1、前言
可能刚接触的人会思考为啥要使用编译器:
一般跨平台、跨语言的都有一套固定的流程,大致可分为:
撰写IDL文件 -> 使用对应语言的编译器,编译成对应的语言 -> 序列化 ->持久化 -> 反序列化
这里就对应着这个阶段:使用编译器
根据自己语言的选择,选择对应的编译器即可,有些语言需要注意版本问题,如我当前用的是 Java,需要接入第三方Jar,如:
<dependency>
<groupId>com.google.flatbuffers</groupId>
<artifactId>flatbuffers-java</artifactId>
<version>22.10.26</version>
</dependency>这里用的是22.10.26版本,所以用的编译器需要在下载对应版本的编译器
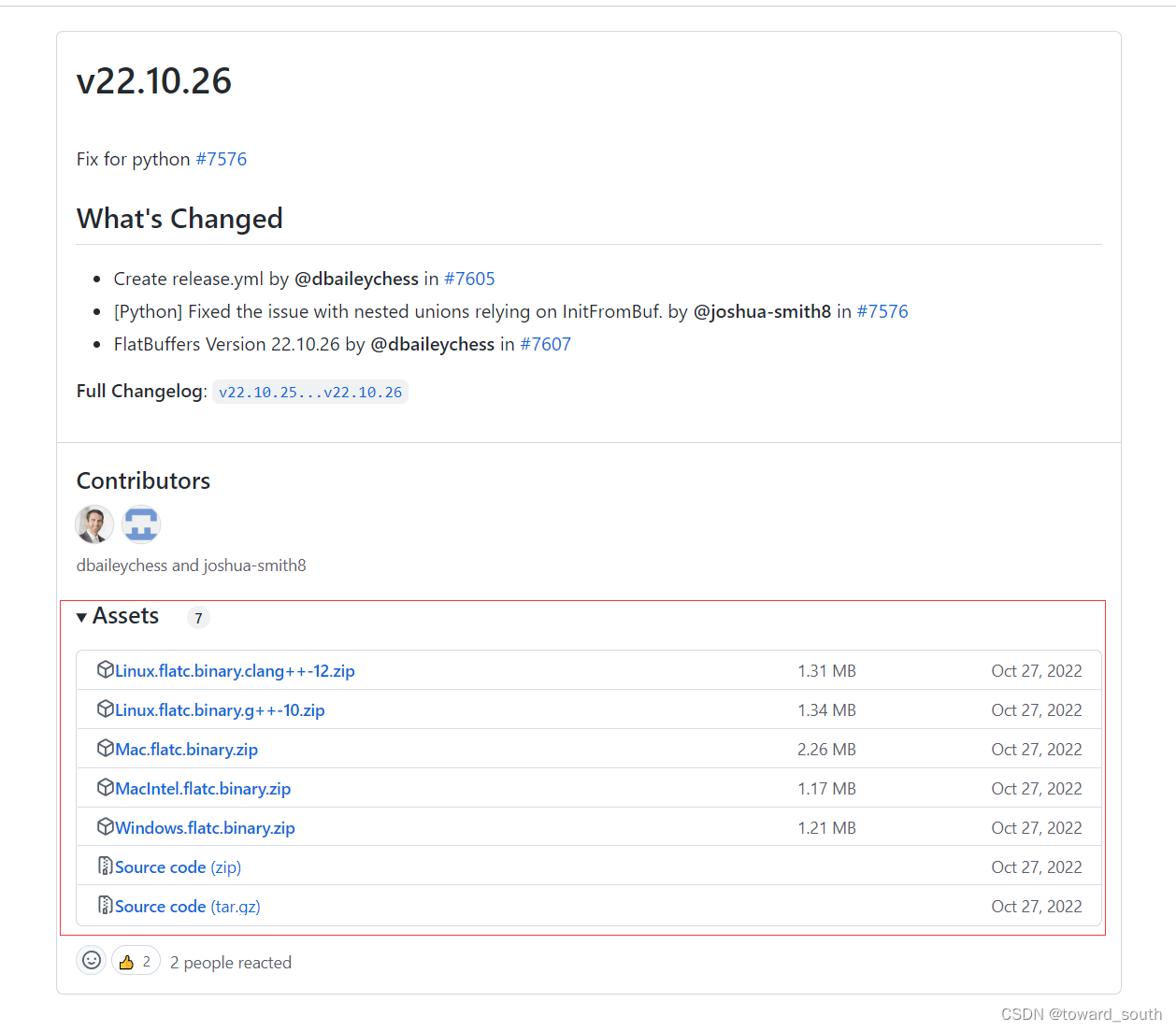
编译器下载地址:Releases · google/flatbuffers · GitHub,下载位置如下图所示:
2、编译命令
切换到编译器的位置,然后执行对应命令即可,如 :
flatc --java process.fbs
执行完之后,flatC 这个目录下就会生成对应的 Java 类了。
具体命令说明地址:
FlatBuffers: Using the schema compiler
里边值得说的几个命令:
1、--gen-mutable -- 这个用来可以就地的修改信息类里的一些数据,即生成的对象中提供了设置值的方法,举个例子:一般我们接受对方发过来的数据,进行反序列化后,我们需要修改一部分数据,这时候就需要这个命令了。特别提示下,在Java中,这个只作用于一些基础类型,如double 、float、int、boolean 这些。不提供String 的直接修改。
2、--gen-object-api -- 生成辅助类,即帮助你设置和获取值的,好处就是方便,坏处就是多了一个类,每个table会生成两个类。