概述
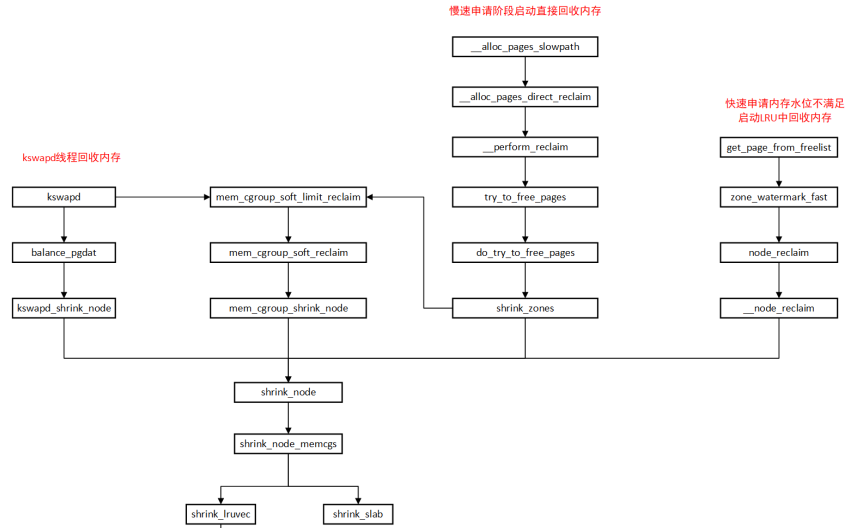
内存回收主要是有kswapd异步回收和direct reclaim同步回收两种入口,其中逻辑非常复杂,本文主要只概要描述不同回收场景下内核设计的主要思想,源码细节不同版本有不少区别,具体的分析后续会有专门的文章分析。
页面回收常识:
- 页面扫描回收时才意味着老化。
- 一个页面被访问之后,相应的access标记会一直打在那里,直到这个页面被扫描。LRU里面的时间流逝跟自然时间是没有关系的,扫描才是推动历史车轮前进的动力。而扫描又是由于达不到balanced而被触发的,可见页面老化的速度跟系统中内存的紧缺程度是相关的。内存紧缺的时候,1分钟前才被访问过的页面可能都不会被视作活跃;反过来,如果内存不紧缺,长期不需要进行回收,那么几小时前访问过的页面又可能都会被视作活跃,并且在这段时间内被访问过一次和被访问过多次的页面会被同等对待(access是标记而不是计数);
kswapd后台异步回收
1)何时唤起kswapd:
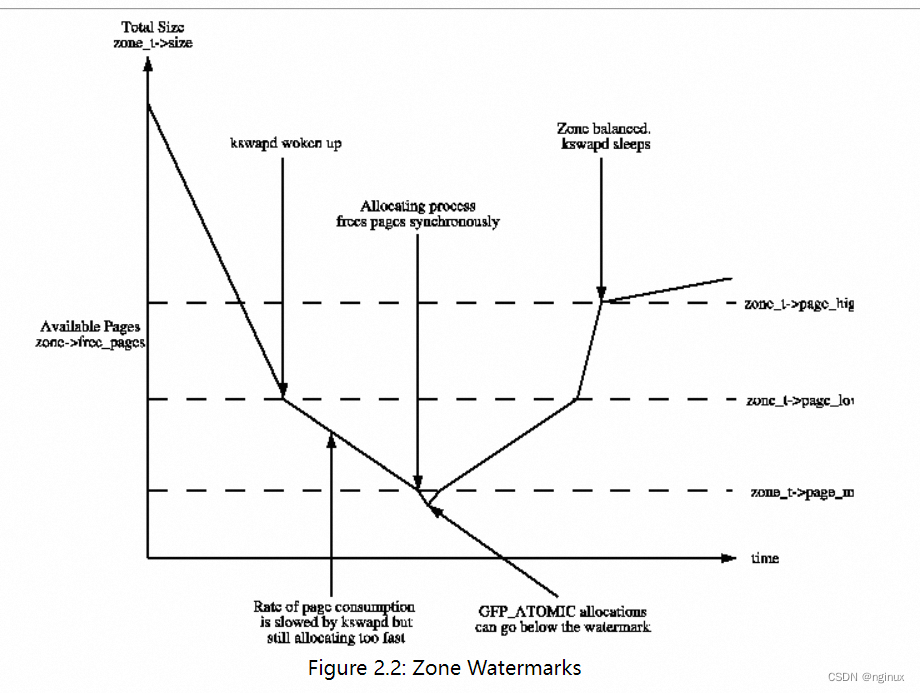
- 如果内存低于low watermark系统会唤醒kswapd进行内存回收
- alloc_page申请内存时候,先使用low watermark进行快速内存申请,如果失败了就会进入慢路径(也就是说free page < low),这个时候会主动wakeup kswapd,同时使用min watermark申请内存。
2)kswapd何时停止,回收(一个for循环)的频率如何
核心思路:既要高效回收page,又不能过度消耗CPU。
- 如上图kswapd如果判定pgdat_balanced(判定order和high watermark是否满足),那么就先进入“浅睡眠”(schdule_timeout(100)),避免马上陷入full sleep(TASK_INTERRUPTIBLE sleep),只能等到direct reclaim唤醒了,影响了内存分配性能,这里也可以看出kswapd的作用就是要尽量保持内存在high watermark,但是又要避免for(;;)过度循环导致cpu太高。
- 如果kswapd回收后满足pgdat_balanced陷入睡眠后,将wakeup_kcompactd,做内存compact。
- 如果kswapd一直回收而始终不满足pgdat_balanced,那么kswapd prepare_kswapd_sleep返回false,意味者kswapd不能休息要一直回收。
3)kswapd 回收page目标数量是多少?
- 目标:free page要满足high watermark;而kswapd又是从低于low watermark开始回收的,故源码设置sc.nr_to_reclaim尽量比较大能满足上述目标,如下:
for (z = 0; z <= sc->reclaim_idx; z++) {
zone = pgdat->node_zones + z;
if (!managed_zone(zone))
continue;
//high_wmark_pages返回的high watermark值
sc->nr_to_reclaim += max(high_wmark_pages(zone), SWAP_CLUSTER_MAX);
}注意:虽然kswapd的sc.nr_to_reclaim虽然设置的回收目标挺大的,但是真正执行shrink回收页面的时候(实际上指shrink_list)一次回收的单位最大是SWAP_CLUSTER_MAX(32)个pages。
4)kswapd回收的方向(zone)和 order?
- kswapd回收方向和alloc_pages方向相关尽力避免锁竞争。
- alloc_pages方向是从high zone-> low zone;kswapd反之
- kswapd会从alloc_pages拿到目标zone(prefered zone)和order,然后按zone 0 -> prefered zone顺序回收(比如prefered zone是1,那么只回收0 - 1zone,不要浪费时间去收回zone 2)
- 上面大概提到判定zone是否平衡的条件有考虑order,可参见源码pgdat_balanced函数,平衡不仅仅是要free pages > high watermark,同时至少要有2^order连续的物理内存才可。
5)kswapd's scan control priority优先级设置
- kswapd开始以DEF_PRIORITY(12)的优先级开始扫描
- 调用函数balance_pgdat在do{}循环中进行回收,如果一轮循环回收后没有balance,那就不断将priority提升,增加一轮scan page数量;如果priority最高后还没有balance,根据watermark_boots情况可以看是否wakeup_kcompactd。
direct reclaim
- 快速路径申请:
- 以ALLOC_WMARK_LOW申请内存,zone水位不满足条件(即free pages < low),node_reclaim触发回收,此过程不能够引入I/O开销,因此不能对mapped anonymous page或者脏文件页回写操作,主要针对的是unmapped file pages和 slab pages,上述类型的内存页可直接被回收:
static int __node_reclaim(struct pglist_data *pgdat, gfp_t gfp_mask, unsigned int order)
{
...
struct scan_control sc = {
.nr_to_reclaim = max(nr_pages, SWAP_CLUSTER_MAX),
.gfp_mask = current_gfp_context(gfp_mask),
.order = order,
.priority = NODE_RECLAIM_PRIORITY,
.may_writepage = !!(node_reclaim_mode & RECLAIM_WRITE),
.may_unmap = !!(node_reclaim_mode & RECLAIM_UNMAP),
.may_swap = 1,
.reclaim_idx = gfp_zone(gfp_mask),
};
...
}my_writepage = 0:代表不能进行页面回写落盘
my_unmap = 0 : 不能进行try_to_unmap(page)等unmap解除页表映射。
may_swap = 1;可以进行页面swap操作,android上比如可以机型zram匿名页压缩。
priority : 回收优先级是4,即最多尝试调用shrink_node进行回收的次数为4次,或者当回收到的页数达到需要分配的内存页数停止。
nr_to_reclaim:请求分配页面和SWAP_CLUSTER_MAX的最大值,即最少也要扫描32个page,否则一次shrink性价比太低了。
慢路径申请:
如果快速路径回收页面后依旧分配内存失败,则会进入到慢速分配路径,慢速分配会尝试从所有zone中以WMARK_MIN阀值分配内存页。在慢速分配路径中,会再次尝试快速路径回收,未成功则调用__alloc_pages_direct_reclaim进行内存回收。允许mapped anonymous page回收,且如果laptop_mode不为真,则允许脏文件页写回。laptop_mode通过/proc/sys/vm/laptop_mode控制,为0允许直接内存回收对脏页进行回写操作。try_to_free_pages每次回收页面最大值为32(SWAP_CLUSTER_MAX),priority为12,shrink_node最多会被调用12次。
unsigned long try_to_free_pages(struct zonelist *zonelist, int order,
gfp_t gfp_mask, nodemask_t *nodemask)
{
unsigned long nr_reclaimed;
struct scan_control sc = {
.nr_to_reclaim = SWAP_CLUSTER_MAX,
.gfp_mask = current_gfp_context(gfp_mask),
.reclaim_idx = gfp_zone(gfp_mask),
.order = order,
.nodemask = nodemask,
.priority = DEF_PRIORITY,
.may_writepage = !laptop_mode,
.may_unmap = 1,
.may_swap = 1,
};
调用栈:
#0 shrink_node (pgdat=0xffff888007fda000, sc=0xffff888005767450) at mm/vmscan.c:2672
#1 0xffffffff81356a4a in shrink_zones (sc=<optimized out>, zonelist=<optimized out>) at mm/vmscan.c:2971
#2 do_try_to_free_pages (zonelist=<optimized out>, sc=0xffff888005767450) at mm/vmscan.c:3026
#3 0xffffffff81358cec in try_to_free_pages (zonelist=0xffff888007fdb400, order=0, gfp_mask=<optimized out>, nodemask=<optimized out>) at mm/vmscan.c:3265
#4 0xffffffff813bcd27 in __perform_reclaim (ac=<optimized out>, ac=<optimized out>, order=<optimized out>, gfp_mask=<optimized out>) at mm/page_alloc.c:4274
#5 __alloc_pages_direct_reclaim (did_some_progress=<optimized out>, ac=<optimized out>, alloc_flags=<optimized out>, order=<optimized out>, gfp_mask=<optimized out>) at mm/page_alloc.c:4295
#6 __alloc_pages_slowpath (gfp_mask=<optimized out>, order=<optimized out>, ac=0x0 <fixed_percpu_data>) at mm/page_alloc.c:4699
#7 0xffffffff813bdf9d in __alloc_pages_nodemask (gfp_mask=1125578, order=0, preferred_nid=<optimized out>, nodemask=<optimized out>) at mm/page_alloc.c:4915
#8 0xffffffff813e0637 in alloc_pages_current (gfp=1125578, order=0) at ./include/linux/topology.h:88
#9 0xffffffff8132b0b5 in alloc_pages (order=<optimized out>, gfp_mask=<optimized out>) at ./include/linux/gfp.h:545
#10 __page_cache_alloc (gfp=<optimized out>) at mm/filemap.c:957
#11 __page_cache_alloc (gfp=1125578) at mm/filemap.c:942
具体回收的过程以及判定哪些页面怎么处理的细节后面文章分析。
思考问题:
现在内核如果kswapd回收,但是一直无法balance,没有措施确保kswapd能歇一歇?会不会造成cpu浪费?