论文链接:https://openreview.net/pdf?id=ylMq8MBnAp
代码链接:GitHub - joffery/TRO: The Pytorch implementation for "Topology-aware Robust Optimization for Out-of-Distribution Generalization" (ICLR 2023)
01. 研究背景
近年来,机器学习(ML)被广泛应用在高风险和安全关键型应用中。这类应用提出了前所未有的“分布外(OOD)泛化挑战”:ML模型不断接触到训练空间之外的未知分布。尽管在“内插”问题上取得了巨大的成功,但现代ML模型(如深度神经网络)在“外推”问题上非常薄弱;即使平均准确性很高的模型在面对罕见或未知分布时也可能发生灾难性失败。例如,针对美国2000年至2020年间所有89次重大洪水事件进行训练的洪水预测模型,会错误地对2021年的“飓风艾达”事件进行预测。如果不解决这个挑战,模型的应用场景及其相关风险将变得不清楚。
一种解决分布外泛化问题的有效方法是进行分布鲁棒优化(DRO)[1]。DRO通过构建一个“不确定性集合”以最小化潜在测试分布的“最坏”(worst-case)预期风险。这个不确定性集合通常被构造为一个围绕训练集的散度球。与最小化平均风险的方法(ERM)相比,DRO对来自虚假相关性、对抗攻击、子群体或自然变化等因素引起的“分布漂移”更具有鲁棒性[2]。
然而,构建一个能够真正近似未知分布的不确定性集合来是一个非常具有挑战性的任务。
一方面,为了对抗广泛的分布漂移,不确定性集合必须足够大,这增加了包含不可信分布(例如异常值)的风险,从而导致过于悲观的模型和低预测置信度[3]。
另一方面,最坏分布不一定是与未知分布真正相关的“有影响力的分布”;优化最坏分布而不是有影响力的分布会牺牲模型的鲁棒性。
02. 方法介绍
因为模型不可能泛化到任意的未知分布,我们假设数据分布的拓扑结构对构建真实的“不确定性集合”至关重要。更具体地说,我们提出了一种整合两个优化目标的拓扑感知鲁棒优化(TRO)方法:
-
拓扑学习:我们将数据分布建模为位于共同低维流形上的多个离散组,通过使用物理先验或测量分布之间的多尺度推土距离(EMD)来“探索”分布拓扑。
-
拓扑上的学习:然后,利用获得的分布拓扑来构建一个真实的不确定性集合,其中鲁棒优化将泛化风险限制在拓扑图中,而不是盲目地泛化到未知分布上。
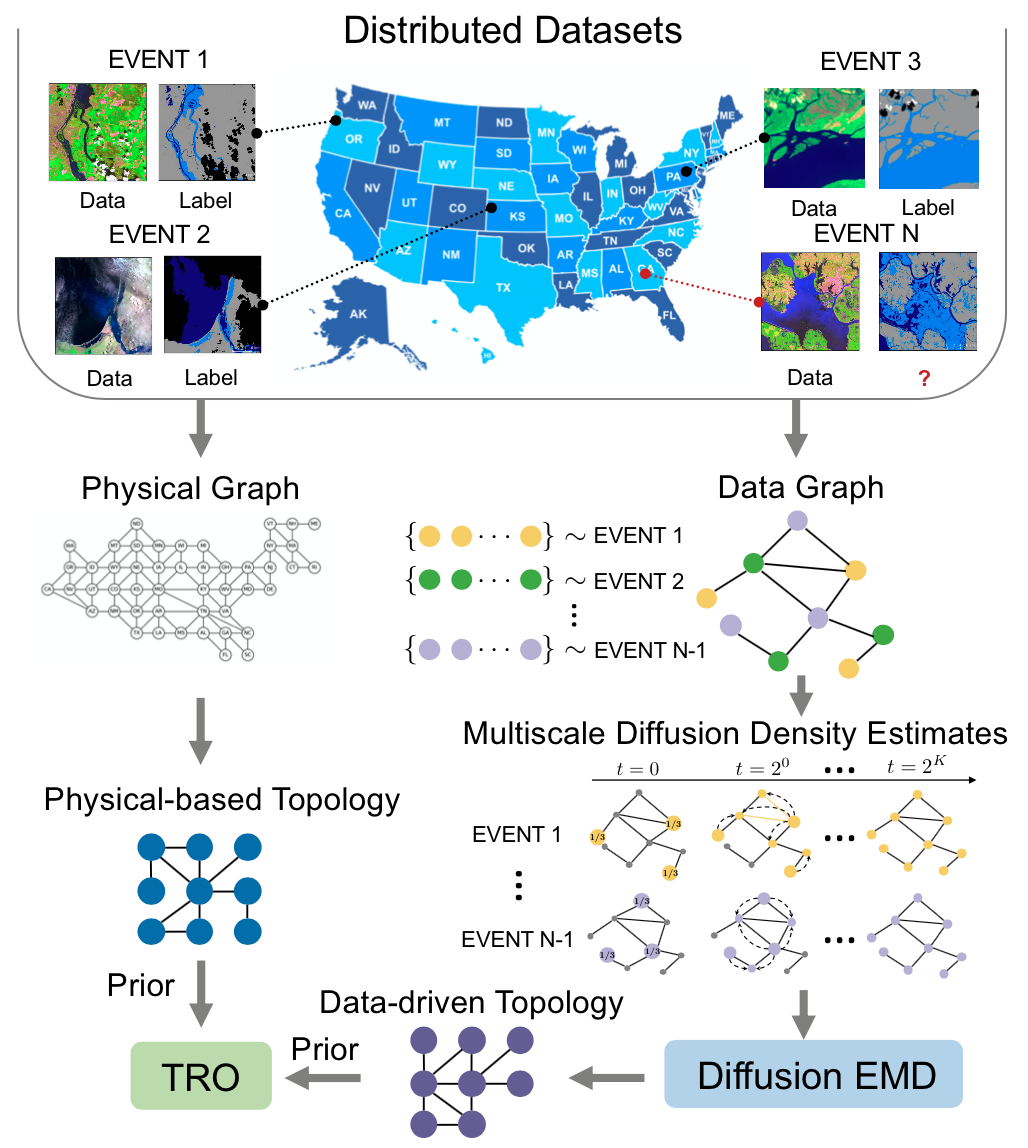
2.1 拓扑学习:探索分布拓扑

2.2 拓扑上的学习:利用拓扑进行鲁棒优化

03. 实验结果
我们在广泛的任务中对TRO进行了评估,包括分类、回归和语义分割。
我们将TRO与最先进的基准模型进行了OOD泛化性能的比较,并对TRO的关键组成部分进行了消融研究。
3.1 气温预测
数据集。TPT-48[7] 包含了美国48个相邻州从2008年到2019年的月平均温度数据。
我们专注于回归任务,根据前6个月的温度预测接下来6个月的温度。我们考虑了两个泛化任务:
-
E(24) →→ W(24):我们将24个东部州作为训练组,24个西部州作为测试组;
-
N(24) →→ S(24):我们将24个北部州作为训练组,24个南部州作为测试组。
与最近的训练组相距一条边的测试组定义为Hop-1测试组,相距两条边的测试组定义为Hop-2测试组,其余组定义为Hop-3 测试组。
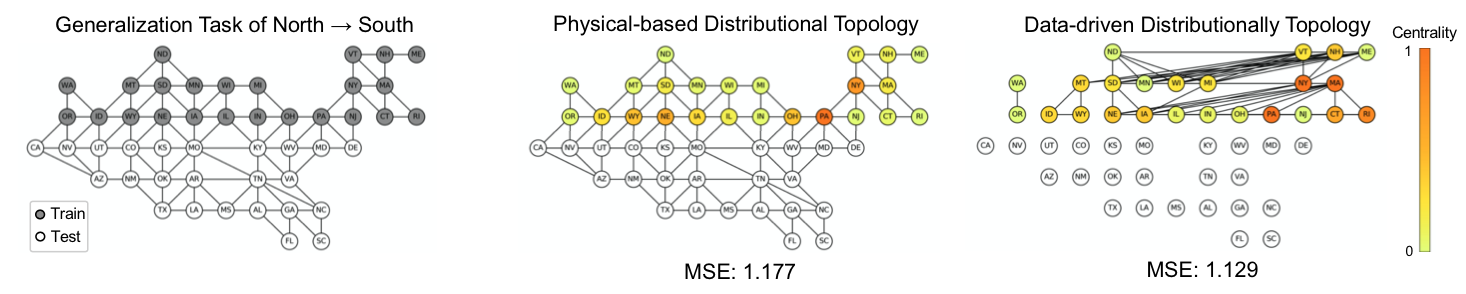
TPT-48数据集上的N(24) →→ S(24)的可视化结果如图 2 (左) 所示。
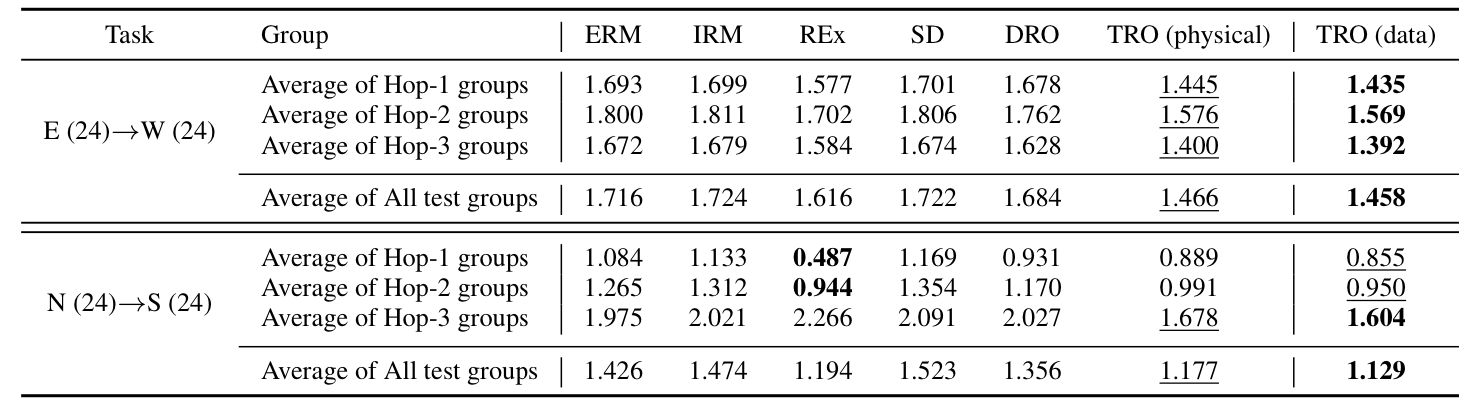
结果。我们在上表中展示了TPT-48的结果。
TRO在两个任务中均获得了最低的平均均方误差(MSE)。我们还报告了两个任务中Hop-1、Hop-2和Hop-3测试组的平均均方误差。尽管在N(24) →→ S(24)任务中,REx在Hop-1和Hop-2组上的误差最低,但在Hop-3组上的预测误差最高。
结果表明,REx在面对较大的分布漂移时可能会产生性能上的妥协。TRO在Hop-3组上表现出最佳性能,表明它在面对较大的分布漂移时具有强大的泛化能力。
3.2 洪水分割
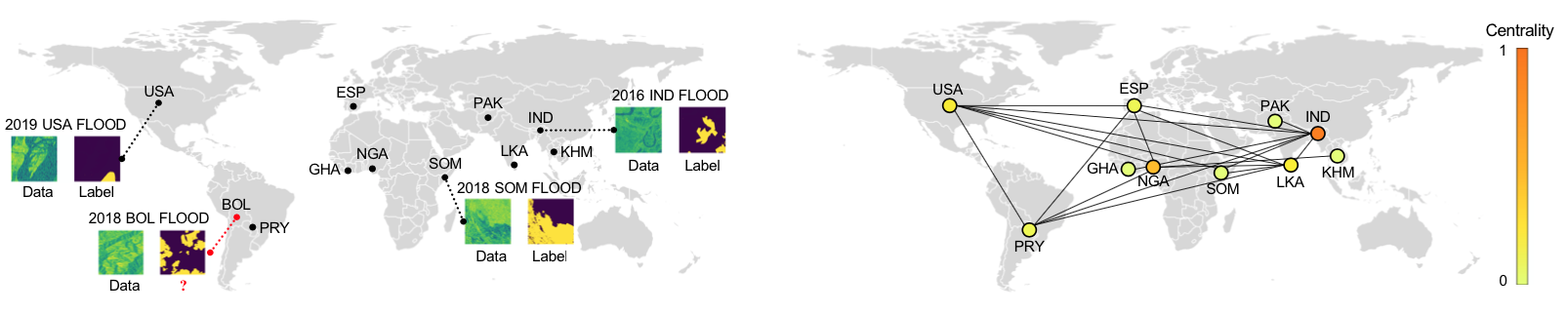
数据集。Sen1Floods11[8] 是一个用于全球洪水映射的公共数据集。
该数据集提供了全球范围内的4,831个512 x 512的分辨率为10米的卫星图像,涵盖了11个不同的洪水事件,总共覆盖了120,406平方千米的区域。每个图像都附带有像素级的标签。11个洪水事件的位置如图 3(左)所示。
不同的洪水事件在边界条件、地形和其他潜在因素上存在变化,对现有模型的可靠性和可解释性提出了显著的OOD挑战。
按照[8]的约定,事件“BOL”被保留作为测试集,其他事件的数据随机划分为训练集和验证集,比例为80%和20%。
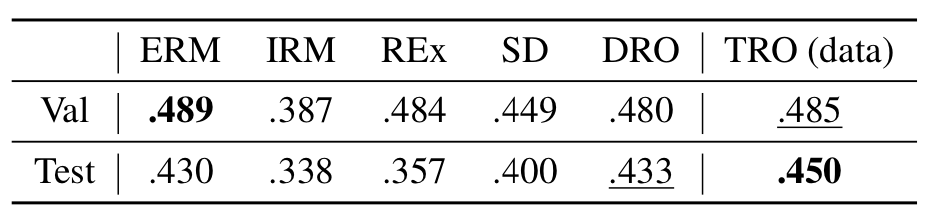
结果。我们在上表中展示了Sen1Floods11的结果。
ERM在验证集上获得了最高的Intersection over Union (IoU),而TRO在测试集上获得了最高的IoU。
结果证明,TRO在未见的洪水事件上比其他基准模型表现出更好的性能。
04. 结语
我们的贡献包括:
-
一种新的优化方法,通过无缝地集成拓扑信息,以增强模型的分布外(OOD)泛化性能。
-
理论分析证明我们的方法在凸和非凸损失函数下都具有快速收敛性,同时对泛化风险进行了严格的界定。
-
在包括分类、回归和语义分割在内的广泛任务中的实验结果证明我们的方法相对于SOTA具有更优越的性能。
-
数据驱动的分布拓扑与领域知识一致,并增强了模型的可解释性。
参考文献
[1] Namkoong et al. Stochastic gradient methods for distributionally robust optimization with f-divergences. NeurIPS 2016
[2] Robey et al. Model-based domain generalization. NeurIPS 2021
[3] Hu et al. Does distributionally robust supervised learning give robust classifiers? ICML 2018
[4] Leeb et al. Hölder–lipschitz norms and their duals on spaces with semigroups, with applications to earth mover’s distance. Journal of Fourier Analysis and Applications, 2016
[5] Tong et al. Diffusion earth mover’s distance and distribution embeddings. ICML 2021
[6] Newman. A measure of betweenness centrality based on random walks. Social networks, 2005
[7] Xu et al. Graph-relational domain adaptation. ICLR 2022
[8] Bonafilia et al. Sen1floods11: A georefer- enced dataset to train and test deep learning flood algorithms for sentinel-1. CVPR Workshops, 2020
招生信息
特拉华大学(University of Delaware)计算机系(Computer and Information Sciences) 招收2024 Spring/Fall全奖博士生.
研究方向:
- Robust and Explainable DL;
- Human-centered Computer Vision.
导师:彭曦(Dr. Xi Peng, Assistant Professor)
关于实验室:
我们持续在顶会发表工作包括NeurIPS, ICLR, CVPR, ICCV, ECCV, KDD, AAAI, IJCAI;近些年入学的几位同学已经在CVPR’20-23,AAAI’21,TPAMI’22,ICLR’23,ICCV’23 发表一作论文并且荣获 NeurIPS’21 Workshop Best Paper Award;我们与北美多家工业界实验室合作紧密可推荐优秀学生前往暑期实习Google Research, Snap Research, Amazon AWS, IBM Watson Research.更多信息:Deep-REAL
邮件: xipeng@udel.edu
邮箱主题/简历命名格式:博士申请+姓名
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。期待这里可以成为你学习Al前沿知识的高地,分享自己最新工作的沃士,在AI进阶之路上的升级打怪的根据地!更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区








![[洛谷]P2052 [NOI2011] 道路修建(dfs)](https://img-blog.csdnimg.cn/080fcbbd57134cc8ada7cce6263ab774.png)