问题
有没有好奇过,自己写的前端代码是怎么变成上线可用的代码的?
前言
目前实现从源码到可用的静态文件,我们都是借助打包工具实现的,目前用的比较多的是webpack、rollup、vite..., 那么以上问题也可以描述为“构建工具是如何进行构建的?”, 本文主要以rollup(v0.34.9)为例,对以上问题进行阐述,需要说明的是
v0.34.9版本的rollup功能基本完善,后续的版本是在现有基础上的迭代,原理是一样的- 文章关注的是实现构建功能的核心流程,不涉及插件、钩子等概念,因此没用过
rollup也是不要紧的 - 看了https://mp.weixin.qq.com/s/JndBu8maXC-f9r1Ghw8kgg 此篇文章之后,我发现
webpack和rollup的打包过程基本是一样的,所以如果理解了本文描述的构建过程,对于你了解webpack应该是有帮助的 - 以下贴的代码均是
v0.34.9版本相关代码的简写,方便理解 - 如果想看最后的结果整理,建议直接看回答问题
demo
源码
一共包括两个文件main.js和/lib/a.js, mainjs是入口文件,引用a.js
// main.js 入口文件
import { getAge } from "./lib/a";
console.log(getAge())
// ./lib/a.js
const obj = {
name: 'w',
age:123
}
export const getName =() => {
return obj.name
}
export const getAge = () => {
return obj.age
}
打包脚本
打包脚本就是调用rollup对源码进行打包,只制定入口文件和输入的目录,其他均不配置
// build.js
import rollup from "rollup";
async function build() {
// 创建一个 bundle
const bundle = await rollup.rollup({
entry: 'src/main.js'
});
// 或者将bundle写入磁盘
await bundle.write({
dest: 'dist/bundle.js'
});
}
build();
构建结果
打包结果如下:
const obj = {
name: 'w',
age:123
}
const getAge = () => {
return obj.age
}
console.log(getAge())
构建过程
以下会按照rollup代码执行的顺序展示构建过程中的一些关键片段, 辅助以当时执行的代码运行截图进行梳理,为了方便记忆,还会给出一个当时源码在rollup里的展示形式。
1. 初始化
...
function rollup(options) {
...
// 不用管Bundle具体是干嘛的,知道有这个东西就行了
const bundle = new Bundle( options );
}
...
...
class Bundle {
constructor(options) {
...
this.entry = options.entry;
...
}
}
...
从build.js中可以看出,对rollup来说,可以获取的信息就是{entry: 'src/main.js'},rollup会把这个值保存下来,以供后续使用。此时源码在rollup中的呈现就是一个entry属性,值为src/main.js
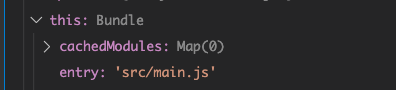
便于记忆,源码目前就是一个字符串

2. 开始构建
...
this.resolveId( this.entry, undefined ).then(id => {
this.entryId = id;
})
...
此处执行了一个resolveId(),关于resolveId的实现我们可以先不考虑,直接把函数执行的结果给大家展示出来
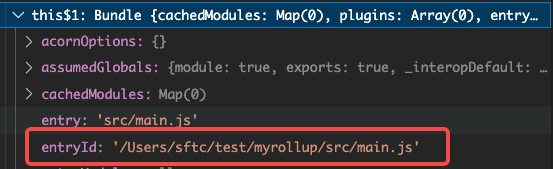
由此可以得知resolveId就是把输入字符串转化为了入口文件的绝对路径,此刻源码的呈现方式也有了变化,从一个输入字符串变为了一个绝对路径。
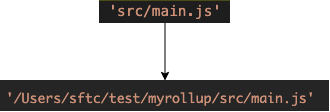
3. 获取文件 fetchModule
这里的代码有点多,我们分三步完成
// 执行 fetchModule
this.fetchModule( id, undefined ); // id就是上一步得到的entryId
// fetchModule定义
fetchModule(id, importer) {
...
// step1
this.load( id ).then(source => {
...
//step2
const module = new Module({
id,
code,
originalCode,
originalSourceMap,
ast,
sourceMapChain,
resolvedIds,
bundle: this
});
this.modules.push( module );
this.moduleById.set( id, module );
// step3
return this.fetchAllDependencies( module ).then( () => {
...
return module;
});
})
...
}
// load 定义
export function load ( id ) {
return readFileSync( id, 'utf-8' );
}
3.1 step1: load
可以看出load方法就是在读文件,所以经过这个步骤后,源码的呈现方式又发生了变化,从绝对路径变为了一个文件(以字符串的形式存在于rollup中)
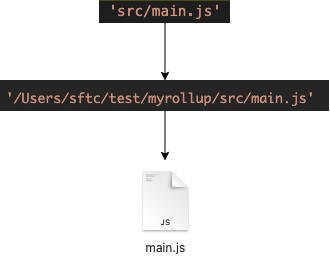
3.2 step2: new Module
从代码上看是实例化了一个Module类,并把读取的文件(source变量)保存到了module实例上,这里也可以得出一个重要结论“rollup中一个文件就是一个模块(module)”。 这里源码再一次发生变化,成为了一个module实例,并保存到了modules变量中,整个step2的过程就执行完成了,但需要再介绍一点细节,在new Module()的过程中,rollup还做了一下操作
import { parse } from 'acorn/src/index.js';
...
class Module {
constructor({code}) {
...
this.code = code ;
this.statements = this.parse();
this.analyse();
...
}
}
...
rollup对这个模块的代码进行了ast生成及基本的分析,记录了一些该模块的信息(这里就不一一展示了,后面用到的话再说明)

那么此刻源码就是一个记录了一堆自己属性(源码字符串、ast各类属性…)的module实例

3.2 step3: fetchAllDependencies
fetchAllDependencies(module) {
// mapSequence 函数作用可先理解为类似 module.sources.forEach(socure => {})
return mapSequence( module.sources, source => {
const resolvedId = module.resolvedIds[ source ];
return ( resolvedId ? Promise.resolve( resolvedId ) : this.resolveId( source, module.id ) )
.then( resolvedId => {
...
return this.fetchModule( resolvedId, module.id );
})
}
想看懂这个方法在干嘛主要是要知道module.sources是啥东西

sources记录了该模块依赖的文件(比如在mainjs里引入了ajs,这里就会记录ajs),所以这里的代码就可以解释为拿到ajs的入口字符串,执行resolveId函数后获取ajs的resolveId(也就是ajs的绝对路径),然后在执行fetchModule()… 这个过程是不是有点熟悉?
我们发现这里其实就是在重复前面的流程,不过之前是mainjs,这次是ajs,所以我们知道fetchAllDependencies就是在把mainjs所依赖的文件都进行上述的步骤,而且这一过程会不断地递归,最终把项目中用到的所有文件都实例化为一个个module实例存到modules里,这一过程我们就不在展示了,直说最终结果,我们拿到了一个modules数组,类似于[module1, module2,…,moduleN],记录了所有的源码文件。

4. 建立连接binding
源码中此步骤有注释说明,可以看如下代码,建立连接也有三步
// Phase 2 – binding. We link references to their declarations
// to generate a complete picture of the bundle
this.modules.forEach( module => module.bindImportSpecifiers() ); // step1
this.modules.forEach( module => module.bindAliases() ); // step2
this.modules.forEach( module => module.bindReferences() ); // step3
4.1 bindImportSpecifiers 模块之间建立联系
class Module {
...
bindImportSpecifiers () {
...
this.sources.forEach( source => {
const id = this.resolvedIds[ source ];
const module = this.bundle.moduleById.get( id );
if ( !module.isExternal ) this.dependencies.push( module );
});
}
...
}
前面提到过this.sources是存的依赖的文件路径,所以可以看出这里是把依赖文件对应的模块存到dependencies里。
举个例子,在ajs有这段代码,`import {x} from './b.js;`,我们可以用moduleA.dependencies = [ moduleB] 来记录ajs和bjs的依赖关系,经过此步骤之后我们就将各个模块连接起来了!
可能有的同学看到这里会有些疑惑,我们不是在第三步fetchModule的时候就已经知道了两个模块间的依赖关系,为啥还要在这里再做一遍呢?包括我自己在内,过一段时间回忆这块逻辑的时候也会有这个问题,这里就专门强调下:因为fetchModule的时候我们知道的是模块a依赖文件b,此刻b还只是个文件,不是module。
4.2 前置说明
-
后面的两步同样也是在建立连接,需要一些ast知识,但自己这方面的认知还有点欠缺,如果存在问题,还请大家指正
-
以下两步的主要作用是啥呢?我能够看到的是为了后续做代码优化(消除没有用到的代码,减少打包体积),所以如果没有这两部分功能能够成功打包吗?目前我的回答是可以的,也许随着我对打包过程理解的深入这个答案会有所不同,但按照我目前的思路,也就是说后面两步目前可以不看,直接到下一步
这里我先给出源码进行完整个第四步后的呈现形式,便于大家直接跳到第五步观看
4.3 AST相关的知识
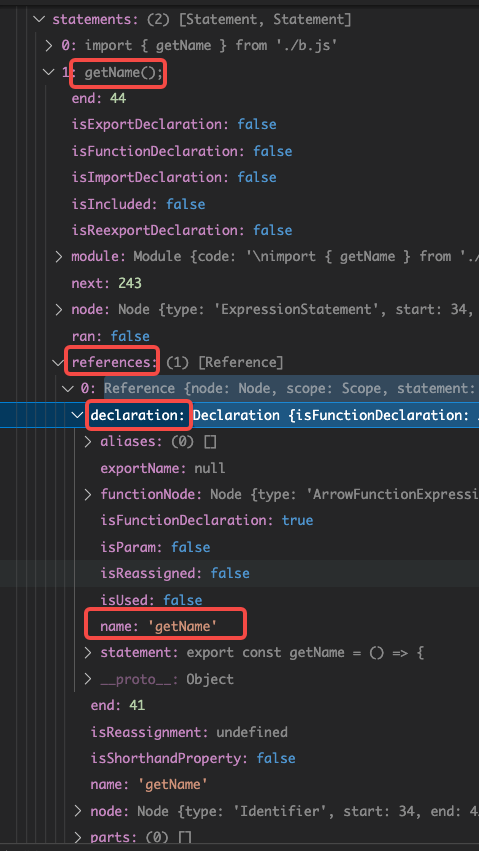
这里提一些前置需要的ast基本概念,以下主要是对declaration和statement两种ast节点的处理,可以参考下常见的AST节点 - 掘金,declaration就是变量声明,statment就是执行语句,此外后面还涉及Identifier,也就是标识符,这里需要有个印象。
以下两步都用到了statement.references属性,所以有必要说明下references。references并不是ast生成后自动包含的,而是在获取ast后,rollup自己加进去的。
// 实现类似于
let module = new Module()
class Module {
constructor(code) {
this.code = code
this.parse();
this.analyse(); // references就是在这里加进去的
}
analyse() {
this.statements.forEach( statement => {
...
this.firstPass()
})
}
}
// references添加大概是这样
class Statement {
...
firstPass() {
...
let { references} = this;
walk(this.node {
...
if ( isReference( node, parent ) ) {
...
const reference = new Reference( node, referenceScope, statement );
references.push( reference );
...
}
})
}
}
// isReference实现(未删改) 感兴趣的可以看看判断依据,这里只要知道这个判断就行了
export default function isReference ( node, parent ) {
if ( node.type === 'MemberExpression' ) {
return !node.computed && isReference( node.object, node );
}
if ( node.type === 'Identifier' ) {
// the only time we could have an identifier node without a parent is
// if it's the entire body of a function without a block statement –
// i.e. an arrow function expression like `a => a`
if ( !parent ) return true;
// TODO is this right?
if ( parent.type === 'MemberExpression' || parent.type === 'MethodDefinition' ) {
return parent.computed || node === parent.object;
}
// disregard the `bar` in `{ bar: foo }`, but keep it in `{ [bar]: foo }`
if ( parent.type === 'Property' ) return parent.computed || node === parent.value;
// disregard the `bar` in `class Foo { bar () {...} }`
if ( parent.type === 'MethodDefinition' ) return false;
// disregard the `bar` in `export { foo as bar }`
if ( parent.type === 'ExportSpecifier' && node !== parent.local ) return;
return true;
}
}
reference顾名思义是引用,也就是要记录statement引用了哪些值,主要就是看isReference的实现。举例:
`let a = b + c`这个statement里使用了了3个标识符a b c,用代码来表示这个引用关系就是`statement.references = [referenceA, referenceB, referenceC]``getName()`里出现了一个标识符,那么引用关系就是`statement.references = [referenceGetName]`,`{ name: val}`这种形式的出现了两个标识符,也需要有两个引用吗,name此处只是一个属性名,明显不是从其他地方引用的,所以这里的引用关系就是`statement.references = [referenceVal]`,这也就是isReference在做的事情,有了这一步,所有有引用的statement就都被统计到了。
4.3 bindAliases: declaration之间建立联系
class Module {
...
bindAliases () {
// this.declarations 记录了该模块定义的所有变量
keys( this.declarations ).forEach( name => {
const declaration = this.declarations[ name ];
const statement = declaration.statement;
...
statement.references.forEach( reference => {
if ( reference.name === name ) return;
const otherDeclaration = this.trace( reference.name );
if ( otherDeclaration ) otherDeclaration.addAlias( declaration );
});
});
}
// 追踪name是在哪里定义的,不用细看
trace ( name ) {
if ( name in this.declarations ) return this.declarations[ name ];
if ( name in this.imports ) {
const importDeclaration = this.imports[ name ];
const otherModule = importDeclaration.module;
if ( importDeclaration.name === '*' && !otherModule.isExternal ) {
return otherModule.namespace();
}
const declaration = otherModule.traceExport( importDeclaration.name );
if ( !declaration ) throw new Error( `Module ${otherModule.id} does not export ${importDeclaration.name} (imported by ${this.id})` );
return declaration;
}
return null;
}
...
}
class Declaration {
...
addAlias ( declaration ) {
this.aliases.push( declaration );
}
...
}
举个例子:
// a.js
import {b } from './b/js'
let c = 2
let a = b + c
// b.js
export const b = 2;
针对let a = b + c 这条既是declaration ,也是statement,statement中收集了出现的3个标识符a b c

接下来要把a b c 这三个变量分别定义的declaration找出来,建立let a = b + c这个statement和a b c各自的declaration之间的连接。 a就是在本条语句,所以没必要记录,直接返回,然后通过this.trace方法分别找到b c的declaration,并通过addAlias方法记录这种关系,比如b的declaration会记录如下:declarationB.alias = [declarationA]

这里提一下this.trace方法负责寻找变量声明的declaration,可以从本模块找,也可从依赖的模块找(这个能力就是上一步建立模块之间的连接支撑的)。这一步过后就把declartion之间连接起来了!
4.4 bindReferences: statement与使用到的declaration之间建立联系
class Module {
...
bindReferences () {
...
this.statements.forEach( statement => {
...
statement.references.forEach( reference => {
const declaration = reference.scope.findDeclaration( reference.name ) ||
this.trace( reference.name );
if ( declaration ) {
declaration.addReference( reference );
} else {
// TODO handle globals
this.bundle.assumedGlobals[ reference.name ] = true;
}
});
});
}
...
}
class Declaration {
...
addReference ( reference ) {
reference.declaration = this;
if ( reference.name !== this.name ) {
this.name = makeLegalIdentifier( reference.name ); // TODO handle differences of opinion
}
if ( reference.isReassignment ) this.isReassigned = true;
}
}
举个例子:
// b.js
export const getName = () => {
return 'name'
}
// a.js
import { getName } from './b.js'
getName();
getName()这个statement我们初始化references属性的时候就知道这里存在一个reference statement.references = [referenceGetName],但是referenceGetName只是被初始化了,我们只知道这个statement引用了getName,但却不知道getName的详细信息,这里就是在找getName的declaration并且记录下来,用代码表示就是referenceGetName.declaration = declarationGetName,这样statement就引用的declaration就建立连接了。
5. 优化:标记代码
// Phase 3 – marking. We 'run' each statement to see which ones
// need to be included in the generated bundle
// mark all export statements
entryModule.getExports().forEach( name => {
const declaration = entryModule.traceExport( name );
declaration.exportName = name;
declaration.use();
});
// mark statements that should appear in the bundle
let settled = false;
while ( !settled ) {
settled = true;
this.modules.forEach( module => {
if ( module.run( this.treeshake ) ) settled = false;
});
}
以上是此部分的源码和注释(未删改),可以看出此部分主要就是在优化代码,把不需要的去掉,减少打包体积。也是分为两步
5.1 mark all export statements
这里很简单,就是把入口文件涉及到的导出语句中用到的declaration都执行一下 declaration.use(),这么做的原因很简单,导出的变量肯定是需要的,不能被删除的
class Declaration {
use () {
if ( this.isUsed ) return;
this.isUsed = true;
if ( this.statement ) this.statement.mark();
this.aliases.forEach( use );
}
}
use函数中除了把declaration.isUsed设为true,还做了两个事,
-
this.aliases.forEach( use );,这里用到了在4.3中建立的eclaration之间的关联,把用到这个declaration的相关declaration都设为used,表示都需要保留,不能删除 -
if ( this.statement ) this.statement.mark();,如果这个declaration也是个statement,那么执行下statement.mark()
class Statement {
...
mark () {
if ( this.isIncluded ) return; // prevent infinite loops
this.isIncluded = true;
this.references.forEach( reference => {
if ( reference.declaration ) reference.declaration.use();
});
}
}
可以看出,会把这个statemen会把自己标记为isIncluded, 把用到的declaration都设置为used(用到了4.4里建立的statement和declaration之间的连接)
5.2 mark statements that should appear in the bundle
class Module {
/**
* Statically runs the module marking the top-level statements that must be
* included for the module to execute successfully.
*
* @param {boolean} treeshake - if we should tree-shake the module
* @return {boolean} marked - if any new statements were marked for inclusion
*/
run ( treeshake ) {
if ( !treeshake ) {
// 如果不做treeshake,那么所有的statement都执行mark,即都标记为isIncluded
this.statements.forEach( statement => {
if ( statement.isImportDeclaration || ( statement.isExportDeclaration && statement.node.isSynthetic ) ) return;
statement.mark();
});
return false;
}
let marked = false;
this.statements.forEach( statement => {
marked = statement.run( this.strongDependencies ) || marked;
});
return marked;
}
}
class Statement {
run ( strongDependencies ) {
if ( ( this.ran && this.isIncluded ) || this.isImportDeclaration || this.isFunctionDeclaration ) return;
this.ran = true;
if ( run( this.node, this.scope, this, strongDependencies, false ) ) {
this.mark();
return true;
}
}
}
这里要把需要保留的代码记录下来,方法就是每个statement都执行run方法,这里又调用了一个run方法,如果为true的话才会执行mark方法标记这个statement.isIncluded为true,那么看下run方法
function run (node ) {
let hasSideEffect = false;
walk(node, {
enter: (node ,parent) {...},
leave: (node ,parent) {...},
})
return hasSideEffect
}
可以看出可以就是在判断此statement执行会不会产生副作用,如果可能产生副作用的话就返回true,执行statement.mark(),判断的情况有挺多种,感兴趣的话可以看下这块源码。
此步过后源码的呈现形式大概是:
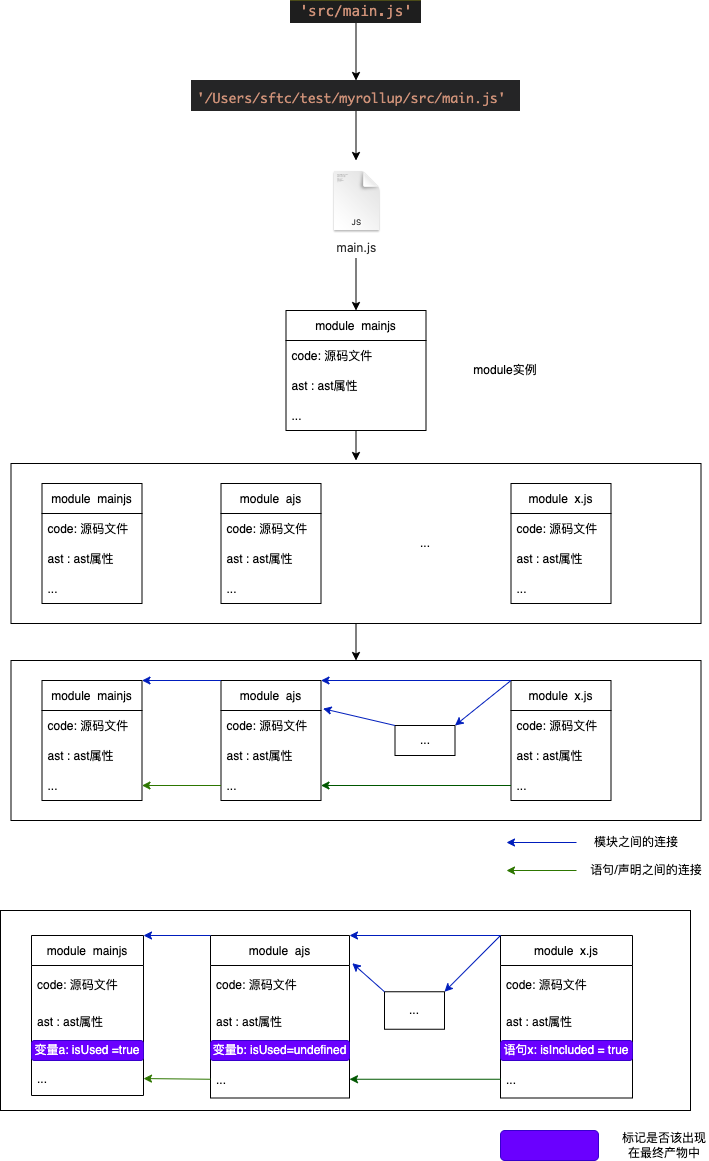
6. 最后准备:排序&去除重名
// Phase 4 – final preparation. We order the modules with an
// enhanced topological sort that accounts for cycles, then
// ensure that names are deconflicted throughout the bundle
this.orderedModules = this.sort();
this.deconflict();
首先是排序,举个例子,比如ajs依赖bjs,那么代码生成的时候bjs肯定要写在前面,否则就出错了,按照模块依赖的关系排序就行,这里要特殊处理一下循环依赖的关系
去除重名也很好理解,ajs和bjs都定义了变量name的话肯定会出现错误,那么就需要改变其中一个变量名,保证全局作用于中无相同的重名变量

7. 生成dist
这一步打包脚本build.js中的bundle.write({ dest: 'dist/bundle.js'});在调用fs.readFile()之前还需要把所有的module合成一个文件,消除一些不必要的代码(在第五步中设置的标记就起到了作用)
class Module {
...
render() {
...
if ( !statement.isIncluded ) {
if ( statement.node.type === 'ImportDeclaration' ) {
magicString.remove( statement.node.start, statement.next );
return;
}
magicString.remove( statement.start, statement.next );
return;
}
...
if ( !defaultDeclaration.exportName && !defaultDeclaration.isUsed ) {
magicString.remove( statement.start, statement.node.declaration.start );
return;
}
...
}
}
最终源码就变成了dist产物
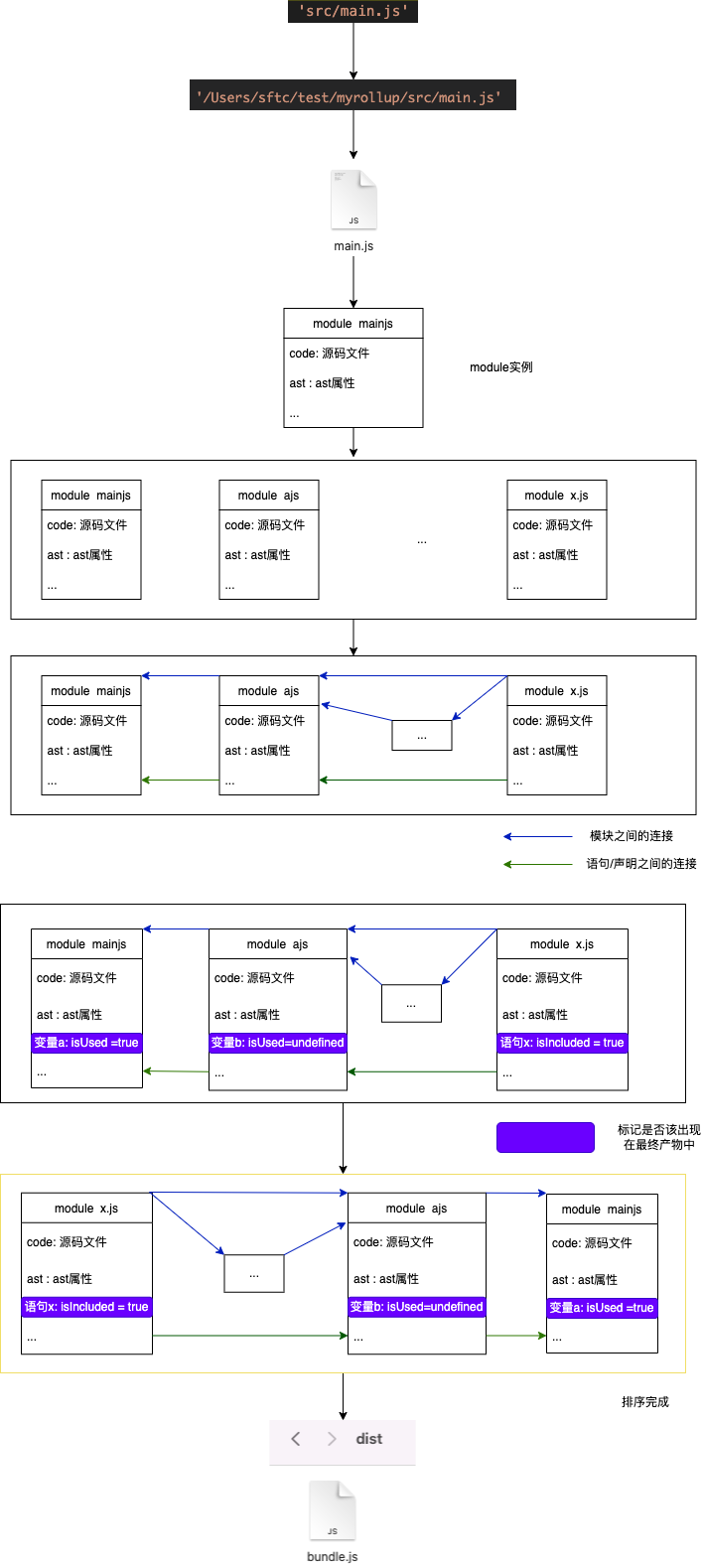
回答问题
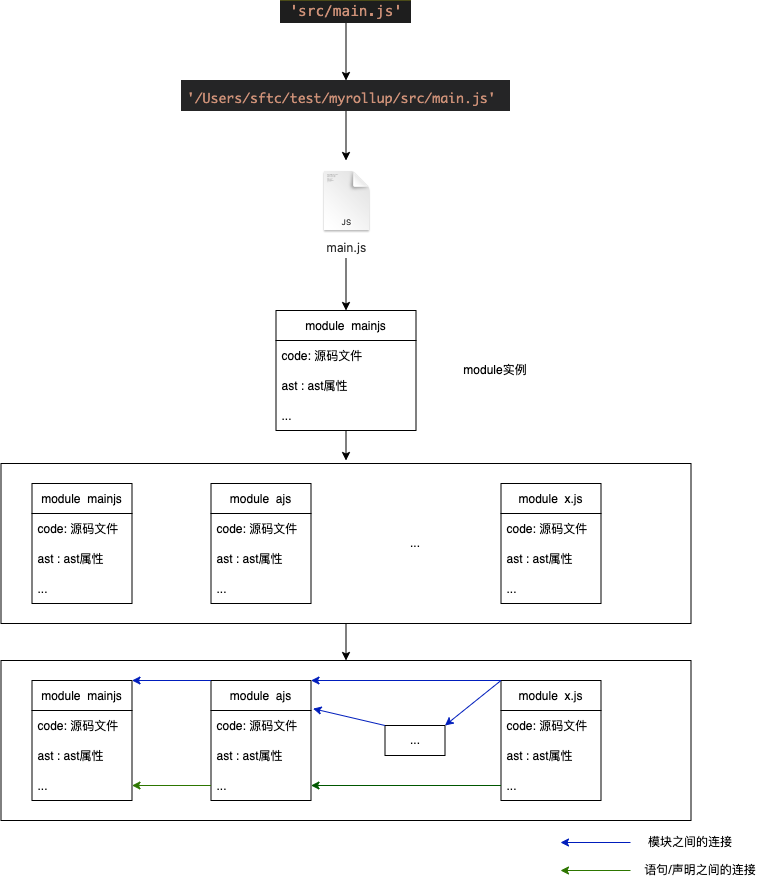
构建工具是怎么把源码变为dist文件的?
- 获取输入字符串
src/main.js - 转化为
mainjs的绝对路径 - 获取
mainjs源文件 - 把
mainjs文件变为一个module实例,不仅仅包含源码,还包含一些ast相关的信息 - 获取
mainjs依赖的文件并递归以上过程,得到一个保存全部源文件module实例的数组 - 将
module之间、declaration之间、statement与declaration之间的依赖关系记录下来 - “run”一下代码,标记出所有用到的代码
- 将所有
module实例进行排序,解决可能冲突的命名 - 将所有
module实例打包进一个文件(过程中只打包被标记的代码,无用代码就去掉了) - 完成
(整个过程就是上图)
一些细节点
- 对于
if(false) {console.log(1)}里面不会进打包产物的判断在parse的过程中就完成了
class Module {
...
parse() {
...
walk( this.ast, {
enter: node => {
// eliminate dead branches early
if ( node.type === 'IfStatement' ) {
if ( isFalsy( node.test ) ) {
this.magicString.overwrite( node.consequent.start, node.consequent.end, '{}' );
node.consequent = emptyBlockStatement( node.consequent.start, node.consequent.end );
} else if ( node.alternate && isTruthy( node.test ) ) {
this.magicString.overwrite( node.alternate.start, node.alternate.end, '{}' );
node.alternate = emptyBlockStatement( node.alternate.start, node.alternate.end );
}
}
this.magicString.addSourcemapLocation( node.start );
this.magicString.addSourcemapLocation( node.end );
},
...
)
}
}
export function isFalsy ( node ) {
return not( isTruthy( node ) );
}
export function isTruthy ( node ) {
if ( node.type === 'Literal' ) return !!node.value;
if ( node.type === 'ParenthesizedExpression' ) return isTruthy( node.expression );
if ( node.operator in operators ) return operators[ node.operator ]( node );
}
这里可以解释一下现象(把以下代码复制进https://astexplorer.net/ 看一下就行了)
// 不会打包进最终产物
if(false) {
console.log(1)
}
let b = false
//会打包进最终产物
if(b) {
console.log(1)
}
declaration和statement只收集了module顶层的变量和语句statement语句是否有副作用的方法在这里,如果看不懂自己的代码为啥会被treeshaking,可以参考这里github.com
END
- 以上可能存在理解不到位的地方,如有问题,还请指正
- 自己阅读源码的记录会统一放在这里,包括
single-spa rollup qiankun...
- 感谢阅读!
refer
- https://mp.weixin.qq.com/s/JndBu8maXC-f9r1Ghw8kgg
- https://astexplorer.net/
- github.com
- https://juejin.cn/post/7025193043460358151
- ECMAScript 里的 MemberExpression 是指什么? - navegador的回答 - 知乎 https://www.zhihu.com/question/432019874/answer/1595881300


![[附源码]JAVA毕业设计养老院老人日常生活管理系统(系统+LW)](https://img-blog.csdnimg.cn/38f8cf45719b4f47808ac8159b4febb8.png)