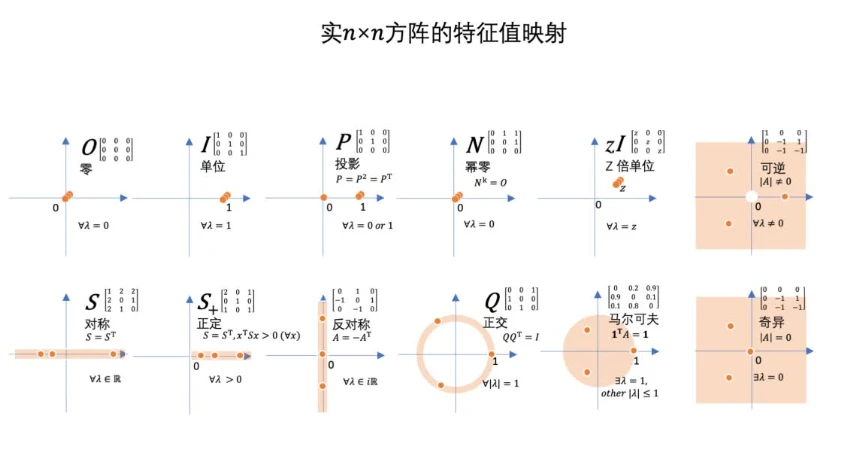
介绍几篇利用CNN+Transformer实现图像分类的论文:CMT(CVPR2022),MaxViT(ECCV2022),MaxViT(ECCV2022),MPViT(CVPR2022)。主要是说明Transformer的局限性,然后利用CNN的优势去弥补和结合。
CMT: Convolutional Neural Networks Meet Vision Transformers, CVPR2022
论文:https://arxiv.org/abs/2107.06263
代码:https://github.com/ggjy/cmt.pytorch
解读:【图像分类】2022-CMT CVPR_說詤榢的博客-CSDN博客
CVPR22 |CMT:CNN和Transformer的高效结合(开源) - 知乎 (zhihu.com)
简介
Vision Transformer 已成功应用于图像识别任务,因为它们能够捕获图像中的远程依赖关系。然而,Transformer 和CNN在性能和计算成本上仍然存在差距,Transformer在patch化图像构建远程依赖时,容易破坏局部结构信息,降低其性能。
本文目标是将CNN的优点结合到Transformer中,以解决上述问题。提出了一个全新的架构CMT,基于层级结构(stage-wise)的transformer,引入卷积操作进行细粒度特征提取,同时也设计了独特的模块层次化提取局部和全局特征。利用transformer来捕获远程依赖关系,并利用 CNN 对局部特征进行建模。在ImageNet基准测试和下游任务上的实验表明了该方法在精度和计算复杂度方面的优越性。

CMT方法
- 首先,输入 Image 进入 CMT Stem,利用卷积进行特征提取并减小图像尺寸。
- 然后,输入由CMT Block堆叠成的4个stage中。
- 最后经过全局平均池化 + 全连接 + softmax 进行分类。

CMT block
包括三部分:a local perception unit (LPU) 局部感知单元, a lightweight multi-head self-attention (LMHSA) module 轻量级多头注意力, and an inverted residual feed-forward network (IRFFN) 反向残差前馈网络。
LPU:采用3x3的深度分离卷积,将卷积的平移不变形引入Transformer模块,并利用残差连接稳定网络训练。
![]()
LMHSA: 利用两个kxk的深度分离卷积分别对Key和Value的生成进行降采样处理,获得两个相对较小的特征K’和V’,节省计算量和显存。
![]()

![]()
IRFFN:在两层全连接层之间加入了深度可分离卷积层.


网络架构
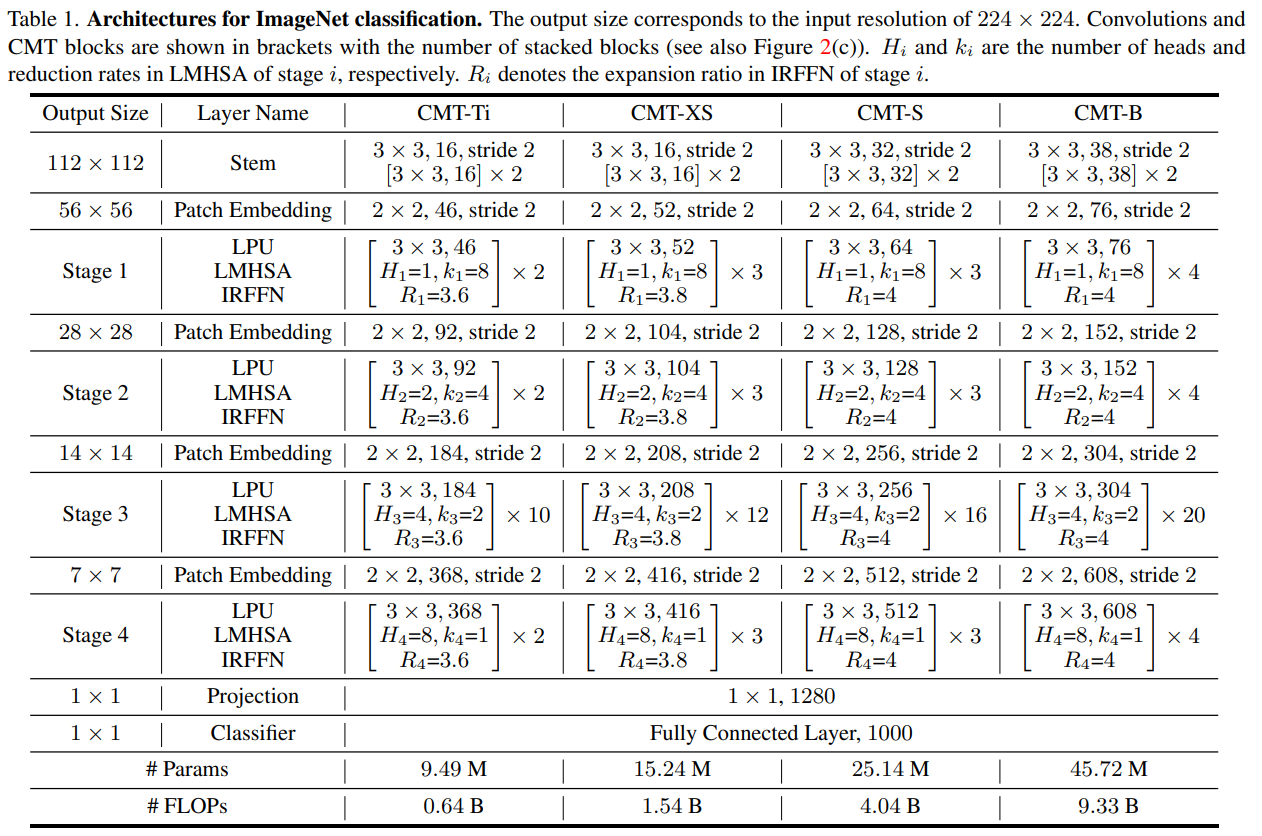
CMT网络主要由CMT(Conv) Stem,四个下采样层,四个Stage,池化层和全连接分类器组成,其中每个Stage由若干个CMT Block堆叠构成。具体结构如表1所示,其中Hi和ki 分别是轻量级多头注意力模块的头部数量和下采样率,Ri是反向残差前馈网络中间层通道的扩增倍数。
实验
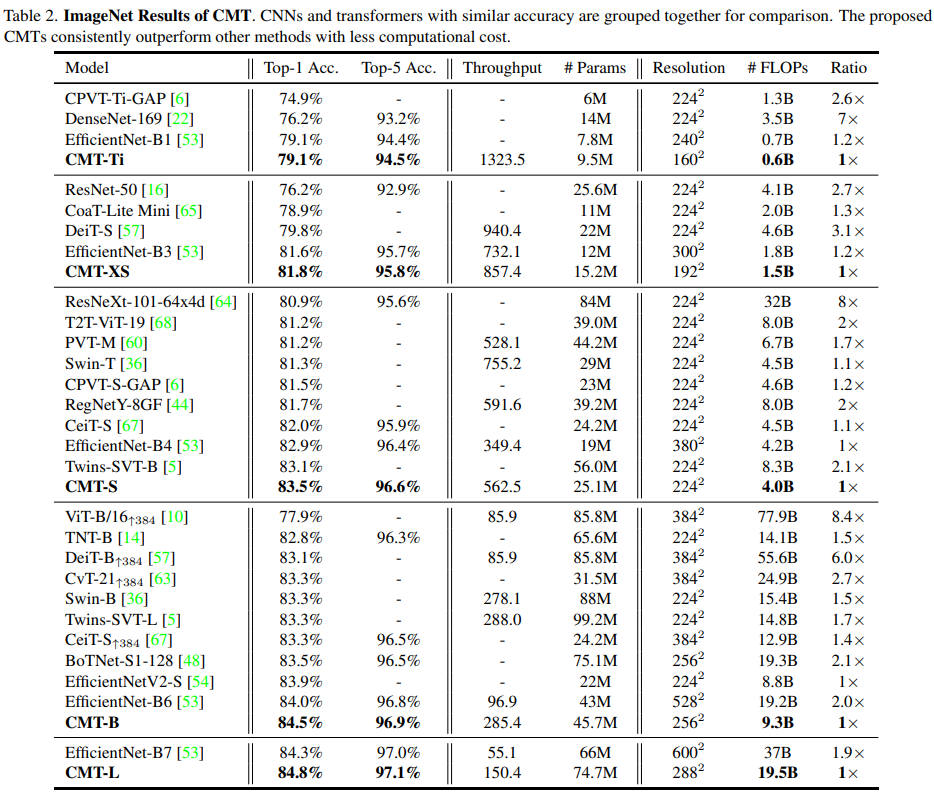
MaxViT: Multi-Axis Vision Transformer, ECCV2022
论文:https://arxiv.org/abs/2204.01697
代码:https://github.com/google-research/maxvit
解读:【图像分类】2022-MaxViT ECCV_图像分类最新模型_說詤榢的博客-CSDN博客
MaxViT: Multi-Axis Vision Transformer - 知乎
简介
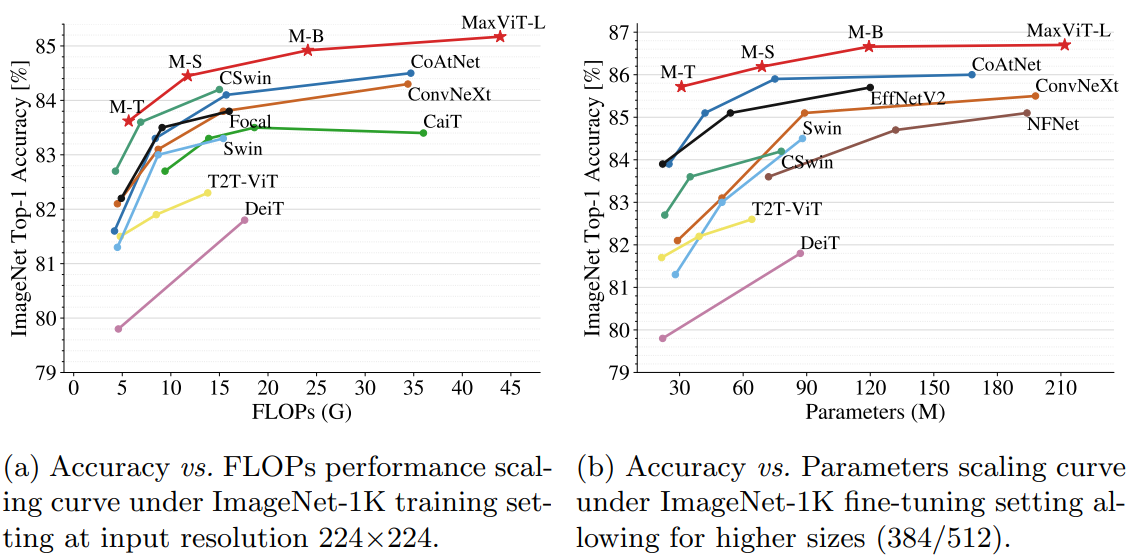
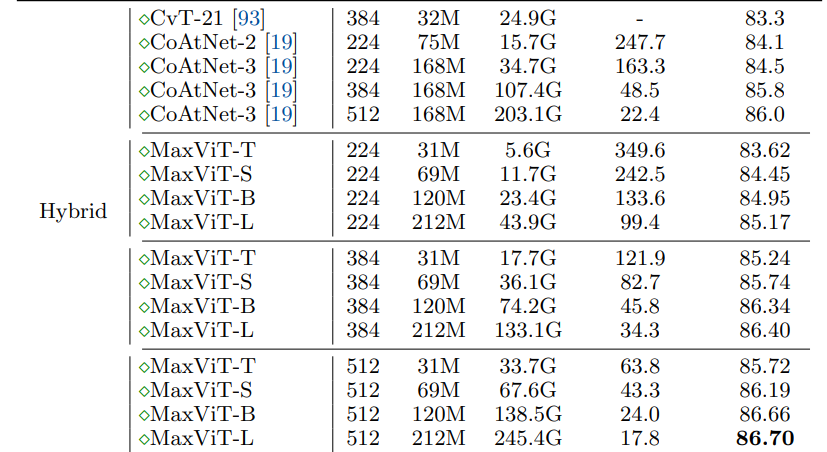
由于自注意力的机制对于图像大小方面缺乏可扩展性,限制了它们在视觉主干中的应用。本文提出了一种高效的可拓展的全局注意,该模型包括两个方面:阻塞的局部注意和拓展的全局注意。这些设计选择允许在任意输入分辨率上进行全局-局部空间交互,仅具有线性复杂度。作者通过将该注意模型与卷积有效结合,并简单的将这些模块堆叠,形成了了一个分层的视觉主干网络MaxVit。值得注意的是,MaxVit能在整个网络中看到全局甚至是在早期的高分辨率的阶段。在分类任务上,该模型在ImaegNet 1K上达到86.5%的 top-1准确率,在imageNet-21K上纪进行预训练,top-1准确率可以达到88.7%。
动机
研究发现,如果没有广泛的预训练,ViT在图像识别方面表现不佳。这是由于Transformer具有较强的建模能力,但是缺乏归纳偏置,从而导致过拟合。
一个有效的解决方法就是控制模型容量并提高其可扩展性,在参数量减少的同时得到性能的增强,如Twins、LocalViT以及Swin Transformer等。这些模型通常重新引入层次结构以弥补非局部性的损失,比如Swin Transformer通过在移位的非重叠窗口上应用自我注意。但在灵活性与可扩展性得到提高的同时,由于这些模型普遍失去了类似于ViT的非局部性,即具有有限的模型容量,导致无法在更大的数据集上扩展(ImageNet-21K、JFT等)。
综上,研究局部与全局相结合的方法来增加模型灵活性是有必要的。然而,如何实现对不同数据量的适应,如何有效结合局部与全局计算的优势成为本文要解决的目标。
本文设计了一种简单而有效的视觉骨干,称为多轴Transformer(MaxViT),它由Max-SA和卷积组成的重复块分层叠加。
- MaxViT是一个通用的Transformer结构,在每一个块内都可以实现局部与全局之间的空间交互,同时可适应不同分辨率的输入大小。
- Max-SA通过分解空间轴得到窗口注意力(Block attention)与网格注意力(Grid attention),将传统计算方法的二次复杂度降到线性复杂度。
- MBConv作为自注意力计算的补充,利用其固有的归纳偏差来提升模型的泛化能力,避免陷入过拟合。
MaxViT方法
本文引入了一种新的注意力模块——多轴自注意力(multi-axis self-attention, MaxSA),将传统的自注意机制分解为窗口注意力(Block attention)与网格注意力(Grid attention)两种稀疏形式,在不损失非局部性的情况下,将普通注意的二次复杂度降低到线性。由于Max-SA的灵活性和可伸缩性,我们可以通过简单地将Max-SA与MBConv在分层体系结构中叠加,从而构建一个称为MaxViT的视觉 Backbone,如图2所示。
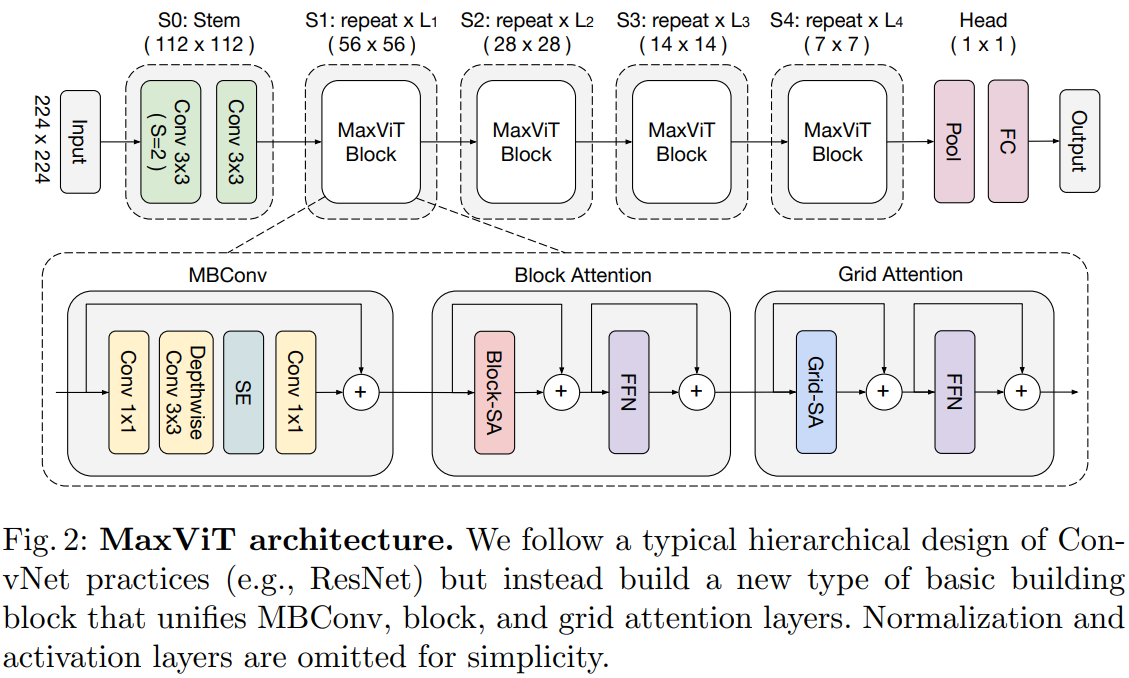
Multi-axis Attention
与局部卷积相比,全局相互作用是自注意力机制的优势之一。然而,直接将注意力应用于整个空间在计算上是不可行的,因为注意力算子需要二次复杂度,为了解决全局自注意力导致的二次复杂度,本文提出了一种多轴注意力的方法,通过分解空间轴得到局部(block attention)与全局(grid attention)两种稀疏形式。
Block attention
对于输入特征(H,W,C),先转化为张量以表示划分为不重叠窗口,其中每个窗口大小为p*p,最后在每个窗口执行计算自注意力。
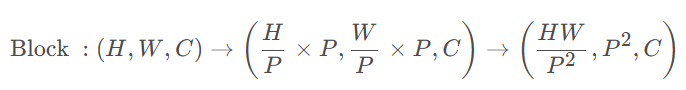
代码:
def block(x,window_size):
B,C,H,W = x.shape
x = x.reshape(B,C,H//window_size[0],window_size[0],W//window_size[1],window_size[1])
x = x.permute(0,2,4,1,3,5).contiguous()
return x
def unblock(x):
B,H,W,C,win_H,win_W = x.shape
x = x.permute(0,3,1,4,2,5).contiguous().reshape(B,C,H*win_W,H*win_W)
return x
class Window_Block(nn.Module):
def __init__(self, dim, block_size=(7,7), num_heads=8, mlp_ratio=4., qkv_bias=False,qk_scale=None, drop=0.,
attn_drop=0.,drop_path=0., act_layer=nn.GELU ,norm_layer=Channel_Layernorm):
super().__init__()
self.block_size = block_size
mlp_hidden_dim = int(dim * mlp_ratio)
self.norm1 = norm_layer(dim)
self.norm2 = norm_layer(dim)
self.mlp = Mlp(dim, mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.attn = Rel_Attention(dim, block_size, num_heads, qkv_bias, qk_scale, attn_drop, drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self,x):
assert x.shape[2]%self.block_size[0] == 0 & x.shape[3]%self.block_size[1] == 0, 'image size should be divisible by block_size'
# self.block_size = 7,也就是按照7×7大小的window划分。
out = block(self.norm1(x),self.block_size)
out = self.attn(out)
x = x + self.drop_path(unblock(self.attn(out)))
out = self.mlp(self.norm2(x))
x = x + self.drop_path(out)
return x
Grid attention
局部注意模型难适用于大规模的数据集。又提出一种稀疏的全局自注意力机制,grid attention(网格注意力机制)。
不同于传统使用固定窗口大小来划分特征图的操作,grid attention 使用固定的G × G ,均匀网格将输入张量网格化为, 此时 得到自适应大小的窗口
, 最后在G × G 上使用自注意力计算。需要注意, 通过使用相同的窗口p × p和网格G × G , 可以有效平衡局部和全局之间的计算 (且仅具有线性复杂度)。

注意:遵循Swin Transformer中窗口设置大小,P = G = 7 P=G=7P=G=7。本文提出的Max-SA模块可以直接替换Swin注意模块力,具有完全相同的参数和FLOPs数量。并且,它享有全局交互能力,而不需要 masking, padding, or cyclic-shifting,使其更易于实现,比移位窗口方案更可取。
代码:
class Grid_Block(nn.Module):
def __init__(self, dim, grid_size=(7,7), num_heads=8, mlp_ratio=4., qkv_bias=False,qk_scale=None, drop=0.,
attn_drop=0.,drop_path=0., act_layer=nn.GELU ,norm_layer=Channel_Layernorm):
super().__init__()
self.grid_size = grid_size
mlp_hidden_dim = int(dim * mlp_ratio)
self.norm1 = norm_layer(dim)
self.norm2 = norm_layer(dim)
self.mlp = Mlp(dim, mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.attn = Rel_Attention(dim, grid_size, num_heads, qkv_bias, qk_scale, attn_drop, drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self,x):
assert x.shape[2]%self.grid_size[0] == 0 & x.shape[3]%self.grid_size[1] == 0, 'image size should be divisible by grid_size'
grid_size = (x.shape[2]//self.grid_size[0], x.shape[3]//self.grid_size[1])
# grid_size 是网格窗口的数量,x.shape[2]//self.grid_size[0] = H // G。
out = block(self.norm1(x),grid_size)
out = out.permute(0,4,5,3,1,2).contiguous()
out = self.attn(out).permute(0,4,5,3,1,2).contiguous()
x = x + self.drop_path(unblock(out))
out = self.mlp(self.norm2(x))
x = x + self.drop_path(out)
return x
Multi-Axis attention与Axial attention区别:
不同于 Axial attention, 在 Axial attention 中 首先使用列注意力(column-wise attention),然后使用行注意力( row-wise attention) 来计算全局 注意力,相当于的计算复杂度,然而 Multi-Axis attention 则先采用局部注意力 (block attention), 再使用稀疏的全局注意力 (grid attention), 这样的 设计充分考虑了图像的 2D 结构,并且仅具有O(N)的线性复杂度。

MBConv
为了获得更丰富的特征表示,首先使用逐点卷积进行通道升维,在升维后的投影空间中进行Depth-wise卷积,紧随其后的SE用于增强重要通道的表征,最后再次使用逐点卷积恢复维度。可用如下公式表示:

对于每个阶段的第一个MBConv块,下采样是通过应用stride=2的深度可分离卷积( Depthwise Conv3x3)来完成的,而残差连接分支也 应用pooling 和 channel 映射:
![]()
MBConv有以下特点:
- 采用了Depthwise Convlution,因此相比于传统卷积,Depthwise Conv的参数能够大大减少;
- 采用了“倒瓶颈”的结构,也就是说在卷积过程中,特征经历了升维和降维两个步骤,并利用卷积固有的归纳偏置,在一定程度上提升模型的泛化能力与可训练性。
- 相比于ViT中的显式位置编码,在Multi-axis Attention则使用MBConv来代替,这是因为深度可分离卷积可被视为条件位置编码(CPE)。
网络架构和变体

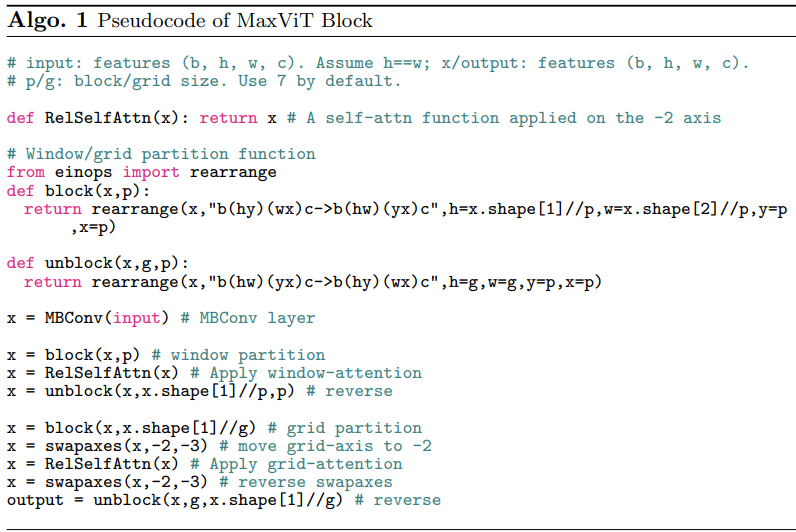
伪代码:

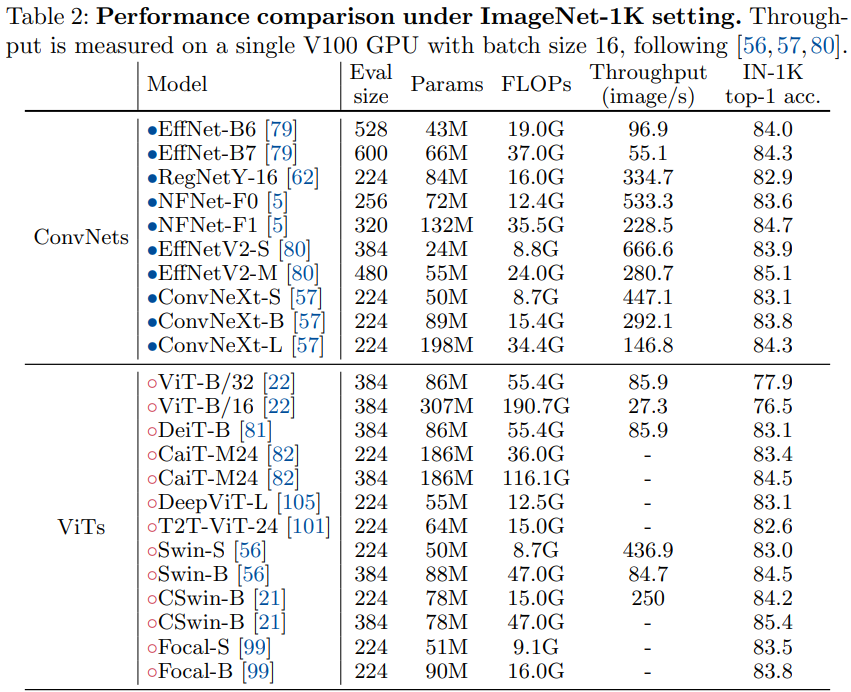
实验
UniFormer: Unifying Convolution and Self-attention for Visual Recognition, TPAMI2023
论文:https://arxiv.org/abs/2201.09450
代码:https://github.com/sense-x/uniformer
解读:【图像分类】2022-UniFormer IEEE_2022年图像分类外文文献_說詤榢的博客-CSDN博客
ICLR2022+TPAMI2023 UniFormer 卷积与自注意力的高效统一 - 知乎 (zhihu.com)
简介
对image和video上的representation learning而言,有两大痛点:
- local redundancy: 视觉数据在局部空间/时间/时空邻域具有相似性,这种局部性质容易引入大量低效的计算。
- global dependency: 要实现准确的识别,需要动态地将不同区域中的目标关联,建模长时依赖。
现有的两大主流模型CNN和ViT,往往只关注解决问题之一。convolution只在局部小邻域聚合上下文,天然地避免了冗余的全局计算,但受限的感受野难以建模全局依赖。而self-attention通过比较全局相似度,自然将长距离目标关联,但ViT在浅层编码局部特征十分低效(如下图所示)。

在ViT的浅层,都仅会倾向于关注query token的邻近token。要知道attention矩阵是通过全局token相似度计算得到的,这无疑带来了大量不必要的计算。相较而言,convolution在提取这些浅层特征时,无论是在效果上还是计算量上都具有显著的优势。
本文提出 UniFormer (Unified transFormer),便旨在以Transformer的风格,有机地统一convolution和self-attention,发挥二者的优势,同时解决local redundancy和global dependency两大问题,实现高效的特征学习。效果显著。
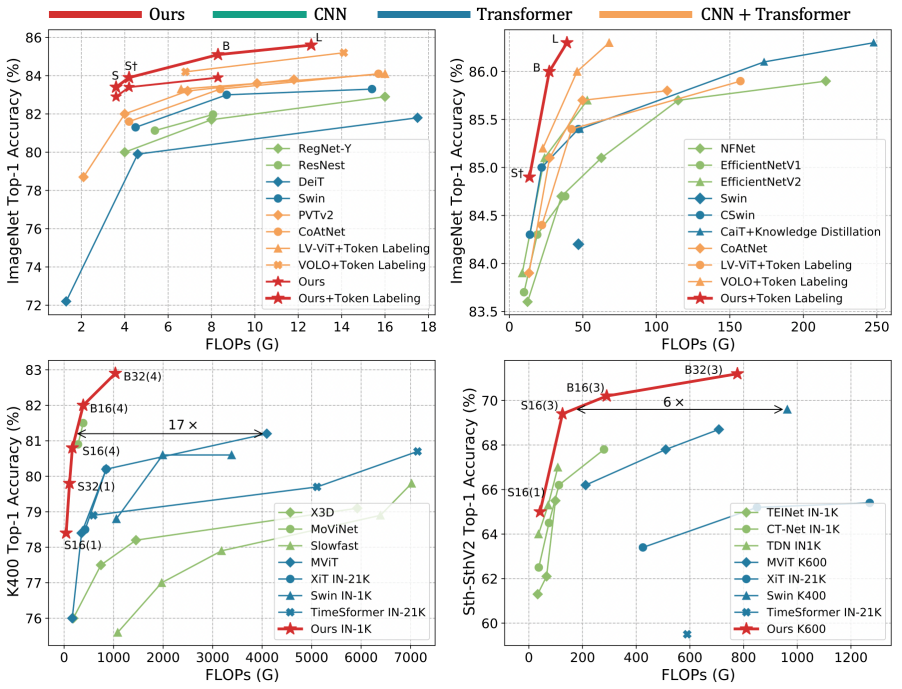

UniFormer方法
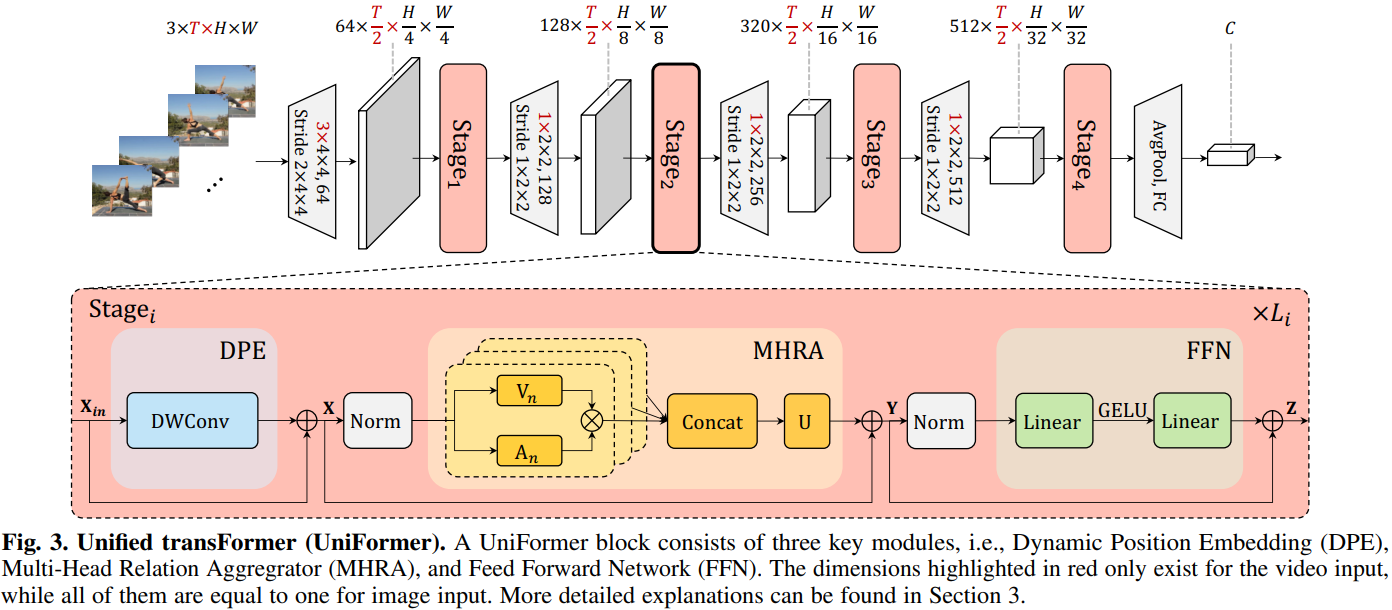
模型整体框架如上所示,借鉴了CNN的层次化设计,每层包含多个Transformer风格的UniFormer block。每个UniFormer block主要由三部分组成,动态位置编码DPE、多头关系聚合器MHRA)及Transformer必备的前馈层FFN。

MHRA

与多头注意力相似,将关系聚合器设计为多头风格,每个头单独处理一组channel的信息。每组的channel先通过线性变换生成上下文token ,然后在token affinity
的作用下,对上下文进行有机聚合。
Local MHRA
在网络的浅层,token affinity应该仅关注局部邻域上下文,这与convolution的设计不谋而合。将局部关系聚合设计为可学的参数矩阵:
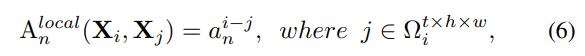
其中 为anchor token,
为局部邻域
任一token,
为可学参数矩阵,
为二者相对位置,表明token affinity的值只与相对位置有关。
Global MHRA
在网络的深层,需要对整个特征空间建立长时关系,这与self-attention的思想一致,因此通过比较全局上下文相似度建立token affinity:
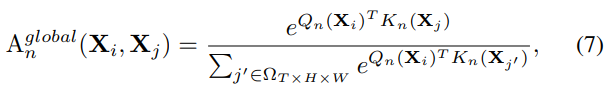
UniFormer在网络的浅层采用local MHRA节省了冗余计算量,使得网络在深层可以轻松使用联合时空注意力,从而可以得到更具辨别性的特征表达。
Dynamic Position Embedding
ViT往往采用绝对或者相对位置编码,但绝对位置编码在面对更大分辨率的输入时,需要进行线性插值以及额外的参数微调,而相对位置编码对self-attention的形式进行了修改。为了适配不同分辨率输入的需要,论文采用了卷积位置编码设计动态位置编码:
![]()
其中DWConv为零填充的的深度可分离卷积。
- 卷积对任何输入形式都很友好,也很容易拓展到空间维度统一编码时空位置信息。
- 深度可分离卷积十分轻量,额外的零填充可以帮助每个token确定自己的绝对位置。
网络架构

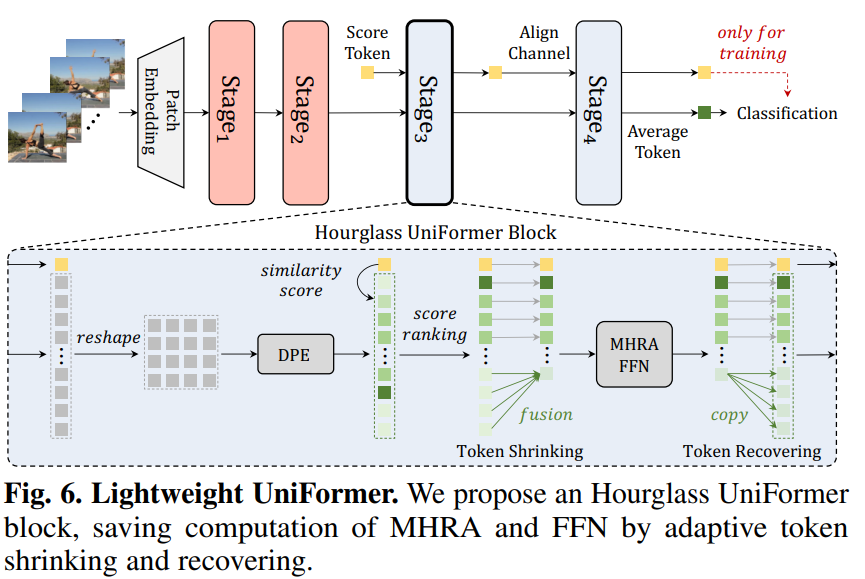
轻量化的UniFormer
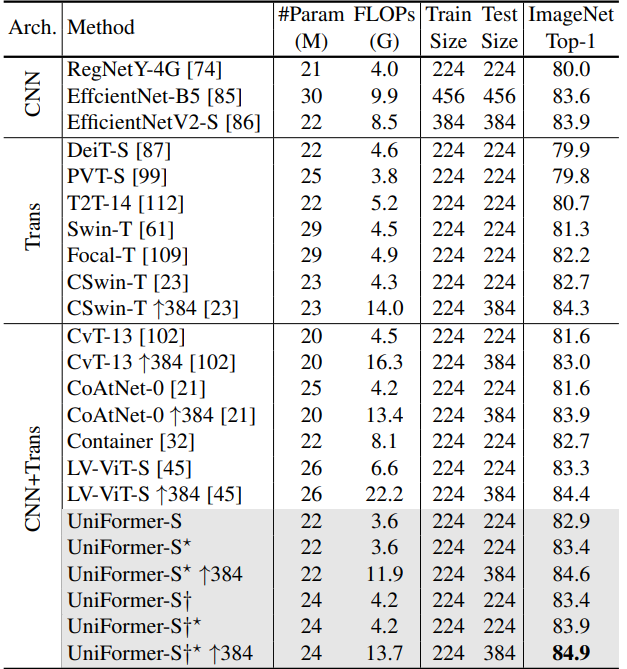
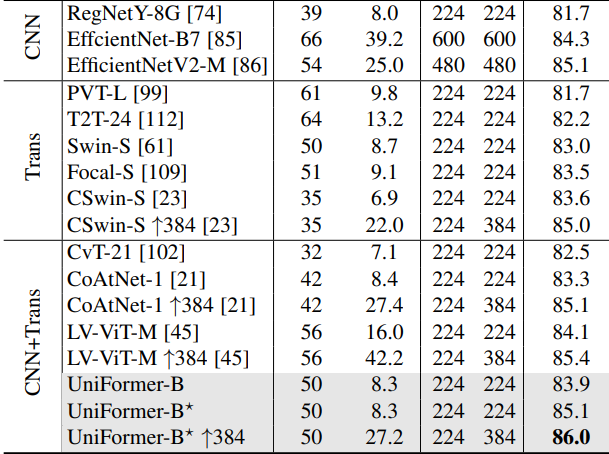
实验
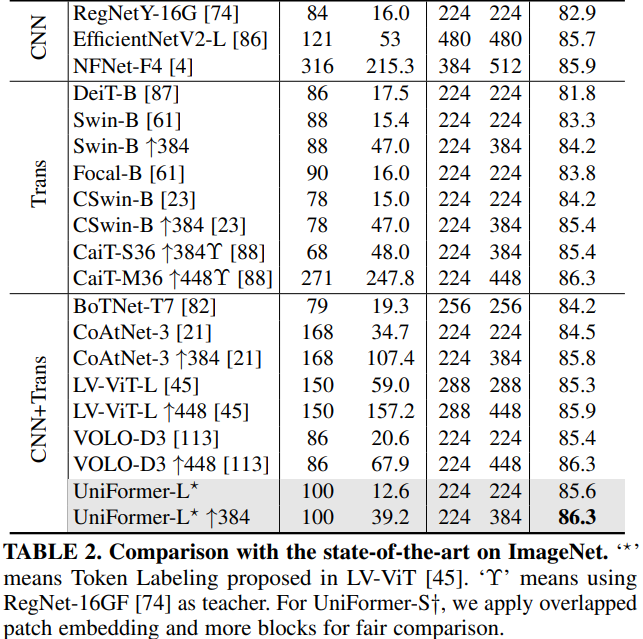
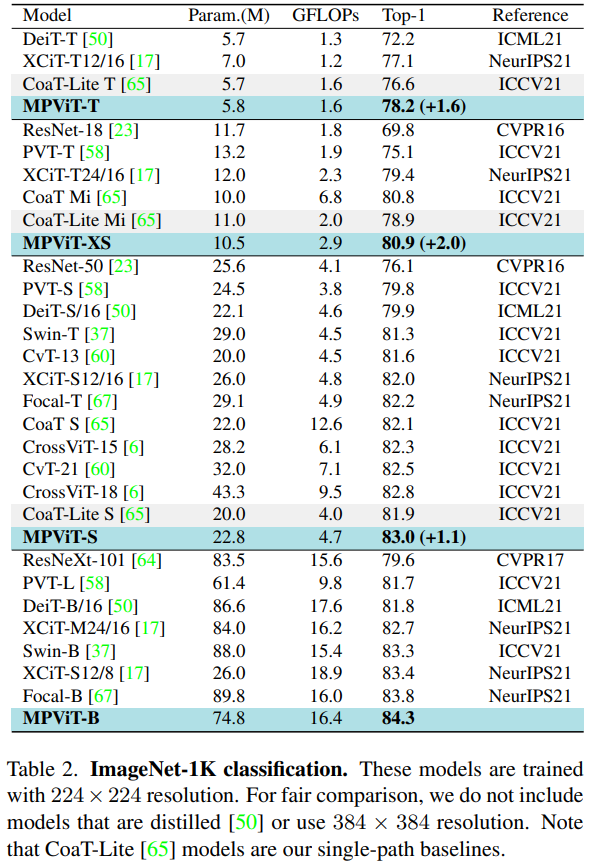
MPViT: Multi-Path Vision Transformer for Dense Prediction, CVPR2022
论文:https://arxiv.org/abs/2112.11010
代码:https://github.com/youngwanLEE/MPViT
解读:【图像分类】2022-MPViT CVPR_cvpr 2022图片分类_說詤榢的博客-CSDN博客
【CVPR2022】MPViT : Multi-Path Vision Transformer for Dense Prediction - 知乎 (zhihu.com)
简介
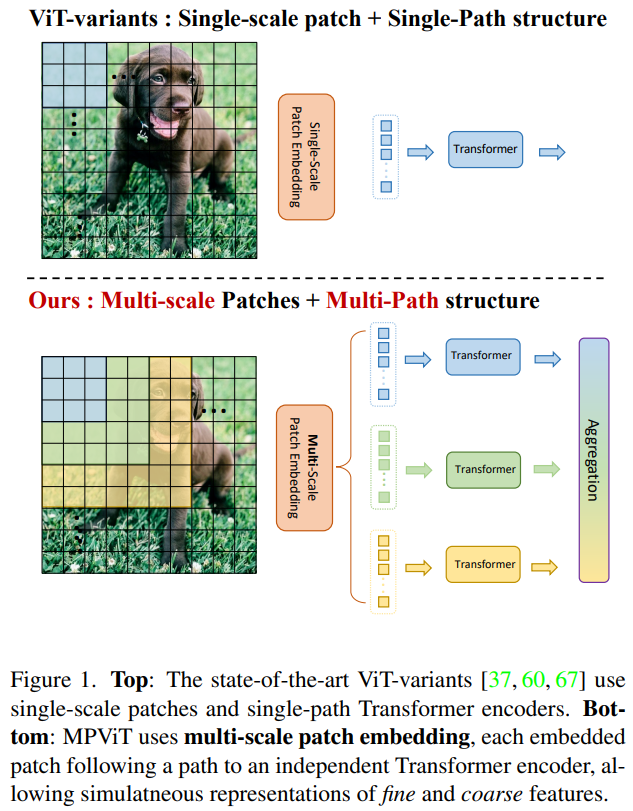
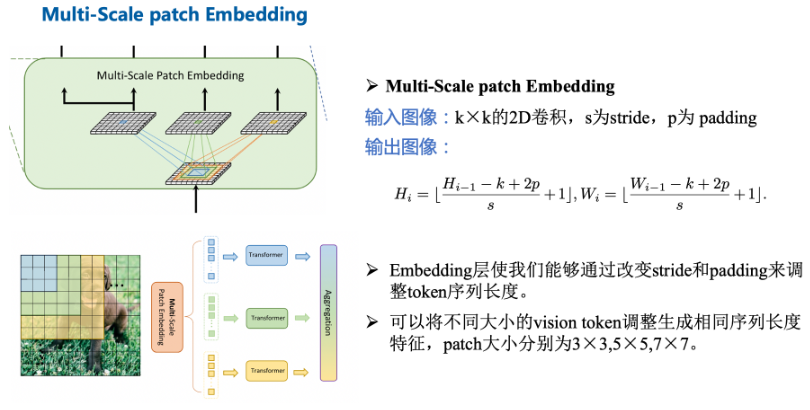
这项工作以不同于现有Transformer的视角,探索多尺度path embedding与multi-path结构,提出了Multi-path Vision Transformer(MPViT)。
- 通过使用 overlapping convolutional patch embedding,MPViT同时嵌入相同大小的patch特征。然后,将不同尺度的Token通过多条路径独立地输入Transformer encoders,并对生成的特征进行聚合,从而在同一特征级别上实现精细和粗糙的特征表示。
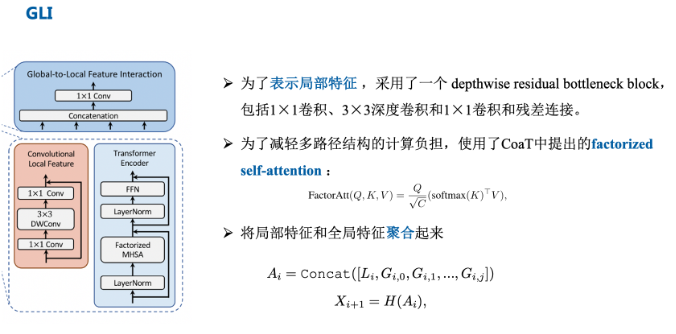
- 在特征聚合步骤中,引入了一个global-to-local feature interaction(GLI)过程,该过程将卷积局部特征与Transformer的全局特征连接起来,同时利用了卷积的局部连通性和Transformer的全局上下文。
因此本文作者将重点放在了图像的多尺度多路径上,通过对图片不同尺度分块及其构成的多路径结构,提升了图像分割中Transformer的精确程度。
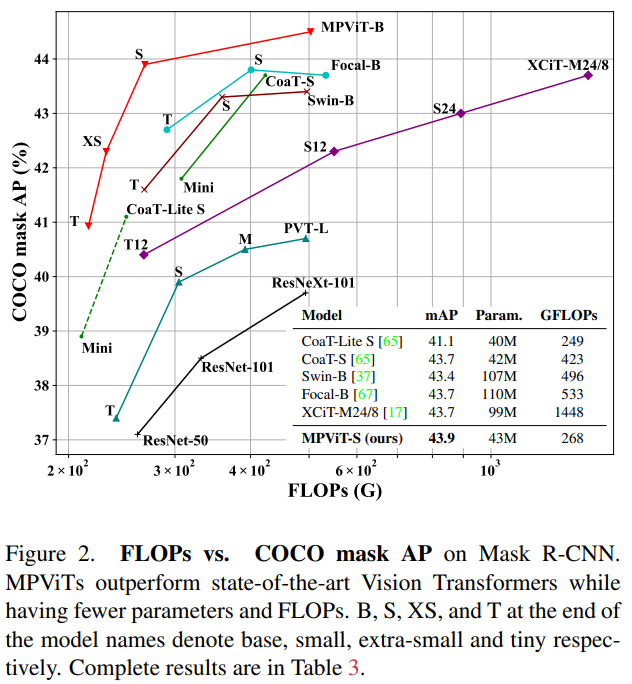
本文有三个贡献:
- 提出了一个具有多路径结构的多尺度嵌入方法,用于同时表示密集预测任务的精细和粗糙特征。
- 提出了全局到本地特征交互(GLI),同时利用卷积的局部连通性和Transformer的全局上下文来表示特征。
- 性能优于最先进的vit,同时有更少的参数和运算次数。
MPViT方法
首先利用Conv-stem对输入图像做卷积提取特征;再依次经过四个MS-PatchEmbed 和 MP-Transformer Block,逐层减小特征尺度,最后实现分类。
最先进的ViT使用单尺度的patch embedding和单路径transformer编码器
- MPViT通过重叠卷积将相同大小的特征和不同大小的patch的同时嵌入。
- 将多尺度patch嵌入,通过重叠卷积将其拉平成为不同尺寸的token,在适当调整卷积的填充/步幅后产生具有相同序列长度的特征。
- 然后,来自不同尺度的token被通过多条路径独立并行送到Transformer编码器中,执行全局自我关注。
- 然后聚合生成的特征,从而在相同的特征级别上实现精细和粗略的特征表示。
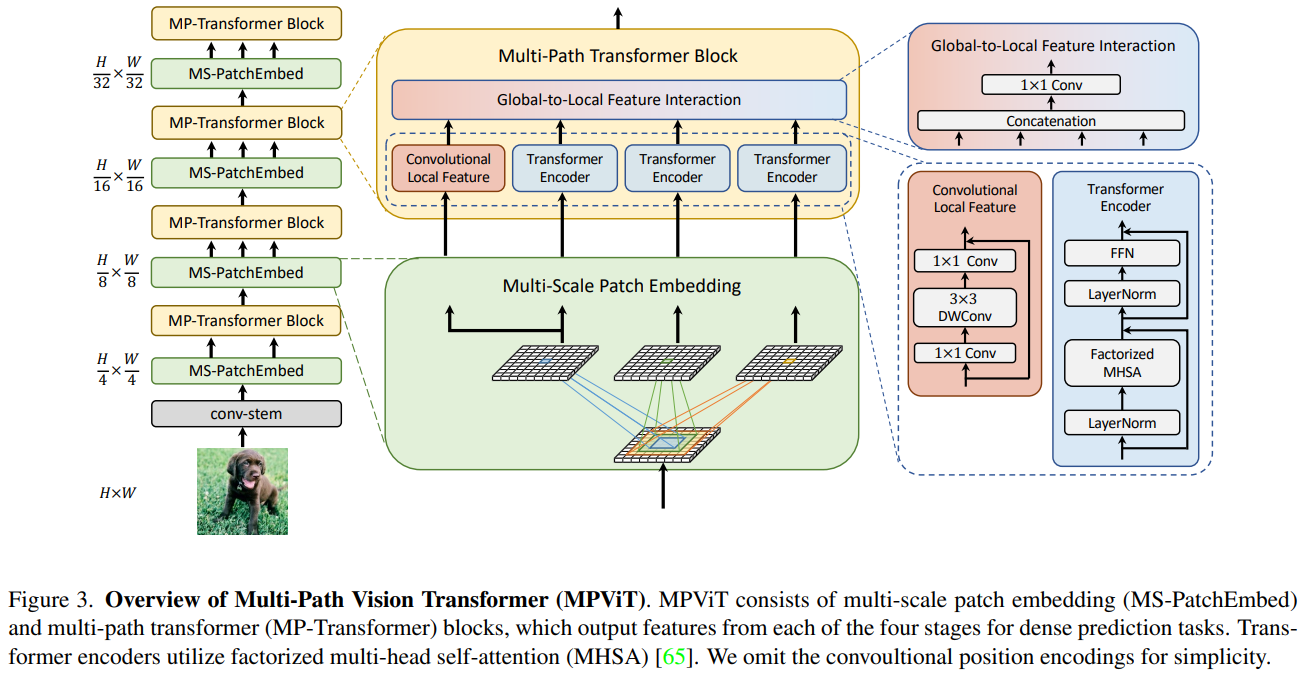
Multi-Scale Patch Embedding:
使用3*3卷积构成不同大小的感受野来得到不同尺度的特征信息。
- 由于堆叠同尺寸卷积可以提升感受野且具有更少的参数量,选择两个连续的3×3卷积层构建5×5感受野,采用三个3×3卷积构建7×7感受野。
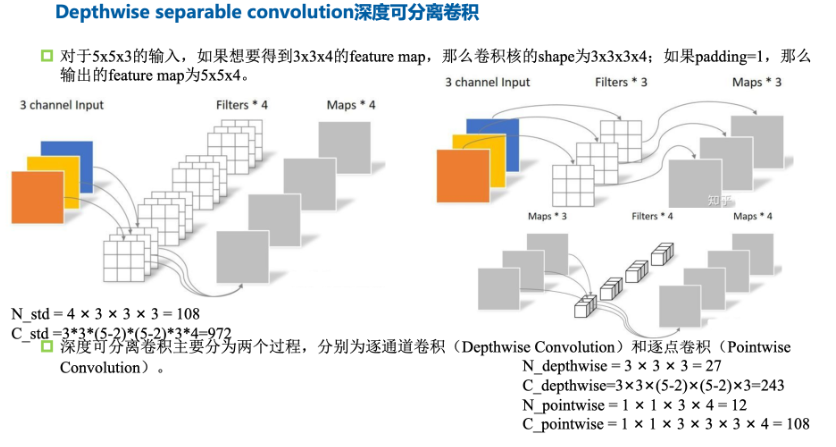
- 为了减少模型参数和计算开销,采用3×3深度可分离卷积,包括3×3深度卷积和1×1点卷积。
- 每个卷积之后都是Batch Normalization 和一个Hardswish激活函数。
接着,不同大小的token embedding features 分别输入到transformer encoder中。
Multi-path Transformer:
- Transformer中的self-attention可以捕获长期依赖关系(即全局上下文),但它很可能会忽略每个patch中的结构性信息和局部关系。
- 相反,cnn可以利用平移不变性中的局部连通性,使得CNN在对视觉对象进行分类时,对纹理有更强的依赖性,而不是形状。
因此,MPViT以一种互补的方式将CNN与Transformer结合起来。
在多路径的特征进行自注意力(局部卷积)计算以及全局上下文信息交互后,所有特征会做一个Concat经过激活函数后进入下一阶段。
Transformer可以关注到较远距离的相关性,CNN能更好地对图像的局部上下文特征进行提取,论文进行互补。
Transformer: 由于每个图像块内作者都使用了自注意力,并且存在多个路径,因此为了减小计算压力,作者使用了CoaT中提出的有效的因素分解自注意(将复杂度降低为线性)
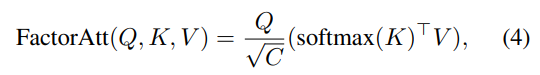
CNN: 为了表示局部特征 L,采用了一个 depthwise residual bottleneck block,包括1×1卷积、3×3深度卷积和1×1卷积和残差连接。在三个Transformer模块的左侧存在一个卷积操作,其实就是通过卷积的局部性,将图像的局部上下文引入模型中,多了这些上下文信息可以弥补Transformer对于局部语义理解的不足。
Global-to-Local Feature Interaction
将局部特征和全局特征聚合起来:通过串联来执行。
对输入特征做了一个Concat并进行了1×1卷积,该模块同时输入了存在远距离关注的Transformer以及提取局部上下文关系的卷积操作,因此可以认为就是对本阶段提取到的图像全局以及局部语义的特征融合,充分利用了图像的信息。

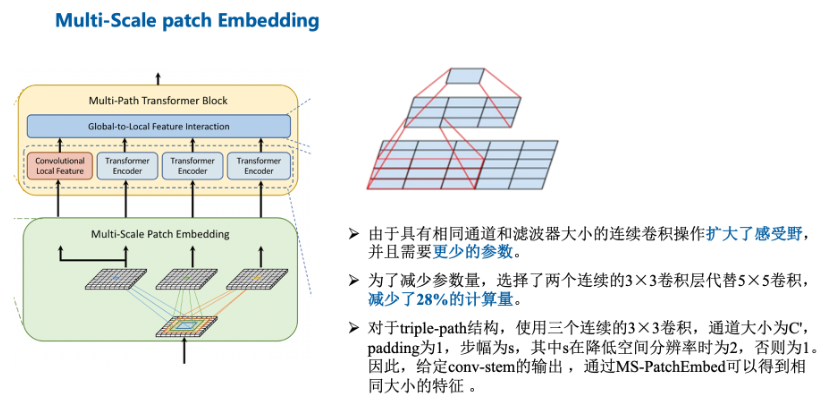

网络架构

实验