编者按:如今,机器学习已成为人类未来发展的焦点领域,如何进一步拓展机器学习技术和理论的边界,是一个极富挑战性的重要话题。7月23日至29日,第四十届国际机器学习大会 ICML 2023 在美国夏威夷举行。该大会是由国际机器学习学会(IMLS)主办的年度机器学习国际顶级学术会议,旨在推动机器学习领域的学术进步。在 ICML 2023 上,微软亚洲研究院的研究员们有多篇论文入选,今天我们将为大家简要介绍其中的5篇。
回路神经网络:一种实现多种神经回路模式的通用神经网络

论文链接:https://openreview.net/pdf?id=Fl9q5z40e3
近年来,人工神经网络(Artificial Neural Network, ANN)在多个领域取得了巨大的成功,这在一定程度上归功于其对人脑结构的模仿。然而,最近的神经科学进展揭示,神经元之间实际上是通过多种多样的连接模式相互交互来处理信息的,这些连接模式有时也被称作回路模式(Circuit Motifs)。但许多现有的人工神经网络只能在其架构中模拟一种或两种回路模式。例如,前馈神经网络很好地模拟了前馈回路模式,循环神经网络模拟了神经元相互连接成环的模式。这种对于不同结构的模拟差异导致了它们在不同类型的机器学习任务中会存在性能差异。
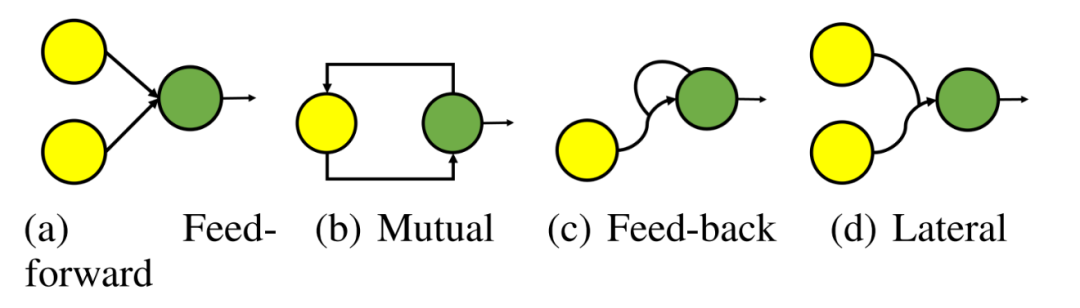
图1:神经元之间的不同回路模式,绿色的神经元通过黄色神经元传入的信号更新自身的状态。从左往右,四种模式分别是前馈模式,环路模式,反馈模式和横向模式
在这篇论文中,研究员们提出了一种新型的神经网络——回路神经网络(CircuitNet),其灵感来源于对大脑神经回路结构的模拟。在 CircuitNet 中,一组密集连接的神经元——回路模式单元(CMU),形成了网络的基本单元。研究员们在 CMU 中引入神经元之间的注意力机制或者高次次项,再调整 CMU 内部的权重,这些基础单元就能够模拟更加通用的回路模式。与传统的前馈网络相比,CircuitNet 具有模拟更多类型神经元连接的能力,如反馈和横向模式。
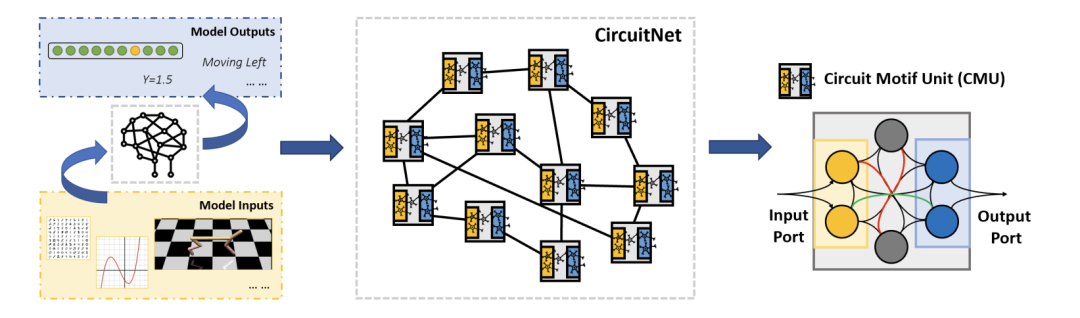
图2:CircuitNet 的模型结构。作为一个通用的神经网络,CircuitNet 可以根据输入的形式用在各种各样的下游任务中(左)。CircuitNet 由一些 CMU 通过相互间的稀疏连接构成 (中)。在单个 CMU 中,神经元间以复杂的形式稠密连接在一起从而建模通用的回路模式,例如,绿色的线连接了两个神经元,可以用来表示线性变换,而红线可以表示更高级的涉及三个神经元的变换,如神经元间的注意力机制(右)
另外,受到人脑局部密集和全局稀疏结构的启发,不同 CMU 之间通过输入端口和输出端口的稀疏连接实现了多次信号传递。
实验证明,CircuitNet 在函数逼近、强化学习、图像分类和时间序列预测等任务中均优于流行的神经网络架构。CircuitNet 不仅提供了更好的性能和灵活性,还为解决复杂的机器学习任务和认知模型奠定了坚实的基础。
带概率激发臂的上下文组合多臂老虎机问题

论文链接:https://arxiv.org/abs/2303.17110
将传统的组合优化和在线学习相结合的组合多臂老虎机(combinatorial multi-armed bandit)是通过在线反馈机制来不断改进模型优化效果的。本文提出了一种新的上下文组合多臂老虎机模型 C^2MAB-T,它结合了上下文信息和概率激活模型,并基于简单而有效的线性结构假设,实现了更好的可扩展性。该模型适用于大规模推荐系统、在线广告、社交网络、无线网络等多个领域。
针对 C^2MAB-T,研究员们在多种光滑条件下设计了相应的算法并进行了理论分析。在概率激活调节(TPM)条件下,研究员们提出了 C^2-UCB-T 算法,消除了潜在的指数级大因子 1/p 对算法性能的影响,其中p表示的是任何臂被触发的最小正概率。在概率激活方差调节(TPVM)条件下,研究员们进一步提出了 VAC^2-UCB 算法,实现了每个时刻激活的臂数K对算法性能影响的更好控制,使其从 O(K) 降低为 O(log K)。需要注意的是,文中的分析技术和方差自适应算法也同样适用于 CMAB-T 和 C^2MAB,并且改进了现有算法的结果。
C^2MAB-T 模型通过仿真实验在推荐系统场景中验证了算法的性能。相较于两组现有算法,C^2MAB-T 的算法分别获得了25%和45%的性能提升。
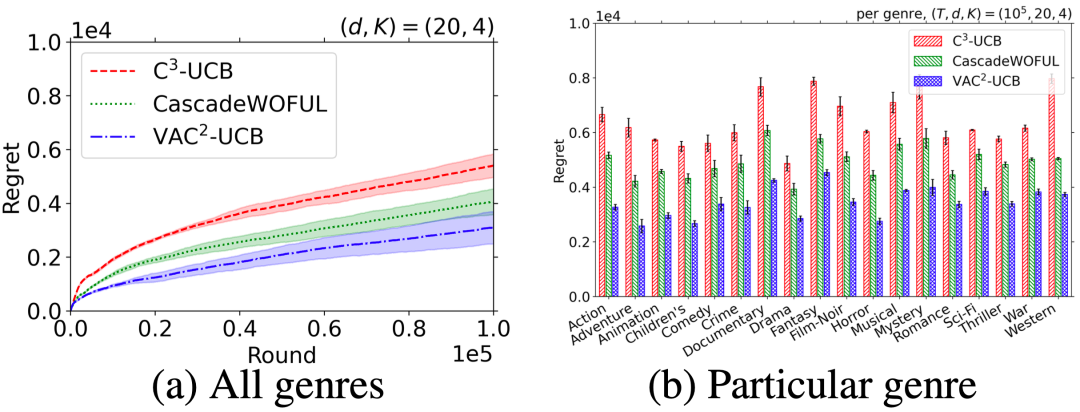
图3:基于 MovieLens-1M 数据集的实验表明,VAC^2-UCB(蓝色)在性能上超过了 C^3-UCB [Li et al., ICML'16](红色)和另一个方差感知算法 CascadeWOFUL [Vial et al., NeurIPS'22(绿色)],分别减少了45%和25%算法损失(regret)。
Magneto:一种基础的Transformer模型架构

论文链接:https://openreview.net/pdf?id=oeAhgeKFEw
近年来,人们陆续见证了语言、视觉、语音以及多模态等领域中模型架构的大融合。从自然语言处理开始,Transformers 已经广泛作为视觉、语音以及多模态在内的各领域骨干网络。然而,尽管都使用同样的名字“Transformers”,但它们的实现在不同任务中存在着显著差异。在多模态模型的预训练中,对于不同的输入模态,最优的 Transformer 变体通常是不同的。图4总结了在各任务上广泛使用的先进模型的架构。视觉预训练往往使用 Pre-LayerNorm 的 Transformers,而掩码语言建模和机器翻译则使用 Post-LayerNorm 以取得更好的性能。以视觉-语言预训练为例,对于视觉编码来说,使用 Post-LayerNorm 是次优的,而对于语言任务来说,使用 Pre-LayerNorm 则是次优的。真正的多模态预训练需要一个在各种任务和模态下都能表现良好的统一架构。另外,大规模 Transformer 模型训练难、易崩溃,需要付出巨大的成本来调整超参数或监督模型的训练过程。

图4:微软亚洲研究院的研究员们提出的 Magneto 在语言、语音、视觉和多模态任务上比之前最先进的骨干网表现更好。
由此,微软亚洲研究院的研究员们呼吁发展“Foundation Transformers”以实现真正的通用建模,进而提出了 Magneto。图5展示了 Magneto 的伪代码和不同架构下的示意图。可以看到,Magneto 引入了 Sub-LayerNorm,并在每个子层中增加了一个额外的层归一化来减缓预训练中遭遇的激活爆炸。此外,研究员们还拓展了 DeepNet 对于训练稳定性的分析框架,为 Magneto 提出了一种新的初始化方法,从理论上保证深层模型训练的稳定,使得 Magneto 可以无痛地进行扩展。
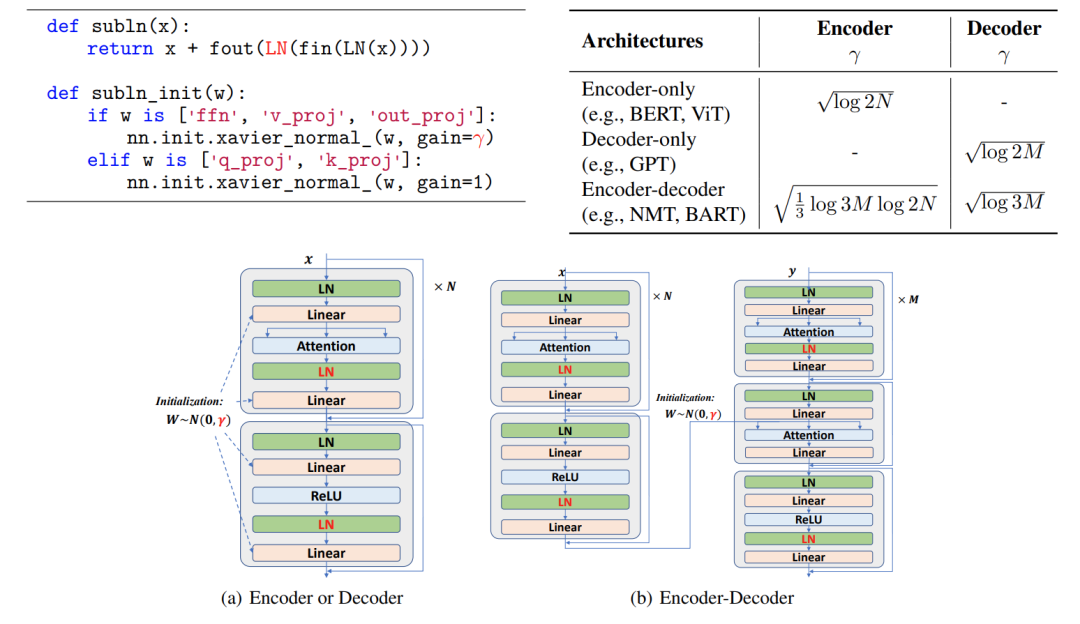
图5:左上:Sub-LN 的伪代码。这里以 Xavier 初始化为例,可以用其他标准初始化方法替代。γ 是一个常数。右上:不同架构(N 层编码器,M 层解码器)的 γ 值。底部:不同架构下的 Sub-LN。
研究员们在广泛的任务和模态上评估了 Magneto 的性能,包括掩码语言建模(BERT)、因果语言建模(GPT)、机器翻译、掩码图像建模(BEiT)、语音识别和视觉-语言预训练(BEiT-3)。图4展示了 Magneto 在各种下游任务上显著优于现有分别设计的 Transformer 变体。而且,Magneto 在优化方面更稳定,这就使得以更高的学习率来提升下游任务性能的表现成为可能,同时不会导致训练崩溃。
环境干扰下的鲁棒情境强化学习

论文链接:https://openreview.net/pdf?id=hGJLN2Ys4c
在很多实际的任务中,动态变化且不可控制的环境因子对决策过程起着重要作用,比如库存管理中的顾客需求量和自动驾驶中的前车速度,这类环境因子被为上下文(context)。强化学习在这类应用中的主要挑战之一在于,真实的上下文转移分布会暴露于某些因素的干扰下,导致上下文的转移分布发生偏移,极大地影响强化学习算法的性能。例如,在自动驾驶的跟车任务中,智能体在训练中遇到前车速度一直是正常的,但在测试的时候前车突然急刹车,导致智能体控制的车撞了上去。
为了处理这类问题,研究员们提出利用胡伯尔污染模型(Huber’s contamination model)对上下文转移分布的偏差和不确定性进行建模,并称这个框架为对形势变化鲁棒的马尔可夫决策过程。基于这个模型,研究员们把现有的强化学习算法扩展成能对上下文转移分布的扰动达到比较好鲁棒效果的算法,从而得到对形势变化鲁棒的决策。在跟车类型的机器人运动控制和库存管理的实验里,相比基础的强化学习算法和鲁棒强化学习算法,该算法达到了对于上下文扰动更好的鲁棒性能。
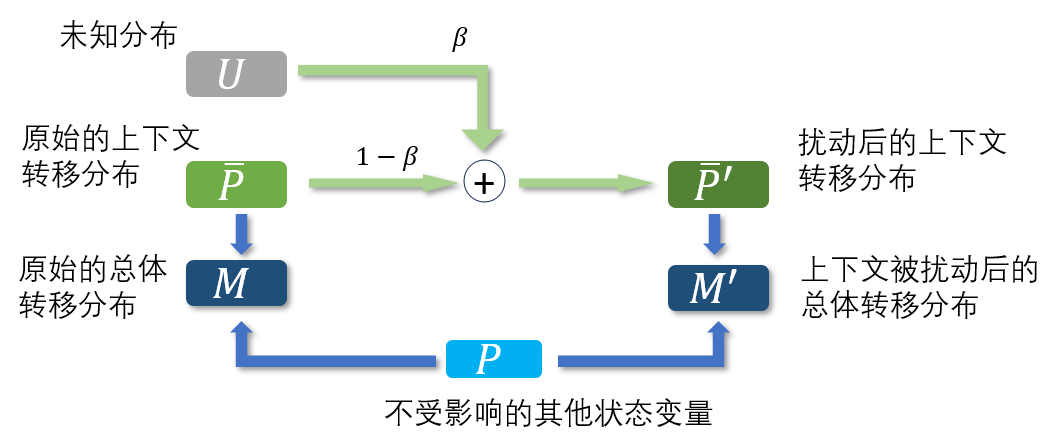
图6:胡伯尔污染模型框架
Synthetic Prompting: 为大语言模型合成有效的思维链示例

论文链接:https://openreview.net/pdf?id=RYD1UMgTdk
大语言模型可以通过链式思考(chain-of-thought prompting)来完成各种推理任务,即利用指令和任务示例引导模型生成逐步的推理过程来解决问题。在少样本的情况下,语言模型的表现很大程度上取决于任务示例的质量,尤其是在推理过程复杂且模式多样的任务上。理想情况下,科研人员们希望能获取大量且多样的示例,从中选取对模型帮助最大的示例构成任务提示词。然而,人工构建大量的示例既费时又繁琐,而仅依赖少量的人工示例则可能不利于模型泛化到更多样的测试场景当中去。
为解决上述问题,研究员们提出了 Synthetic Prompting,利用大语言模型自身的知识和生成能力,基于有限的人工示例合成更多更有效的示例,并通过合成示例触发更好的推理表现。具体而言,给定一些种子示例,每个示例由一个问题和一系列推理步骤组成,通过交替进行后向-前向过程来引导语言模型生成更多示例:(1)后向过程,语言模型根据自我采样的推理链合成一个问题,以确保问题可回答且逻辑清晰;(2)前向过程,语言模型基于合成的问题生成一个推理链,确保推理链的精确性。这个过程需一直重复直到获得足够的合成示例。
为了从合成的示例集中选择最有效的示例,研究员们提出了一种基于 in-cluster complexity 的选择方案:通过对示例进行聚类并选择每个聚类中最复杂的示例(推理链最长的示例)来最大程度地增加所选示例的多样性和信息量。最后,用所选定的示例构成提示词来进行推理测试。

图7:示例合成阶段的后向过程(左图)和前向过程(右图)。在后向过程中,研究人员将主题词、所期望的推理复杂度、以及模型采样生成的推理过程(蓝色部分)作为问题合成(绿色部分)的生成条件,以分别提高所合成样本的多样性、信息量、和逻辑性。在前向过程中,语言模型为后向过程中所生成的问题合成一个更精确的推理链(紫色部分)。后向过程中生成的问题和前向过程中生成的推理过程构成一个合成示例。
Synthetic Prompting 让大语言模型同时充当任务示例的“消费者”和“生产者”,一定程度上实现推理效果的自我提升。在数值推理、算法推理和符号推理任务上的实验表明,相比于此前方法,如 chain-of-thought prompting 和 PAL prompting,Synthetic Prompting 可以实现高达15.6%的提升。






![go 查询采购单设备事项[小示例]](https://img-blog.csdnimg.cn/cc4f4e917ae142e8ac7ed42331aaacae.png)