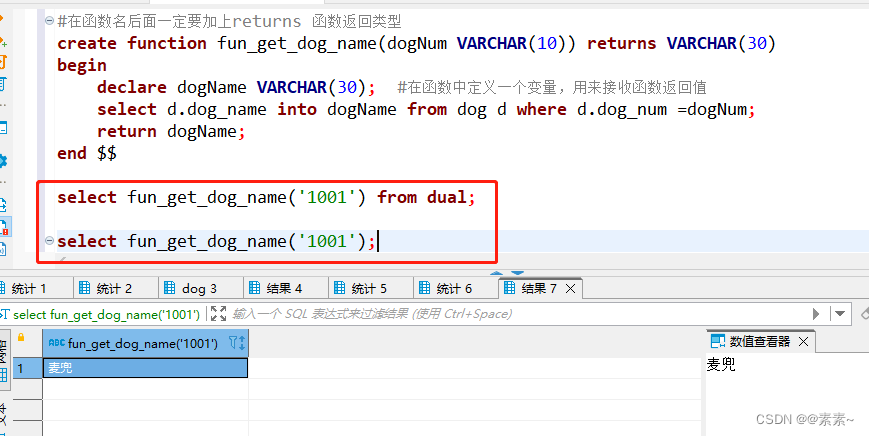
Go语言中的哈希表有它自己的一套实现方式。和Java的哈希表还是有些不同的,但是为了保证知识体系的完整性,我还是准备从头开始说起。
哈希表设计原理
哈希表的读写时间复杂度是O(1),因为它提供了键值之间的映射。要实现一个性能优异的哈希表,需要注意两个关键点
- 哈希函数
- 哈希冲突解决
哈希函数
一个优秀的哈希函数的标准:
哈希函数的映射要尽可能的均匀
解决冲突
结局冲突的方法:
- 开发寻址法
- 拉链法
我们这里说的哈希冲突其实并不一定是哈希完全相等,可能是哈希的部分相等,例如两个键对应哈希的前4个字节相同
开放寻址法
-
使用开放寻址法的时候哈希表的底层数据结构就是简单的数组,不过因为数组的长度有限,所以当我们向哈希表写入这个键值对的(love, forever)的时候会从如下的索引开始遍历:
index := hash("love") % array.len -
如果写入的时候发现
index位置上有哈希值,且哈希值与我当前要插入的数据相同,那么就说发生了哈希冲突 -
当遇到哈希冲突的时候,我们就把
index++,然后重复上面的哈希值判断过程,直到找到一个空位可以插入为止。 -
当进行查找的时候,我们也是按照上述方法进行遍历,遇到key相等的就比较值,如果值不相等就
index++继续向后比较。当遇到空位的时候,我们还没有从查找到结果的时候,就说明没有对应的值。
拉链法
拉链法是大多数哈希表的实现方式,它比开放寻址法优秀的地方在于使用链表动态的分配空间,节省较多的存储空间。
- 写入键值对。
- 同样使用
index := hash("love") % array.len的位置来进行遍历。 - 可能会遇到两种情况
- 没有找到键相同的键值对,在链表末尾追加新的键值对
- 找到相同的键值对,更新对应的值
拉链法和开放寻址法都存在装载因子这个概念。
装载因子 = 元素数量 / 桶数量
Go的map
概述
我们先用两张图来全局的查看Go的map。
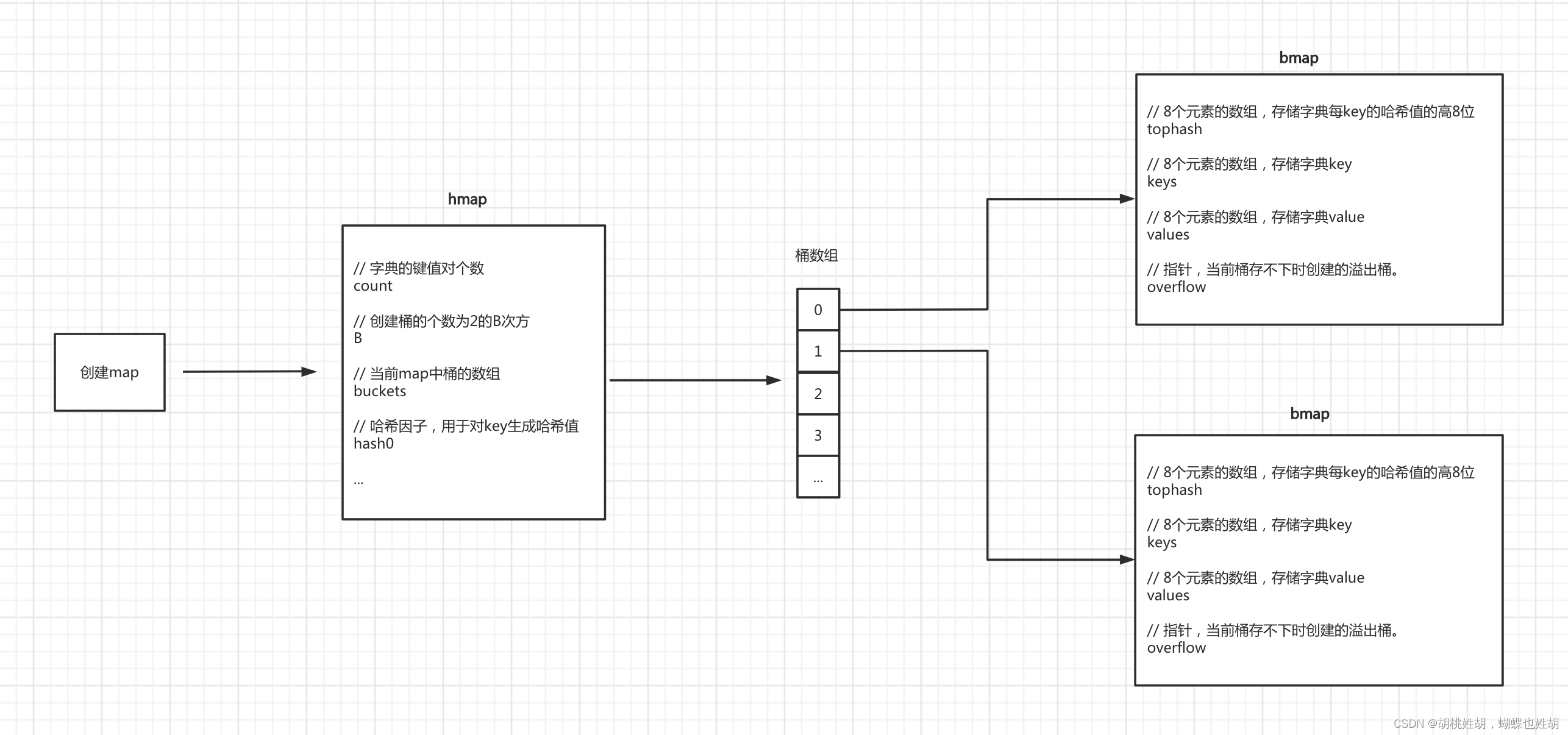
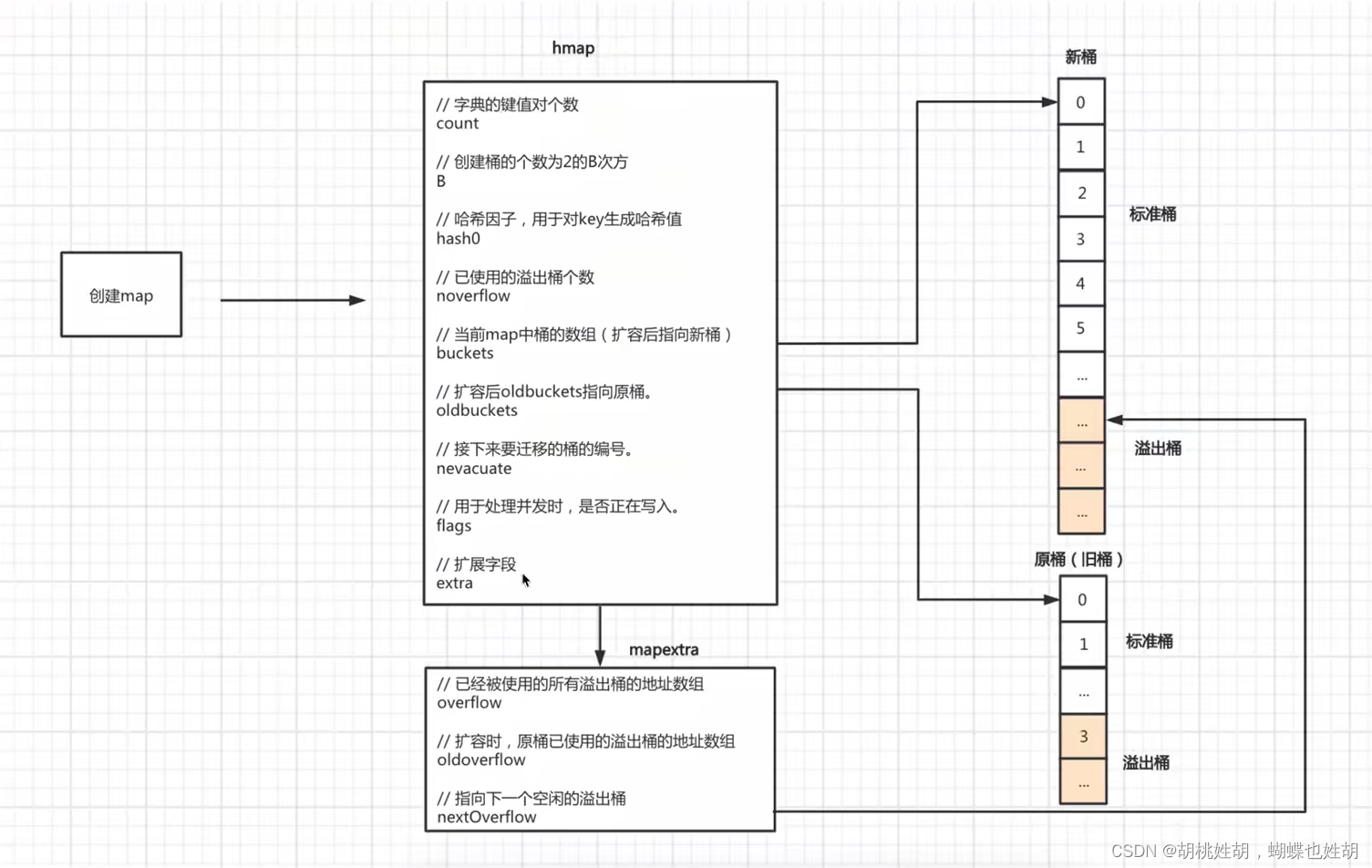
这下大家对哈希表肯定有了全局的概念了,接下来我们来逐一的进行分析:
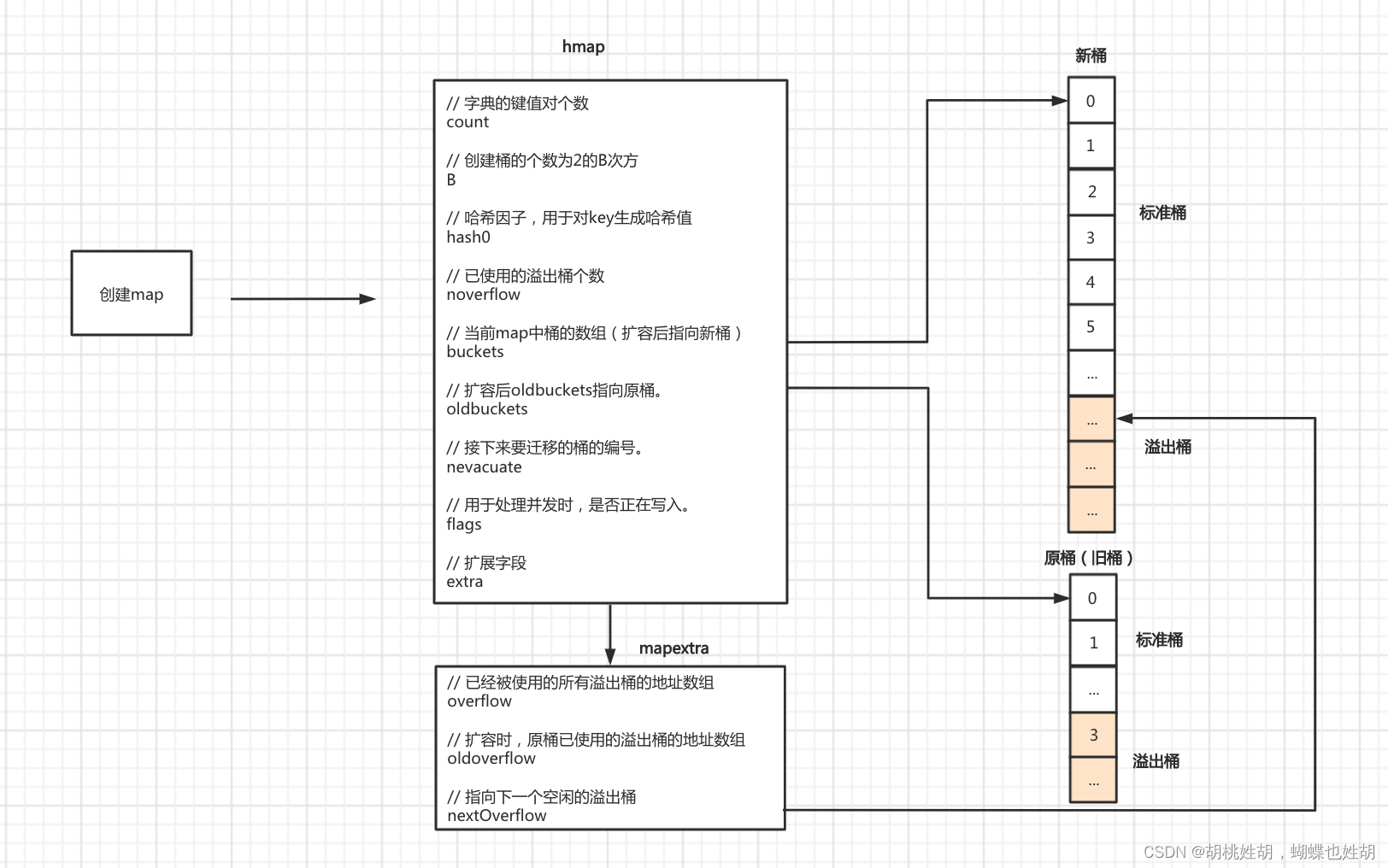
首先是最核心的结构体runtime.hmap
type hmap struct {
// 字典的键值对个数, len(m)
count int
// 标识位,按位与得到的flags,用于处理并发,map并不是并发安全的
// iterator = 1 buckets正在被遍历
// oldIterator = 2 oldbuckets正在被遍历
// hashWriting = 4 正在被写入
// sameSizeGrow = 8 是否有同样大小的扩容
flags uint8
// 创建桶的个数位2的B次方
B uint8
// 已使用的溢出桶的个数
noverflow uint16
// 哈希因子,用于对key生成hash值
hash0 uint32
// 当前map中的桶的数组(扩容后指向新桶)
buckets unsafe.Pointer
// 扩容后oldbuckets指向原桶
oldbuckets unsafe.Pointer
// 接下来要迁移的桶的编号
nevacuate uintptr
// 扩展字段, hmap用于宏观的表述整个哈希表,这个extra是用来表述溢出桶的,溢出桶是什么我们后面会详细的进行讲解,同时,这个字段还有一个作用,这个字段的指针指向溢出桶的地址,可以保证它使用是可用,不会被GC掉
extra *mapextra
}
我们可以看到这个结构体里面嵌套了一个结构体mapextra
所以我们来看一下这个结构体的定义:
type mapextra struct {
// 已经被使用的所有溢出桶的地址数组
overflow *[]*bmap
// 扩容时,原桶已使用的溢出桶的地址数组
oldoverflow *[]*bmap
// 指向下一个空闲的溢出桶
nextOverflow *bmap
}
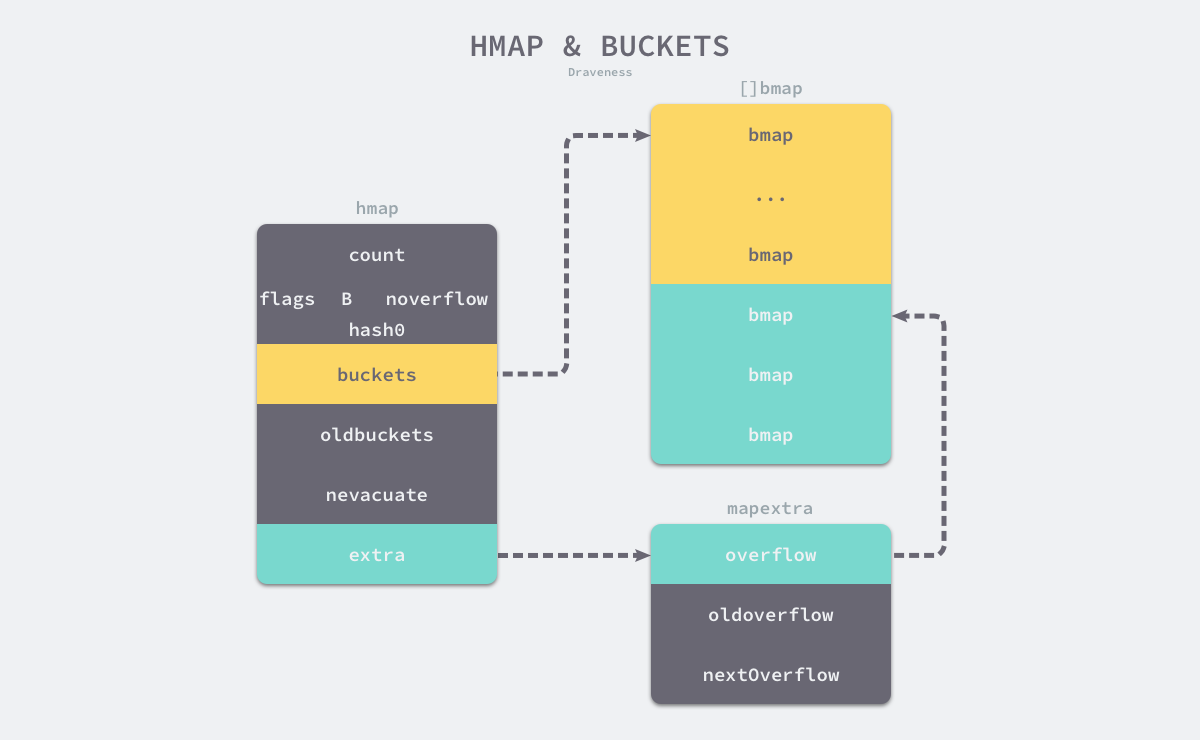
本图来自面向信仰编程的博客,这是一位神级大佬
bmap是hmap的桶,每一个bmap都可以存储8个键值对。
我们来看一下这个结构体:
// A bucket for a Go map.
type bmap struct {
// bucketCnt = 8
tophash [bucketCnt]uint8
}
可以看到它只有一个字段,但是实际上它不仅只包含了这一个字段的功能,因为哈希表中可能存储不同的键值对,而且Go不支持泛型,所以对键值对占据的内存空间的大小只能在编译时进行推导。它的其他字段实际上是不存在的,但是我们可以通过编译时的代码推断出它大致的结构:
type bmap struct {
// 8个元素的数组,存储字典key的高8位哈希值
topbits [8]uint8
// 8个元素的数组,存储字典的key
keys [8]keytype
// 8个元素的数组,存储字典value
values [8]valuetype
// 指针,当前桶存不下时创建的溢出桶
overflow uintptr
}
我们可以看到有两种桶正常桶和溢出桶。这两种桶在内存中是连续存储的,黄色的是正常桶,绿色的是溢出桶。
我们可用看到这个桶主要由4个部分组成:topbits部分,key存储部分,value存储部分,overflow部分。
topbits部分
运行时会使用hash函数计算出一个hashcode,这个东西非常关键,运行时会把它一分为二去看待,其中高8位用来选择是哪一个桶,低某位(不确定是几位,具体在后面进行讲解)用来选择topbits。如图:
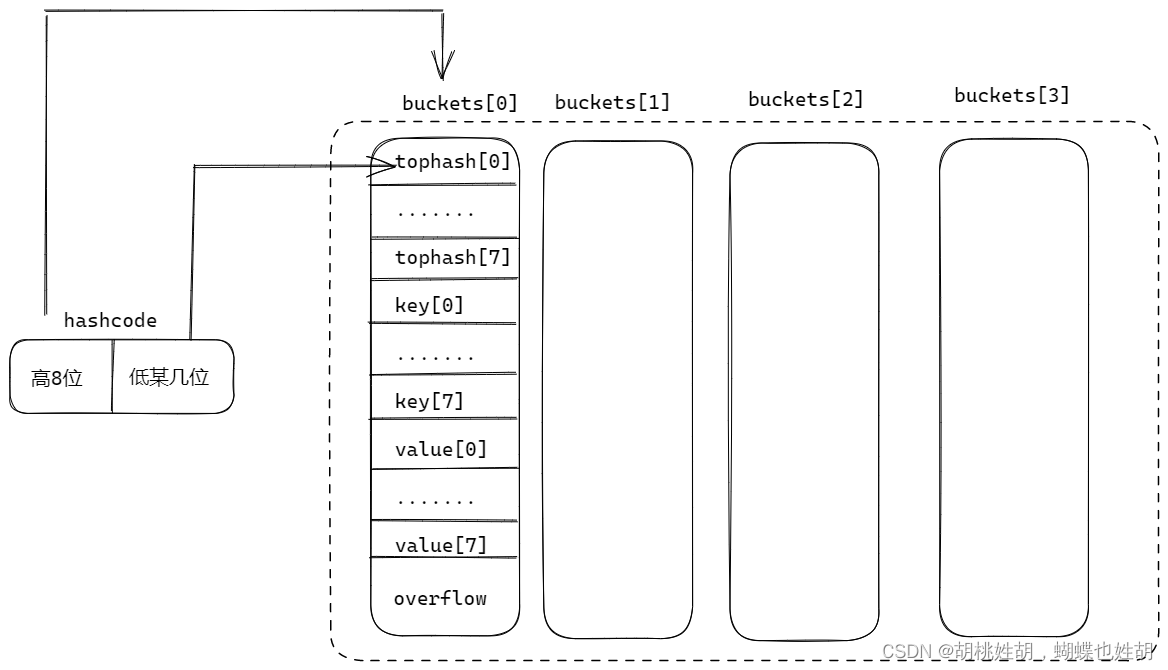
假如我定位到了tophash区域的0号,那么key就放在0号,value也是0号。
这样做的好处是:查找速度更快,因为字符串匹配也是需要很长时间的,如果key非常大,那么全部匹配就需要花费很多的时间
key存储区域
我们思考一个问题:我们可以看到tophash区域下面是一块连续的内存空间,存储的是这个桶承载的所有的key数据。运行时在分配bucket的时候需要知道key的size,那么它是如何知道的呢?
我们有一个结构体:
type maptype struct {
typ _type
key *_type
elem *_type
bucket *_type // internal type representing a hash bucket
// function for hashing keys (ptr to key, seed) -> hash
hasher func(unsafe.Pointer, uintptr) uintptr
keysize uint8 // size of key slot
elemsize uint8 // size of elem slot
bucketsize uint16 // size of bucket
flags uint32
}
当我们声明一个map类型的变量的时候例如var m map[string]int,Go会为这个实例生成一个runtime.maptype实例。后期所有的运行时方法的第一个参数都有这个结构体。
// 创建map类型变量实例
m := make(map[keyType]valType, capacityhint) → m := runtime.makemap(maptype, c
// 插入新键值对或给键重新赋值
m["key"] = "value" → v := runtime.mapassign(maptype, m, "key") v是用于后续存储val
// 获取某键的值
v := m["key"] → v := runtime.mapaccess1(maptype, m, "key")
v, ok := m["key"] → v, ok := runtime.mapaccess2(maptype, m, "key")
// 删除某键
delete(m, "key") → runtime.mapdelete(maptype, m, “key”)
map的操作的运行时会被替换成上面的这些函数
value存储区域
key和value是分开存储的,这样减少了内存对齐带来的空间浪费
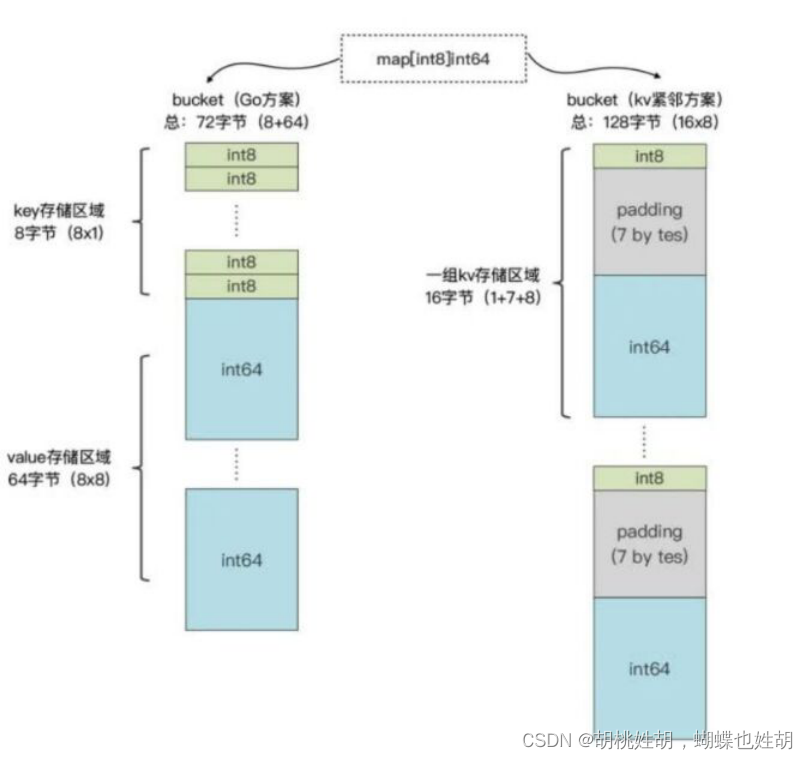
图片来自于《极客时间 – Tony Bai Go语言第一颗》
初始化
初始化哈希表有两种方法:
- 字面量
- 运行时
字面量
hash := map[string]int{
"1": 2,
"3": 4,
"5": 6,
}
-
当哈希表中的元素少于或者等于25个的时候,处理方法跟切片非常类似
// 代码会转换成以下代码 hash := make(map[string]int, 3) hash["1"] = 2 hash["3"] = 4 hash["5"] = 6 -
如果超过25个的话,编译器就会创建两个数组分别存储键和值用以下方式假如哈希表:
hash := make(map[string]int, 26) vstatk := []string{"1", "2", "3", ... , "26"} vstatv := []int{1, 2, 3, ... , 26} for i := 0; i < len(vstak); i++ { hash[vstatk[i]] = vstatv[i] }当然,切片的创建会按照切片字面量初始化的方式再度展开,可以回顾我的博客《Go设计与实习-数组和切片》
运行时
-
如果哈希表被分配到栈上并且容量小于
BUCKETSIZE = 8的时候,Go会用如下方法快速初始化哈希表:var h *hmap var hv hmap var bv bmap h := &hv b := &bv h.buckets = b h.hash0 = fashtrand0() -
除了上面这个优化之外,我们只要使用
make进行初始化,都会被转换成runtime.makemap来进行初始化:func makemap(t *maptype, hint int, h *hmap) *hmap { // 计算哈希表占用的内存是否溢出或者超出能分配的最大值 mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size) if overflow || mem > maxAlloc { hint = 0 } // 初始化hamp if h == nil { h = new(hmap) } // 传入一个随机的哈希种子 h.hash0 = fastrand() // 根据hint计算出需要多少桶,例如B是2,那么就是4桶,3就是8桶,4就是16桶以此类推 B := uint8(0) for overLoadFactor(hint, B) { B++ } h.B = B // allocate initial hash table // if B == 0, the buckets field is allocated lazily later (in mapassign) // If hint is large zeroing this memory could take a while. if h.B != 0 { var nextOverflow *bmap // 创建用于保存桶的数组 h.buckets, nextOverflow = makeBucketArray(t, h.B, nil) if nextOverflow != nil { h.extra = new(mapextra) h.extra.nextOverflow = nextOverflow } } return h } -
我们来仔细看一下
makeBucketArray的源码// makeBucketArray initializes a backing array for map buckets. // 1<<b is the minimum number of buckets to allocate. // dirtyalloc should either be nil or a bucket array previously // allocated by makeBucketArray with the same t and b parameters. // If dirtyalloc is nil a new backing array will be alloced and // otherwise dirtyalloc will be cleared and reused as backing array. func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) { base := bucketShift(b) nbuckets := base // For small b, overflow buckets are unlikely. // Avoid the overhead of the calculation. if b >= 4 { // Add on the estimated number of overflow buckets // required to insert the median number of elements // used with this value of b. nbuckets += bucketShift(b - 4) sz := t.bucket.size * nbuckets up := roundupsize(sz) if up != sz { nbuckets = up / t.bucket.size } } if dirtyalloc == nil { buckets = newarray(t.bucket, int(nbuckets)) } else { // dirtyalloc was previously generated by // the above newarray(t.bucket, int(nbuckets)) // but may not be empty. buckets = dirtyalloc size := t.bucket.size * nbuckets if t.bucket.ptrdata != 0 { memclrHasPointers(buckets, size) } else { memclrNoHeapPointers(buckets, size) } } if base != nbuckets { // We preallocated some overflow buckets. // To keep the overhead of tracking these overflow buckets to a minimum, // we use the convention that if a preallocated overflow bucket's overflow // pointer is nil, then there are more available by bumping the pointer. // We need a safe non-nil pointer for the last overflow bucket; just use buckets. nextOverflow = (*bmap)(add(buckets, base*uintptr(t.bucketsize))) last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.bucketsize))) last.setoverflow(t, (*bmap)(buckets)) } return buckets, nextOverflow }通过源码我们可以知道:
- 当B <= 4的时候,也就是桶小于等于2^4的时候,使用溢出桶的可能性比较小,会省略创建溢出桶的过程
- 当大于这个数量的时候,会通过
runtime.newobject格外创建2^(B - 4)个溢出桶
总结初始化过程:
- 生成
runtime.maptype - 以
runtime.maptype为参数使用makemap方法 - 在
makemap方法中创建一个hmap结构体对象 - 在
makemap方法中生成一个哈希因子并赋值到hmap当中,为后续的key创建哈希值 - 根据
hint的数值,(make(map[string]int, 10),这个传过去的10就是hint的值)来计算B - 根据B去创建桶对象
- 当
B < 4的时候创建2^B个标准桶 - 否则创建2^B + 2^(B-4)个桶(标准桶+溢出桶)
- 当
写操作
hash["zyq"] = "love"
当hash[k]的表达式出现在赋值符号左侧的时候,该表达式会在编译期间被转换成runtime.mapassign函数的调用
这个函数的内部的执行流程为:
-
第一步:结合哈希因子和键
name生成哈希值011011100011111110111011011。 -
第二步:获取哈希值的
后B位,并根据后B为的值来决定将此键值对存放到那个桶中(bmap)。- 将哈希值和桶掩码(B个为1的二进制)进行 & 运算,最终得到哈希值的后B位的值。假设当B为1时,其结果为 0
- 哈希值:
011011100011111110111011010 - 桶掩码:
000000000000000000000000001 - 结果:
000000000000000000000000000=0
通过示例你会发现,找桶的原则实际上是根据后B为的位运算计算出 索引位置,然后再去buckets数组中根据索引找到目标桶(bmap)。
-
第三步:在上一步确定桶之后,接下来就在桶中写入数据。
- 获取哈希值的
tophash(即:哈希值的高8位),将tophash、key、value分别写入到桶中的三个数组中。查找方式是循环遍历,先遍历正常桶再遍历溢出桶。 - 如果桶已满,则通过overflow找到溢出桶,并在溢出桶中继续写入。如果溢出桶也满了就继续创建,
hamp.noverflow需要增加
注意:以后在桶中查找数据时,会基于tophash来找(tophash相同则再去比较key)。
- 获取哈希值的
-
第四步:
hmap的个数count++(map中的元素个数+1)
注意:
runtime.mapassign这个函数不会把数值赋值到桶中,它只会返回需要赋值的内存地址,真正的赋值操作在编译期间插入。00018 (+5) CALL runtime.mapassign_fast64(SB) 00020 (5) MOVQ 24(SP), DI ;; DI = &value 00026 (5) LEAQ go.string."88"(SB), AX ;; AX = &"88" 00027 (5) MOVQ AX, (DI) ;; *DI = AX如果桶正在被rehash的话,那么数据只写在新的桶中
读操作
和写操作差不多。
name := hash["name"]
在map中读取数据时,内部的执行流程为:
-
第一步:结合哈希引子和键
name生成哈希值。 -
第二步:获取哈希值的
后B位,并根据后B为的值来决定将此键值对存放到那个桶中(bmap)。 -
第三步:确定桶之后,再根据key的哈希值计算出tophash(高8位),根据tophash和key去桶中查找数据。
当前桶如果没找到,则根据overflow再去溢出桶中找,均未找到则表示key不存在。
如果桶正在被rehash的话,那么oldbuckets和buckets的数据都要去遍历进行读取
删除操作
delete关键字会被这样转换:
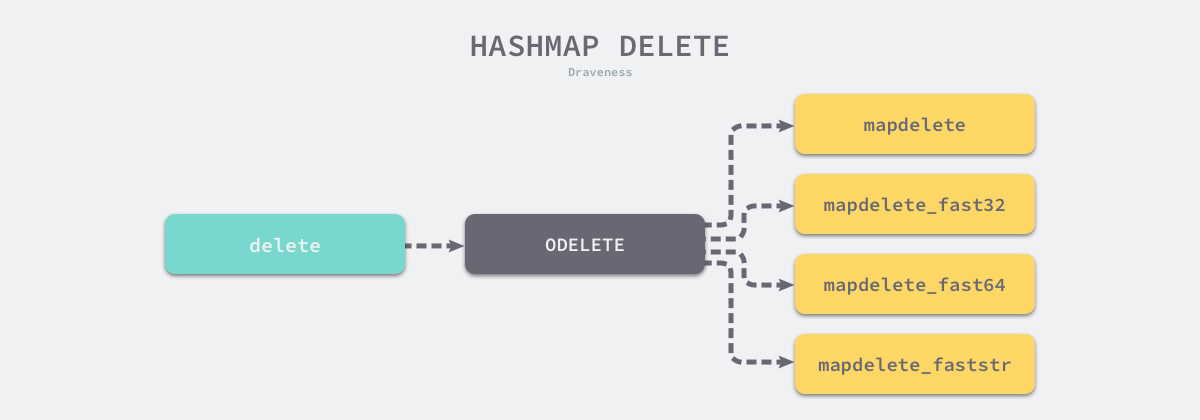
本图来自面向信仰编程的博客
具体过程其实和写入也是差不多的。
如果删除太多了,那么桶会缩容,缩容和扩容是一套机制的,所以我们接下来着重讲解扩容
扩容
删除,写入操作都会设计到扩容。扩容会涉及到迁移,接下来详细的进行讲解。
删除的函数和写入是差不多的,所以我们只用写入的runtime.mapassign来进行讲解。
这个函数遇到两种情况的时候会进行扩容:
- 装载因子超过6.5,此时进行翻倍扩容
- 哈希表使用了太多溢出桶 – 如果我们把表中插入的数据全部删除,可能会导致溢出桶里面东西很多,而正常桶反而没有装满,此时进行等量扩容
扩容条件:
- map中数据总个数 / 桶个数 > 6.5 ,引发翻倍扩容。
- 使用了太多的溢出桶时(溢出桶使用的太多会导致map处理速度降低)。
- B <=15,已使用的溢出桶个数 >= 2B 时,引发等量扩容。
- B > 15,已使用的溢出桶个数 >= 2^15 时,引发等量扩容。
func hashGrow(t *maptype, h *hmap) {
// If we've hit the load factor, get bigger.
// Otherwise, there are too many overflow buckets,
// so keep the same number of buckets and "grow" laterally.
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
...
}
但是这个runtime.hashGrow没有真正的对数据进行复制和转移,真正的复制和转移是在runtime.evacuate中完成的。
runtime.evacuate会把一个旧桶分流到两个新桶,所以它会创建两个用于保存分配上下文的结构体,如果是等量复制的话就只有一个结构体:这两个结构i他分别指向了一个新桶。
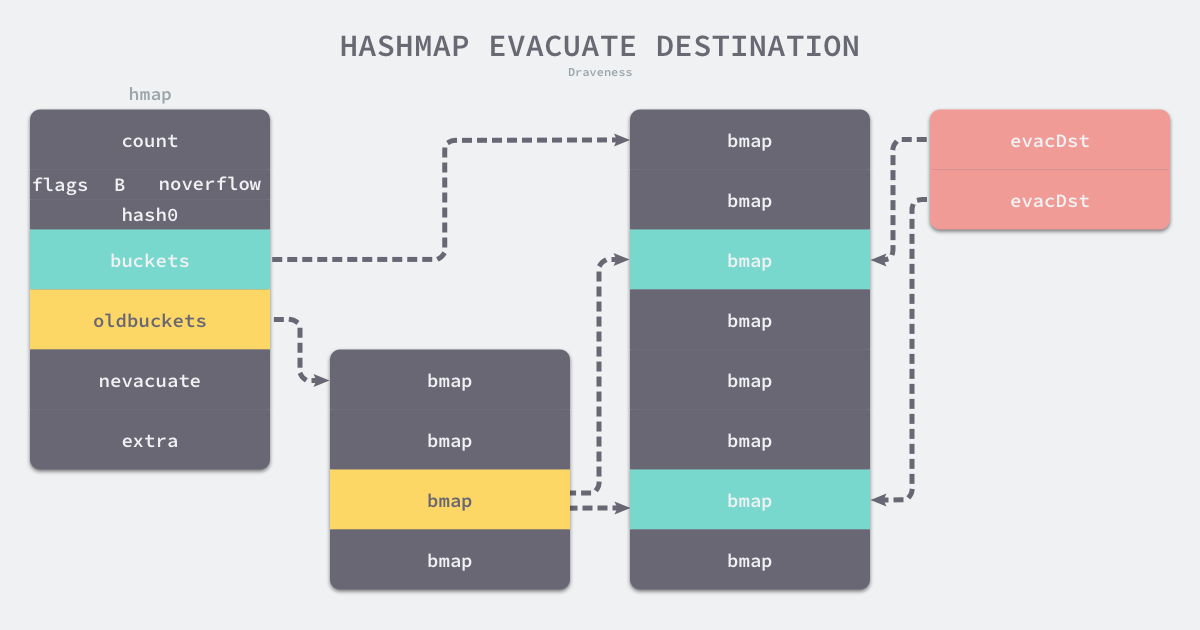
图片来自面向信仰编程
// evacDst is an evacuation destination.
type evacDst struct {
b *bmap // current destination bucket
i int // key/elem index into b
k unsafe.Pointer // pointer to current key storage
e unsafe.Pointer // pointer to current elem storage
}
当扩容之后:
- 第一步:B会根据扩容后新桶的个数进行增加(翻倍扩容新B=旧B+1,等量扩容 新B=旧B)。
- 第二步:oldbuckets指向原来的桶(旧桶)。
- 第三步:buckets指向新创建的桶(新桶中暂时还没有数据)。
- 第四步:nevacuate设置为0,表示如果数据迁移的话,应该从原桶(旧桶)中的第0个位置开始迁移。
- 第五步:noverflow设置为0,扩容后新桶中已使用的溢出桶为0。
- 第六步:extra.oldoverflow设置为原桶(旧桶)已使用的所有溢出桶。即:
h.extra.oldoverflow = h.extra.overflow - 第七步:extra.overflow设置为nil,因为新桶中还未使用溢出桶。
- 第八步:extra.nextOverflow设置为新创建的桶中的第一个溢出桶的位置。
2.3.5 迁移
扩容之后,必然要伴随着数据的迁移,即:将旧桶中的数据要迁移到新桶中。
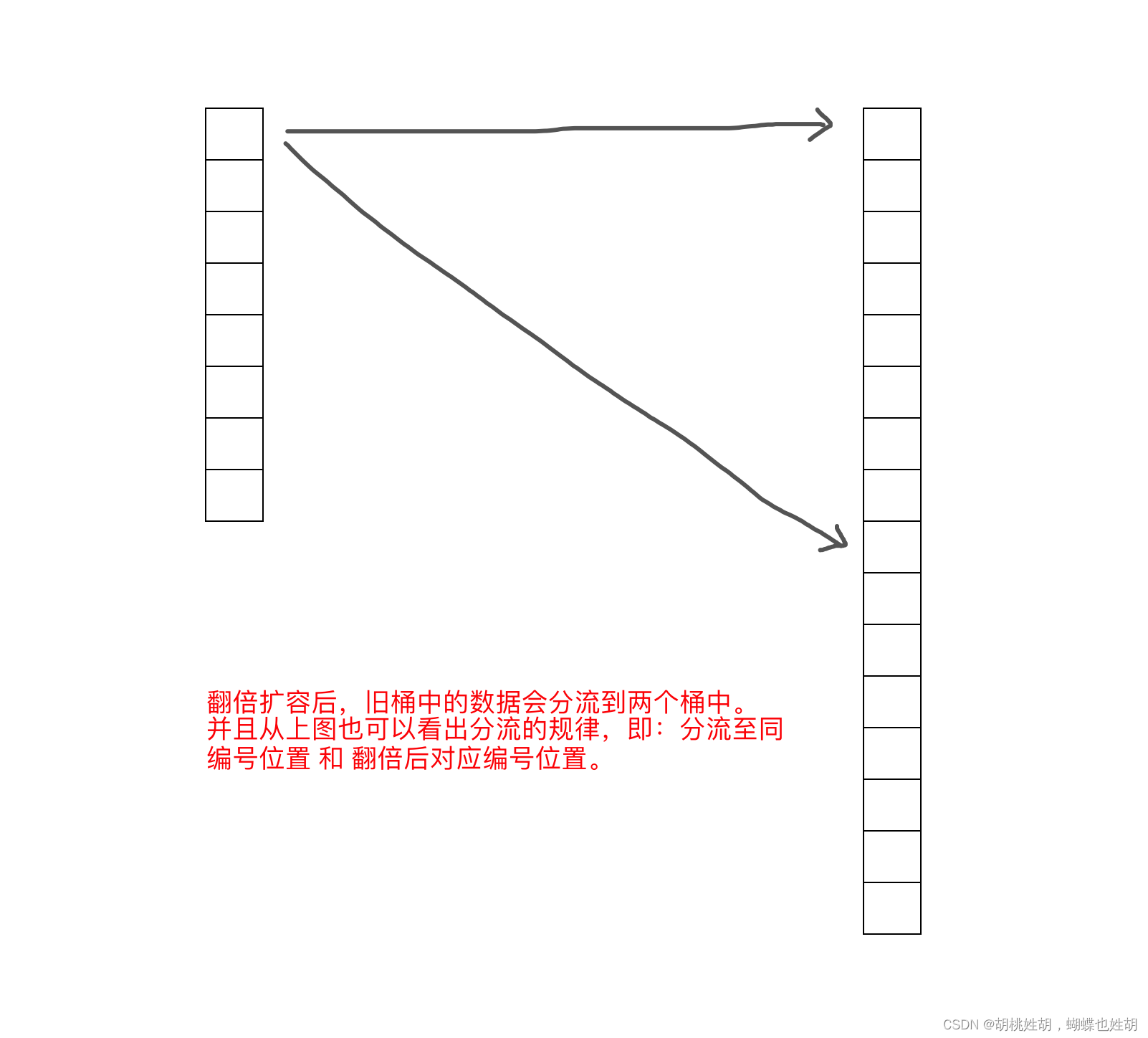
翻倍扩容
如果是翻倍扩容,那么迁移规就是将旧桶中的数据分流至新的两个桶中(比例不定),并且桶编号的位置为:同编号位置 和 翻倍后对应编号位置。
那么问题来了,如何实现的这种迁移呢?
首先,我们要知道如果翻倍扩容(数据总个数 / 桶个数 > 6.5),则新桶个数是旧桶的2倍,即:map中的B的值要+1(因为桶的个数等于
2
B
2^B
2B,而翻倍之后新桶的个数就是
2
B
2^B
2B * 2 ,也就是
2
B
+
1
2^{B+1}
2B+1,所以 新桶的B的值=原桶B + 1 )。
迁移时会遍历某个旧桶中所有的key(包括溢出桶),并根据key重新生成哈希值,根据哈希值的 底B位 来决定将此键值对分流道那个新桶中。
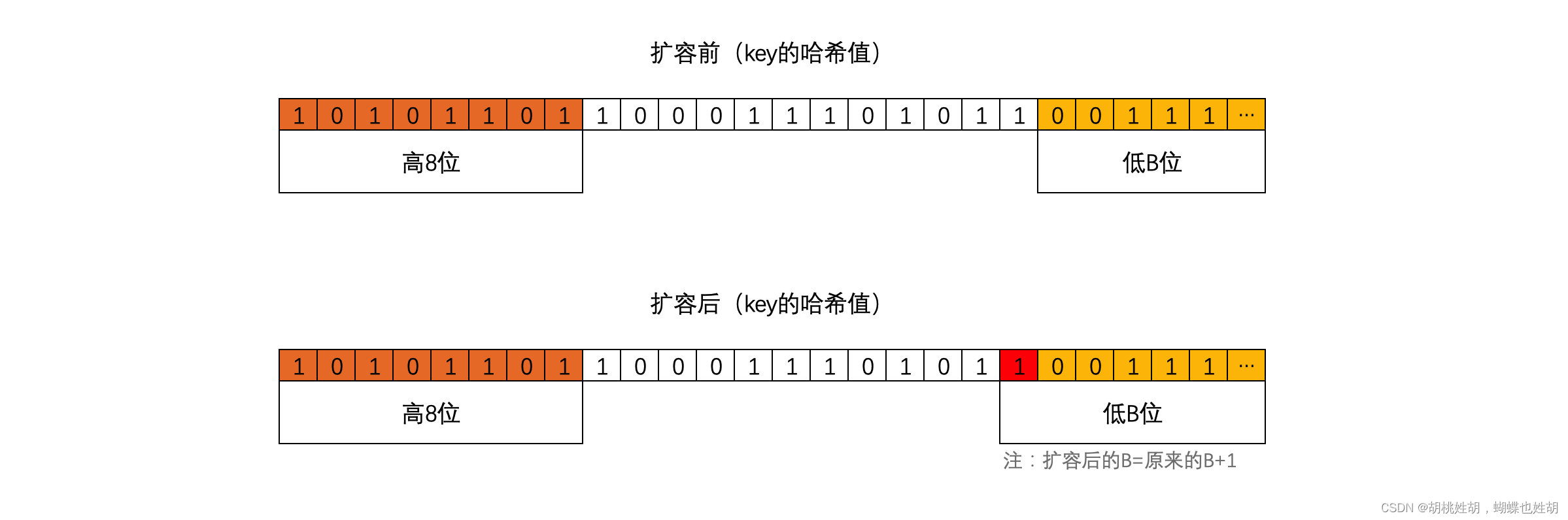
扩容后,B的值在原来的基础上已加1,也就意味着通过多1位来计算此键值对要分流到新桶位置,如上图:
- 当新增的位(红色)的值为 0,则数据会迁移到与旧桶编号一致的位置。
- 当新增的位(红色)的值为 1,则数据会迁移到翻倍后对应编号位置。
例如:
旧桶个数为32个,翻倍后新桶的个数为64。
在重新计算旧桶中的所有key哈希值时,红色位只能是0或1,所以桶中的所有数据的后B位只能是以下两种情况:
- 000111【7】,意味着要迁移到与旧桶编号一致的位置。
- 100111【39】,意味着会迁移到翻倍后对应编号位置。
特别提醒:同一个桶中key的哈希值的低B位一定是相同的,不然不会放在同一个桶中,所以同一个桶中黄色标记的位都是相同的。
等量扩容
如果是等量扩容(溢出桶太多引发的扩容),那么数据迁移机制就会比较简单,就是将旧桶(含溢出桶)中的值迁移到新桶中。
这种扩容和迁移的意义在于:当溢出桶比较多而每个桶中的数据又不多时,可以通过等量扩容和迁移让数据更紧凑,从而减少溢出桶。
扩容过程是rehash的过程,每次操作数据的时候顺便扩容一部分,所以不会对map的性能进行抖动