死锁是事务型数据库中一种现象,为了在高并发环境下不出错,数据库引入了"锁"这一数据结构来控制资源的并发访问,但也会导致死锁。
目录
一、死锁概念
1.1 死锁的原因
1.2 死锁监测
二、死锁演示
2.1 死锁生成过程
2.2 死锁信息查看
三、改善建议
一、死锁概念
1.1 死锁的原因
数据库为了控制事务的并发访问,当事务要更新数据时,必须先获得数据上的"锁"。如果此时"锁"正被其他事务持有,那么就需要排队等待,当其他事务释放了锁之后(提交或回滚)。即可获取锁并对该数据进行操作。
而死锁的原因是"锁"闭环了,例如:
1. 事务A更新获取了记录1上的锁,事务B更新获取了记录2上的锁,Innodb支持行级锁,不会有任何冲突。
2. 此时如果事务A尝试获取记录2上的锁,由于其正被事务B持有,那么事务A会正常等待B释放锁。
3. 此时如果事务B又尝试去获取记录1的锁,那么它又要去等待A释放锁,两事务陷入了相互等待,即死锁。
因此死锁的原因是锁等待闭环了,实际情况可能更复杂一点,有可能是A等B,B等C,C等A,如果不加干预,那么事务有可能无限等待下去。
1.2 死锁监测
实际情况下,死锁是不会无限等待下去的,MySQL自带了死锁监控机制。死锁监控机制由参数 innodb_deadlock_detect 控制,默认就是打开的,当发现死锁时,会立刻挑选一个成本较小的事务作为“牺牲品”,回滚该事务,打破这个等待闭环。
show variables like 'innodb_deadlock_detect';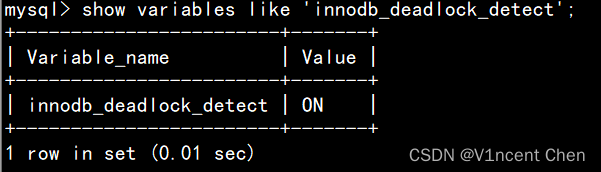
如果关闭改参数,那么MySQL将不再进行死锁监测,大家就这么一直互相等待下去,直到锁等待超时(由参数 innodb_lock_wait_timeout控制)。关闭后由死锁造成的等待超时报错是"Lock wait time out exceeded"而不是死锁的"Dead Lock Found",可能有一定的迷惑性。
二、死锁演示
下面我们通过一个示例来理解死锁,首先创建测试数据,一张test表,插入2行数据。
create table test(
id smallint not null primary key,
name varchar(32));
insert into test values(1,'Vincent');
insert into test values(2,'Victor');
commit;
2.1 死锁生成过程
准备好数据后,我们开启3个会话,会话1,2运行事务,会话3用来观察锁等待情况。
在会话1中执行:
begin; -- 显式开启事务
update test set name='AAA' where id=1;在会话2中执行:
begin;
update test set name='BBB' where id=2;
此时我们通过会话3来查看两个会话锁持有情况,在会话3中执行下列查询:
SELECT
engine_transaction_id,
object_name,
index_name,
lock_data,
lock_mode,
lock_status,
lock_type
FROM performance_schema.data_locks;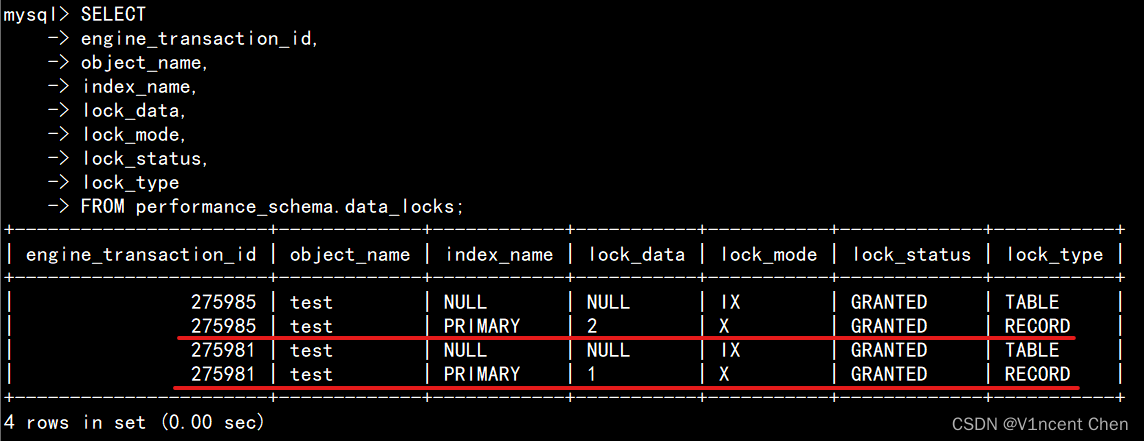
Innodb用的是行级锁,更新不同的记录并不冲突。我们可以看到会话1(事务ID:275981)持有记录1的锁,会话2(事务ID:275985)持有记录2的锁,状态都是GRANTED(已获取)。
此时我们再在会话1中运行下面SQL,尝试更新记录2,由于记录2的锁目前由会话2持有,那么会进入等待,会话不会返回:
update test set name='AAA' where id=2;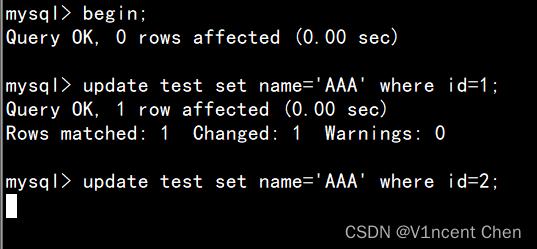
从会话3再次运行上面的锁查询SQL,我们看到会话1(事务ID:275981)又新增了一条锁记录,不过状态是waiting,代表其正在进行锁等待,但并没有获得(会话1等会话2条件达成了)。如果想查看它具体在等谁,可以通过performance_schema.data_lock_waits来查看,这里就不演示了。
SELECT
engine_transaction_id,
object_name,
index_name,
lock_data,
lock_mode,
lock_status,
lock_type
FROM performance_schema.data_locks;
最后一步,我们再从会话2上执行下面SQL,尝试获取会话1持有的锁,正常情况下会话2应该等会话1,而上一步中,会话1也在等待会话2,两事务陷入相互等待。MySQL会立刻探测到死锁,报错并选择一个成本小的事务回滚。
update test set name='BBB' where id=1;
本例中牺牲了会话2的事务(回滚后事务2持有的锁就全部释放了),那么会话1的事务就可以继续进行了。
2.2 死锁信息查看
在发生死锁后,也可以通过innodb 监视器(show engine innodb status;)中"LATEST DETECTED DEADLOCK"模块来查看死锁事务信息,这里显示了哪个事务持有什么锁,在等待什么,以及回滚了谁。
show engine innodb status \G;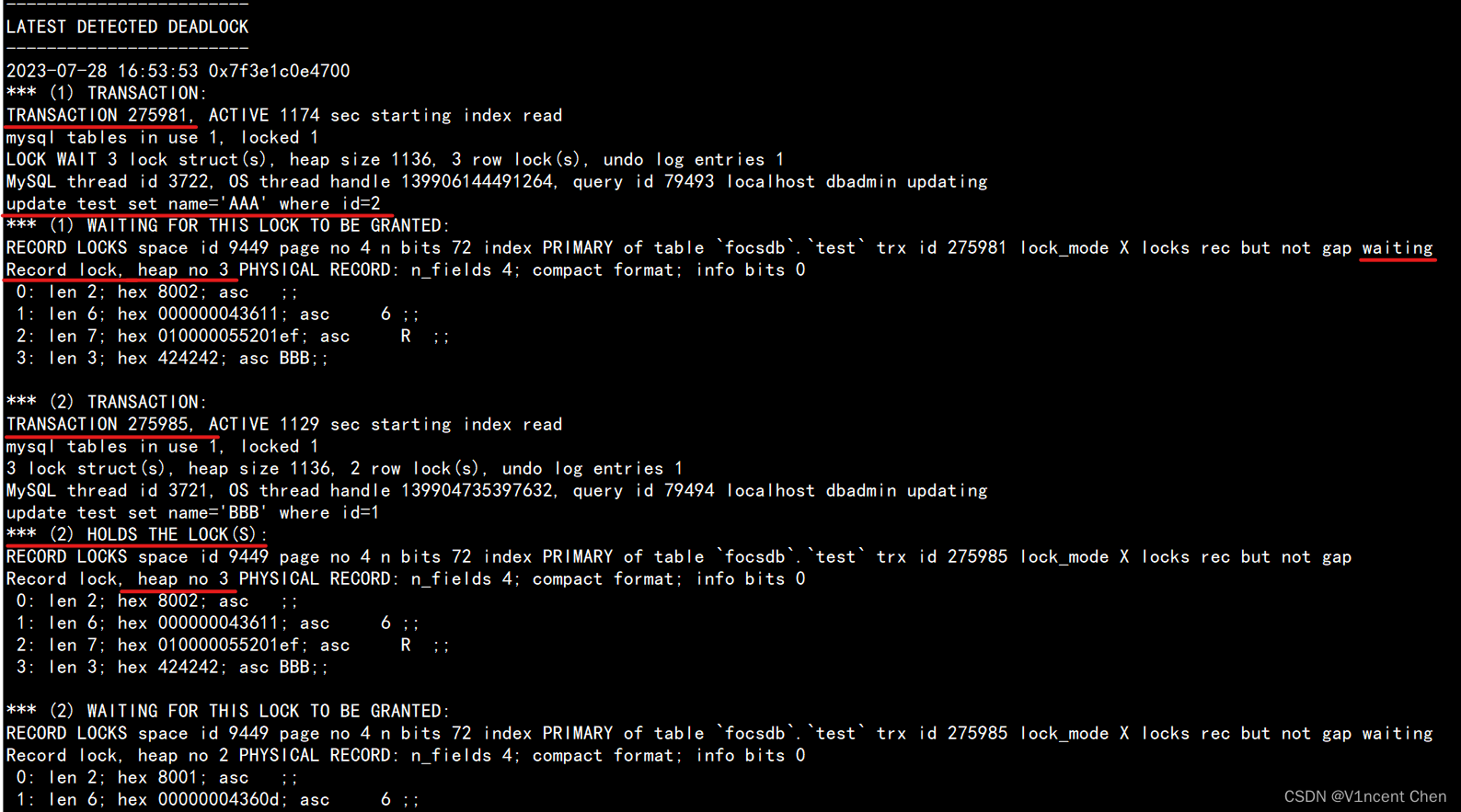
如果经常出现死锁,你也可以打开参数innodb_print_all_deadlocks,该参数会使死锁信息打印进错误日志(由参数log_error指定)中,方便排查问题。
show variables like 'innodb_print_all_deadlocks';
set global innodb_print_all_deadlocks=1;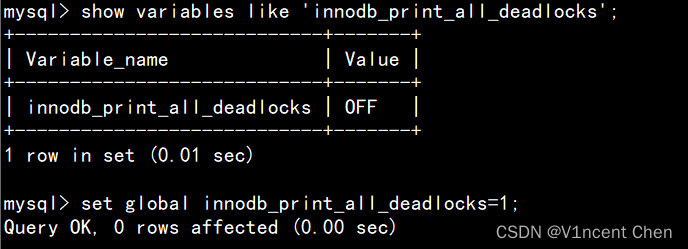
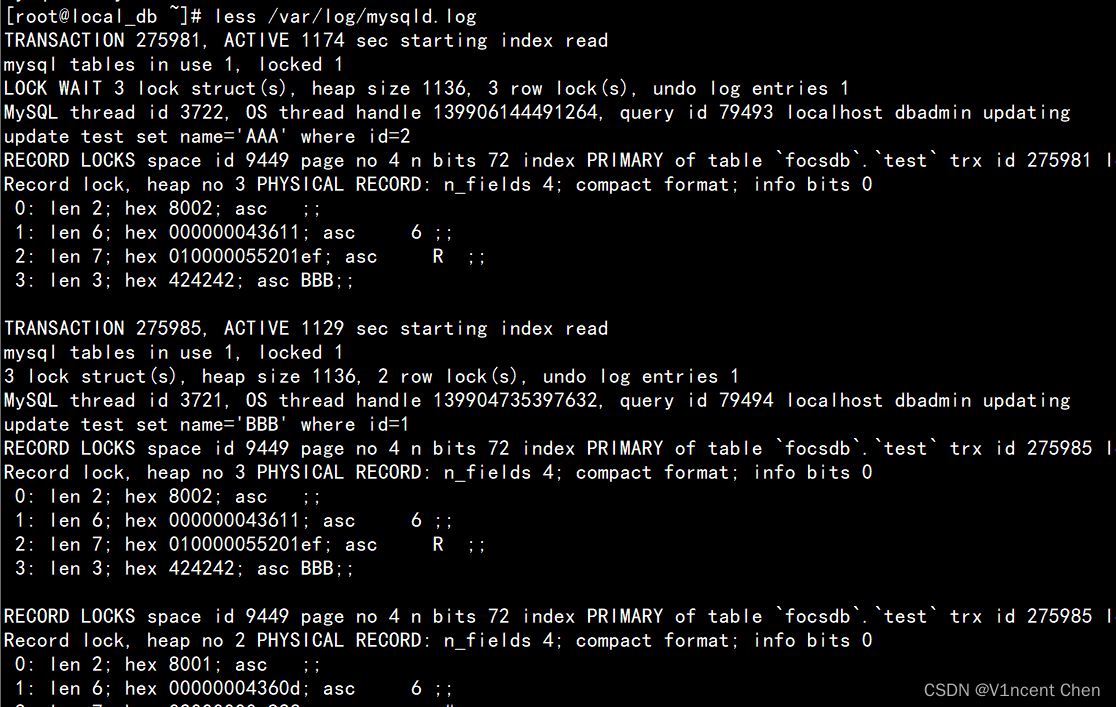
日志中和监视器是同样的信息,但是监视只能显示最新的死锁,打到日志中可以留存记录。
三、改善建议
通常情况下,死锁不会导致特别严重的问题,事务回滚后只要再重新提交就可以了,不会出现数据不一致的现象。但如果生产环境频繁出现死锁,那可能就会影响业务的流畅性了,这种现象通常都是应用设计不合理导致的,需要分析原因解决了。
如果经常出现死锁现象,可以尝试下列改善方法:
- 尽量保持事务设计不要过大,更小的事务可以更快提交,及时释放资源,降低死锁概率。
- 及时提交事务,不要让会话持有长时间未提交的事务。
- 如果事务需要更新多张表,要保持相同的更新顺序。从案例可以看到设计不合理的应用无关事务大小,几句SQL就能导致死锁,可以将操作逻辑封装进函数或存储过程,保证按顺序获取锁。
- 如果要使用"锁读"(select … for update / select … for share),可以尝试将隔离级别降低到 read committed.




![[Linux]线程基本知识](https://img-blog.csdnimg.cn/cc16f1e3591a439787df18f97bb2f134.png)





![[语义分割] DeepLab v3(Cascaded model、ASPP model、两种ASPP对比、Multi-grid、训练细节)](https://img-blog.csdnimg.cn/c037de8b60a34235a6512378e2c14e05.png#pic_center)