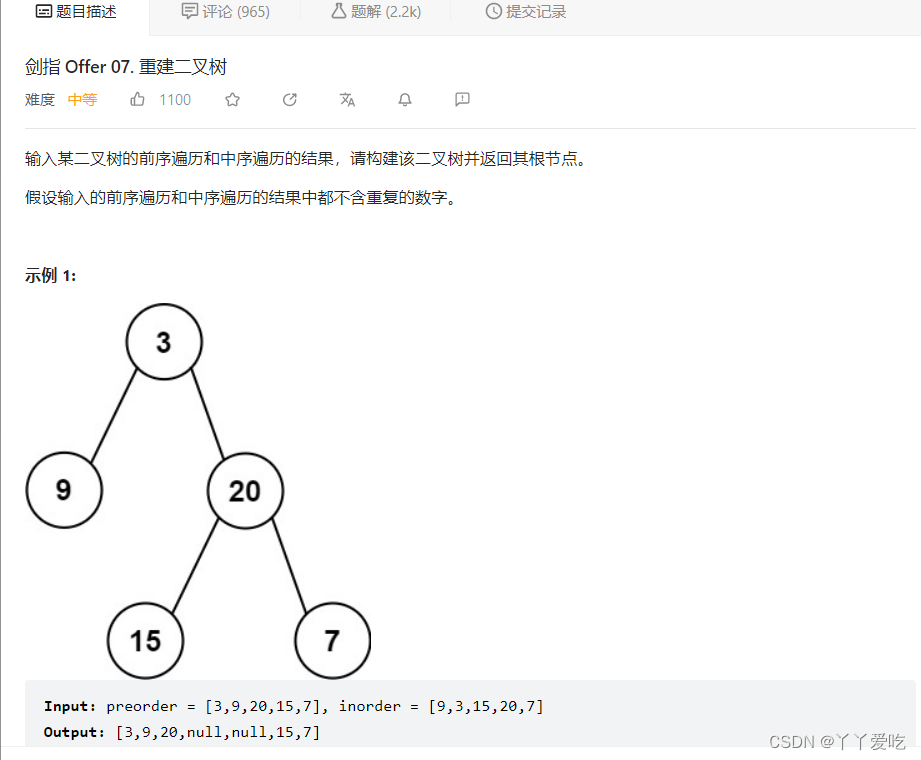
来记录几个注意事项
1.vector容器里利用find()函数
不同于map(map有find方法),vector本身是没有find这一方法,其find是依靠algorithm来实现的。
所以要包含头文件
#include <iostream>
#include <algorithm> //find函数的调用需要包含algorithm这一头文件
#include <vector>
另外返回类型并不是int 类型的索引 iterator迭代器类型的
auto inroot=find(vector.begin(),vector.end(),val)//假设在int类型的vector容器里找值为val的位置
2.关于在vector容器里根据找寻到的位置进行切片,前面为新的vector容器,后面为一个新的vector容器
错误写法
vector inleft=inorder(inorder.begin(),inroot);
这里并不是赋值操作,利用赋值是不对的
正确写法
vector<int> inleft(inorder.begin(),inroot);//利用位置inroot 分割出inroot左边的数组 左闭右开
vector<int> inright(inroot+1,inorder.end());//利用位置inroot 分割出inroot右边的数组 左闭右开
解法:递归
class Solution {
//前序 中左右
//中序 左中右
public:
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
if(preorder.empty()||inorder.empty()) return nullptr;
//1.根节点肯定是前序的第一个
TreeNode* root=new TreeNode(preorder[0]);
//2.在中序遍历中找一下根节点的位置 记住这个函数find(begin(),end(),val)
auto inroot=find(inorder.begin(),inorder.end(),preorder[0]);
//3.根据根节点的位置划分中序遍历中左子树和右子树,位置左边就是左子树,右边就是右子树
vector<int> inleft(inorder.begin(),inroot);
vector<int> inright(inroot+1,inorder.end());
//4.根据中序遍历中左右子树的大小划分前序遍历数组
int leftsize=inleft.size();
vector<int> preleft(preorder.begin()+1,preorder.begin()+1+leftsize);
//不能写成(1,leftsize+1)
vector<int> preright(preorder.begin()+1+leftsize,preorder.end());
//递归处理左右子树
root->left=buildTree(preleft,inleft);
root->right=buildTree(preright,inright);
return root;
}
};
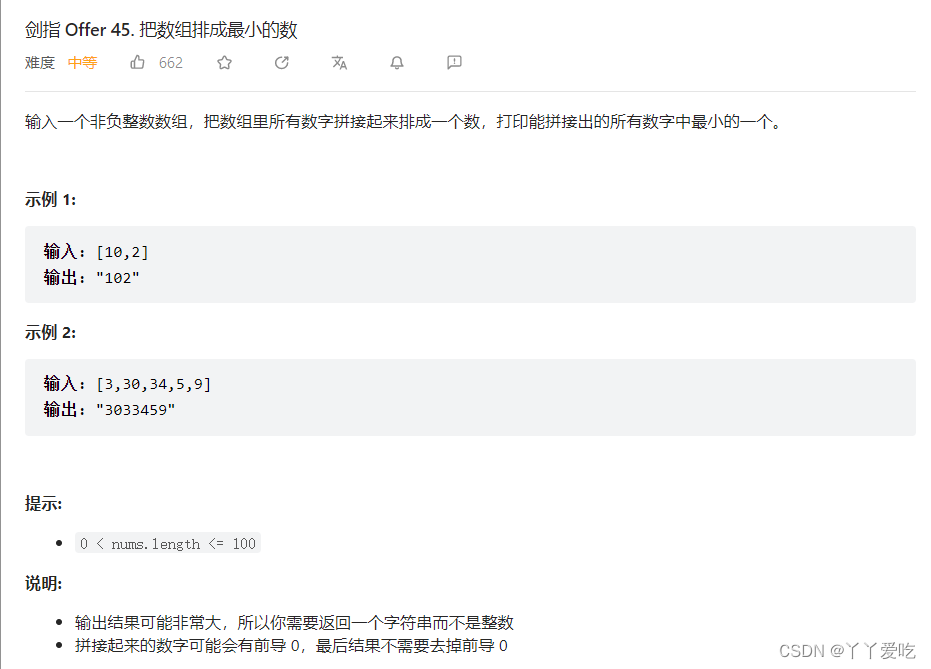
思路:重新定义排序方式
sort(nums.begin(),nums.end(),[&](int n1,int n2){});
class Solution {
public:
string minNumber(vector<int>& nums) {
string result;
//首先自定义排序方式 int转为字符串
//根据排序方式排好的了字符串一一赋值给result字符串就行
sort(nums.begin(),nums.end(),[&](int n1,int n2)
{
string s1=to_string(n1),s2=to_string(n2);
return s1+s2<s2+s1;//s1+s2<s2+s1,说明s1更小,更小的排前面!
});
for(auto& num:nums) result+=to_string(num);
return result;
}
};
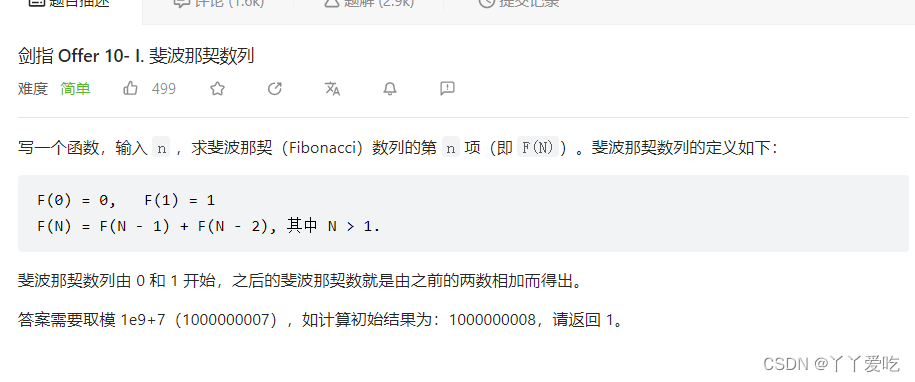
class Solution {
public:
int fib(int n) {
if(n==0) return 0;
if(n==1) return 1;
int x=0,y=0,z=1;
for(int i=2;i<=n;i++)
{
x=y;
y=z;
z=(x+y)%1000000007;
}
return z;
}
};



![[语义分割] DeepLab v3(Cascaded model、ASPP model、两种ASPP对比、Multi-grid、训练细节)](https://img-blog.csdnimg.cn/c037de8b60a34235a6512378e2c14e05.png#pic_center)