目录
- 1、例子抛出
- 2、 了解inline
- 2.1 宏替换的副作用
- 2.2 内联函数
- 2.3 有意思的点
- 3、总结
- 4、 感谢您的阅读!
1、例子抛出
我们知道可以用宏定义来代替一个变量或者函数块:
#define A 20
#define MYFUNC(a,b) ((a) > (b) ? (a) : (b))
但是用宏定义来替换代码块的时候会有一些副作用(从上面那么多括号也能看出来)。所以想找一种方法来代替宏代码片段,这就是内联函数的作用。
inline int myfunc(int a,int b)
{
return (a > b ? a : b);
}
2、 了解inline
2.1 宏替换的副作用
几个简单的例子:
// 1 优先级问题
#define MYADD(a,b) (a) + (b)
int c = MYADD(a,b) * 3; // => (a) + (b) * 3 其实是想要(a + b) * 3
// 2 ++,--
#define MAX(a,b) ((a) > (b) ? (a) : (b))
int a = 3,b = 2;
int c = MAX(a++,b); // 这块大家可以去试验一下,看看几个变量最后的取值
2.2 内联函数
内联函数是在 C++ 中增加的一个功能,可以提高程序执行效率。如果函数是内联的,编译器在编译时,会把内联函数的实现替换到每个调用内联函数的地方,可以与宏函数作类比,但宏函数不会进行类型检查。
为什么要用内联函数?
先来想想普通函数的调用过程:
# include ...
int add(int a, int b)
{
return a+b;
}
int main()
{
int a = 1, b = 2,;
int c = add(a, b);
int d = add(c, a);
int e = add(d, b);
return 0;
}
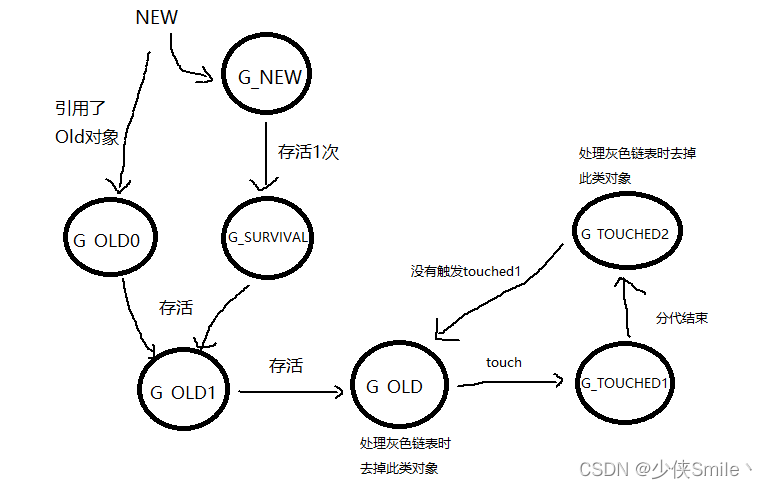
他的调用过程可以这样画出来:
每执行一次add函数就要压栈跳转返回等一系列操作,如果函数很简单,这样频繁开销也降低了程序的运行效率。
# include ...
// 如果把这个短小精悍的函数变为内联函数
inline int add(int a, int b)
{
return a+b;
}
int main()
{
int a = 1, b = 2,;
// 那么效果就会变成类似这样, 不严谨哈,表达这个意思。
int c = {
return a+b;
};
int d = {
return c+a;
};
int e = {
return d+b;
};
return 0;
}
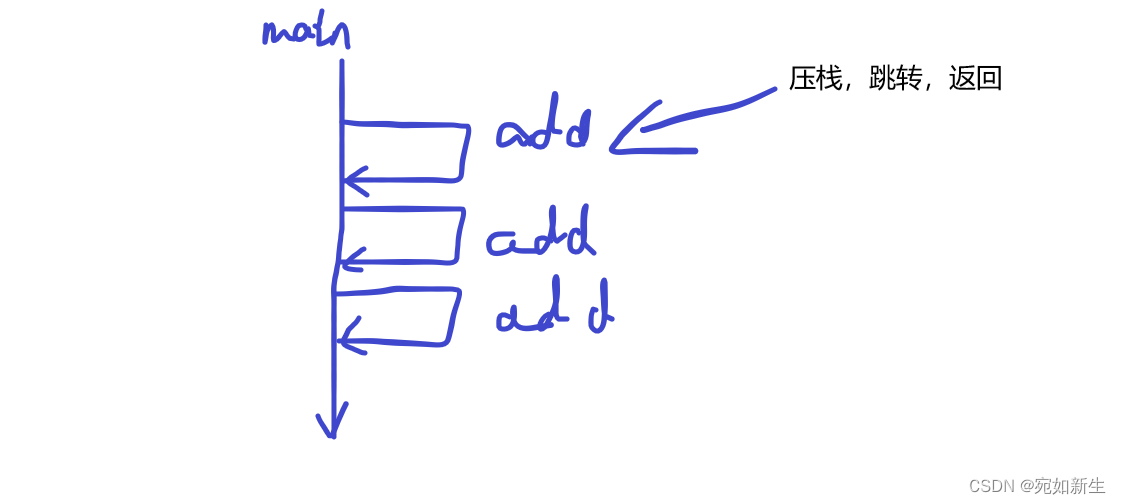
引入内联函数主要是解决一些频繁调用的小函数消耗大量空间的问题。通常情况下,在调用函数时,程序会将控制权从调用程序处转移到被调用函数处,在这个过程中,传递参数、寄存器操作、返回值等会消耗额外的时间和内存,如果调用的函数代码量很少,也许转移到调用函数的时间比函数执行的时间更长。而如果使用内联函数,内联函数会在调用处将代码展开,从而节省了调用函数的开销。
2.3 有意思的点
内联函数在最终生成的代码中没有定义,c++编译器直接将函数体插入到函数调用的位置
啥意思?你可以告诉自己知道这地方有个内联函数,但是当编译完成时,这块代码块你就可以无视了,因为他已经插入到函数调用的地方去了。所以下面这种写法也可以;
# include ...
int main()
{
inline int add(int a, int b)
{
return a+b;
}
int a = 1, b = 2,;
int c = add(a, b);
int d = add(c, a);
int e = add(d, b);
return 0;
}
但是,一定要注意,内联函数要写在函数调用之前。
3、总结
① 内联函数必须声明和函数体实现写在一块;
② 内联函数在最终生成的代码中没有定义,c++编译器直接将函数体插入到函数调用的位置;
③ 内联函数调用时,没有普通函数调用时的额外开销(压栈出栈等)
④ c++编译器不一定准许函数的内联请求,这时即使写了inline关键字,也不一定编译成内联函数, 短小精悍的才适合定义为内联函数;
⑤ 内联函数由编译器处理,宏替换由预处理器处理(这里会产生一些副作用)
⑥ c++编译器对内联函数有一定限制:
不能存在任何形式的循环语句在内;
不能存在条件太多的判断语句在内;
函数体不能过大;