent: ({w_final:8.4f},{b_final:8.4f})")
Iteration 0: Cost 7.93e+04 dj_dw: -6.500e+02, dj_db: -4.000e+02 w: 6.500e+00, b: 4.00000e+00
Iteration 1000: Cost 3.41e+00 dj_dw: -3.712e-01, dj_db: 6.007e-01 w: 1.949e+02, b: 1.08228e+02
Iteration 2000: Cost 7.93e-01 dj_dw: -1.789e-01, dj_db: 2.895e-01 w: 1.975e+02, b: 1.03966e+02
Iteration 3000: Cost 1.84e-01 dj_dw: -8.625e-02, dj_db: 1.396e-01 w: 1.988e+02, b: 1.01912e+02
Iteration 4000: Cost 4.28e-02 dj_dw: -4.158e-02, dj_db: 6.727e-02 w: 1.994e+02, b: 1.00922e+02
Iteration 5000: Cost 9.95e-03 dj_dw: -2.004e-02, dj_db: 3.243e-02 w: 1.997e+02, b: 1.00444e+02
Iteration 6000: Cost 2.31e-03 dj_dw: -9.660e-03, dj_db: 1.563e-02 w: 1.999e+02, b: 1.00214e+02
Iteration 7000: Cost 5.37e-04 dj_dw: -4.657e-03, dj_db: 7.535e-03 w: 1.999e+02, b: 1.00103e+02
Iteration 8000: Cost 1.25e-04 dj_dw: -2.245e-03, dj_db: 3.632e-03 w: 2.000e+02, b: 1.00050e+02
Iteration 9000: Cost 2.90e-05 dj_dw: -1.082e-03, dj_db: 1.751e-03 w: 2.000e+02, b: 1.00024e+02
(w,b) found by gradient descent: (199.9929,100.0116)
从上面打印的梯度下降过程可以看出,偏导数 dj_dw和dj_db逐渐变小,开始变得很快,然后变慢。当过程接近“碗底”时,由于该点的导数值较小,进度会变慢。
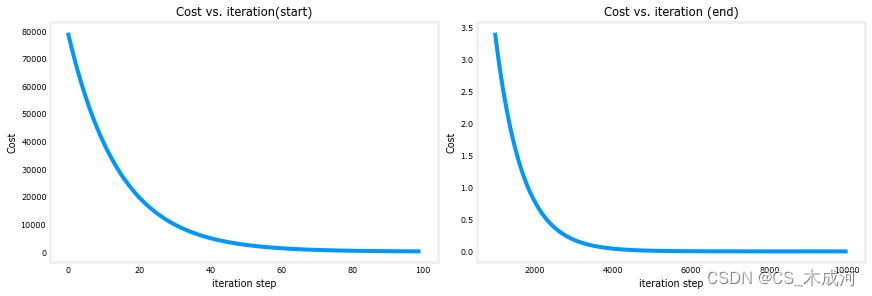
(3) 梯度下降的cost与迭代次数
cost 与迭代次数的图是梯度下降中进展的一个有用指标。在成功的运行中,cost 应该始终降低。cost的变化在最初阶段非常迅速,因此将初始阶段的下降与最后阶段的下降绘制在不同的比例尺上是很有用的。在下面的图中,请注意坐标轴上cost的刻度和迭代步骤。
# plot cost versus iteration
fig, (ax1, ax2) = plt.subplots(1, 2, constrained_layout=True, figsize=(12,4))
ax1.plot(J_hist[:100])
ax2.plot(1000 + np.arange(len(J_hist[1000:])), J_hist[1000:])
ax1.set_title("Cost vs. iteration(start)"); ax2.set_title("Cost vs. iteration (end)")
ax1.set_ylabel('Cost') ; ax2.set_ylabel('Cost')
ax1.set_xlabel('iteration step') ; ax2.set_xlabel('iteration step')
plt.show()
(4) 预测
现在已经找到了参数 w w w 和 b b b 的最优值,可以使用这个模型根据学到的参数来预测房屋价格。如预期的那样,对于相同的房屋,预测值与训练值几乎相同。此外,对于没有在预测中的值,它与预期值是一致的。
print(f"1000 sqft house prediction {w_final*1.0 + b_final:0.1f} Thousand dollars")
print(f"1200 sqft house prediction {w_final*1.2 + b_final:0.1f} Thousand dollars")
print(f"2000 sqft house prediction {w_final*2.0 + b_final:0.1f} Thousand dollars")
1000 sqft house prediction 300.0 Thousand dollars
1200 sqft house prediction 340.0 Thousand dollars
2000 sqft house prediction 500.0 Thousand dollars
3、绘图
通过在cost函数的等高线图上绘制cost随迭代次数的变化来展示梯度下降执行过程。
fig, ax = plt.subplots(1,1, figsize=(12, 6))
plt_contour_wgrad(x_train, y_train, p_hist, ax)
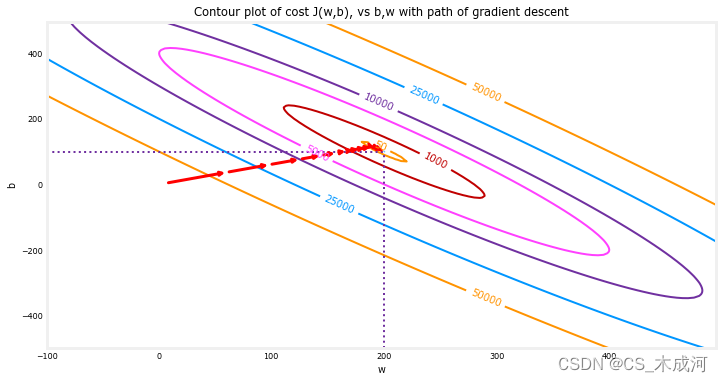
在上面的等高线图中,展示了
c
o
s
t
(
w
,
b
)
cost(w,b)
cost(w,b) 在一系列
w
w
w 和
b
b
b 值上的变化。cost 水平由环状图表示。用红色箭头叠加在图中,表示梯度下降的路径。这条路径向着目标稳步(单调地)前进,最初的步长比接近目标时的步长要大得多。
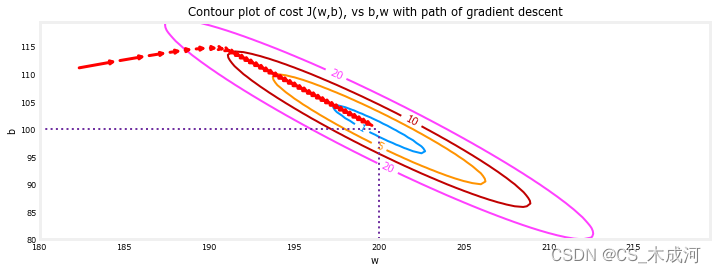
将梯度下降的最后步进行放大,随着梯度接近零,步之间的距离会缩小。
fig, ax = plt.subplots(1,1, figsize=(12, 4))
plt_contour_wgrad(x_train, y_train, p_hist, ax, w_range=[180, 220, 0.5], b_range=[80, 120, 0.5], contours=[1,5,10,20],resolution=0.5)
4、学习率
α \alpha α 越大,梯度下降就会更快地收敛到一个解。但是,如果 α \alpha α 太大,梯度下降可能会发散。上面的例子展示了一个很好地收敛的解。如果增加 α \alpha α 的值,看看会发生什么?
# initialize parameters
w_init = 0
b_init = 0
# set alpha to a large value
iterations = 10
tmp_alpha = 8.0e-1
# run gradient descent
w_final, b_final, J_hist, p_hist = gradient_descent(x_train ,y_train, w_init, b_init, tmp_alpha, iterations, compute_cost, compute_gradient)
Iteration 0: Cost 2.58e+05 dj_dw: -6.500e+02, dj_db: -4.000e+02 w: 5.200e+02, b: 3.20000e+02
Iteration 1: Cost 7.82e+05 dj_dw: 1.130e+03, dj_db: 7.000e+02 w: -3.840e+02, b:-2.40000e+02
Iteration 2: Cost 2.37e+06 dj_dw: -1.970e+03, dj_db: -1.216e+03 w: 1.192e+03, b: 7.32800e+02
Iteration 3: Cost 7.19e+06 dj_dw: 3.429e+03, dj_db: 2.121e+03 w: -1.551e+03, b:-9.63840e+02
Iteration 4: Cost 2.18e+07 dj_dw: -5.974e+03, dj_db: -3.691e+03 w: 3.228e+03, b: 1.98886e+03
Iteration 5: Cost 6.62e+07 dj_dw: 1.040e+04, dj_db: 6.431e+03 w: -5.095e+03, b:-3.15579e+03
Iteration 6: Cost 2.01e+08 dj_dw: -1.812e+04, dj_db: -1.120e+04 w: 9.402e+03, b: 5.80237e+03
Iteration 7: Cost 6.09e+08 dj_dw: 3.156e+04, dj_db: 1.950e+04 w: -1.584e+04, b:-9.80139e+03
Iteration 8: Cost 1.85e+09 dj_dw: -5.496e+04, dj_db: -3.397e+04 w: 2.813e+04, b: 1.73730e+04
Iteration 9: Cost 5.60e+09 dj_dw: 9.572e+04, dj_db: 5.916e+04 w: -4.845e+04, b:-2.99567e+04
在上面的情况下, w w w 和 b b b 在正值和负值之间来回跳动,其绝对值在每次迭代中增加。此外,每次迭代 ∂ J ( w , b ) ∂ w \frac{\partial J(w,b)}{\partial w} ∂w∂J(w,b) 都会改变符号,并且cost不是减小而是增加。这明显表明学习率过大,导致解发散。通过图形来可视化这个情况。
plt_divergence(p_hist, J_hist,x_train, y_train)
plt.show()
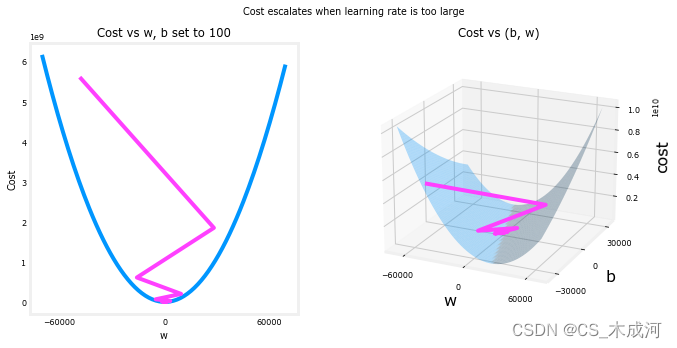
上面的左图显示了梯度下降的前几步中
w
w
w 的变化情况。
w
w
w 在正值和负值之间振荡,并且cost迅速增长。梯度下降同时对
w
w
w 和
b
b
b 进行操作,因此需要右边的三维图来得到完整的图像。