论文链接:https://arxiv.org/abs/2206.14718
代码链接:GitHub - HUANGLIZI/LViT: This repo is the official implementation of "LViT: Language meets Vision Transformer in Medical Image Segmentation" (IEEE Transactions on Medical Imaging/TMI)
摘要
深度学习在医学图像分割等方面得到了广泛的应用。然而,现有医学图像分割模型的性能一直受到数据标注成本过高而无法获得足够高质量标记数据的挑战的限制。为了缓解这一限制,我们提出了一种新的文本增强医学图像分割模型LViT (Language meets Vision Transformer)。在我们的LViT模型中,医学文本注释被纳入以弥补图像数据的质量缺陷。此外,在半监督学习中,文本信息可以引导生成质量提高的伪标签。我们还提出了一种指数伪标签迭代机制(EPI)来帮助像素级注意模块(PLAM)在半监督LViT设置下保持局部图像特征。在我们的模型中,LV (Language-Vision)损失被设计用来直接使用文本信息监督未标记图像的训练。为了评估,我们构建了包含x射线和CT图像的三个多模态医学分割数据集(图像+文本)。实验结果表明,本文提出的LViT在全监督和半监督环境下都具有较好的分割性能。
背景
1)与自然图像不同,医学图像中不同区域之间的边界往往是模糊的,边界附近的灰度值差很小,很难提取出高精度的分割边界。高质量的医学图像数据难以获取,而医学文本记录数据与图像数据具有天然的互补性,因此文本信息可以弥补医学图像数据的质量不足。
2)为了解决标注不足的数据问题,一些方法已经超越了传统的监督学习,通过使用标记和更广泛可用的未标记数据来训练模型,例如半监督学习[5],[8]和弱监督学习[9]。但是学习效果非常依赖于伪标签质量。
贡献
1)如何利用已有的图像-文本信息提高分割性能;
sol:我们提出了LViT模型(图1(b)),它在处理图像和文本方面具有创新性。在LViT中,使用嵌入层代替文本编码器获得文本特征向量,可以减少模型中参数的数量。此外,具有像素级注意模块(PLAM)的混合CNNTransformer结构能够更好地合并文本信息,并在保留CNN的局部特征的同时使用Transformer编码全局特征
2)如何充分利用文本信息,保证伪标签的质量。
sol:我们设计了一种指数伪标签迭代机制(Exponential Pseudo label Iteration mechanism, EPI),旨在交叉利用标记数据的标签信息和未标记数据的潜在信息。EPI间接结合文本信息,以指数移动平均线(EMA)的方式逐步完善伪标签[10]。此外,LV (Language-Vision) loss的设计目的是直接利用文本信息来监督未标记医学图像的训练。为了验证LViT的性能,我们构建了包含CT图像(MosMedData+[11],[12]和ESO-CT)和x射线(QaTa-COV19[13])的三个多模态医学图像分割数据集。结果表明,LViT具有较好的分割性能,在MosMedData+数据集上的Dice得分为74.57%,mIoU为61.33%;在QaTa-COV19数据集上的Dice得分为83.66%,mIoU为75.11%;在ESO-CT数据集上的Dice得分为71.53%,mIoU为59.94%。值得注意的是,使用1/4的训练集标签的LViT仍然可以具有与全监督分割方法相同的性能。
相关工作
医学图像的语义分割
1. FCN
2. UNet
3. UNet++
视觉语言模型
1. Clip
2. ViLT,它允许利用交互层的力量来处理视觉特征,而不需要单独的深度视觉嵌入器。是一种纯Transformer模型,没有卷积和区域监督来提取局部特征,不适合边界模糊的医学图像分割。
3. VLT, 视觉语言转换器VLT框架通过促进多模态信息之间的深度交互,融合语言和视觉特征来实现参考分割。
4. LAVT, Aware Vision Transformer 框架采用了早期的融合方案,通过像素字注意机制将语言特征集成到视觉特征中,可以有效地利用Transformer编码器对多模态上下文建模
LViT:只利用嵌入层进行文本特征的变换,需要的参数更少,计算成本更低。此外,混合CNN-Transformer可以同时获得全局与局部特征
注意力机制
1. RAN
2. CBAM
LViT:我们提出PLAM,通过自我关注来弥补对局部特征关注的不足。它还有助于卷积层产生更有效的局部特征表示。为了解决高计算量的问题,我们使用统一的编码器来编码视觉和语言特征,而不是使用单独的编码器。
方法
LViT 模型
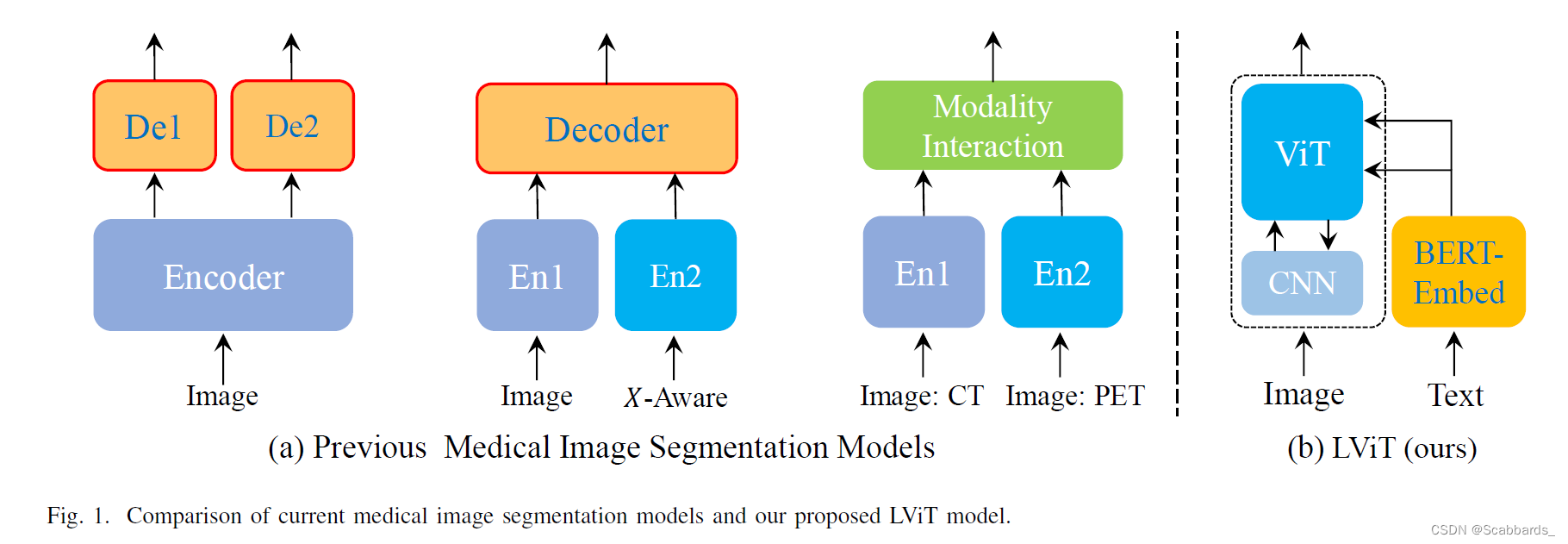
LViT模型是一个双u型结构,由一个u型CNN支路和一个u型Transformer支路组成。
其中CNN分支作为信息输入源和预测输出的分割头,ViT分支用于图像和文本信息的合并,利用Transformer处理跨模态信息的能力。在对文本进行简单的矢量化后,将文本向量与图像向量合并,送至u形ViT分支进行处理。在模型推理阶段,我们还需要对文本输入进行类似的处理。并将相应大小的融合信息传递回每一层的u形CNN分支进行最终的分割预测。此外,在u型CNN分支的跳接位置设置一个像素级注意模块(PLAM)。利用PLAM, LViT能够尽可能多地保留图像的局部特征信息。

(1) U-shape CNN Branch

Ushaped CNN分支接收图像信息,作为分割头输出预测掩码。
利用Conv、BatchNorm(BN)和ReLU激活层组成每个CNN模块。在每个DownCNN模块之间用Maxpool对图像特征进行下采样。在每个UpCNN模块之间执行连接操作。

每个CNN模块的具体过程用Eqn. 1和2描述,其中,YDownCNN,i表示第i个DownCNN模块的输入,对第i个DownCNN模块和MaxPool层进行下采样后变为YDownCNN,i+1。此外,我们设计了CNN-ViT交互模块,使用了上采样等方法来对齐来自ViT的特征。重构后的ViT特征通过残差与CNN特征连接,形成CNN-ViT交互特征。此外,为了进一步提高局部特征的分割能力,在跳接处设计了PLAM:将CNN-ViT交互特征输入到PLAM中,再将交互特征传递到UpCNN模块,逐层向上给出信息。
(2) U-shape ViT Branch
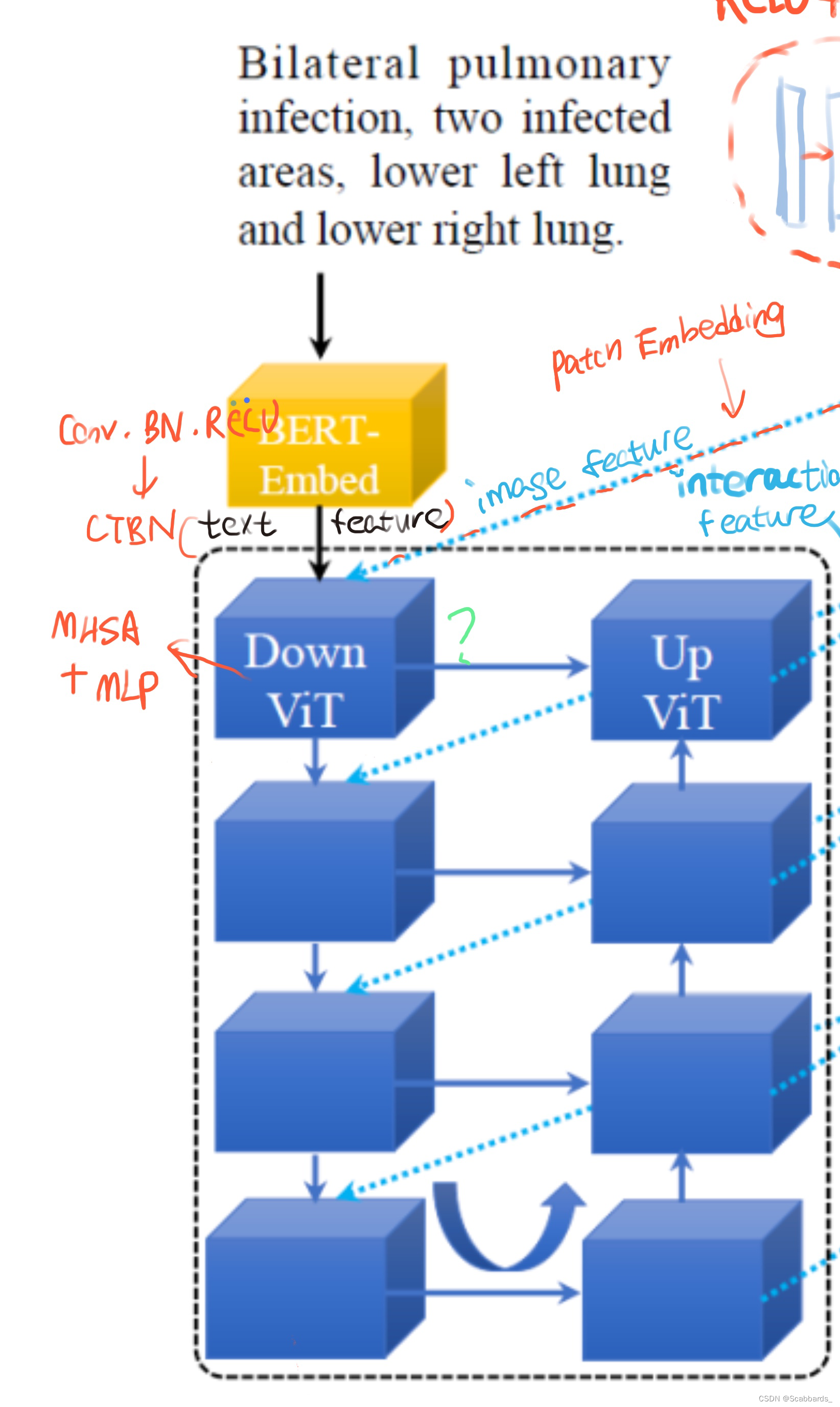
参考u形CNN分支,设计u形ViT分支用于合并图像特征和文本特征。如图2(a)所示,第一层DownViT模块接收BERT-Embed[42]输入的文本特征和第一层DownCNN模块输入的图像特征。BERT-Embed的预训练模型是BERT_12_768_12模型,它可以将单个单词转换为768维的单词向量。
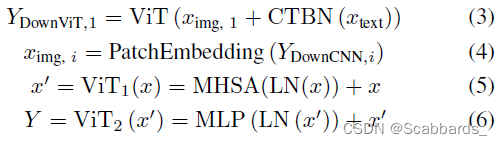
具体的跨模态特征合并操作表示为公式中,ximg,i表示来自DownCNN的图像特征,xtext表示文本特征,patchembeds可以帮助YDownCNN,i形成嵌入特征ximg,i。ViT表示T编码器[39],即Y = ViT (x) = V iT2 (V iT1(x))。
![]()
ViT由多头自注意组成
(MHSA)模块和MLP层。LN表示归一化层。CTBN块还包括Conv层、BatchNorm层和ReLU激活层,用于对齐ximg、1和xtext的特征维度。第2层、第3层和第4层的后续DownViT模块既接收上层DownViT模块的特征,又接收相应层的DownCNN模块的特征,如方程7所示。
i= 1、2、3时,相应尺寸的特征再通过UpViT模块传回CNN-ViT交互模块。将该特征与对应层的DownCNN模块的特征合并。这样可以最大限度地提取图像的全局特征,避免由于文本标注的不准确而导致模型性能的振荡。
(3)

PLAM旨在保留图像的局部特征,并进一步融合文本中的语义特征。
此外,它还可以增强卷积层在生成强大的局部特征表示方面的性能。
参考CBAM[36],我们的PLAM使用并行分支用于Global Average Pooling (GAP)和Global Max Pooling (GMP)。
我们还合并了连接和加法操作。加法操作将有助于合并具有相似语义的相应通道特征并节省计算。相比之下,连接操作可以更直观地整合特征信息,并有助于保留每个部分的原始特征。在连接特征信息之后,我们使用MLP结构和乘法操作来帮助对齐特征大小。
一般来说,我们的PLAM与LAVT中的像素字注意模块(PWAM)在几个方面有所不同[27]。首先,PLAM通过增强局部特征来缓解Transformer带来的对全局特征的偏好。相比之下,PWAM旨在通过交叉注意来对齐视觉和语言表示。其次,在实现上,PLAM采用通道注意和空间注意相结合的方式,而PWAM采用交叉自注意机制。总体而言,PLAM旨在增强局部特征,以提高医学图像的性能
Exponential Pseudo-label Iteration mechanism 指数伪标签迭代机制

在本节中,我们提出指数伪标签迭代机制(EPI),旨在帮助扩展LViT的半监督版本。在EPI中,使用EMA的思想迭代更新伪标签[10],如图3(a)和Eqn. 8所示。
![]()
式中Pt−1表示模型Mt−1的预测值
将动量参数β设为0.99。值得注意的是,这里Pt−1是一个N维预测向量,其中N表示类别类的数量,每个维度表示预测概率。因此,EPI可以逐步优化模型对每个未标记像素的分割预测结果,并且对噪声标签具有鲁棒性。这是因为我们没有简单地将一代模型预测的伪标签作为下一代模型的目标,这样可以避免伪标签质量的急剧恶化。(证明原论文中有,这里我就不放上来了)
LV (Language-Vision) Loss

为了进一步利用文本信息来指导伪标签的生成,我们设计了LV (Language-Vision)损失函数,如图3(b)所示。一般来说,人体器官在医学图像中的位置是相对固定的。因此,我们可以使用结构化的文本信息来形成相应的掩码(对比标签)。我们计算文本之间的余弦相似度,如公式16所示

其中,xtext,p表示伪标签对应的文本特征向量,xtext,c表示对比标签对应的文本特征向量。然后,根据TextSim算法,选择相似度最高的对比文本,找到该文本对应的分割掩码;我们使用标签相似度计算预测的分割伪标签与对比标签之间的余弦相似度,如公式17和18所示。

式中,ximg,p表示伪标签特征向量,ximg,c表示比较标签特征向量。
与欧氏距离相比,余弦相似度对绝对值不敏感,更定性地反映相似度,符合我们的任务动机。对比标记主要提供近似位置的标记信息,而不是对边界进行细化。
因此,左室丢失的首要目的是避免有显著差异的病例被错误分割或被错误标记。
因此,我们只在未标记的情况下使用LV损耗,因为当数据被标记时,对比标签对性能的提高帮助不大。在无标签的情况下,进行一致性监管的LV丢失可以避免伪标签质量的急剧恶化。值得注意的是,与VLT中的masked conservative learning相比,我们的LViT中的Pseudo和contrast标签旨在解决不同的问题[29]。
首先,伪标签和对比标签是为半监督学习而设计的,而隐藏保守学习旨在探索与单个对象相关的不同语言表达的知识。其次,LViT通过计算文本相似度来确定案例是否相似,而VLT通过提取文本特征来实现。然而,在医学领域,通过隐式特征提取来确定放射学报告之间的相似性是很困难的,因为不同的放射学报告可能只有很少的措辞变化。
因此,结构化格式通常用于区分报告。此外,与masked conservative learning不同,我们设计了一种指数伪标签迭代机制(Exponential Pseudo label Iteration, EPI),以保证带有文本信息的伪标签的质量,该机制交叉利用了标记数据的标签信息和未标记数据的潜在信息。
CNN-Transformer结构优越性的证明
与之前的视觉和语言工作不同,我们提出LViT模型在处理图像和文本方面具有创新性。
我们没有使用文本编码器,而是创造性地利用CNN和ViT之间的交互来提取特征。
太多公式了打得好麻烦.jpg,先略过后面再补(也许)
实验

数据集
1) MosMedData+
里面有2729张肺部感染的CT扫描片
2) QaTa-COV19
该数据集由9258张COVID-19胸部x射线片组成,并附有COVID-的手动注释,首次出现19个病灶。此外,我们对数据集的文本注释进行了扩展,以用于训练视觉语言模型。我们在QaTa-上扩展了文本注释,在专业人员的帮助下首次建立了covid - 19数据集。文本注释侧重于双肺是否感染,病变区域的数量,以及感染区域的大致位置。
3) ESO-CT
由286个案例组成
损失函数

LDice = Dice
LCE = Cross entropy
对于未标记的数据,在损失LLV上引入一个附加项,α = 0.1。对于标记的数据,α = 0。使用Dice和mIoU来评估分割性能。在训练阶段采用提前停止机制。
其中N表示像素数,C表示类别数,在我们的实验中设置为1。
pij表示像素i属于j类的预测概率,yij表示像素i是否属于j类。如果像素i属于j类,则yij = 1,否则为0。
评测指标
Dice Loss 和mIoU指标用于评估我们的LViT模型和其他SOTA方法的性能

实现细节
框架:pytorch
硬件:操作系统为Ubuntu 16.04.12 LTS, CPU为Intel(R) Xeon(R)Gold 5218, GPU为2卡TESLA V100 32G,内存容量为128gb。
学习率:
QaTa-COV19数据集的初始学习率设置为3e-4
MosMedData+数据集的初始学习率设置为1e-3。
我们还使用了一个早停机制,直到模型的性能在50个epoch内没有改善。由于每个数据集具有不同的数据大小,因此还设置了不同的批处理大小。QaTa-COV19数据集的默认批大小为24
MosMedData +数据集。
实验结果
话不多说,看图
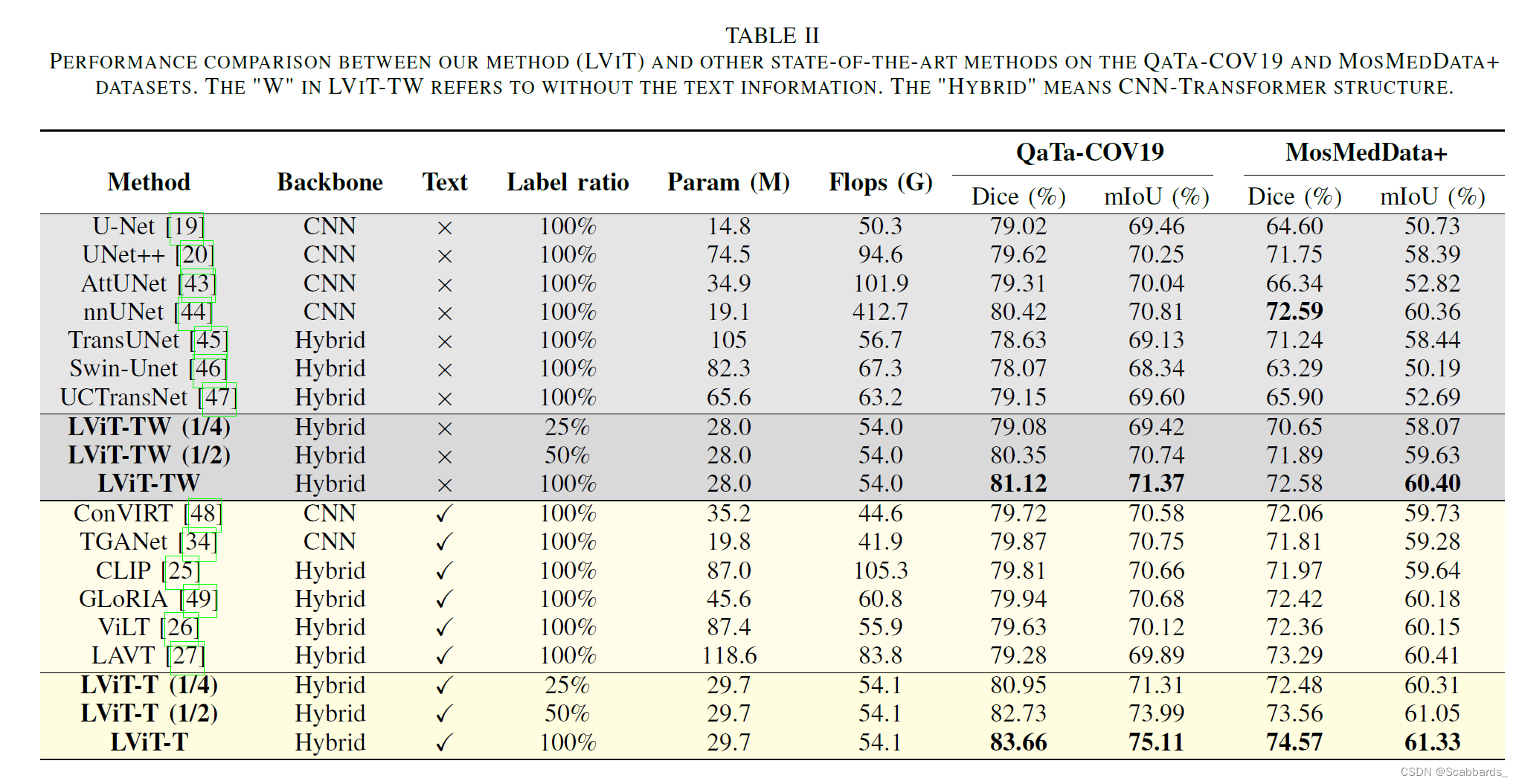

消融实验
从以下几个方面评估
1. 有监督组成部分的有效性

在标记数据上使用LLV并没有显著的好处。
2. 模型尺寸
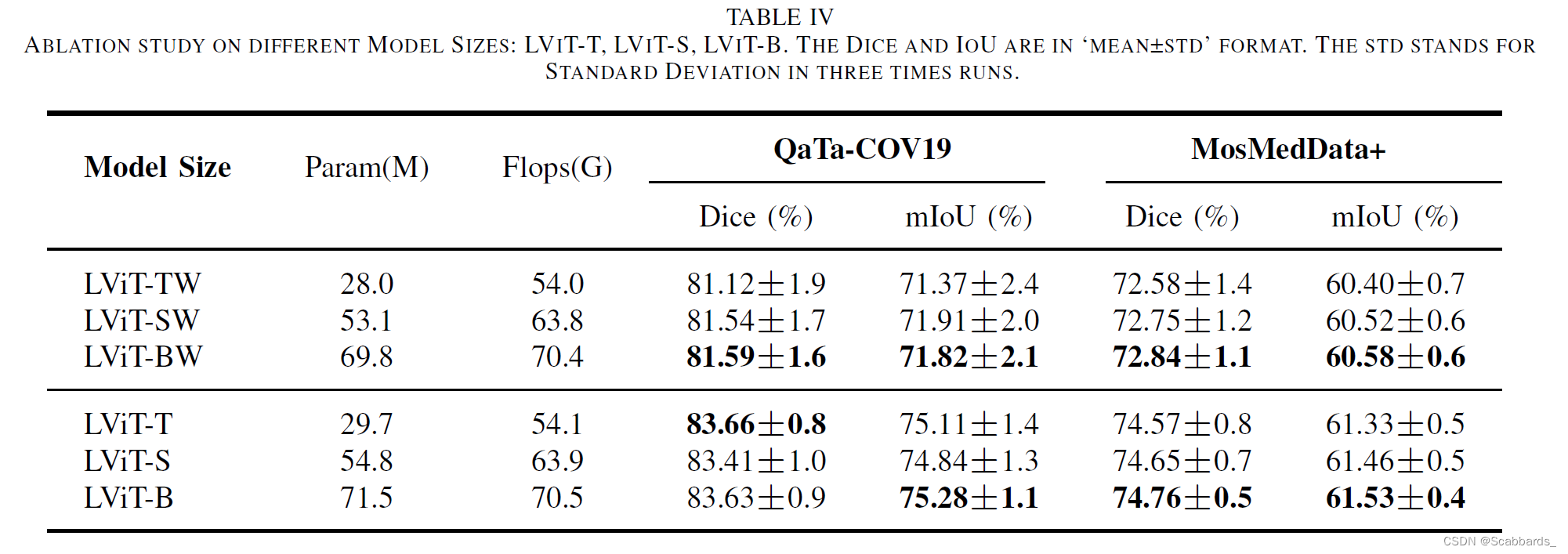
带有文本注释的LViT只比LViT- w多出1.7M的参数和0.1G的计算量,而文本信息对分割性能的提升是显著的。
如果数据集分布存在显著差异,并且图像分割具有挑战性,则增加模型大小可以提高性能。但值得注意的是,随着模型尺寸的增大,模型的性能抖动减小,表明模型变得更加鲁棒。
3. 超参数

超参数对模型性能的影响比模型大小的影响更大。
4. 文本编码器和嵌入层的消融研究
一组侧重于现有结构良好的文本,而另一组侧重于结构不良的文本。

与使用文本嵌入层相比,使用文本编码器所需的参数和计算量几乎是使用文本嵌入层的三倍。
然而,尽管复杂性增加了,模型的性能并没有提高,甚至在结构良好的报告中还会下降。这一发现支持了我们在LViT模型中使用文本嵌入层的决定。
值得注意的是,对于结构不良的报告,带有文本嵌入层的模型性能略低于文本编码器的模型性能。
我们认为这种差异可以归因于文本编码器在处理更多样化的放射学报告时具有更好的编码能力和鲁棒性。然而,重要的是要认识到,由此产生的参数和计算成本并不具有成本效益。
5. 半监督
这些实验涵盖了25%和50%两种不同的标签比例,以探索不同标签比例下的性能变化。
我们提出的LViT模型比其他方法具有更好的分割性能。这归因于指数伪标签迭代机制和LV损失,无论文本信息是否包含在pipeline中。


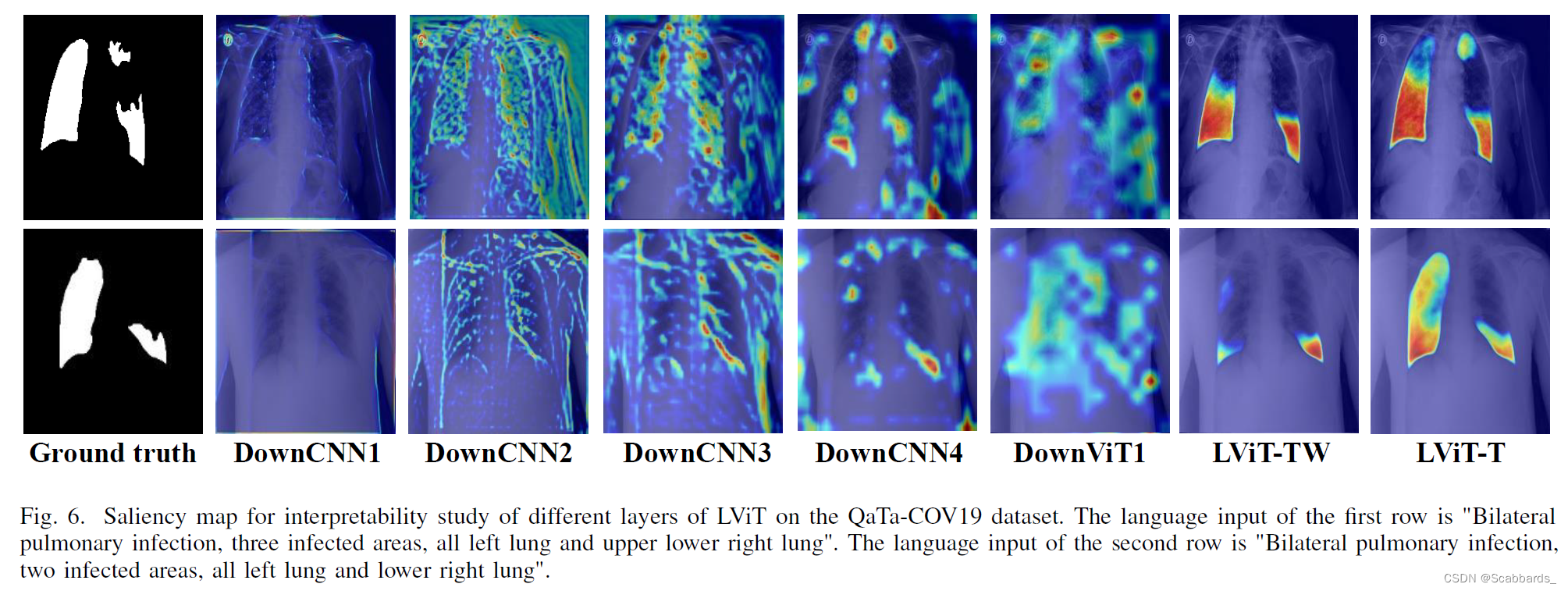
可解释性
GradCAM