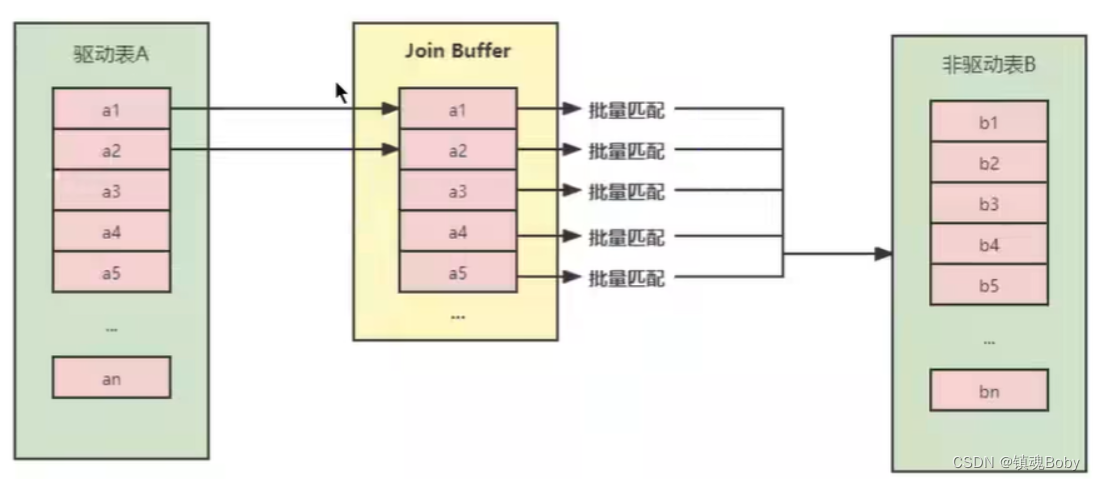
🔍 经验使你在第二次犯相同错误时及时发现。 —— 琼斯
🔖 事故时间:12.7日 17:43 ~ 21:03
🔖 事故影响:服务接口查询慢,用户查看数据转圈
🔖 事故过程:
那是一个宛如平静的下午,一群程序员像往常一样工作着....
突然,在17:43时,运营和运维反馈我们的产品转圈了,且监控发现大量异常发生。
随后我去APM上看了监控,发现service请求响应时间激增。
第一时间怀疑是数据库TiDB的问题(因为就在前几天有个TiDB问题,且还没有修复上线)。
17:50 为了防止大量请求堆积把服务打挂,于是我便进行了服务的重启。
17:55 重启完发现响应时间确实降下来了。
18:20 观察了一阵,发现接口查询已经缓解,于是便先通知了运营。
此时已经算是松了一口气,随后,后端同学便开始排查问题原因。
最开始的排查思路,是这样的:
因为17:30 时突然有大量请求,怀疑是大量查询造成了DB压力,然后造成了查询超时。
于是开始逐一排查激增时间段的这些请求接口。
(我认为这里有一个误区,就当服务整体不可用时,单看某一个或者某几个接口很难排查到问题原因,
应尽量先从全局共享资源去考虑,例如:数据库、缓存、服务CPU、服务内存、网络等)
期间有一个schedule问题,也怀疑过是这个问题造成的,但最终分析不是主要原因。
随着时间的流逝,发现服务每半小时还是有抖动。
不料,20:14 运维和运营同学又相继反馈大量异常和查询慢问题。
20:31,后端同学发现service服务CPU自从12.6发版后异常的高,比平常要翻一倍多。且GC次数也异常增多。
20:33,拉上其他同学,召开紧急会议,确定回退服务对超级店长没有影响时,便进行了版本回滚。
20:49,把服务回滚完毕,继续观察。回滚完CPU果然回到了正常,一切恢复平静,总算松了一口气。
随后,便反馈给运营同学。
12.8 ~ 12.11号,后端同学耗费了大量时间和人力,终于排查到问题根因,以此文章记录事故发生过程及问题排查思路。
🔖 结果根因
根本原因是由于DevOps平台的maven构建近期可能进行了更新,后端同学在构建时发现报错,于是在pom中指定了maven-plugin的版本为项目的springboot版本,也就是2.3.2-RELEASE,怎料spring-boot-loader在2.3.2-REALEASE版本👉👉👉👉👉存在BUG:
当加载不存在类时,会产生大量JarFile对象实例未被引用,从而产生内存泄露,引发服务进行频繁GC而抢占大量的CPU资源,从而引发CPU占用激增,造成服务整体卡顿。
https://github.com/spring-projects/spring-boot/issues/22991
https://github.com/spring-projects/spring-boot/issues/28042
🔖 排查方式
我们花了四天时间,从各个角度对服务进行了问题排查,希望对以后排查问题的同学能有前车之鉴。
下面是不同角度的排查思路:
1.代码
用了一天的时间进行了新发代码的Review,发现除了有个interface版本不一致问题(后来验证该问题不影响主要逻辑),其他业务代码并没有致命问题。
(但最终问题还是因为一行代码引发的血泪事故,这告诫我们——不要忽略任何一行不起眼的代码)
2.日志
除了零碎的几个NPM异常,并没有其他的大量错误日志。
3.JVM(调试三件套:IDEA + arthas + jProfiler)
此处涉及大量的底层知识,如果有些你看不懂,证明你该学习了。
3.1 堆内存
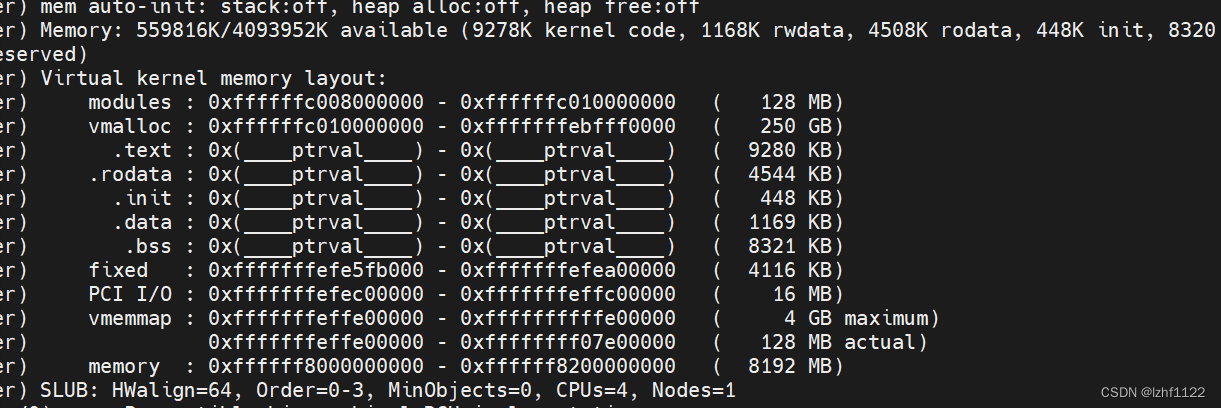
起初的堆内存配置是这样的:
java -jar
-Dcom.sun.management.jmxremote.authenticate=false
-Dcom.sun.management.jmxremote.port=1899
-Dcom.sun.management.jmxremote.ssl=false
-Xms1024m -Xmx6144m -Xmn2048m -Xss2048K
-XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=512m
通过Arthas的memory命令监控得到:
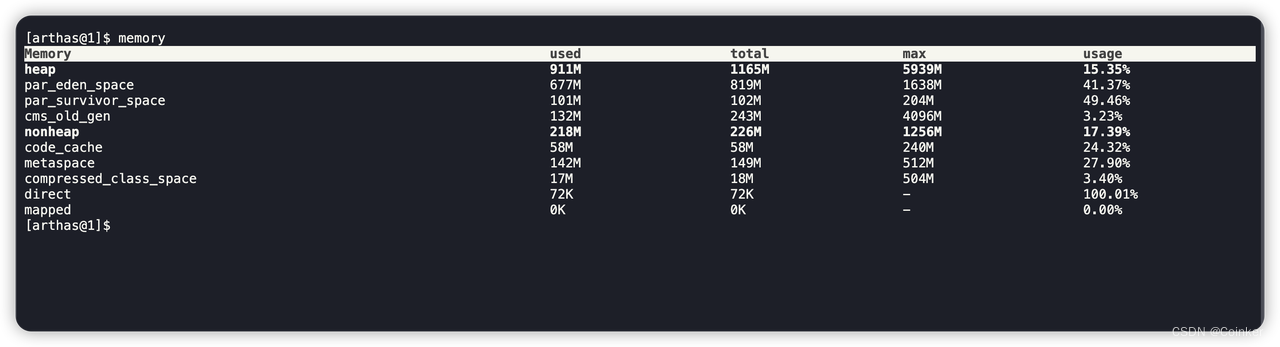
持续监控,发现堆内存的survivor区域持续100%,也就是新生代在不停的进行ParaNewGC,以至于大对象会随着GC次数的增加逐渐进入老年代,而老年代用CSM收集器再会进行回收。
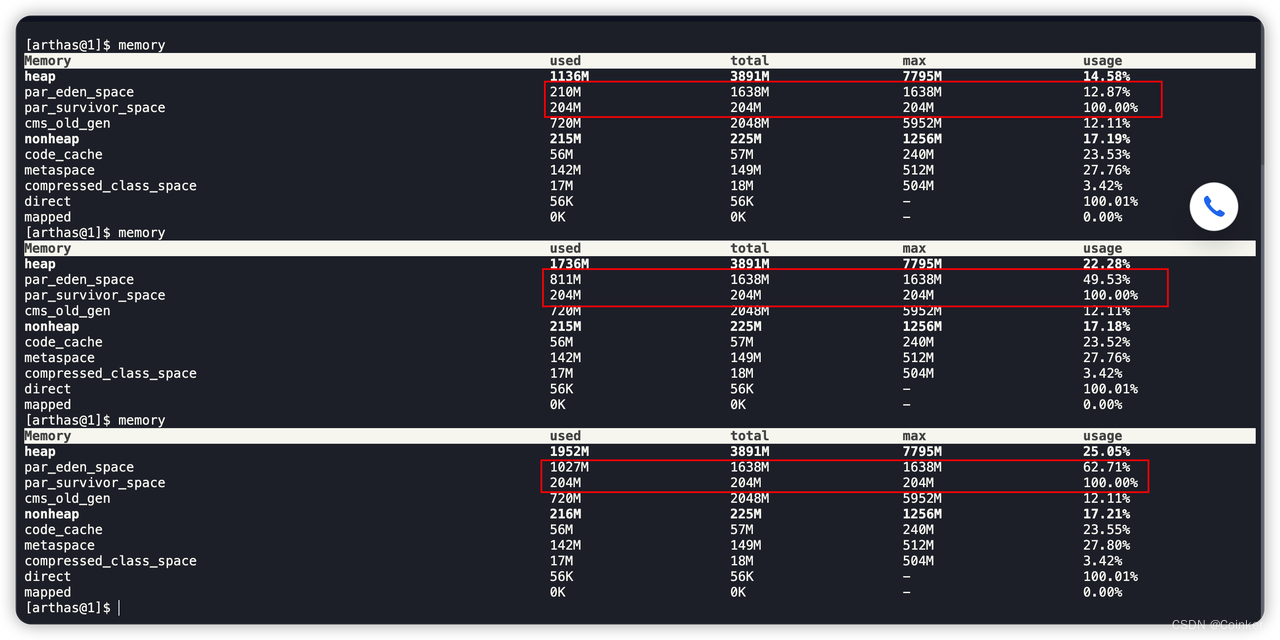
我画了一下此时的JVM内存结构图:
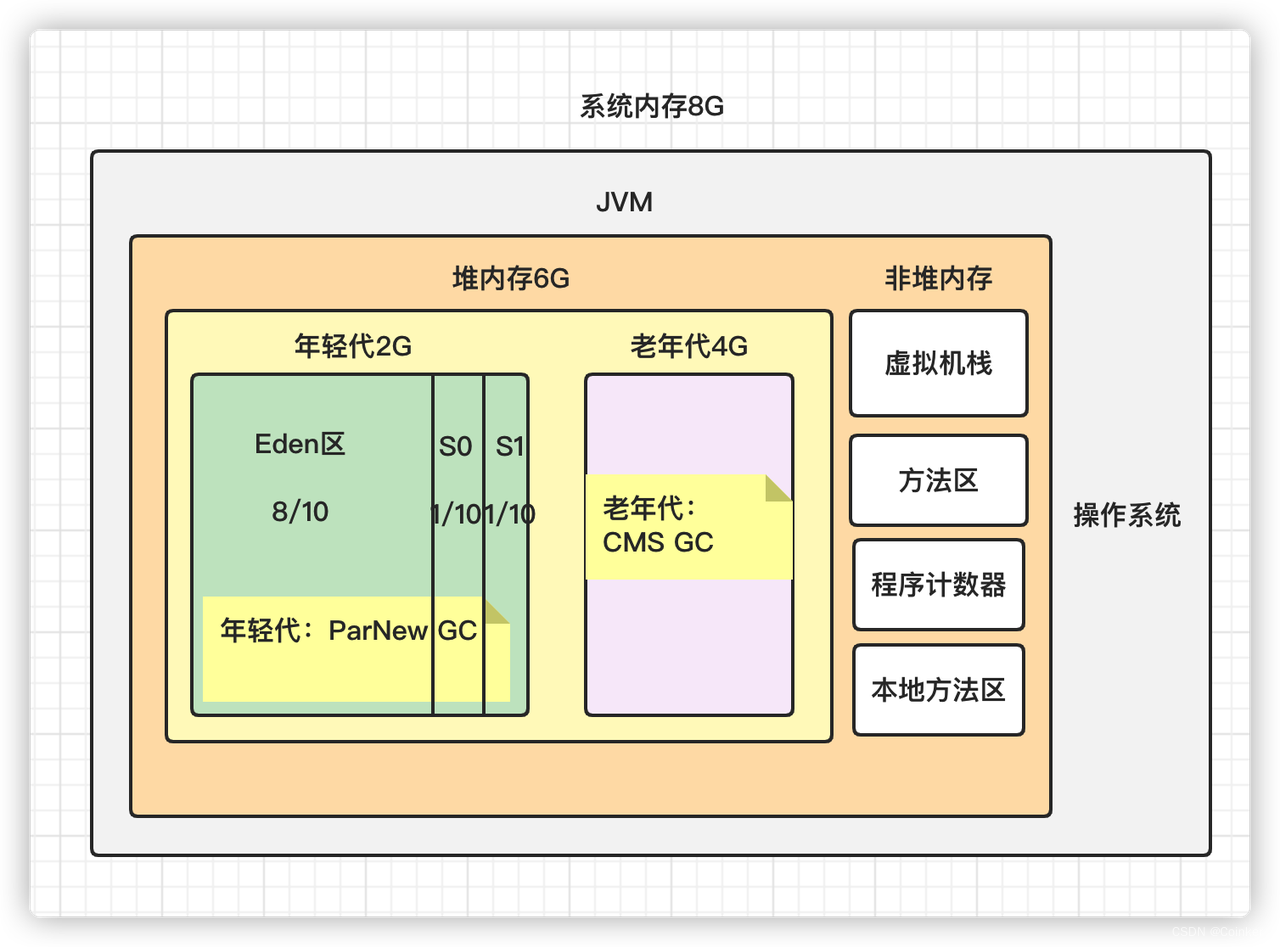
这里的话,有一个问题就是初始堆内存分配的1024M(-Xms1024m),有点小的其实。既然Pod已经分配了4~8个g内存,干脆直接把起始内存分配的大一些。通过实践,发现确实有所改善,但并不是引发事故的主要原因。
-Xms4096m -Xmx8000m -Xmn2048m -Xss2048K -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=512m
3.2 线程
通过arthas的thread --state BLOCKED命令查看阻塞线程,发现确实每隔几秒钟就有几个线程处于BLOCKED阻塞状态,其中占用CPU资源最大的就是Finalizer线程。
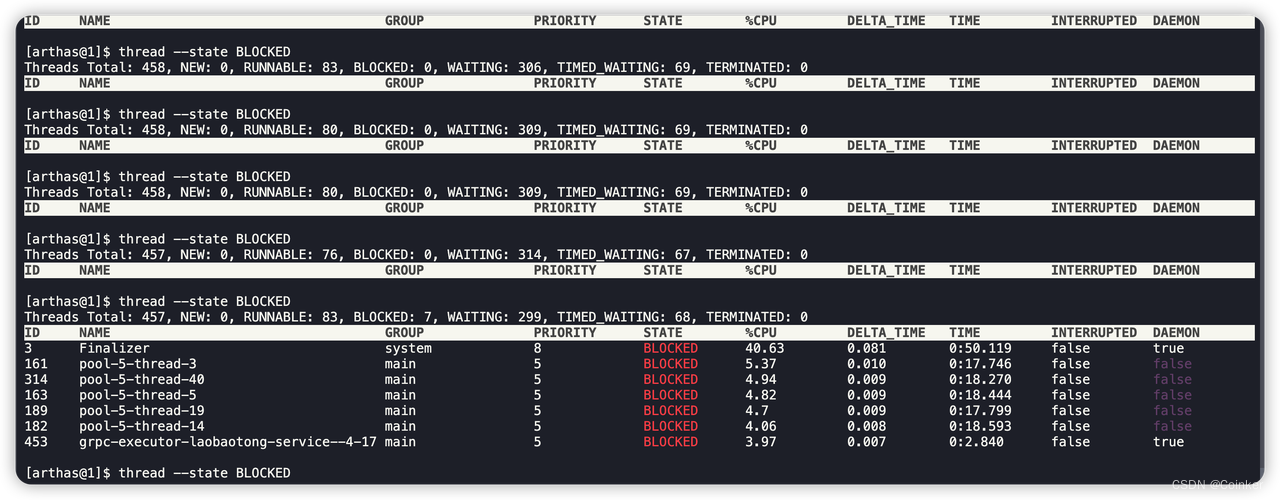
那么什么是Finalizer线程?它都做了什么事情?
https://binkery.com/archives/362.html
其实通过这里,其实已经可以定位到是由于GC大量消耗CPU造成的资源紧张了。
顺着上面的思路,我们生成几份JVM堆内存快照,拷贝下来进行分析:
arthas生成内存快照命令:
heapdump --live /root/jvm.hprof
这里有一个Tips,就是如果你拉下来了大量不同间隔时间内存快照,怎么知道优先分析哪个?
原则是——优先选择文件最大的那个
因为文件越大,证明占用内存越多,越容易得到更多的信息。
通过JProfiler利器可以对快照进行分析:
异常Pod和正常Pod的快照实例数对比,发现异常Pod的Finalizer类很多,相差数倍:

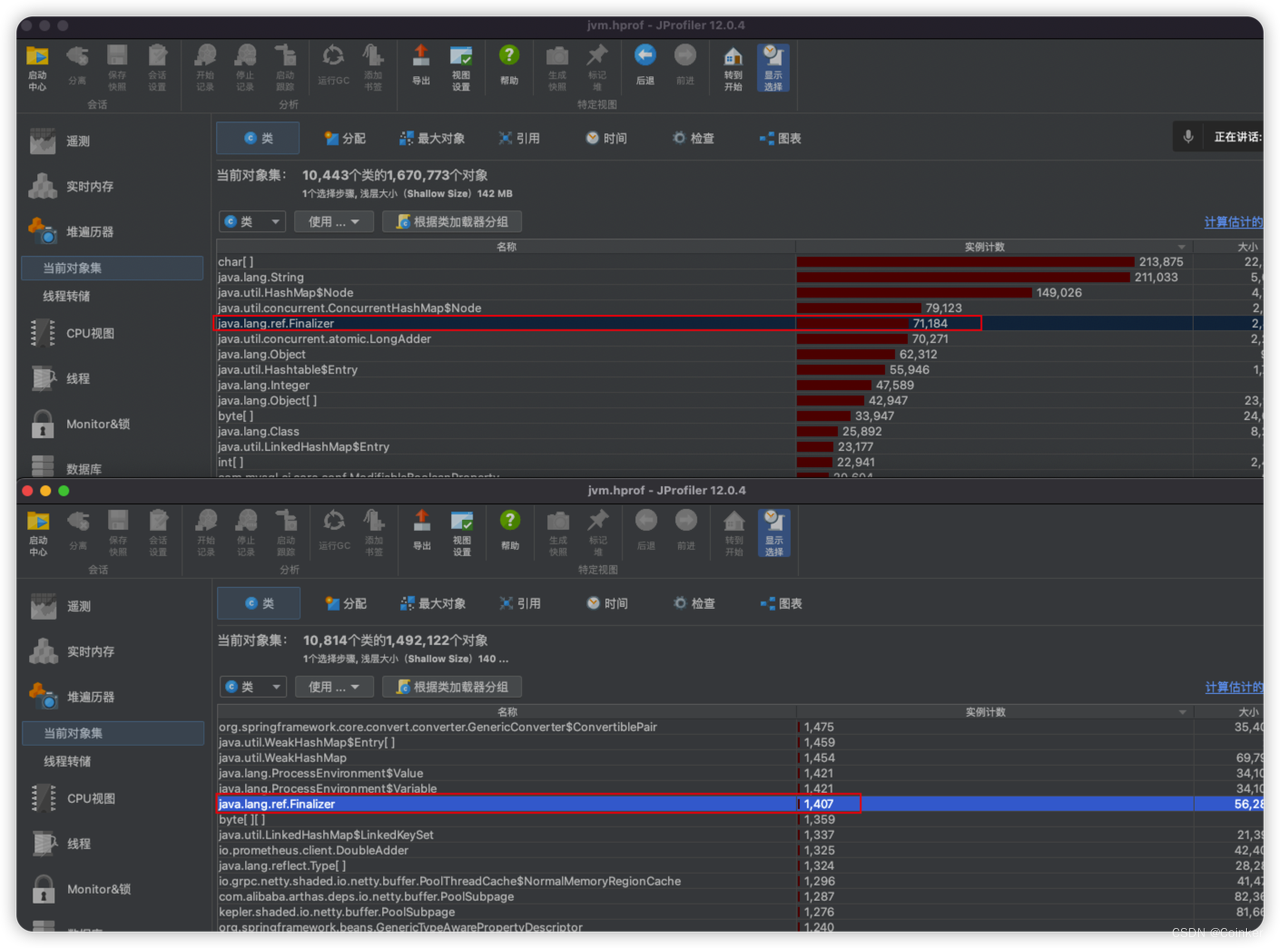
继续分析Finalizer这个对象,发现它大量都与JarFile这个类相关联,而JarFile是做什么的呢?
它是spring boot 对JDK的JarFile的一种拓展,用于我们的spring boot Jar包运行时,把包中的依赖包加载到内存中,通过spring boot的类加载器进行加载。
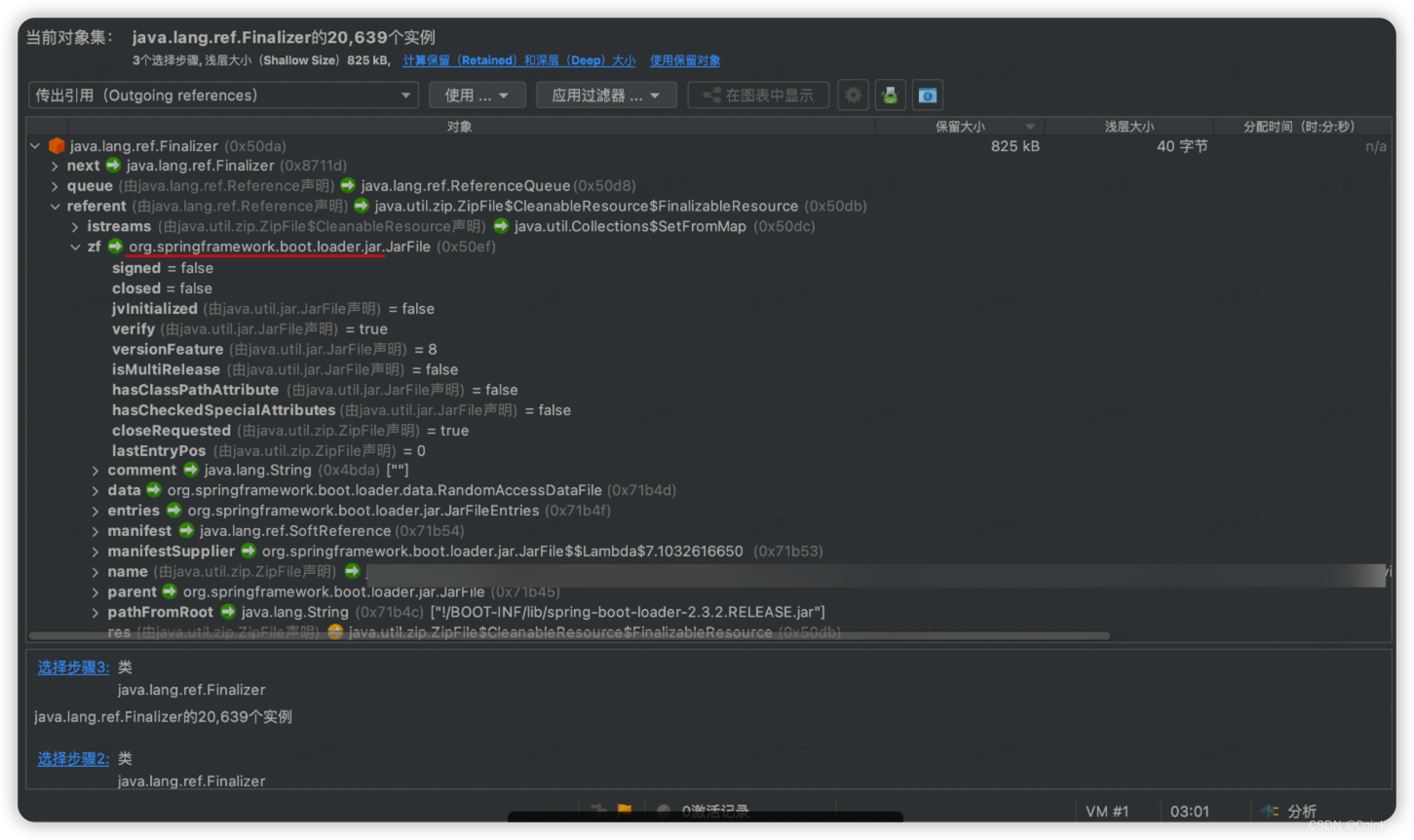
在这里拓展一些知识:
就是spring boot 打包后的结构(你可以自己解压一个jar包试试):
project/
├── BOOT-INF/
│ ├── classes # 当前项目结果文件放置在 classes 路径下
│ │ │ └── application.properties # 项目中配置文件
│ │ ├── org/ # 项目中 java 路径下,编译成 class 文件路径
│ │ ├── static/ # 项目中 resources 路径下的静态文件夹
│ │ └── templates/ # 项目中 resources 路径下的模板文件夹
│ └── lib/ # 项目所依赖的第三方 jar(Tomcat,SpringBoot 等)
├── META-INF/
│ └── MANIFEST.MF # 清单文件,用于描述可执行 jar 的一些基本信息
└── org/springframework/boot/loader/ # jar 包启动相关的引导
├── archive/
├── data
├── ExectableArchiveLauncher.class
├── jar/
├── JarLauncher.class
├── LaunchedURLClassLoader.class
├── LaunchedURLClassLoader$UseFastConnectionExceptionsEnumeration.class
├── Launcher.class
├── MainMethodRunner.class
├── PropertiesLauncher.class
├── PropertiesLauncher$1.class
├── PropertiesLauncher$ArchiveEntryFilter.class
├── PropertiesLauncher$PrefixMatchingArchiveFilter.class
├── PropertiesLauncher$ArchiveEntryFilter.class
├── util/
└── WarLauncher.class
MANIFEST.MF结构:
Manifest-Version: 1.0 # 清单版本号
Start-Class: org.incoder.start.SpringbootStartApplication # 项目 main 方法所在的类
Spring-Boot-Classes: BOOT-INF/classes/ # 项目相关代码在打包后 jar 中的路径
Spring-Boot-Lib: BOOT-INF/lib/ # 项目中所依赖的第三方 jar 在打包后 jar 中的路径
Spring-Boot-Version: 2.1.6.RELEASE # 项目 SpringBoot 版本
Main-Class: org.springframework.boot.loader.JarLauncher # 当前 jar 文件的执行入口类(main 方法所在的类)
回车换行(在清单文件中,必须有,否则会出错)
再拓展一个知识,spring boot的启动流程:
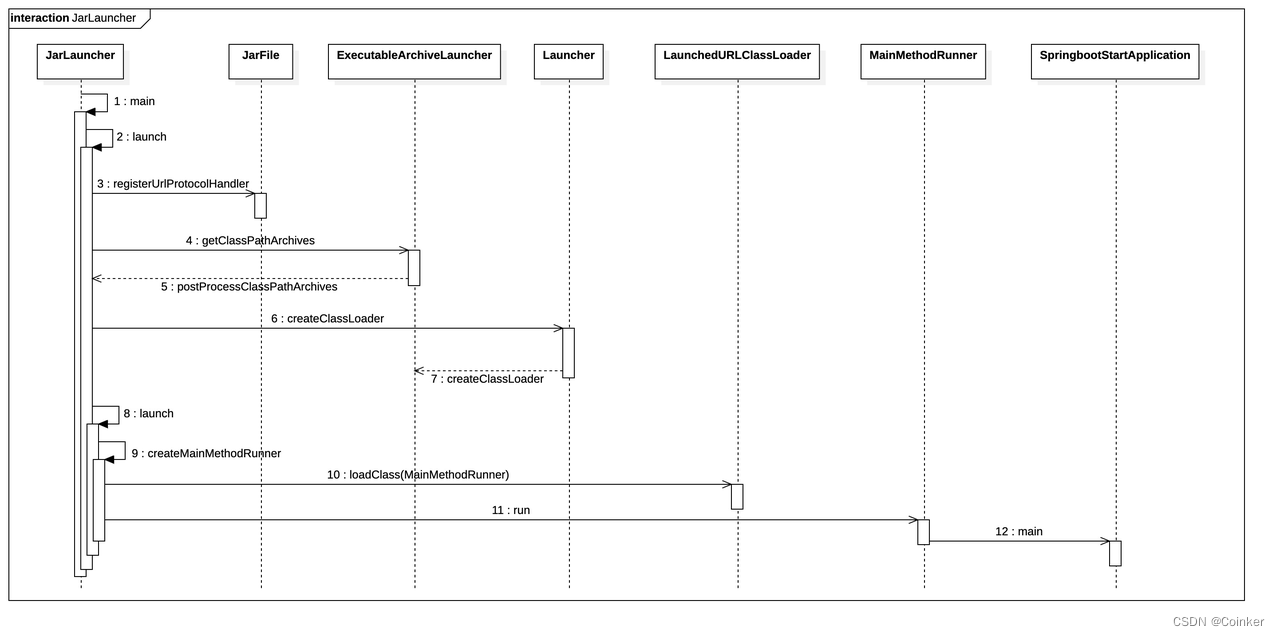
要知道我们平时启动一个普通的jar都是通过jdk自带的三种类加载器进行『双亲委派』加载的,
不同的内置classloader的scope 如下:
- Bootstrap ClassLoader(加载JDK的/lib目录下的类)
- Extension ClassLoader(加载JDK的/lib/ext目录下的类)
- Application ClassLoader(程序自己classpath下的类)
但是spring-boot为了适配fatjar结构,只能打破『双亲委派加载原则』,通过使用spring-boot自定义的类加载器加载我们的程序依赖的Jar包。
通过对比正常和异常的service.jar包解压后的文件,基本定位到该问题就是spring-boot-loader导致的了:
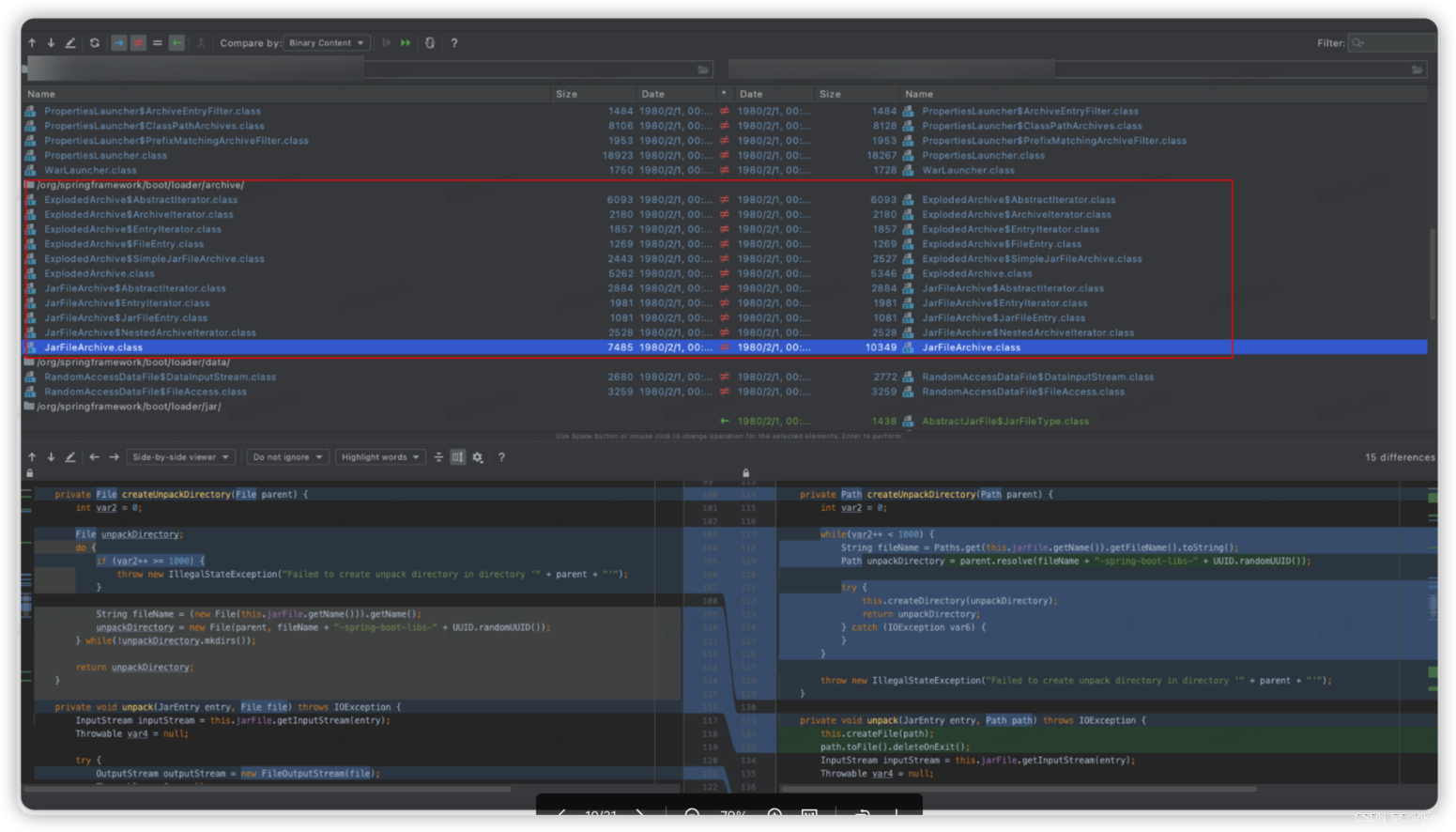
随后我下来了spring-boot的源码,通过对比spring-boot-loader的 2.3.2 和 2.3.4(这个版本正常)版本提交记录,发现了以下问题(可以在github 的issue中搜22991):
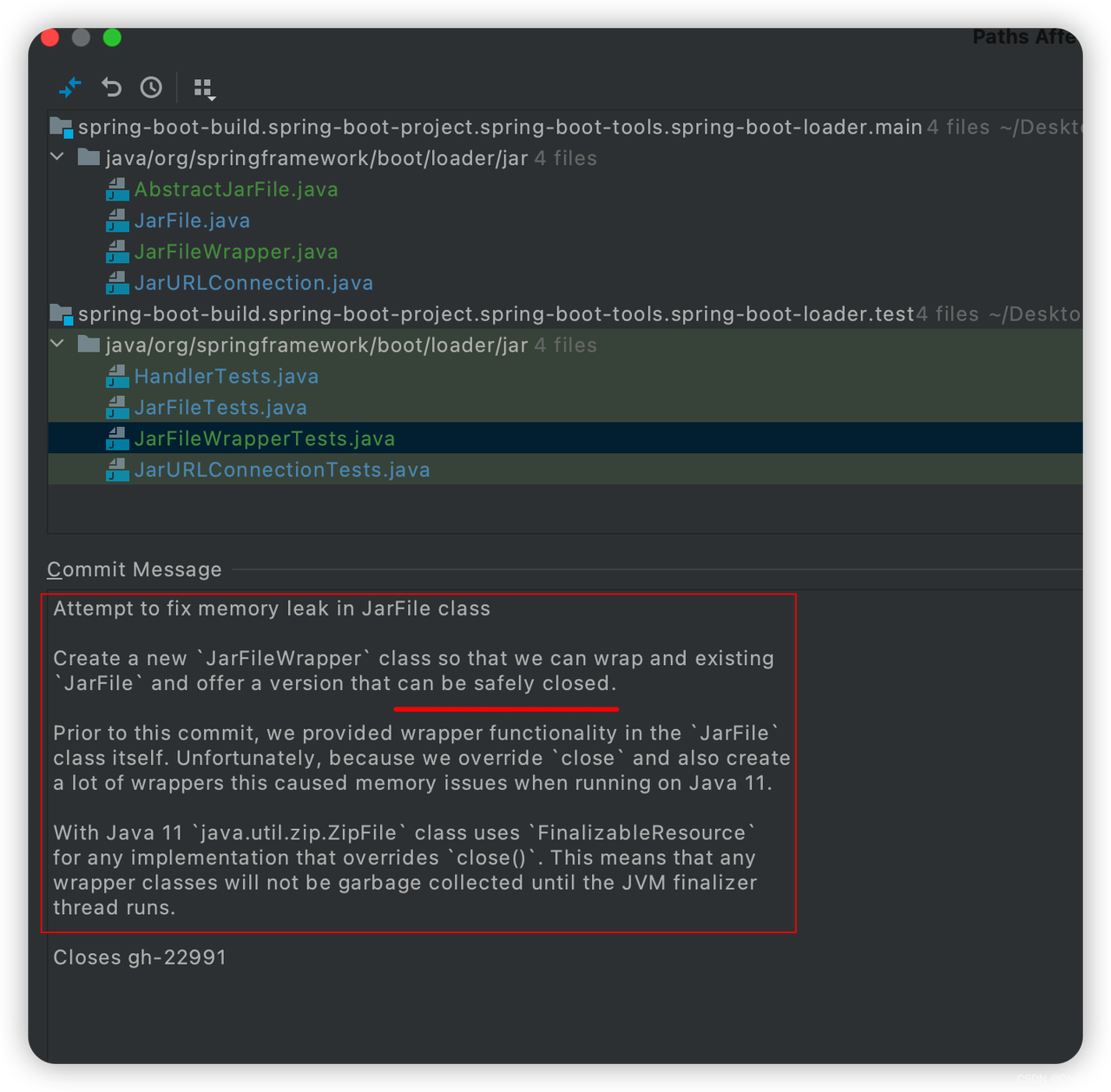
到这里基本确定是JarFile 内存泄露导致的了,且spring-boot在2.3.4版本进行了修复,但值得注意的是,在JDK 11中仍然会存在问题(还好我们用的是JDK8)。
但你以为到这里就分析结束了吗?作为一名程序员,一定要有刨根问底的不懈精神!
于是,我在本地进行了问题复现:
方式也很简单,在service服务中引入 spring-boot-loader源码,通过JarLauncher类启动spring-boot项目,然后模拟大量的请求发送,观察JVM状态,通过捕捉内存快照,果然复现了问题。


通过github的issue得知,是加载了不存在的类造成的内存泄露,那我们去查查哪些类没被加载到:
https://github.com/spring-projects/spring-boot/issues/28042

于是,顺着思路查一下哪些类没有被加载到:
通过,调试源码发现,spring-boot不会对类加载进行异常捕获,于是我手动加上一个try cache,运行。

果然发现了端倪:
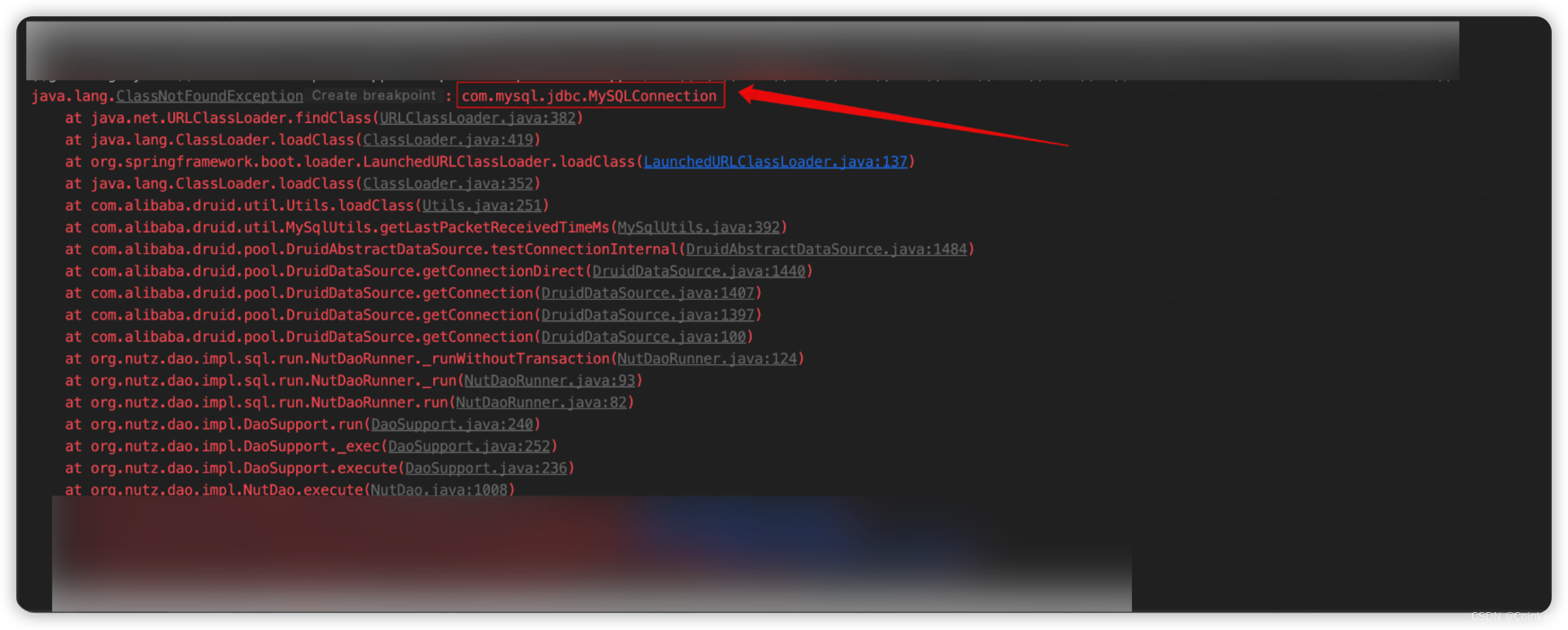
这个类是从阿里巴巴的druid连接池中调用的:
于是跟踪到druid的源代码,发现这里捕获了异常,但是又不打印异常,你说难受不难受,要我们都没发现有报错信息呢。
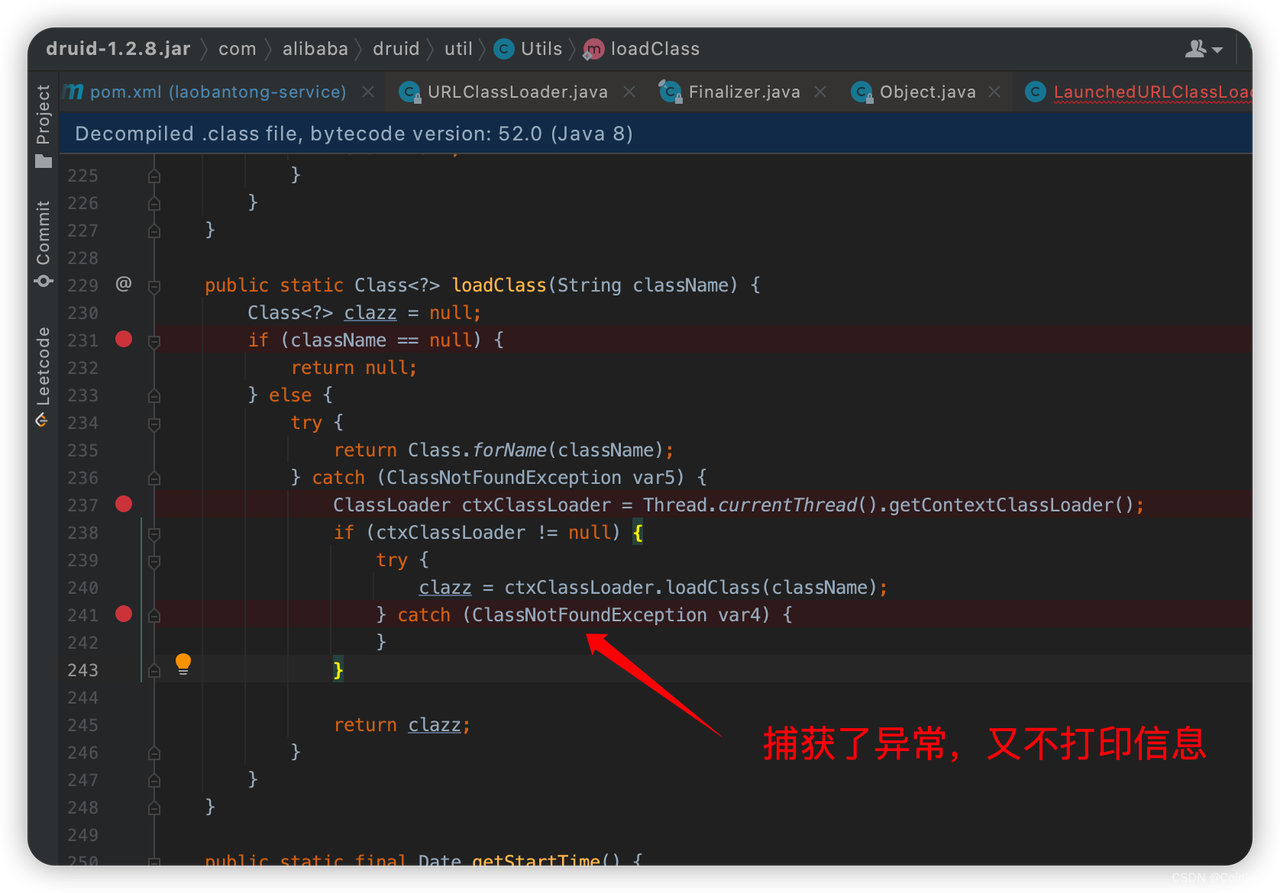
于是再往上跟踪,发现是这里调用的上述方法,这个方法是获取最后一个包发送的时间,用来判断是否需要断开与数据库的连接,为了适配不同的 MySQL 版本,这里先加载第一个类,如果加载不到就加载第二个类。
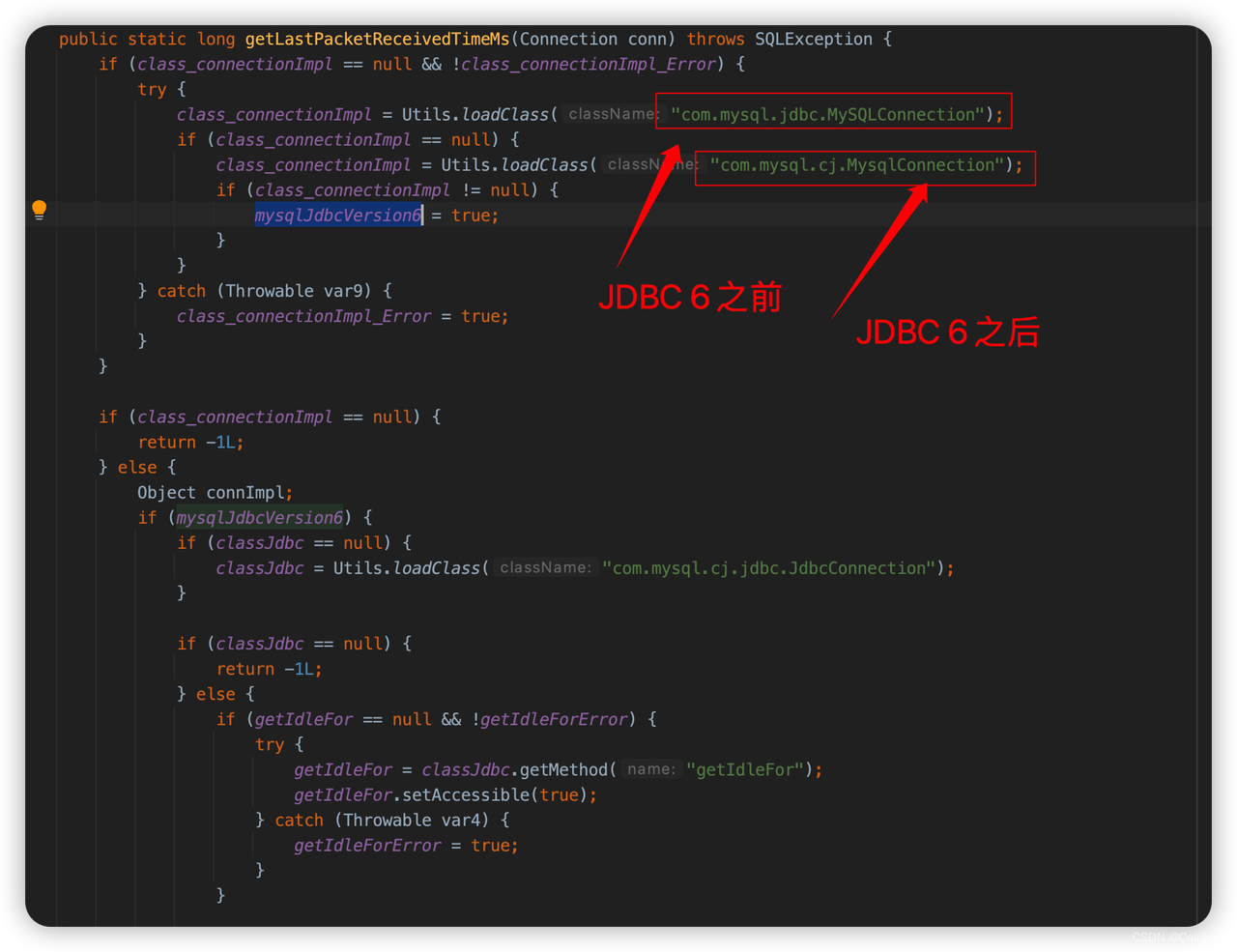
通过调试,我终于发现了这里的大坑:
我们的mysql驱动是6.0.3,理论上应该能找到第二个类并加载
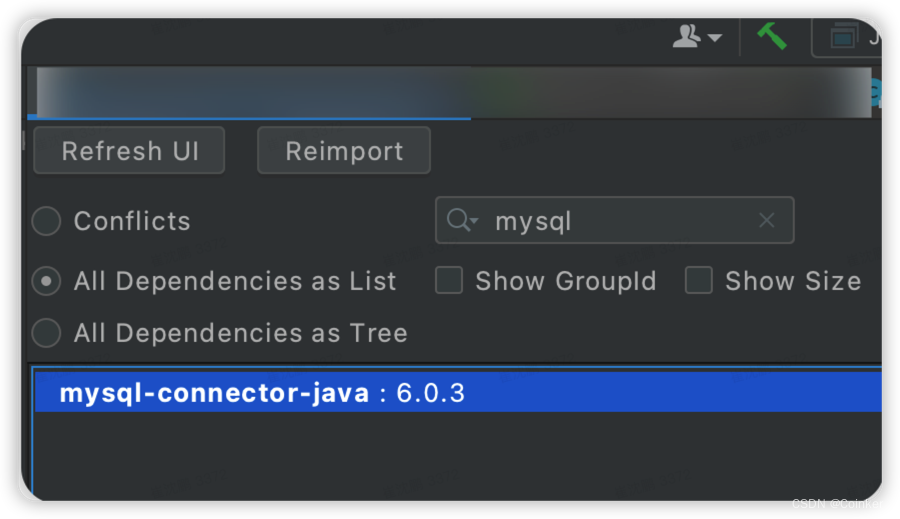
但是!
6.0.3驱动包中的MysqlConnection类名称确实正确,可是包路径却不一致。
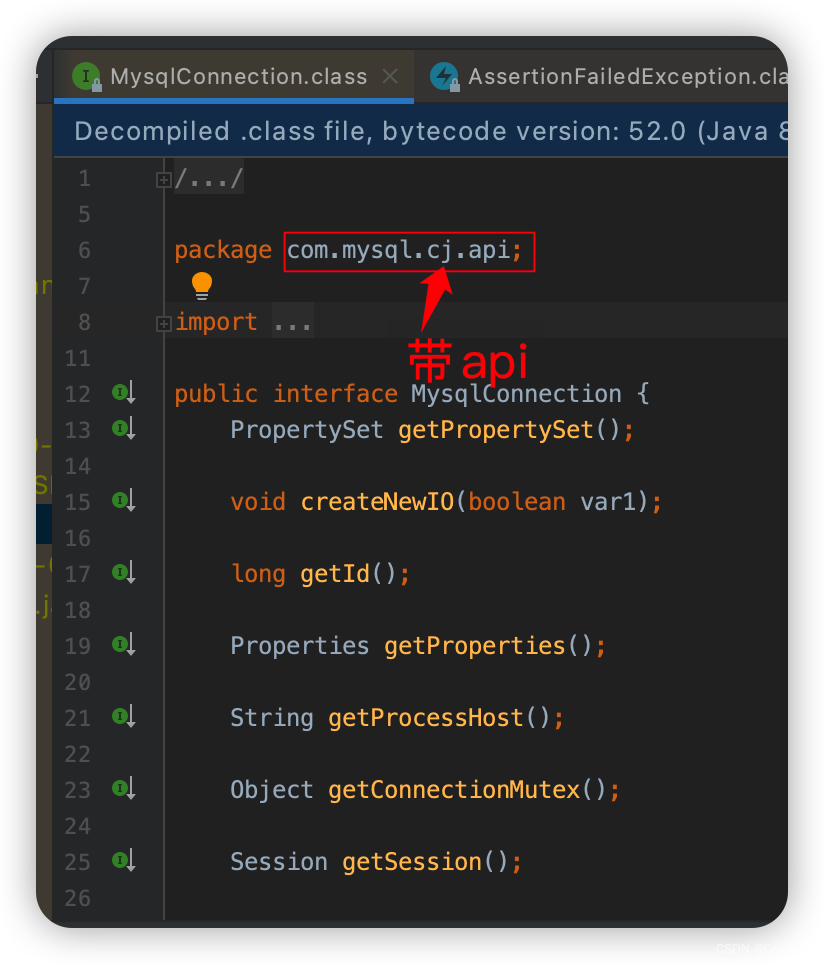
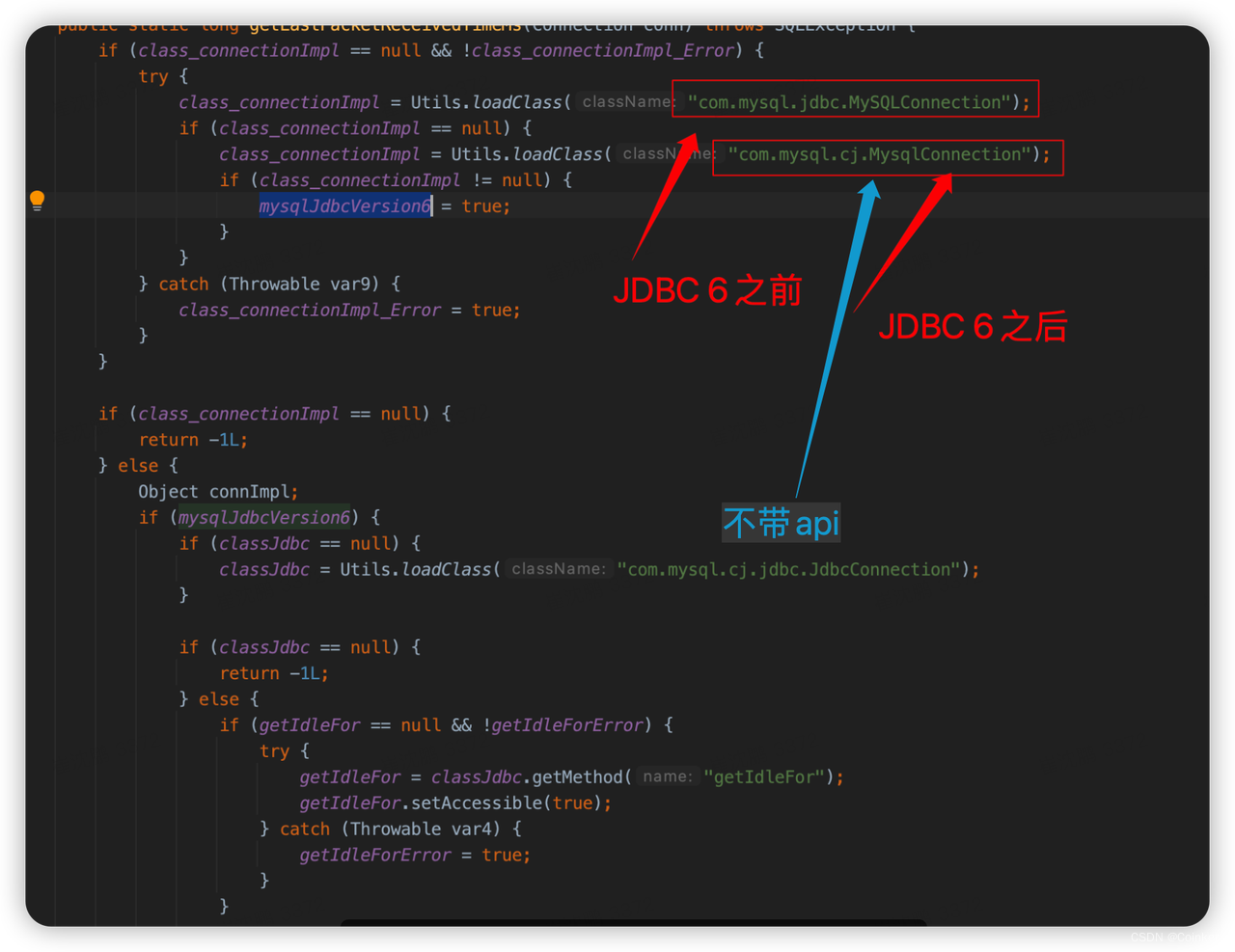
至此,终于定位到问题的根因,解决办法是把
MySQL驱动包升到8.0.21版本,同时把spring-boot-maven-plugin 升级到最新2.7.5
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.21</version>
</dependency>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>2.7.5</version>
<configuration>
<mainClass>com.hualala.report.HualalaReportServiceApplication</mainClass>
</configuration>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
至此,感谢运营和运维同学的及时提醒,感谢每个后端小伙伴的辛苦付出!
希望在今后的日子里,希望我们能慎重对待每一行代码!🎉🎉🎉🎉🎉