系列文章目录
MySQL笔记——MySQL数据库介绍以及在Linux里面安装MySQL数据库,对MySQL数据库的简单操作,MySQL的外接应用程序使用说明
MySQL笔记——表的修改查询相关的命令操作
MySQL案例——多表查询以及嵌套查询
MySQL笔记——数据库当中的事务以及Java实现对数据库进行增删改查操作
文章目录
前言
一 表的分组查询
1.1 语法
1.2. 注意点
1.3 案例添加数据演示
1.4 相关分组案例讲解
数据内容
1.4.1 统计学生表中男女学生数量分别有多少
1.4.2 统计男生的数学平均值,女生数学的平均值
1.4.3 统计不同性别的学生XX成绩在XX分以上的平均值
1) 统计不同性别的学生数学成绩在85分以上的平均值
2) 统计不同性别的学生英语成绩在95分以上的平均值
3)变形——统计不同性别的学生英语平均值在95分之上
PS补充内容:where与having的区别
1.4.4 统计不同 班级的学生的总人数
1.4.5 统计班级总人数大于2的班级的总人数
1.4.6 统计英语成绩在60分之上的班级的总人数,总人数按照从大到小进行排序
二 分页查询
2.1 语法
2.2 具体的案例
三 约束
3.1 几种约束详解
3.1.1 非空约束(not null)
3.1.2 唯一约束(unique)
3.1.3 主键约束(primary key)
3.1.4 设置某列自动增长
3.1.5 外键约束
3.2 约束添加的时机
总结
前言
本文主要介绍表的分组查询、表的分页查询、表的约束,以及相关的案例展示。
一 表的分组查询
1.1 语法
group by 分组字段;1.2. 注意点
1. 分组之后查询的字段:分组字段、聚合函数
2. where 和 having 的区别?
- where 在分组之前进行限定,如果不满足条件,则不参与分组。having在分组之后进行限定,如果不满足结果,则不会被查询出来
- where 后不可以跟聚合函数,having可以进行聚合函数的判断。
按照性别分组。分别查询男、女同学的平均分
SELECT
sex , AVG(math)
FROM student
GROUP BY sex;按照性别分组。分别查询男、女同学的平均分,人数
SELECT
sex , AVG(math),COUNT(id)
FROM student
GROUP BY sex;按照性别分组。分别查询男、女同学的平均分,人数 要求:分数低于70分的人,不参与分组
SELECT
sex , AVG(math),COUNT(id)
FROM student
WHERE math > 70
GROUP BY sex;按照性别分组。分别查询男、女同学的平均分,人数 要求:分数低于70分的人,不参与分组,分组之后。人数要大于2个人
SELECT
sex , AVG(math),
COUNT(id)
FROM student
WHERE math > 70
GROUP BY sex
HAVING COUNT(id) > 2;
SELECT sex , AVG(math),
COUNT(id) 人数
FROM student
WHERE math > 70
GROUP BY sex
HAVING 人数 > 2;group by 的用法
group by 是 SQL 查询语句中的一个关键字,用于对结果集进行分组操作。它通常与聚合函数(如 SUM、COUNT、AVG 等)一起使用,以便在分组的基础上进行计算。
group by 的基本语法如下:
SELECT 列名1, 列名2, ... FROM 表名 GROUP BY 列名1, 列名2, ...在执行 group by 操作时,首先根据指定的列名进行分组,然后对每个分组进行计算或者筛选。查询结果将返回每个分组的聚合结果,而不是每条原始数据的详细信息。
以下是一个示例查询,演示了 group by 的用法:
SELECT department, COUNT(*) as employee_count FROM employees GROUP BY department;这个查询将根据 employees 表中的 department 列对数据进行分组,并计算每个部门的员工数量。最后的结果将返回每个部门和对应的员工数量。
需要注意的是,在 group by 子句中指定的列名必须是查询结果中出现的列名之一,或者是可以通过聚合函数计算得到的列名。否则,将会引发错误。
1.3 案例添加数据演示
此处演示使用SQLyog软件操作,其操作与Navicat类似。
更改列时选中改变表菜单进行更改。
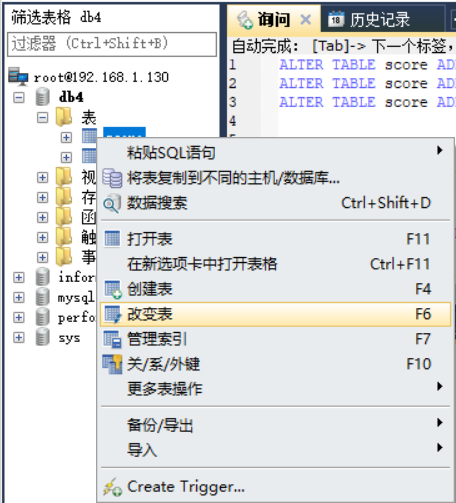
假设添加一个新的列id这一列,操作如下:
此处也可以使用SQL语句来添加新的一列,或者直接在外接工具上面添加一列,添加完成之后记得保存退出即可。
ALTER TABLE score ADD id int(20); 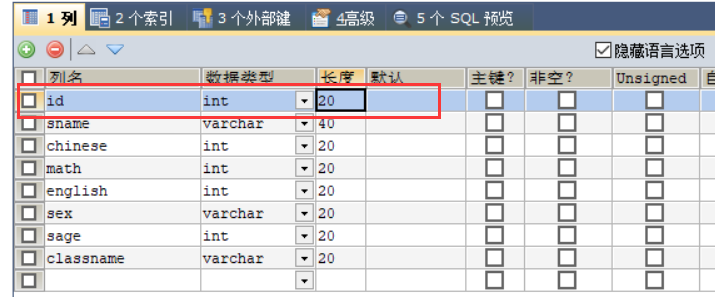
保存完成之后刷洗一下即可看到表的新列添加进去了。

查看表的机构如下
DESC score;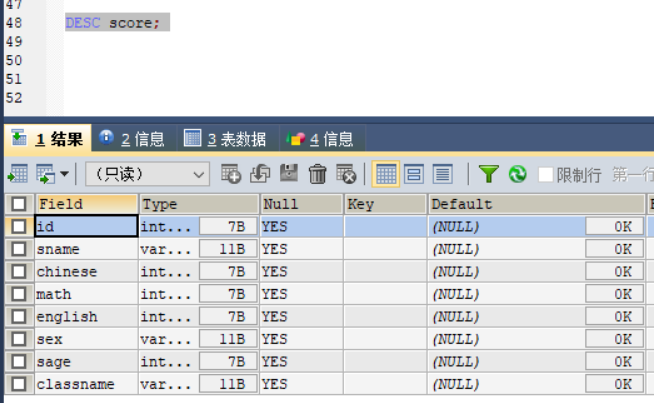
添加前面的id内容之后保存一下。

1.4 相关分组案例讲解
数据内容
INSERT INTO student VALUES(3,'tom',23,'女','2班',88,34,69);
INSERT INTO student VALUES(6,'dismiss',25,'男','1班',48,94,89);
INSERT INTO student VALUES(9,'injury',33,'女','3班',76,34,59);
INSERT INTO student VALUES(2,'export',26,'女','2班',88,54,65);
INSERT INTO student VALUES(7,'spot',20,'男','1班',98,74,76);
INSERT INTO student VALUES(5,'crash',22,'女','2班',78,44,86);
INSERT INTO student VALUES(10,'pollect',24,'男','3班',82,64,79);
INSERT INTO student VALUES(4,'expolit',27,'女','1班',68,39,81);
INSERT INTO student VALUES(8,'exhaust',29,'女','1班',87,64,69);
INSERT INTO student VALUES(12,'collapse',32,'女','2班',58,84,99);
INSERT INTO student VALUES(13,'highly',35,'男','1班',76,73,69);
INSERT INTO student VALUES(11,'discourage',25,'女','3班',79,31,67);
INSERT INTO student VALUES(14,'slippery',28,'男','2班',80,67,84);打开表查看信息
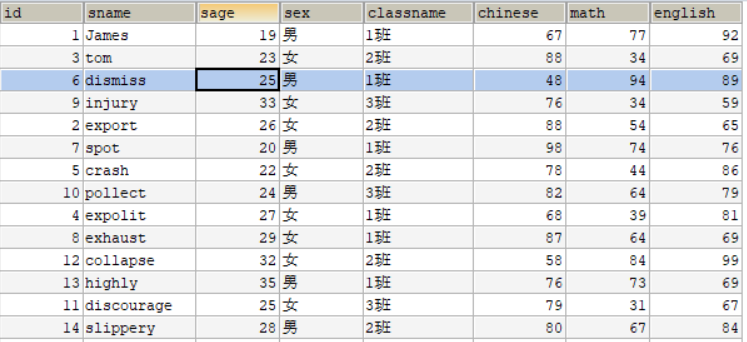
1.4.1 统计学生表中男女学生数量分别有多少
查看难受和女生的数量:
SELECT sex,COUNT(sex) AS 数量
FROM student
GROUP BY sex; 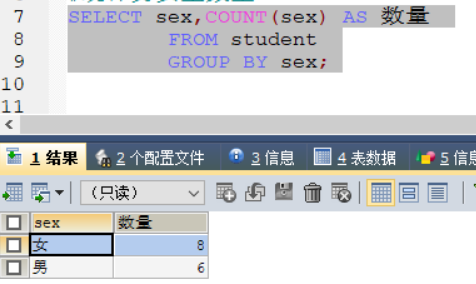
错误的书写方式演示
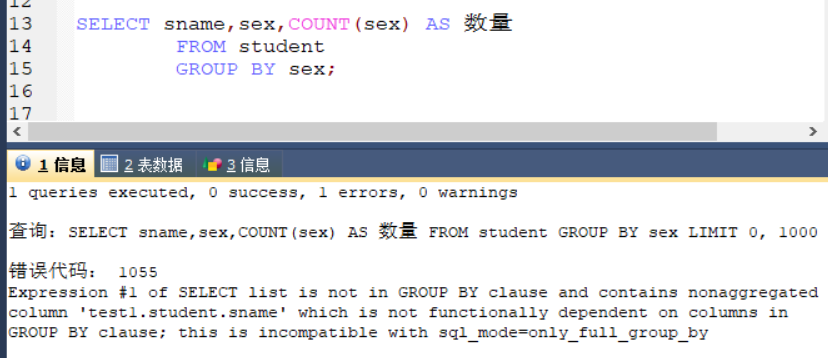
MySQL报错 SELECT list is not in GROUP BY clause and contains nonaggregated column…的原因如下:
在mysql5.7以上的版本中,对于 group by 的这种聚合操作,如果在select 中的列,没有在group by 中出现,那么这个SQL是不合法的,因为列不在group by的从句中,所以对于设置了这个mode的数据库,在使用group by 的时候,就要用MAX(),SUM(),ANT_VALUE()的这种聚合函数,才能完成GROUP BY 的聚合操作
注意:
- SQL里面出现分组,select后面字段的字段必须是group by 后面出现的字段
- 分组语句中select后面的还可以是聚合函数
1.4.2 统计男生的数学平均值,女生数学的平均值
SELECT sex,AVG(math)
FROM student
GROUP BY sex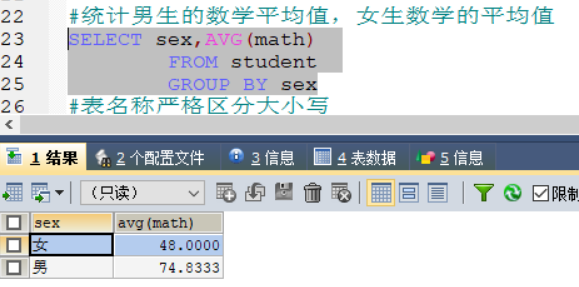
1.4.3 统计不同性别的学生XX成绩在XX分以上的平均值
1) 统计不同性别的学生数学成绩在85分以上的平均值
SELECT sex,AVG(math)
FROM student
WHERE math > 85
GROUP BY sex;
2) 统计不同性别的学生英语成绩在95分以上的平均值
SELECT sex,AVG(english)
FROM student
WHERE english > 95
GROUP BY sex;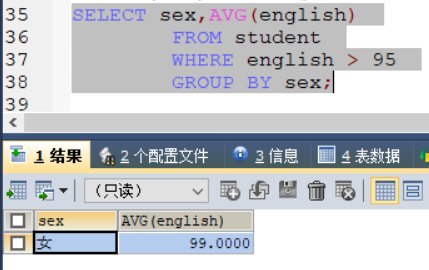
PS:where先于分组之前执行
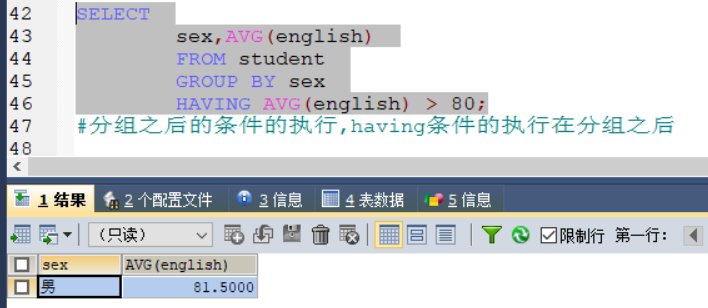
3)变形——统计不同性别的学生英语平均值在95分之上
SELECT
sex,AVG(english)
FROM student
GROUP BY sex
HAVING AVG(english) > 80;查询结果:
PS补充内容:where与having的区别
HAVING 关键字和 WHERE 关键字都可以用来过滤数据,且 HAVING 支持 WHERE 关键字中所有的操作符和语法。
但是 WHERE 和 HAVING 关键字也存在以下几点差异:
1.一般情况下,WHERE 用于过滤数据行,而 HAVING 用于过滤分组。
2.WHERE 查询条件中不可以使用聚合函数,而 HAVING 查询条件中可以使用聚合函数。
3.WHERE 在数据分组前进行过滤,而 HAVING 在数据分组后进行过滤 。
4.WHERE 针对数据库文件进行过滤,而 HAVING 针对查询结果进行过滤。也就是说,WHERE 根据数据表中的字段直接进行过滤,而 HAVING 是根据前面已经查询出的字段进行过滤。
5.WHERE 查询条件中不可以使用字段别名,而 HAVING 查询条件中可以使用字段别名。
1.4.4 统计不同 班级的学生的总人数
SELECT
className,COUNT(className)
FROM student
GROUP BY className;
1.4.5 统计班级总人数大于2的班级的总人数
SELECT
className,COUNT(className)
FROM student
GROUP BY className
HAVING COUNT(className)>4 -- 条件筛选
1.4.6 统计英语成绩在60分之上的班级的总人数,总人数按照从大到小进行排序
SELECT classname,COUNT(classname)
FROM student
WHERE english >60
GROUP BY classname
HAVING COUNT(classname)>3
ORDER BY COUNT(classname) DESC;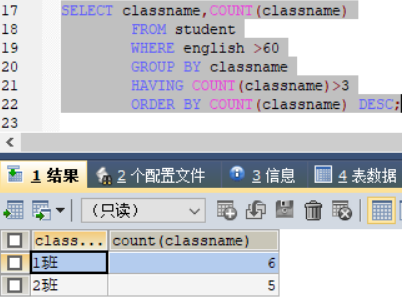
二 分页查询
当我们处理大量数据时,通常需要进行分页查询来减少内存的使用和提高查询效率。MySQL提供了LIMIT和OFFSET子句来实现分页查询。
LIMIT子句用于限制查询结果的数量,而OFFSET子句用于指定查询结果的起始位置。
以下是一个示例代码,展示了如何在MySQL中进行分页查询:
2.1 语法
limit 开始的索引,每页查询的条数;计算公式:开始的索引 = (当前的页码 - 1) * 每页显示的条数
limit 参数1,参数2
参数1:从第几条数据开始
参数2:每页显示的条数 已知的数据:当前的页码 currentPage 每一页显示的多少条数据 pageCount
参数1的获取公式 = (currentPage-1)* pageCount
举例:每页显示3条记录
-- 查询第一页的数据,每一页显示3条
SELECT * FROM student
ORDER BY id
LIMIT 0,3 0 = (1-1)*3
-- 查询第二页的数据,每一页显示3条
SELECT * FROM student
ORDER BY id
LIMIT 3,3 3 = (2-1)*3
-- 查询第三页的数据,每一页显示3条
SELECT * FROM student
ORDER BY id
LIMIT 6,3 6 = (3-1)*3
要显示的总共的页数需要计算
-- 需要的是第5页的数据的sql语句
select * from student limit (5-1)* 3,32.2 具体的案例
SELECT * FROM student
ORDER BY id
LIMIT 0,3
-- 查询第二页内容,每页显示5条数据
SELECT * FROM student
ORDER BY id
LIMIT 5,5
三 约束
一种限制,用于限制表中的数据,为了保证表中的数据的准确和可靠性。MySQL数据库通过约束(constraints)防止无效的数据进入到表中,以保护数据的实体完整性。
约束的分类
在 MySQL 中,主要有六种约束:
- 1、NOT NULL:非空约束,用于约束该字段的值不能为空。比如姓名、学号等。
- 2、DEFAULT:默认值约束,用于约束该字段有默认值,约束当数据表中某个字段不输入值时,自动为其添加一个已经设置好的值。比如性别。
- 3、PRIMARY KEY:主键约束,用于约束该字段的值具有唯一性,至多有一个,可以没有,并且非空。比如学号、员工编号等。
- 4、UNIQUE:唯一约束,用于约束该字段的值具有唯一性,可以有多个,可以没有,可以为空。比如座位号。
- 5、CHECK:检查约束,用来检查数据表中,字段值是否有效。比如年龄、性别。
- 6、FOREIGN KEY:外键约束,外键约束经常和主键约束一起使用,用来确保数据的一致性,用于限制两个表的关系,用于保证该字段的值必须来自于主表的关联列的值。在从表添加外键约束,用于引用主表中某列的值。比如学生表的专业编号,员工表的部门编号,员工表的工种编号。
3.1 几种约束详解
约束是为了对表中的数据进行限定,保证数据的正确性、有效性和完整性。
1. 主键约束:primary key
2. 非空约束:not null
3. 唯一约束:unique
4. 外键约束:foreign key
3.1.1 非空约束(not null)
某一列的值不能为null
1. 创建表时添加约束
CREATE TABLE stu(
id INT,
NAME VARCHAR(20) NOT NULL -- name为非空
);
2. 创建表完后,添加非空约束
ALTER TABLE stu MODIFY NAME VARCHAR(20) NOT NULL;


3. 删除name的非空约束
ALTER TABLE stu MODIFY NAME VARCHAR(20);3.1.2 唯一约束(unique)
某一列的值不能重复
1. 注意:
* 唯一约束可以有NULL值,但是只能有一条记录为null
2. 在创建表时,添加唯一约束
CREATE TABLE stu(
id INT,
phone_number VARCHAR(20) UNIQUE -- 手机号
);3. 删除唯一约束
ALTER TABLE stu DROP INDEX phone_number;4. 在表创建完后,添加唯一约束
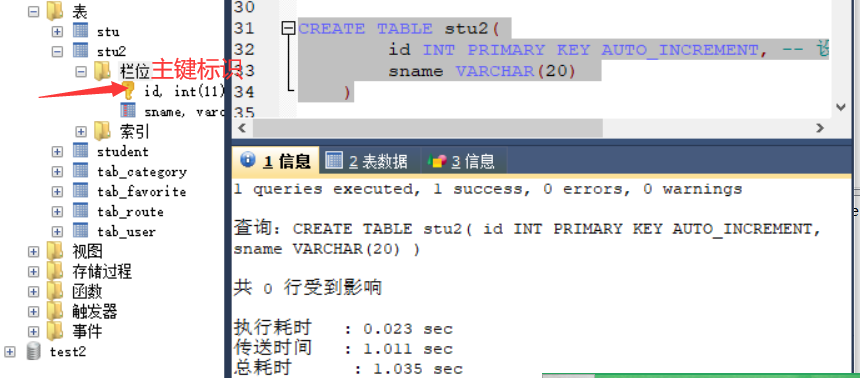
ALTER TABLE stu MODIFY phone_number VARCHAR(20) UNIQUE;3.1.3 主键约束(primary key)
1. 注意:
1. 含义:非空且唯一
2. 一张表只能有一个字段为主键
3. 主键就是表中记录的唯一标识
2. 在创建表时,添加主键约束
create table stu(
id int primary key,-- 给id添加主键约束
name varchar(20)
);
3. 删除主键
-- 错误 alter table stu modify id int ;
ALTER TABLE stu DROP PRIMARY KEY;4. 创建完表后,添加主键
ALTER TABLE stu MODIFY id INT PRIMARY KEY;3.1.4 设置某列自动增长
- 1. 概念:如果某一列是数值类型的,使用 auto_increment 可以来完成值得自动增长
- 2. 在创建表时,添加主键约束,并且完成主键自增长
create table stu(
id int primary key auto_increment,-- 给id添加主键约束
name varchar(20)
);3. 删除自动增长
ALTER TABLE stu MODIFY id INT;4. 添加自动增长
ALTER TABLE stu MODIFY id INT AUTO_INCREMENT; 3.1.5 外键约束
1. 外键约束语法
CREATE TABLE emp(
id INT PRIMARY KEY AUTO_INCREMENT,
sname VARCHAR(20) ,
did INT, -- 添加外键约束
CONSTRAINT emp_depart FOREIGN KEY (did) REFERENCES depart(id)
)2. 删除外键
ALTER TABLE emp DROP FOREIGN KEY emp_depart3. 表创建成功之后添加外键约束
ALTER TABLE emp ADD
CONSTRAINT emp_depart FOREIGN KEY (did) REFERENCES depart(id)
on delete cascade on update cascade4. 不推荐使用级联操作:
级联
- 1、级联删除 on delete cascade
- 2、级联更新 on update cascade
3.2 约束添加的时机
- 1、创建表的的时候添加
- 2、创建表完成以后,也可以添加
- 3、删除约束
总结
以上就是今天的内容~
欢迎大家点赞👍,收藏⭐,转发🚀,
如有问题、建议,请您在评论区留言💬哦。
最后:转载请注明出处!!!