参考官网
Apache Hive integration | Elasticsearch for Apache Hadoop [7.17] | Elastic
官网的介绍很简单,我看了很多博客,写的也很简单,但是我搞了半天才勉强成功,分享下,免得各位多走弯路。
环境准备
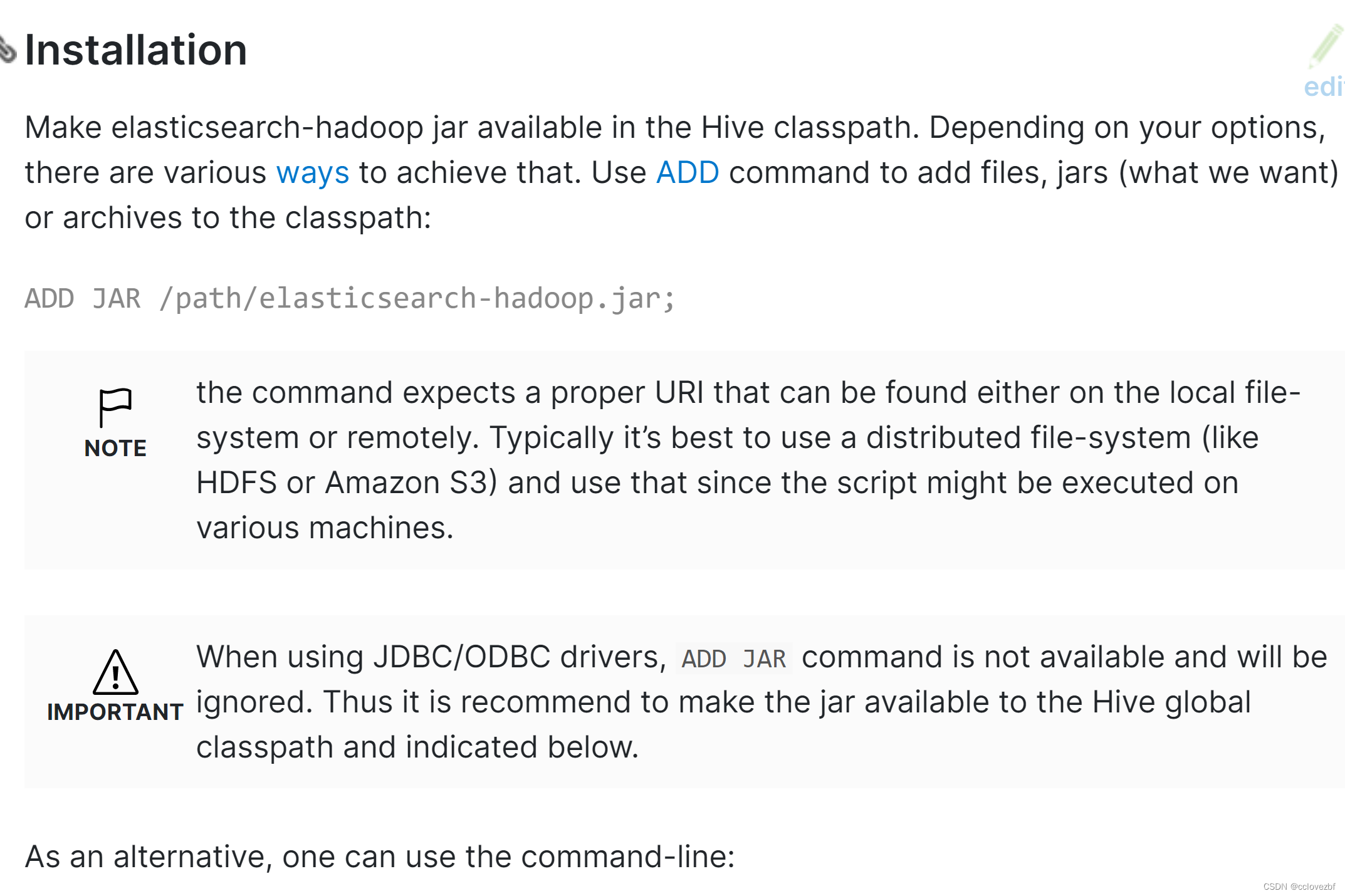

官网也很贴心的给了几种方式。
1.$ bin/hive --auxpath=/path/elasticsearch-hadoop.jar
2.$ bin/hive -hiveconf hive.aux.jars.path=/path/elasticsearch-hadoop.jar
3.修改hive-site.xml
看似方法很多 其实有问题,首先我们现在都是beeline模式登录,bin/hive已经被废弃了。那么beeline能用吗?貌似可以用 第1和第2基本上是一样的
网上还有一种办法 直接把jar上传到这个目录/opt/cloudera/parcels/CDH/lib/hive/auxlib/ auxlib很明显就是上面的变量

beeline -u "jdbc:hive2://cdp-node02:2181,cdp-node03:2181,cdp-node04:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2" -hiveconf hive.aux.jars.path=/path/elasticsearch-hadoop.jar
发现还是没有读取到jar 算了吧

第3种貌似是最好的,但是要动集群配置很麻烦,
于是只有用最简单的方式add jar,注意这个只是当前会话有效;
下载jar包
这个时候有小伙伴会问了 这个jar怎么来的,我看官网好像也没给例子呀。
通过maven,新建一个工程,记住这个工程还有用的
网上看到还有可以直接在服务器wget的。。
<dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch-hadoop</artifactId> <version>7.14.2</version> </dependency>对了低版本的es可能没有个http-client的jar
<dependency>
<groupId>commons-httpclient</groupId>
<artifactId>commons-httpclient</artifactId>
<version>3.1</version>
</dependency>
通过maven把这个jar下下来 ,然后再上传到服务,记住改下es.version

添加到hdfs
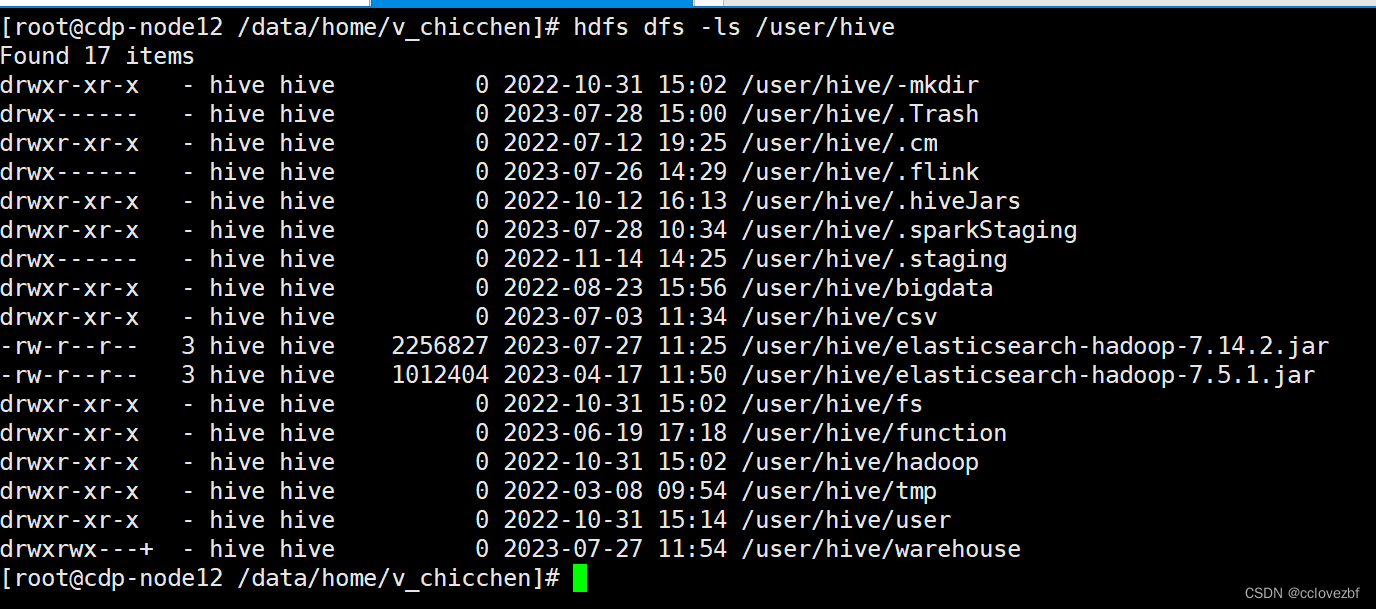 进入beeline add jar
进入beeline add jar
add jar hdfs:///user/hive/elasticsearch-hadoop-7.5.1.jar;
add jar hdfs:///user/hive/commons-httpclient-3.1.jar;
或者
add jar hdfs:///user/hive/elasticsearch-hadoop-7.14.2.jar;
list jar 可以看是否添加成功
至此 我们的hive已经有了这个jar。
开始建表
官网很多demo,肯定找最简单的来。
参考配置

但是此时我又有问题了。这个demo 明显不对,es的地址都没有啊。
Configuration | Elasticsearch for Apache Hadoop [7.17] | Elastic
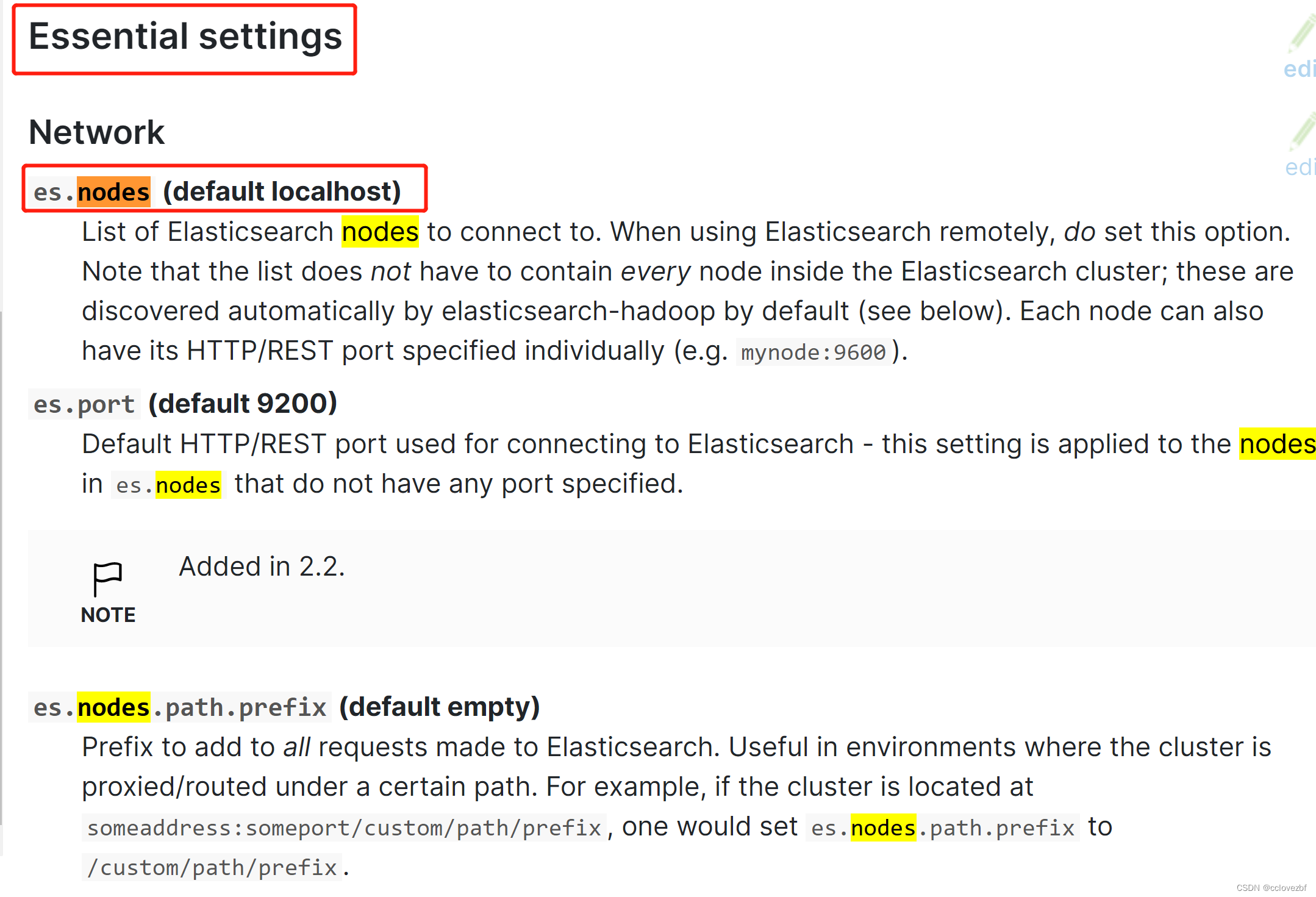

这里提到了essential 和required看来都是必须的,还有写defalut的就不说了。
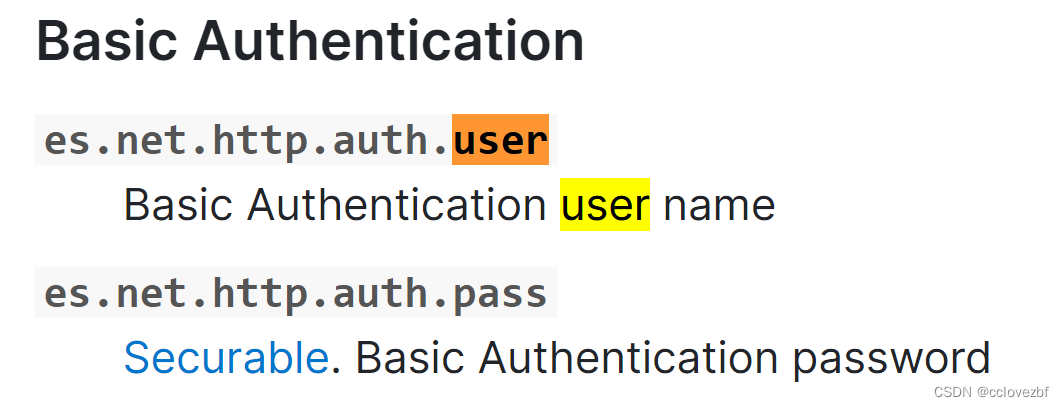
用户认证
因为我的es还有认证所以需要输入用户密码继续在配置里找参数
create external table esdata.cc_test2
(id string ,name string ,des string )
STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler'
TBLPROPERTIES(
'es.net.http.auth.user'='s2_elastic_enterprise',
'es.net.http.auth.pass'='s2@enterprise' ,
'es.nodes'='9.134.161.140', --连接地址
'es.resource' = 'i_dw_cc_test' ) --es7的时候没有type了,这里不需要写type
至此参考了了很多人的文章,感觉也差不多了。结果还是有问题。
报错1
先说一个问题。建好表后,insert into的时候报错了

我已经认证了,为什么这里还是报权限错误呢?我这个用户在es是可以查和插入这个index的数据的 确定以及肯定。
分析报错原因,查看源码,这里就提到刚刚那个工程了。
搜索RestClient.getHttpNodes

这个熟不熟悉。这个不就是kibana的get请求么,我在es试了确实没权限,要组长帮忙开通这个权限后,这个错就解决了。
报错2
接着建表。然后又出错了!!!!!!
先给大家看下代码 注意这个node =9.134.161.140

连接 正常。我hive建表的es.node也是这个地址

但是当我执行select count(1) from cc_test;时报错了。
Error: Error while compiling statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.tez.TezTask. Vertex failed, vertexName=Map 1, vertexId=vertex_1690006488152_0865_1_00, diagnostics=[Vertex vertex_1690006488152_0865_1_00 [Map 1] killed/failed due to:ROOT_INPUT_INIT_FAILURE, Vertex Input: cc_test initializer failed, vertex=vertex_1690006488152_0865_1_00 [Map 1], org.elasticsearch.hadoop.rest.EsHadoopInvalidRequest: [GET] on [_nodes/http] failed; server[9.10.132.27:9200] returned [403|Forbidden:]
--注意这里9.10.132.27 怎么这是个啥ip。
at org.elasticsearch.hadoop.rest.RestClient.checkResponse(RestClient.java:486)
at org.elasticsearch.hadoop.rest.RestClient.execute(RestClient.java:443)
at org.elasticsearch.hadoop.rest.RestClient.execute(RestClient.java:437)
at org.elasticsearch.hadoop.rest.RestClient.execute(RestClient.java:397)
at org.elasticsearch.hadoop.rest.RestClient.execute(RestClient.java:401)
at org.elasticsearch.hadoop.rest.RestClient.get(RestClient.java:177)
at org.elasticsearch.hadoop.rest.RestClient.getHttpNodes(RestClient.java:134)
at org.elasticsearch.hadoop.rest.RestClient.getHttpDataNodes(RestClient.java:151)
at org.elasticsearch.hadoop.rest.InitializationUtils.filterNonDataNodesIfNeeded(InitializationUtils.java:157)
因为es不是我搭建的,所以我也很难搞。但是没关系,我刚刚不是java客户端连接上了吗? 我根据客户端查下, 其实上面的那张图片也说明了这个问题,就是怎么连接到DATANODE了呢?

添加参数
无奈,继续查找参数。

es.nodes.ingest.only (default false) -- 这个感觉也有用懒得试了。
es.nodes.wan.only (default false) --反正是加了这个参数就好了。其中过程复杂就不说了。
简单的理解,我们最开始写的地址没有错,但是es这个家伙会发现其他节点的ip,然后用其他ip去连,你这个为true了就只能用我写的那个了
成功案例
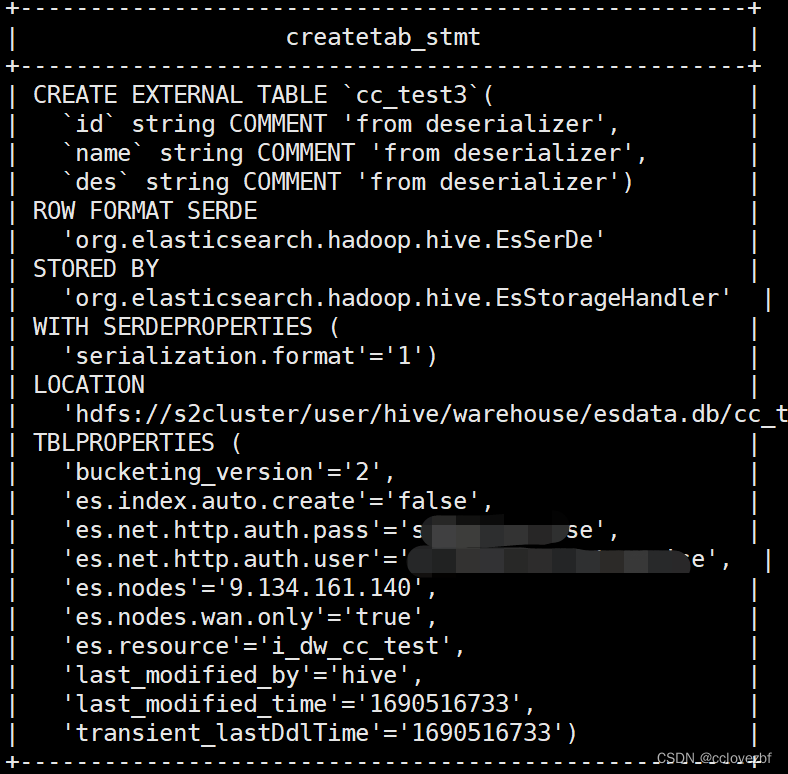
最后的建表语句
create external table esdata.cc_test3
(id string ,name string ,des string )
STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler'
TBLPROPERTIES(
'es.net.http.auth.user'='xxxx',
'es.net.http.auth.pass'='xxxx' ,
'es.nodes'='9.134.161.140',
'es.nodes.wan.only'='true',
'es.resource' = 'i_dw_cc_test',
'es.index.auto.create' = 'false');
count

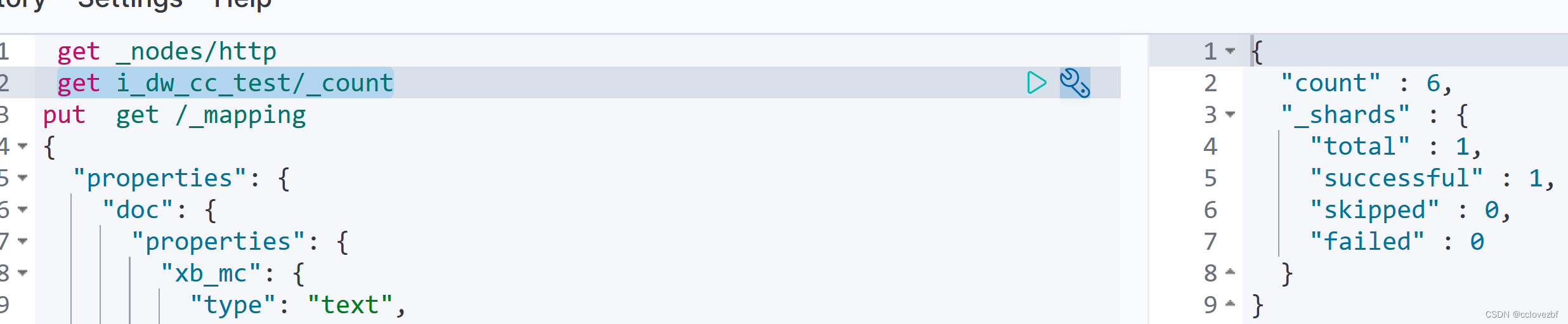
group

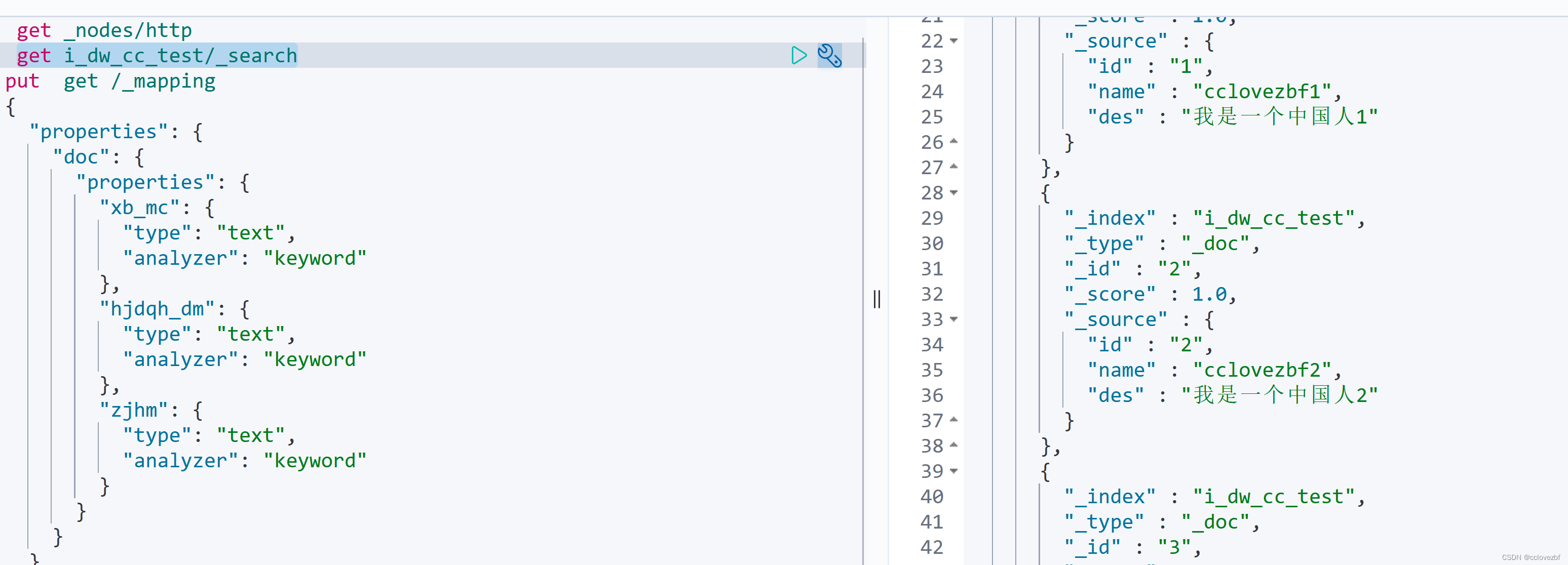 insert
insert

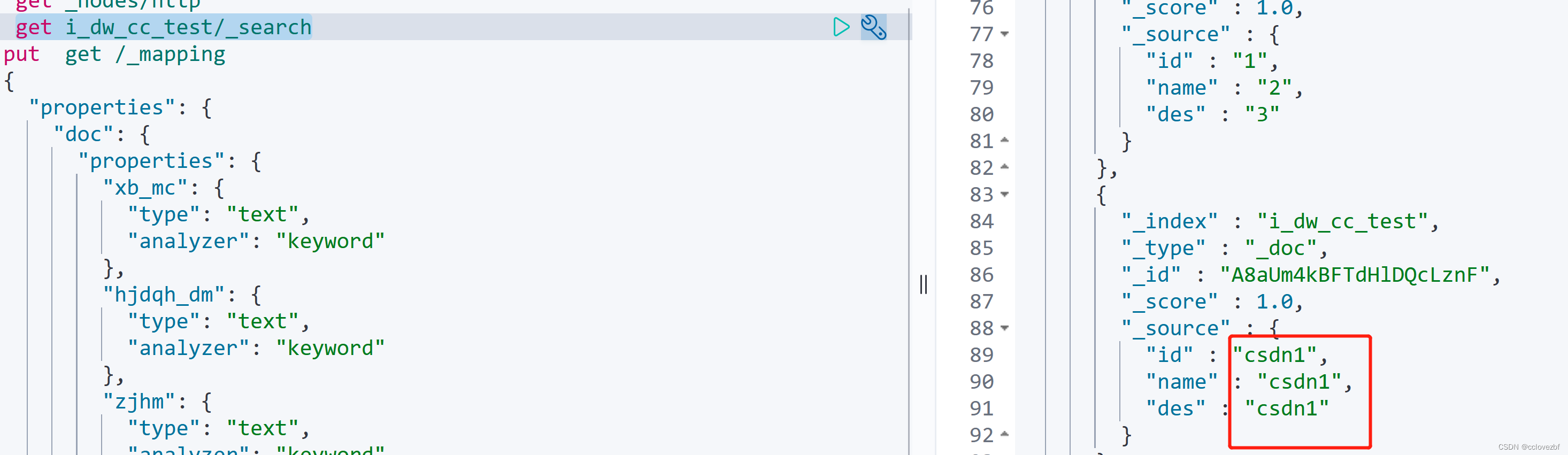
遗留问题
以为到这里就大功告成了吗? 我遇到了一个最大的问题。。。。一直没说
就是我不能select * 。 上面的那个查询是可以select id,name from t group by id,name
但是tm的就是不能直接select *!!!!!!!!!!!!!!
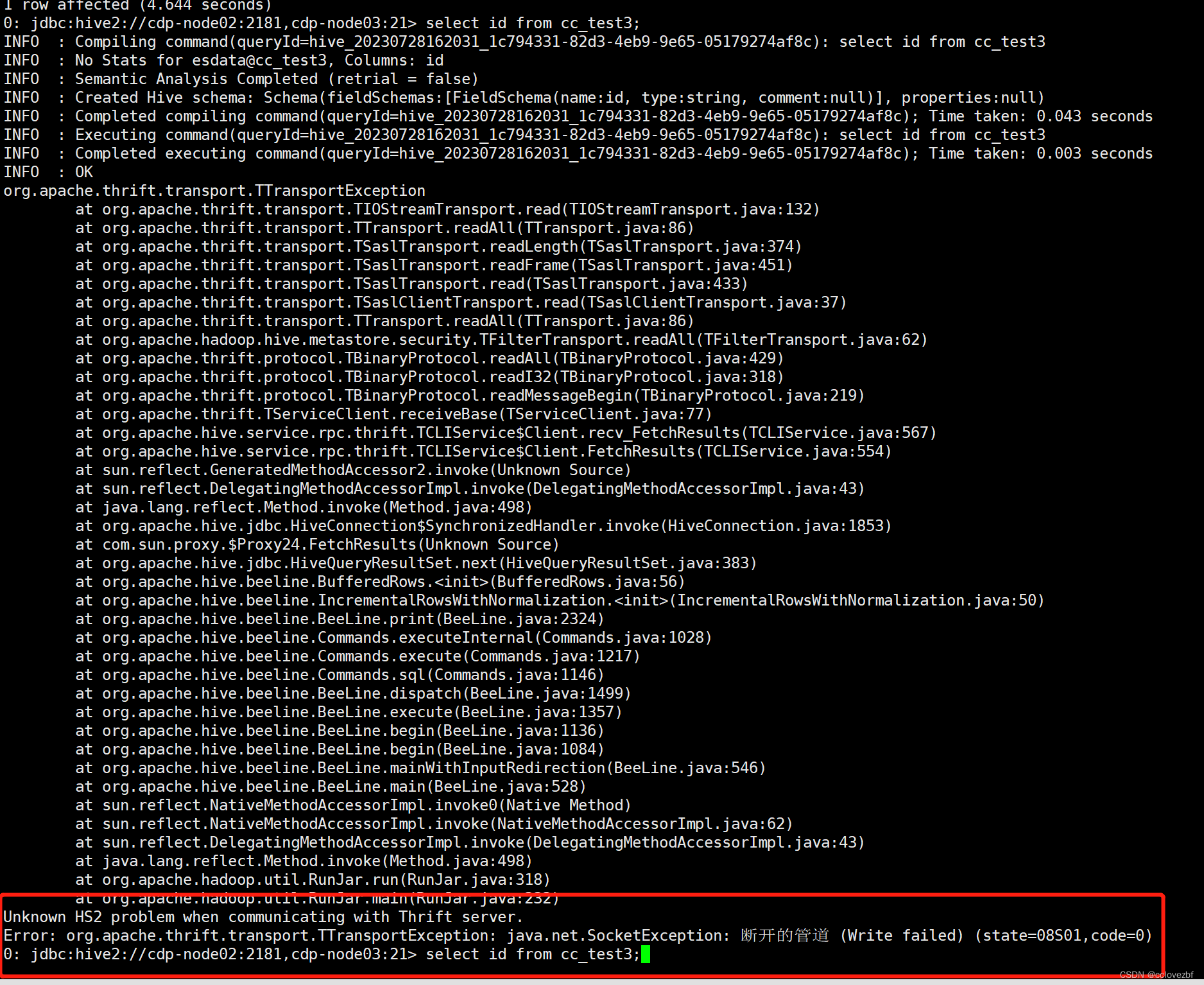
关键是这个报错我连错误日志都看不懂,感觉就是连接hive出错了。但是select 其他都是正常呀。。 等待研究。。。。