目录
- 一、前言
- 二、安装
- 三、自己训练一个tokenizer
- 四、模型运行
- 五、拓展
一、前言
前面我们介绍了一种字符编码方式【如何训练一个中英翻译模型】LSTM机器翻译seq2seq字符编码(一)
这种方式是对一个一个字符编码,丢失了很多信息比如“机器学习训练”,会被编码为“机”,“器”,“学”,“习”,“训”,“练”,单独一个字符,丢失了关联性。对于英文句子,比如:Let’s do tokenization!,基于字符分割如下图:
 当然,我们也可以基于其它类型进行分割,比如说基于空格,或者基于punctuation
当然,我们也可以基于其它类型进行分割,比如说基于空格,或者基于punctuation

但这种分割方式分割不了beginning,应该beginning是由begin跟后缀ning组成的,再比如annoyingly实际可分割为annoying加上后缀ly。
再比如想将“机器学习训练”分割为“机器/学习/训练”,那么该怎么办呢,这里可以用谷歌开源的工具sentencepiece(当然了,github仓库说明了这不是 Google 官方产品),接下来我们来看看怎么安装使用。
建议可以先把:如何训练一个中英翻译模型这个栏目的文章看一看,对于理解LLM是会有所帮助的,因为在transformer还未诞生之前可谓是LSTM(RNN)的天下,后人思想受前人思想的启发,提前了解收货会更大。
1)仓库代码:
github:sentencepiece
2)SentencePiece介绍:
SentencePiece 是一种无监督文本分词器和去分词器,主要用于基于神经网络的文本生成系统,其中词汇量大小在神经模型训练之前预先确定。 SentencePiece 通过扩展原始句子的直接训练来实现子词单元(例如,字节对编码 (BPE) (byte-pair-encoding (BPE) [ Sennrich et al.]))和一元语言模型(unigram language model Kudo.))。 SentencePiece 允许我们制作一个纯粹的端到端系统,不依赖于特定于语言的预处理/后处理。
二、安装
ubuntu安装依赖
sudo apt-get install cmake build-essential pkg-config libgoogle-perftools-dev
安装sentencepiece
1)命令安装(超级推荐)
# 用于训练的
sudo apt install sentencepiece -y
# 用于python推理调用的
pip3 install sentencepiece
2)除此之外,还可以选择编译安装:
% git clone https://github.com/google/sentencepiece.git
% cd sentencepiece
% mkdir build
% cd build
% cmake ..
% make -j $(nproc)
% sudo make install
% sudo ldconfig -v
3)或者vcpkg编译安装
git clone https://github.com/Microsoft/vcpkg.git
cd vcpkg
./bootstrap-vcpkg.sh
./vcpkg integrate install
./vcpkg install sentencepiece
安装好了之后就可开始尝试进行训练一个模型了。
三、自己训练一个tokenizer
用于训练的txt文件自己去找一个即可,我这边找的是斗破某陆小说。
这里要注意XXX.txt文本的编码格式,建议采用utf-8格式,对于windows下的ANSI,ubuntu下打开会乱码,且训练出来的模型是会有问题,所以先打开XXX.txt看看文本是不是乱码的。
乱码是真的乱,如下:
 确保XXX.txt文件没问题了,那么就可以进行训练了
确保XXX.txt文件没问题了,那么就可以进行训练了
在命令窗口输入以下命令:
spm_train --input=dpcq.txt -model_prefix=./tokenizer
–input:输入的txt文件,这里的文件是dpcq.txt
-model_prefix:模型输出路径与名称,这里的名称是tokenizer
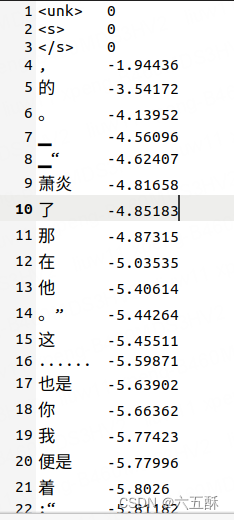
训练完成可以看到以下两个文件:

tokenizer.model:是训练出来的模型
tokenizer.vocab:为所分割的词汇,这个文件可以打开来看看:
四、模型运行
训练出来的模型,我们来跑跑看效果怎样:
from sentencepiece import SentencePieceProcessor
model_path = "tokenizer.model"
sp_model = SentencePieceProcessor(model_file=model_path)
mm = sp_model.EncodeAsPieces("虽说这些年大陆之上已是没有了他的身影,但那传说,却依然是口口相传,炎帝之名,响彻着斗气大陆的每一个角落。")
print(mm)

五、拓展
有了上面的基础了,这里我们来进行一个拓展,这个拓展是基于llama2模型的。
github链接:
llama2.c
先git下来
git clone https://github.com/karpathy/llama2.c.git
下载后要训练自己的模型,命令如下:
# 下载数据集
python tinystories.py download
# 数据集标记化处理
python tinystories.py pretokenize
# 训练
python train.py
我们这里主要是来看tokenize,python tinystories.py pretokenize这个命令是调用了tokenizer.py,我们来看相应的代码:
# Taken from llama code and lightly modified
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This software may be used and distributed according to the terms of the Llama 2 Community License Agreement.
import os
from logging import getLogger
from typing import List
from sentencepiece import SentencePieceProcessor
TOKENIZER_MODEL = "tokenizer.model" # the llama sentencepiece tokenizer model
TOKENIZER_BIN = "tokenizer.bin" # binary version of the tokenizer for inference in C
class Tokenizer:
def __init__(self):
model_path = TOKENIZER_MODEL
assert os.path.isfile(model_path), model_path
self.sp_model = SentencePieceProcessor(model_file=model_path)
#print(f"Loaded SentencePiece model from {model_path}")
# BOS / EOS token IDs
self.n_words: int = self.sp_model.vocab_size()
self.bos_id: int = self.sp_model.bos_id()
self.eos_id: int = self.sp_model.eos_id()
self.pad_id: int = self.sp_model.pad_id()
#print(f"#words: {self.n_words} - BOS ID: {self.bos_id} - EOS ID: {self.eos_id}")
assert self.sp_model.vocab_size() == self.sp_model.get_piece_size()
def encode(self, s: str, bos: bool, eos: bool) -> List[int]:
assert type(s) is str
t = self.sp_model.encode(s)
if bos:
t = [self.bos_id] + t
if eos:
t = t + [self.eos_id]
return t
def decode(self, t: List[int]) -> str:
return self.sp_model.decode(t)
def export(self):
tokens = []
for i in range(self.n_words):
# decode the token and light postprocessing
t = self.sp_model.id_to_piece(i)
if i == self.bos_id:
t = '\n<s>\n'
elif i == self.eos_id:
t = '\n</s>\n'
elif len(t) == 6 and t.startswith('<0x') and t.endswith('>'):
t = chr(int(t[3:5], 16)) # e.g. make '<0x01>' into '\x01'
t = t.replace('▁', ' ') # sentencepiece uses this as the whitespace
tokens.append(t)
with open(TOKENIZER_BIN, 'wb') as f:
for token in tokens:
bytes = token.encode('utf-8')
f.write((len(bytes)).to_bytes(4, 'little')) # write length of bytes
f.write(bytes) # write token bytes
if __name__ == "__main__":
t = Tokenizer()
t.export()
可以看到代码主要是调用了模型TOKENIZER_MODEL = "tokenizer.model"来对训练集进行训练前的编码,这个模型是来源于llama的,我们按照上面的方法来调用看看分割效果:
from sentencepiece import SentencePieceProcessor
model_path = "tokenizer.model"
sp_model = SentencePieceProcessor(model_file=model_path)
mm = sp_model.EncodeAsPieces("The line of code you provided is using the Hugging Face tokenizers library to encode a piece of text. The encode method is being called with the bos=True parameter, which adds a special \"beginning of sequence\" (BOS) token to the beginning of the encoded sequence.")
print(mm)
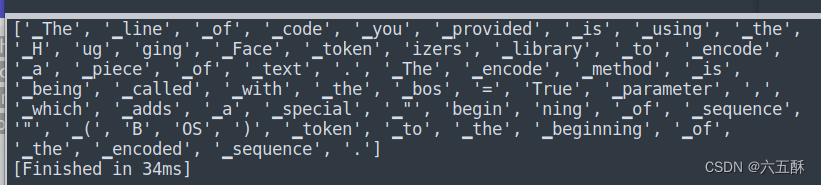 可以看到分割时候会把’beginning’分割为’begin’, ‘ning’。当然了,必要的话也可跟着上面的步骤一样自己训练一个Tokenizer模型。
可以看到分割时候会把’beginning’分割为’begin’, ‘ning’。当然了,必要的话也可跟着上面的步骤一样自己训练一个Tokenizer模型。
这一篇文章先到这里了,还是挺有意思,后面的文章我们将逐渐介绍怎么来训练自己的llama2
参考文献:
https://huggingface.co/learn/nlp-course/zh-CN/chapter2/4?fw=tf
https://blog.csdn.net/sparkexpert/article/details/94741817







![[Linux]线程基本知识](https://img-blog.csdnimg.cn/cc16f1e3591a439787df18f97bb2f134.png)