文章目录
- 主键生成策略介绍
- AUTO策略
- INPUT策略
- ASSIGN_ID策略
- ASSIGN_UUID策略
- NONE策略
- MybatisPlus分页
- 分页插件
- 自定义分页插件
- ActiveRecord模式
- SimpleQuery工具类
- SimpleQuery介绍
- list
- map
- Group
主键生成策略介绍
- 主键:在数据库中,主键通常用于快速查找和访问数据。主键是数据库表中的一列或一组列,用于唯一标识表中的每一行数据。主键必须具有唯一性,而且主键值不能为NULL。主键可以用来确保数据的完整性和一致性,还可以用于建立表之间的关系。
- 在MybatisPlus中提供了一个注解,是
@TableId,该注解提供了各种的主键生成策略,通过使用该注解来对于新增的数据指定主键生成策略。在新增数据的时候,数据就会按照指定的主键生成策略来生成对应的主键。
AUTO策略
- 该策略为跟随数据库表的主键递增策略
- 当使用AUTO策略(自动递增)来生成主键值时,数据库主键的类型应设置为整数类型(如INT、BIGINT等),以便能够自动递增并确保唯一性。这是因为自动递增主键会自动为每个新插入的行生成一个唯一的整数值,而整数类型可以更有效地存储和处理这些值。
- 前提是数据库表的主键要设置为自增,此处要设置好下次递增的数字
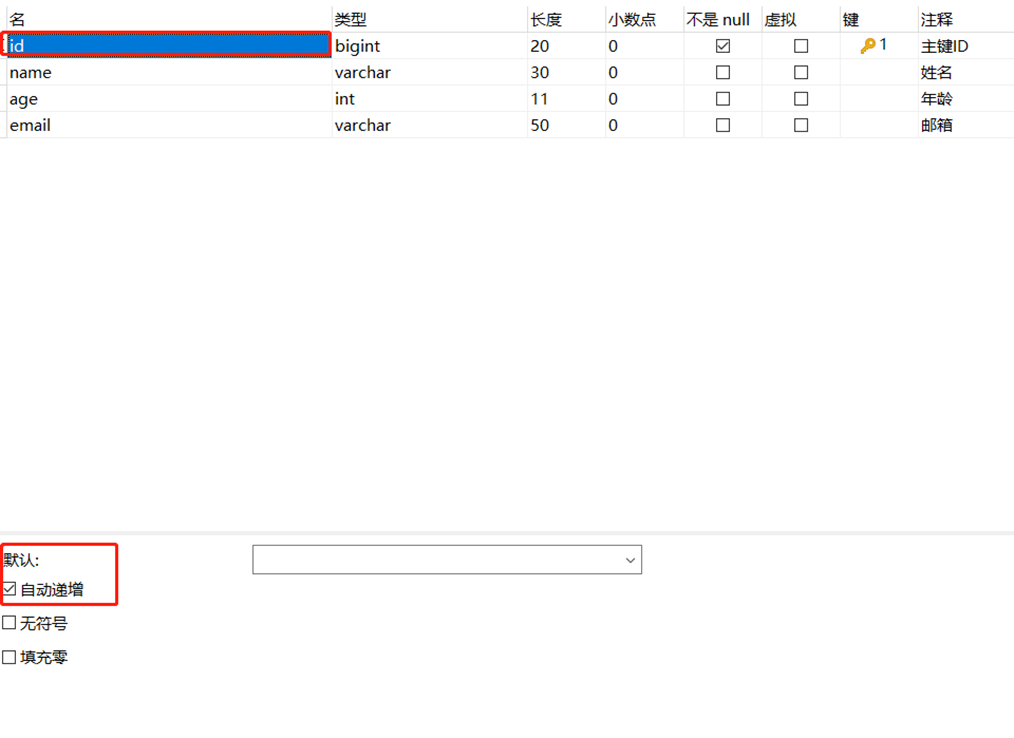
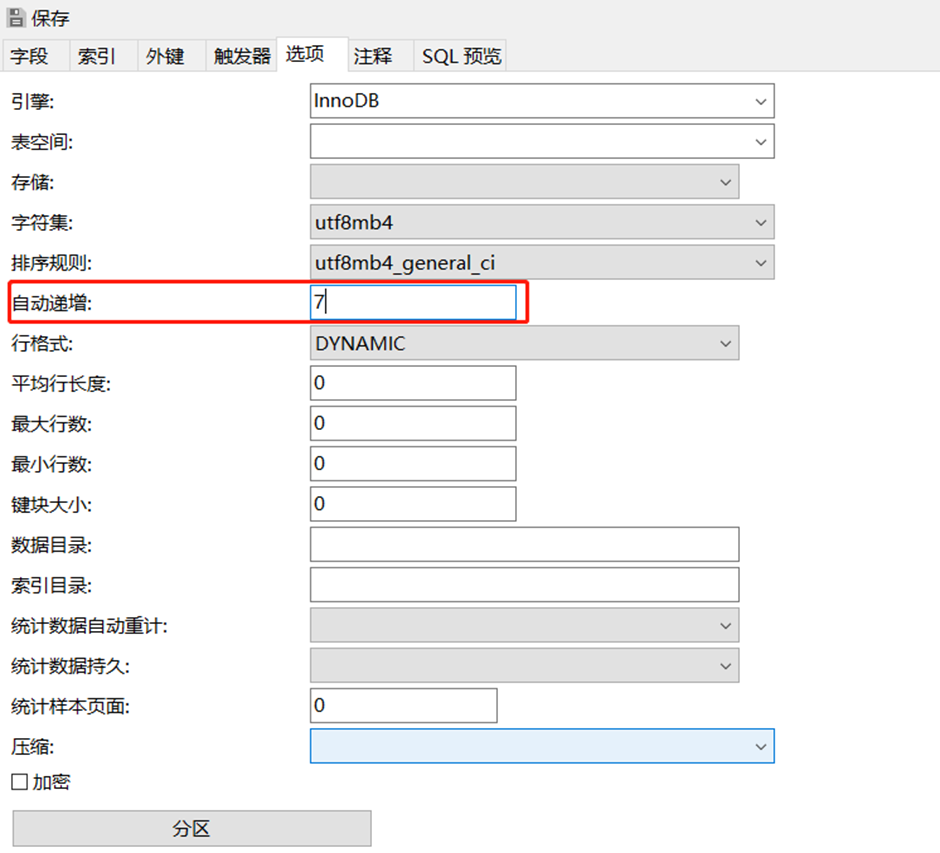
- 实体类添加注解,指定主键生成策略
@TableId(type = IdType.AUTO)
private Long id;
INPUT策略
- 对于INPUT策略,数据库主键的类型可以是任何合适的数据类型,根据具体的需求来确定。
- INPUT策略意味着主键的值是由用户手动输入或提供的,而不是由数据库自动生成。因此,主键可以是任何合法的数据类型,如整数、字符串、日期等,取决于业务需求和数据的特性。需要注意的是,需要确保主键的值在表中是唯一的,以维护数据的完整性和一致性。
@TableId(type = IdType.INPUT)
private Long id;
ASSIGN_ID策略
- ASSIGN_ID策略是一种手动分配主键值的策略。主键的类型可以是任何合适的数据类型,根据具体的需求来确定。
- 如果不设置类型值,默认则使用
IdType.ASSIGN_ID策略(自 3.3.0 3.3.0 3.3.0起)。该策略会使用雪花算法自动生成主键ID,主键类型为长或字符串(分别对应的MySQL的表字段为BIGINT和VARCHAR) - 需要注意的是,需要确保主键的值在表中是唯一的,以维护数据的完整性和一致性。
- 雪花算法是由一个64位的二进制组成的,最终就是一个Long类型的数值。主要分为四部分存储:
- 位的符号位,固定值为0
- 41位的时间戳
- 10位的机器码,包含5位机器id和5位服务id
- 12位的序列号

@TableId(type = IdType.ASSIGN_ID)
private Long id;
ASSIGN_UUID策略
- UUID(Universally Unique Identifier)全局唯一标识符,定义为一个字符串主键,采用32位数字组成,编码采用16进制,定义了在时间和空间都完全唯一的系统信息。
- UUID的编码规则:
- 1~8位采用系统时间,在系统时间上精确到毫秒级保证时间上的唯一性;
- 9~16位采用底层的IP地址,在服务器集群中的唯一性;
- 17~24位采用当前对象的HashCode值,在一个内部对象上的唯一性;
- 25~32位采用调用方法的一个随机数,在一个对象内的毫秒级的唯一性。
- 使用UUID作为MySQL主键时,主键类型应选择
VARCHAR类型。UUID是一个36位的字符串,由32位的十六进制数字和4个连字符组成。因此,需要使用VARCHAR(36)来存储UUID。
@TableId(type = IdType.ASSIGN_UUID)
private String id;
NONE策略
- NONE策略表示不指定主键生成策略,当我们没有指定主键生成策略或者主键策略为NONE的时候,跟随的是全局策略。全局默认配置
id-type使用的是雪花算法。
@TableId(type = IdType.NONE)
private Long id;
MybatisPlus分页
分页插件
-
分页的本质就是需要设置一个拦截器,通过拦截器拦截了SQL,通过在SQL语句的结尾添加limit关键字,来实现分页的效果。
-
配置的步骤
- 通过配置类来指定一个具体数据库的分页插件,因为不同的数据库的方言不同,具体生成的分页语句也会不同。
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}
- 实现分页查询效果
@Test
void selectPage(){
//1.创建QueryWrapper对象
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
//2.创建分页查询对象,指定当前页和每页显示条数
IPage<User> page = new Page<>(1,3);
//3.执行分页查询
userMapper.selectPage(page, lambdaQueryWrapper);
//4.查看分页查询的结果
System.out.println("当前页码值:"+page.getCurrent());
System.out.println("每页显示数:"+page.getSize());
System.out.println("总页数:"+page.getPages());
System.out.println("总条数:"+page.getTotal());
System.out.println("当前页数据:"+page.getRecords());
}
- 查询语句查看
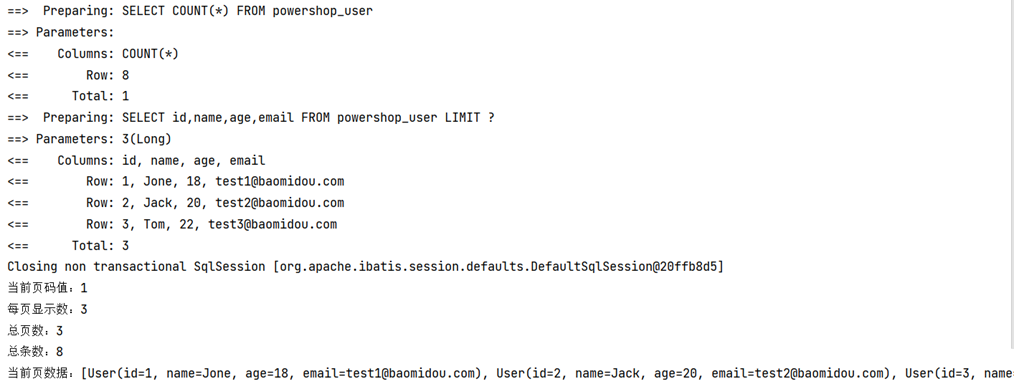
自定义分页插件
在某些场景下,需要自定义SQL语句来进行查询。接下来演示一下自定义SQL的分页操作
- 在
UserMapper.xml映射配置文件中提供查询语句
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.powernode.mapper.UserMapper">
<select id="selectByName" resultType="com.powernode.domain.User">
select * from powershop_user where name = #{name}
</select>
</mapper>
- 在
Mapper接口中提供对应的方法,方法中将IPage对象作为参数传入
@Mapper
public interface UserMapper extends BaseMapper<User> {
IPage<User> selectByName(IPage<User> page, String name);
}
- 实现分页查询效果
@Test
void selectPage2(){
//1.创建分页查询对象,指定当前页和每页显示条数
IPage<User> page = new Page<>(1,2);
//2.执行分页查询
userMapper.selectByName(page,"Mary");
//3.查看分页查询的结果
System.out.println("当前页码值:"+page.getCurrent());
System.out.println("每页显示数:"+page.getSize());
System.out.println("总页数:"+page.getPages());
System.out.println("总条数:"+page.getTotal());
System.out.println("当前页数据:"+page.getRecords());
}
ActiveRecord模式
- ActiveRecord(活动记录,简称AR),是一种领域模型模式,特点是一个模型类对应关系型数据库中的一个表,而模型类的一个实例对应表中的一行记录。
- ActiveRecord 一直广受解释型动态语言( PHP 、 Ruby 等)的喜爱,通过围绕一个数据对象进行CRUD操作。而 Java 作为准静态(编译型)语言,对于 ActiveRecord 往往只能感叹其优雅,所以 MP 也在 AR 道路上进行了一定的探索,仅仅需要让实体类继承 Model 类且实现主键指定方法,即可开启 AR 之旅。
- 实现步骤
- 让实体类继承Model类
@Data @AllArgsConstructor @NoArgsConstructor public class User extends Model<User> { private Long id; private String name; private Integer age; private String email; }- Model类中提供了一些增删改查方法,可以直接使用实体类对象调用这些增删改查方法,简化了操作的语法,但底层依然是需要UserMapper,所以持久层接口并不能省略
- 测试ActiveRecord模式的增删改查
- 添加数据
@Test void activeRecordAdd(){ User user = new User(); user.setName("wang"); user.setAge(35); user.setEmail("wang@powernode.com"); user.insert(); }- 删除数据
@Test void activeRecordDelete(){ User user = new User(); user.setId(8L); user.deleteById(); }- 修改数据
@Test void activeRecordUpdate(){ User user = new User(); user.setId(6L); user.setAge(50); user.updateById(); }- 查询数据
@Test void activeRecordSelect(){ User user = new User(); user.setId(6L); User result = user.selectById(); System.out.println(result); }
SimpleQuery工具类
SimpleQuery介绍
- SimpleQuery可以对selectList查询后的结果用Stream流进行了一些封装,使其可以返回一些指定结果,简洁了api的调用
list
- 演示基于字段封装集合
@Test
void testList(){
//.list()方法执行查询,并返回符合条件的用户列表
//使用.list(User::getId)来指定返回的字段为ID
List<Long> ids = SimpleQuery.list(new LambdaQueryWrapper<User>().eq(User::getName, "Mary"), User::getId);
System.out.println(ids);
}
- 演示对于封装后的字段进行lambda操作
@Test
void testList2(){
/* e -> Optional.of(e.getName()).map(String::toLowerCase).ifPresent(e::setName)
额外的逻辑处理,即对返回的姓名进行转换
Optional.of(e.getName())用于将姓名转换为Optional对象,以便进行后续的操作。
接着,.map(String::toLowerCase)将姓名转换为小写形式。最后,.ifPresent(e::setName)将转换后的小写姓名设置回User对象的姓名属性。
*/
List<String> names = SimpleQuery.list(new LambdaQueryWrapper<User>().eq(User::getName, "Mary"),User::getName,e -> Optional.of(e.getName()).map(String::toLowerCase).ifPresent(e::setName));
System.out.println(names);
}
map
- 演示将所有的对象以id,实体的方式封装为Map集合
@Test
void testMap(){
//将所有元素封装为Map形式
Map<Long, User> idEntityMap = SimpleQuery.keyMap(new LambdaQueryWrapper<>(), User::getId);
System.out.println(idEntityMap);
}
- 演示将单个对象以id,实体的方式封装为Map集合
@Test
void testMap2(){
//将单个元素封装为Map形式
Map<Long, User> idEntityMap = SimpleQuery.keyMap(
new LambdaQueryWrapper<User>().eq(User::getId,1L), User::getId);
System.out.println(idEntityMap);
}
- 演示只想要id和name组成的map
@Test
void testMap3(){
//只想要只想要id和name组成的map
Map<Long, String> idNameMap = SimpleQuery.map(new LambdaQueryWrapper<>(), User::getId, User::getName);
System.out.println(idNameMap);
}
Group
- 演示分组效果
@Test
void testGroup(){
Map<String, List<User>> nameUsersMap = SimpleQuery.group(new LambdaQueryWrapper<>(), User::getName);
System.out.println(nameUsersMap);
}

![c++学习(c++11)[24]](https://img-blog.csdnimg.cn/1531e1227c704464a0d385f1a3af204b.png)