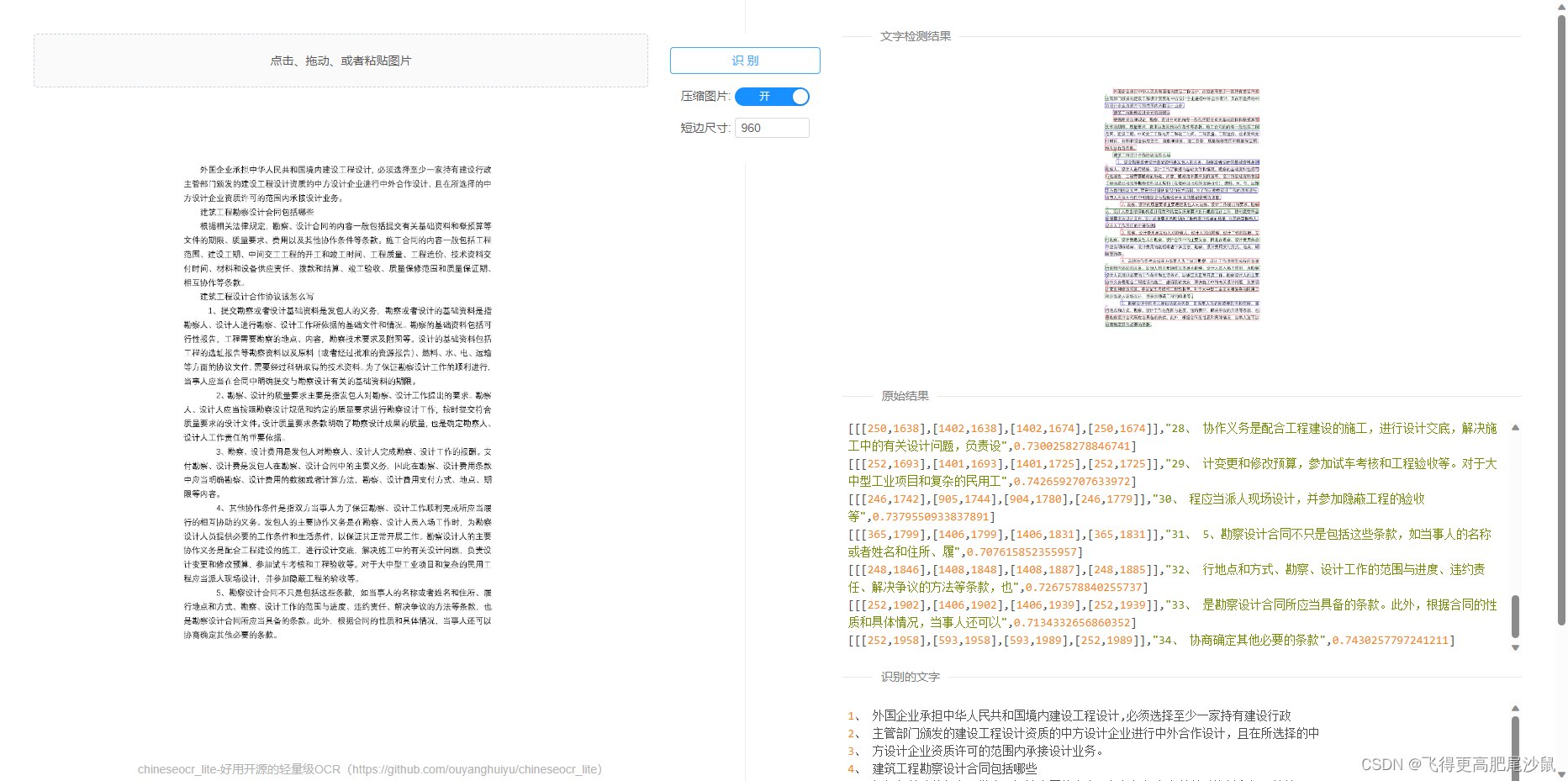
使用python部署chineseocr_lite
- 简介
- 安装
- 报错解决
- python调用
- 结果
简介
项目地址:https://github.com/DayBreak-u/chineseocr_lite
chineseocr_lite 是一个开源项目,用来实现中文的文字识别,支持竖排文字识别、繁体识别,总模型只有几M,无需联网,支持 CPU 与 GPU
安装
pip install -r requirements.txt
然后
cd chineseocr_lite ## 进入chineseocr目录
python backend/main.py
报错解决
提示:error: metadata-generation-failed
这个项目使用的numpy和opencv都是较低版本或特定版本的,如果之前某个环境安装过所需的依赖,再次安装就会报错
错误提示
Preparing metadata (pyproject.toml) did not run successfully
Encountered error while generating package metadata.
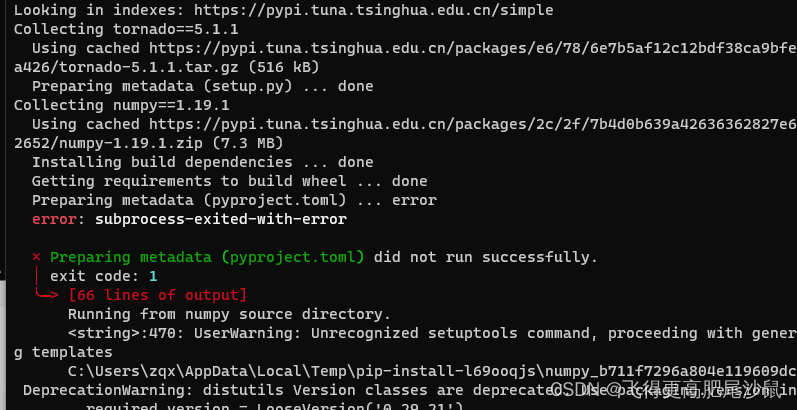
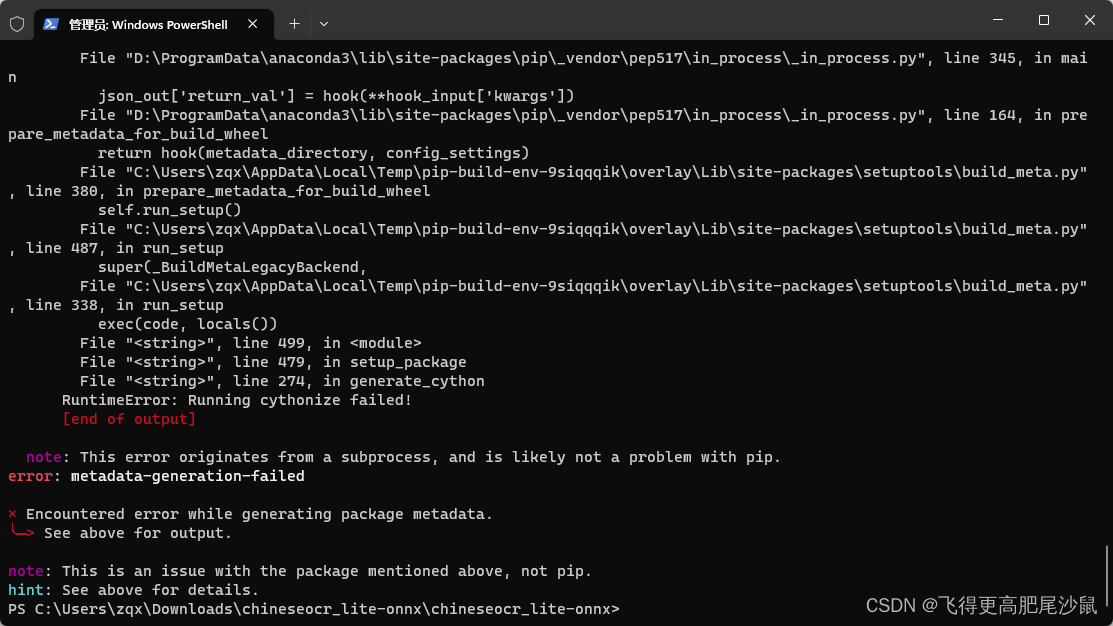
创建虚拟环境,然后使用下面的requirements.txt文件安装依赖
tornado==5.1.1
numpy==1.19.1
opencv_python==4.2.0.34
onnxruntime==1.4.0
Shapely==2.0.1
pyclipper==1.2.0
Pillow==9.5.0
python调用
# 使用python backend/main.py启动服务后
import base64
import requests
# 使用python backend/main.py启动服务后
def get_text1(img_path):
# 方式1:直接传递file文件
with open(img_path, 'rb') as f:
file = f.read()
body_data = {
'compress': 960
}
img_file = {
'file': file
}
result = requests.post('http://127.0.0.1:8089/api/tr-run/', files=img_file, params=body_data)
print(result.json())
def get_text2(img_path):
# 方式2:将文件放到data中传递, 该方式传递jpg文件时可能报错
with open(img_path, 'rb') as f:
file = f.read()
body_data = {
'img': str(base64.b64encode(file), 'utf-8'),
'compress': 960
}
result = requests.post('http://127.0.0.1:8089/api/tr-run/', data=body_data)
print(result.json())
if __name__ == '__main__':
file_path = r'123.jpg'
get_text1(file_path)
get_text2(file_path)
结果