前言
嗨喽,大家好呀~这里是爱看美女的茜茜呐
又到了学Python时刻~

分析目标
-
各城市对数据分析岗位的需求情况
-
不同细分领域对数据分析岗的需求情况
-
数据分析岗位的薪资状况
-
工作经验与薪水的关系
-
公司都要求什么掌握什么技能
-
岗位的学历要求高吗
-
不同规模的企业对工资经验的要求以及提供的薪资水平
代码展示
导包和数据
import pandas as pd
import numpy as np
import seaborn as sns
from pyecharts.charts import Pie
from pyecharts import options as opts
import matplotlib.pyplot as plt
%matplotlib inline
sns.set_style('white',{'font.sans-serif':['simhei','Arial']})
pd.set_option("display.max_column", None)
pd.set_option("display.max_row",None)
读取数据
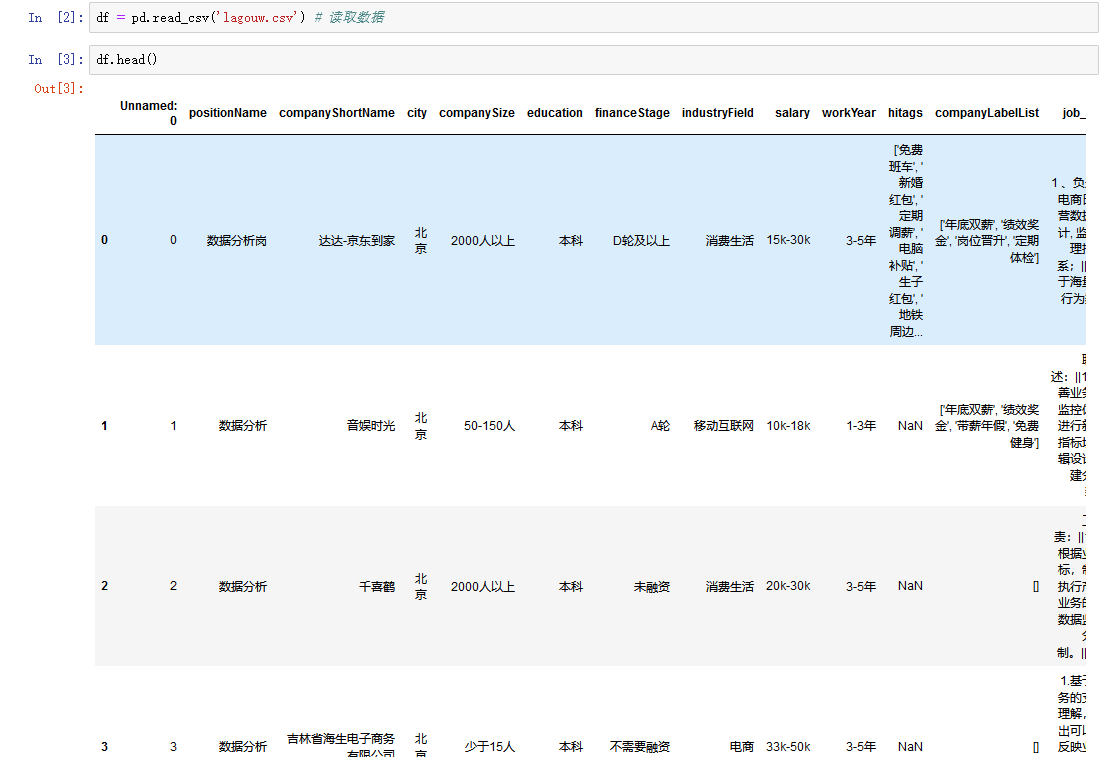

取出我们进行后续分析所需的字段
columns = ["positionName", "companyShortName", "city", "companySize", "education", "financeStage",
"industryField", "salary", "workYear", "hitags", "companyLabelList", "job_detail"]
df[columns].drop_duplicates() #去重
数据清洗
去掉非数据分析岗的数据
数据分析相应的岗位数量
cond_1 = df["positionName"].str.contains("数据分析") # 职位名中含有数据分析字眼的
cond_2 = ~df["positionName"].str.contains("实习") # 剔除掉带实习字眼的
len(df[cond_1 & cond_2]["positionName"])
PS:完整源码如有需要的小伙伴可以加下方的群去找管理员免费领取

# df = df[cond_1 & cond_2]
# df
筛选出我们想要的字段,并剔除positionName
df = df[cond_1 & cond_2]
df.drop(["positionName"], axis=1, inplace=True)
df.reset_index(drop=True, inplace=True)
df.head()
将薪水转化为数值
采集下来的薪水是一个区间,这里用薪水区间的均值作为相应职位的薪水
处理过程
-
将salary中的字符串均小写化(因为存在8k-16k和8K-16K)
-
运用正则表达式提取出薪资区间
-
将提取出来的数字转化为int型
-
取区间的平均值
df["salary"] = df["salary"].str.lower()\
.str.extract(r'(\d+)[k]-(\d+)k')\
.applymap(lambda x:int(x))\
.mean(axis=1)
从job_detail中提取出技能要求
将技能分为以下几类:
-
Python/R
-
SQL
-
Tableau
-
Excel
处理方式: 如果job_detail中含有上述四类,则赋值为1,不含有则为0
df["job_detail"] = df["job_detail"].str.lower().fillna("") #将字符串小写化,并将缺失值赋值为空字符串
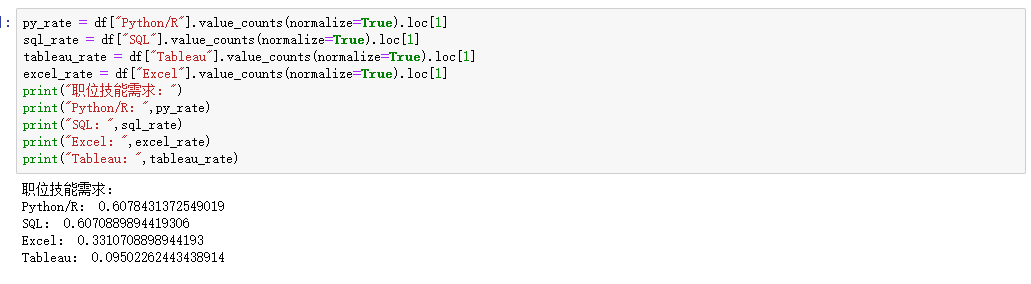
df["Python/R"] = df["job_detail"].map(lambda x:1 if ('python' in x) or ('r' in x) else 0)
df["SQL"] = df["job_detail"].map(lambda x:1 if ('sql' in x) or ('hive' in x) else 0)
df["Tableau"] = df["job_detail"].map(lambda x:1 if 'tableau' in x else 0)
df["Excel"] = df["job_detail"].map(lambda x:1 if 'excel' in x else 0)
df.head(1)
处理行业信息
def clean_industry(industry):
industry = industry.split(",")
if industry[0]=="移动互联网" and len(industry)>1:
return industry[1]
else:
return industry[0]
df["industryField"] = df.industryField.map(clean_industry)
数据分析可视化
各城市对数据分析岗位的需求量
fig, ax = plt.subplots(figsize=(12,8))
sns.countplot(y="city",order= df["city"].value_counts().index,data=df,color='#3c7f99')
plt.box(False)
fig.text(x=0.04, y=0.90, s=' 各城市数据分析岗位的需求量 ',
fontsize=32, weight='bold', color='white', backgroundcolor='#c5b783')
plt.tick_params(axis='both', which='major', labelsize=16)
ax.xaxis.grid(which='both', linewidth=0.5, color='#3c7f99')
plt.xlabel('')
plt.ylabel('')
plt.show()
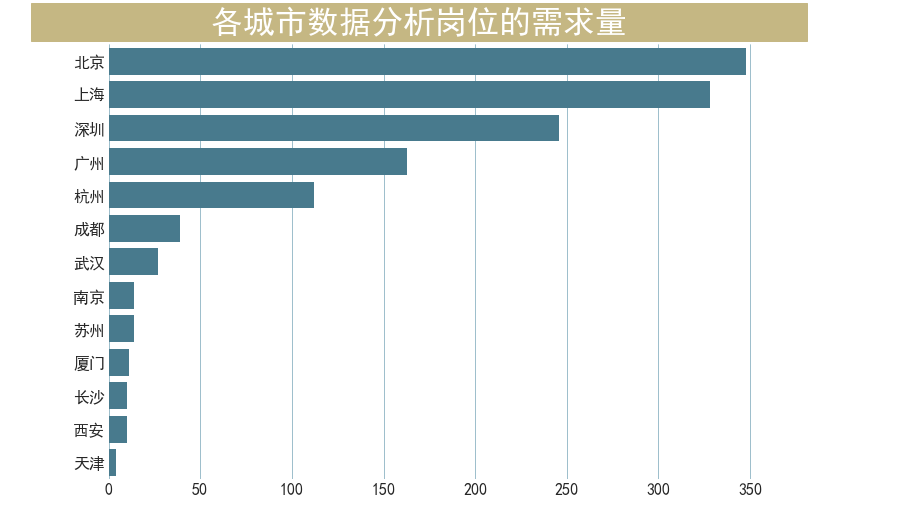
不同细分领域对数据分析岗的需求量

fig, ax = plt.subplots(figsize=(12,8))
sns.countplot(y=industry.values,order = industry_index,color='#3c7f99')
plt.box(False)
fig.text(x=0, y=0.90, s=' 细分领域数据分析岗位的需求量(取前十) ',
fontsize=32, weight='bold', color='white', backgroundcolor='#c5b783')
plt.tick_params(axis='both', which='major', labelsize=16)
ax.xaxis.grid(which='both', linewidth=0.5, color='#3c7f99')
plt.xlabel('')
plt.ylabel('')
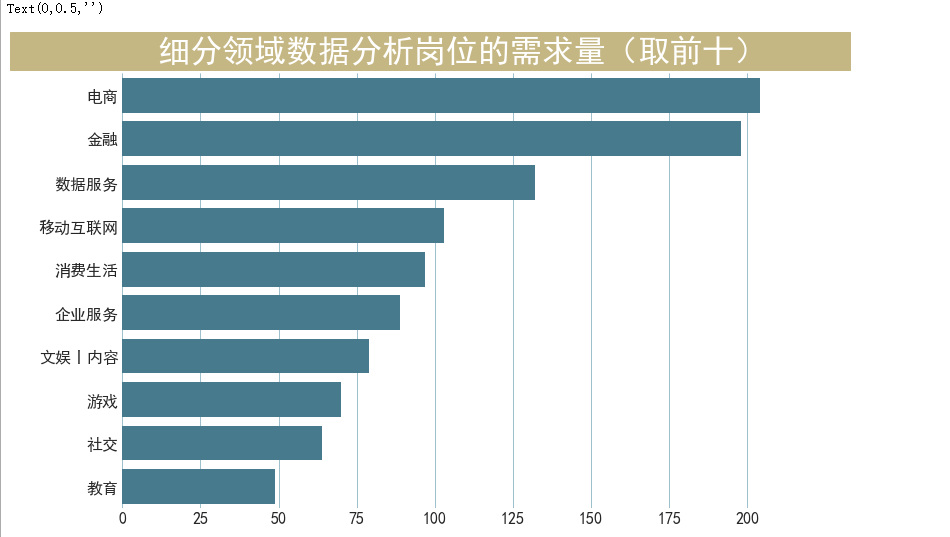
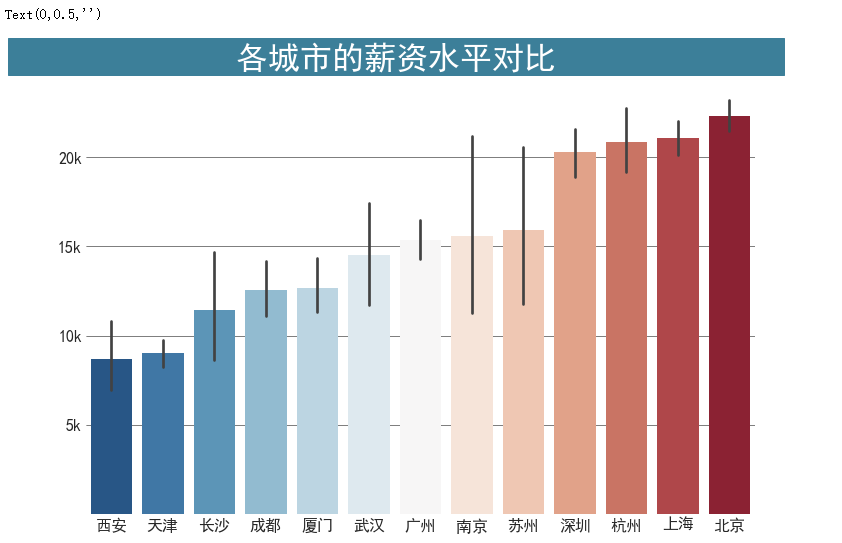
各城市相应岗位的薪资状况
fig,ax = plt.subplots(figsize=(12,8))
city_order = df.groupby("city")["salary"].mean()\
.sort_values()\
.index.tolist()
sns.barplot(x="city", y="salary", order=city_order, data=df, ci=95,palette="RdBu_r")
fig.text(x=0.04, y=0.90, s=' 各城市的薪资水平对比 ',
fontsize=32, weight='bold', color='white', backgroundcolor='#3c7f99')
plt.tick_params(axis="both",labelsize=16,)
ax.yaxis.grid(which='both', linewidth=0.5, color='black')
ax.set_yticklabels([" ","5k","10k","15k","20k"])
plt.box(False)
plt.xlabel('')
plt.ylabel('')
fig,ax = plt.subplots(figsize=(12,8))
fig.text(x=0.04, y=0.90, s=' 一线城市的薪资分布对比 ',
fontsize=32, weight='bold', color='white', backgroundcolor='#c5b783')
sns.kdeplot(df[df["city"]=='北京']["salary"],shade=True,label="北京")
sns.kdeplot(df[df["city"]=='上海']["salary"],shade=True,label="上海")
sns.kdeplot(df[df["city"]=='广州']["salary"],shade=True,label="广州")
sns.kdeplot(df[df["city"]=='深圳']["salary"],shade=True,label="深圳")
plt.tick_params(axis='both', which='major', labelsize=16)
plt.box(False)
plt.xticks(np.arange(0,61,10), [str(i)+"k" for i in range(0,61,10)])
plt.yticks([])
plt.legend(fontsize = 'xx-large',fancybox=None)
plt.show()
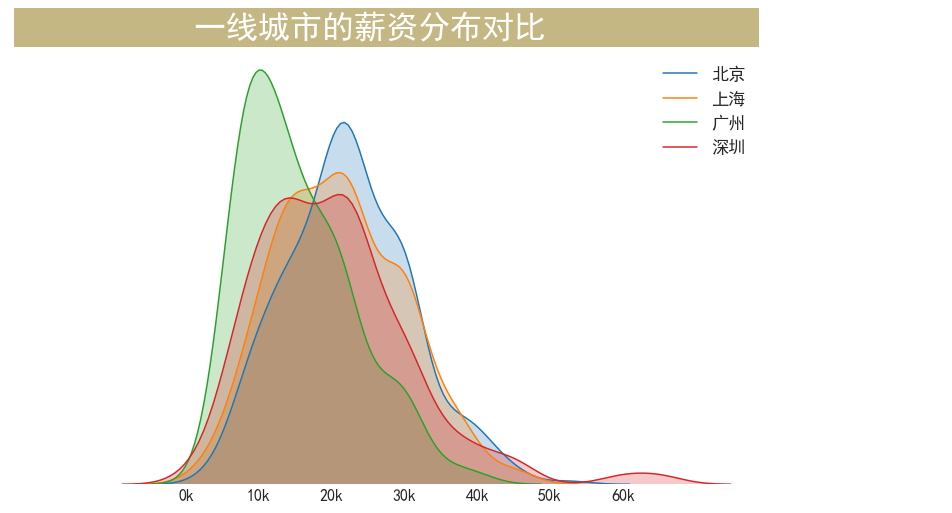
工作经验与薪水的关系
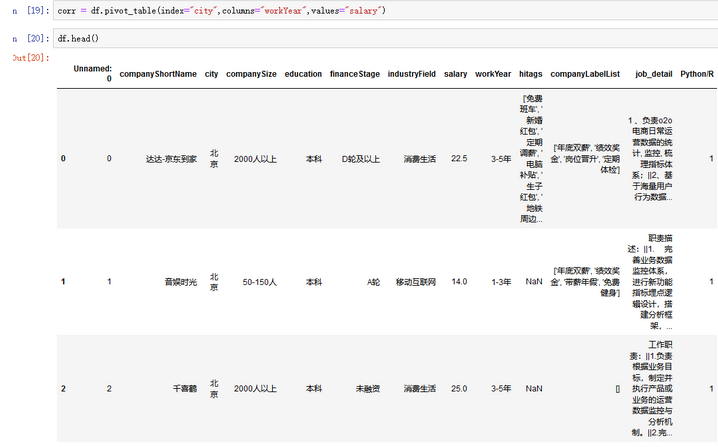

fig,ax = plt.subplots(figsize=(10,8))
sns.heatmap(corr.loc[df["city"].value_counts().index],cmap="RdBu_r",center=20,annot=True,annot_kws={'fontsize':14})
plt.tick_params(axis='x', which='major', labelsize=16)
plt.tick_params(axis='y', which='major', labelsize=16,labelrotation=0)
plt.xlabel(""),plt.ylabel("")
技能要求
def get_level(x):
if x["Python/R"] == 1:
x["skill"] = "Python/R"
elif x["SQL"] == 1:
x["skill"] = "SQL"
elif x["Excel"] == 1:
x["skill"] = "Excel"
else:
x["skill"] = "其他"
return x
df = df.apply(get_level,axis=1)
fig,ax = plt.subplots(figsize=(12,8))
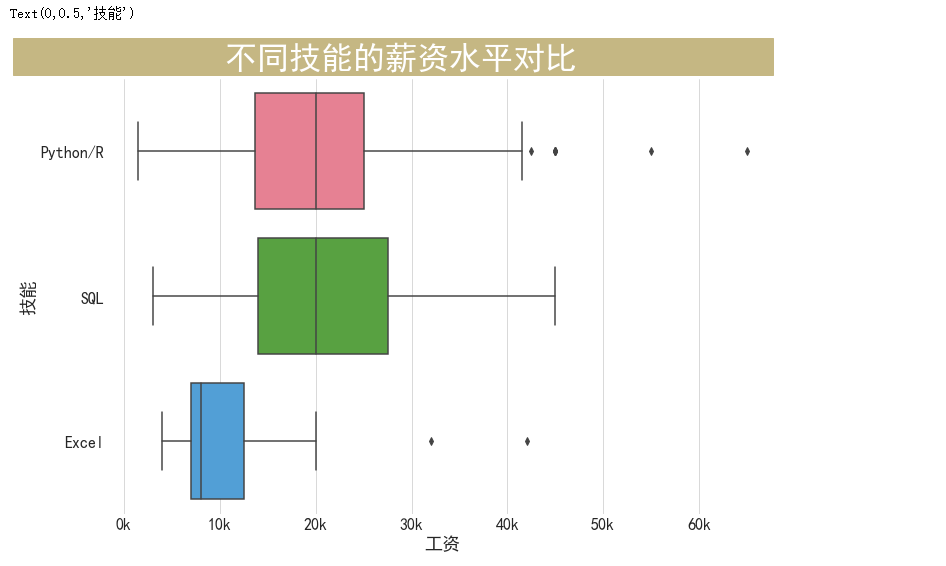
fig.text(x=0.02, y=0.90, s=' 不同技能的薪资水平对比 ',
fontsize=32, weight='bold', color='white', backgroundcolor='#c5b783')
sns.boxplot(y="skill",x="salary",data=df.loc[df.skill!="其他"],palette="husl",order=["Python/R","SQL","Excel"])
plt.tick_params(axis="both",labelsize=16)
ax.xaxis.grid(which='both', linewidth=0.75)
plt.xticks(np.arange(0,61,10), [str(i)+"k" for i in range(0,61,10)])
plt.box(False)
plt.xlabel('工资', fontsize=18)
plt.ylabel('技能', fontsize=18)
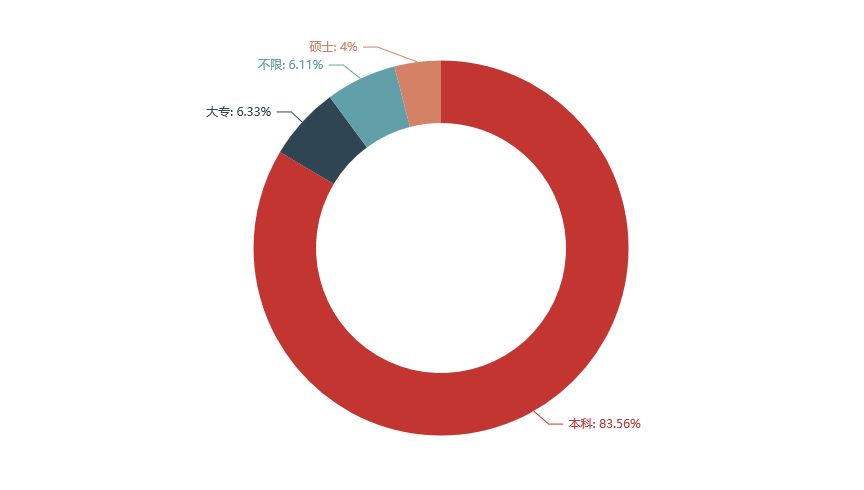
学历要求

from pyecharts.commons.utils import JsCode
def new_label_opts():
return opts.LabelOpts(formatter=JsCode("educatio"))
pie = (
Pie()
.add(
"",
[list(z) for z in zip(education.index, np.round(education.values,4))],
center=["50%", "50%"],
radius=["50%","75%"],
label_opts=new_label_opts()
)
.set_global_opts(
title_opts=opts.TitleOpts(title=""),
legend_opts=opts.LegendOpts(
is_show=False
)
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%")))

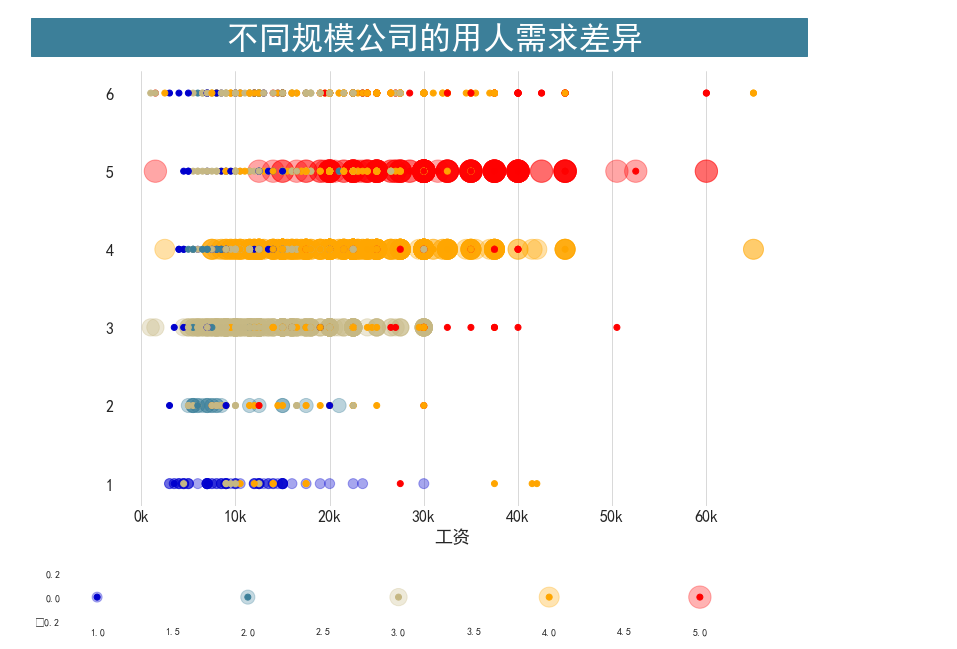
不同规模的公司在招人要求上的差异
company_size_map = {
"2000人以上": 6,
"500-2000人": 5,
"150-500人": 4,
"50-150人": 3,
"15-50人": 2,
"少于15人": 1
}
workYear_map = {
"5-10年": 5,
"3-5年": 4,
"1-3年": 3,
"1年以下": 2,
"应届毕业生": 1
}
df["companySize"] = df["companySize"].map(company_size_map)
df["workYear"] = df["workYear"].map(workYear_map)

def seed_scale_plot():
seeds=np.arange(5)+1
y=np.zeros(len(seeds),dtype=int)
s=seeds*100
colors=['#ff0000', '#ffa500', '#c5b783', '#3c7f99', '#0000cd'][::-1]
fig,ax=plt.subplots(figsize=(12,1))
plt.scatter(seeds,y,s=s,c=colors,alpha=0.3)
plt.scatter(seeds,y,c=colors)
plt.box(False)
plt.grid(False)
plt.xticks(ticks=seeds,labels=list(workYear_map.keys())[::-1],fontsize=14)
plt.yticks(np.arange(1),labels=[' 经验:'],fontsize=16)
fig, ax = plt.subplots(figsize=(12, 8))
fig.text(x=0.03, y=0.92, s=' 不同规模公司的用人需求差异 ', fontsize=32,
weight='bold', color='white', backgroundcolor='#3c7f99')
plt.scatter(df_plot.salary, df_plot["workYear"], s=df_plot["workYear"]*100 ,alpha=0.35,c=df_plot["color"])
plt.scatter(df_plot.salary, df_plot["companySize"], c=df_plot["color"].values.tolist())
plt.tick_params(axis='both', which='both', length=0)
plt.tick_params(axis='both', which='major', labelsize=16)
ax.xaxis.grid(which='both', linewidth=0.75)
plt.xticks(np.arange(0,61,10), [str(i)+"k" for i in range(0,61,10)])
plt.xlabel('工资', fontsize=18)
plt.box(False)
seed_scale_plot()
尾语 💝
我给大家准备了一些资料,包括:
2022最新Python视频教程、Python电子书10个G
(涵盖基础、爬虫、数据分析、web开发、机器学习、人工智能、面试题)、Python学习路线图等等
直接在文末名片自取即可!
有更多建议或问题可以评论区或私信我哦!一起加油努力叭(ง •_•)ง
喜欢就关注一下博主,或点赞收藏评论一下我的文章叭!!!










![[附源码]Python计算机毕业设计SSM基于的社区疫情管理系统(程序+LW)](https://img-blog.csdnimg.cn/9f4397a417064b8694e8c01e319086f3.png)