第4章 离线数据开发
采集系统采集的大量数据只有被整合计算后才能用于洞察商业规律,挖掘潜在的信息,实现其价值。面对海量的数据和复杂的计算,阿里巴巴的数据计算层包括两大体系:
数据存储及计算平台(离线计算平台MaxComputer和实时计算平台StreamCompute)
数据整合及管理体系(OneData)
1.数据开发平台

- 统一计算平台(MaxCompute)
阿里离线数据仓库的存储和计算都是在阿里云大数据计算服务MaxCompute上完成的。
(1)MaxCompute是什么
MaxCompute 是由阿里云自主研发的海量数据处理平台
(2)优点
① 计算性能高且更加普惠
② 集群规模大且稳定性高
③ 功能组件非常强大
④ 安全性高
(3)应用场景
主要服务于海量数据的存储和计算 ,提供完善的数据导入方案,以及多种经典的分布式计算模型,提供海量数据仓库的解决方案

MaxCompute 由四部分组成:
(1)客户端( MaxCompute Client )
客户端户端有以下几种形式。
Web :以 RESTful API 的方式提供离线数据处理服务。
SDK :对 RESTful API 的封装,目前有 Java 等版本的实现。
CLT (Command Line Tool ): 运行在 Windows/Linux 下的客户端工具,通过 CLT 可以提交命令完成 Project 管理、 DDL DML等操作。
IDE :上层可视化 ETL/BI 工具, 即阿里内部名称是在云端( D2 ) , 用户可以基于在云端完成数据同步、任务调度、报表生成等常见操作。(2)接人层( MaxCompute Front End )
接人层提供 HTTP 服务、 Cache 、负载均衡,实现用户认证和服务层面的访问控制。
(3)逻辑层( MaxCompt Server )
逻辑层又称作控制层,是 MaxCompute 的核心部分,实现用户空间和对象的管理、命令的解析与执行逻辑、数据对象的访问控制与授权等功能。在逻辑层有 Worker Sc heduler Executor 三个角色
Worker 处理所有的阻STful 请求,包括用户空间( Project )管理操作、资源(Resource 管理操作、作业管理等,对于 SQLDMLMR 等需要启动 MapReduce 的作业,会生成 MaxCompute Instance (类似于 Hive 中的 Jo ,提交给 cheduler 一步处理。
Scheduler MaxCompute Instance 的调度和拆解,并向计算层的计算集群询问资源占用情况以进行流控。
Executor 负责 MaxCompute Instance 的执行,向计算层的计算集群提交真正的计算任务。(4)存储与计算层( Apsara Core )
计算层就是飞天内核( Apsara Core ),运行在和控制层相互独计算集群上 ,它包括 Pangu (分布式文件系统)、 uxi (资源调度系统)Nuwa/ZK Jamespace 务) Shennong (监控模块)等。 MaxCompute 中的元数据存储在阿里云计算 的另 个开放服务 OTS (Open Table Service ,开放结构化数据服务) 中,元数据内容主要包括用户空间元数据、 Table Partition Schema ACL Job 元数据、安全体系等。
- 统一开发平台(D2等相关平台工具)
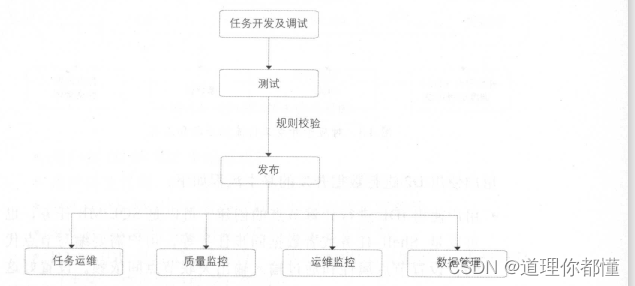
阿里的开发流程以及对应的产品和工具如下图所示
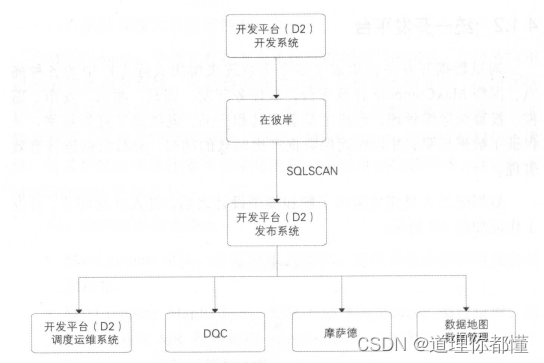
(1)在云端(D2)
① 什么是D2
D2是集成任务开发、调试及发布,生产任务调度及大数据运维数据权限申请及管理等功能的一站式数据开发平台 并能承担数据分析工作台的功能。
② 基本使用流程
用户使用 IDE 行计算节点的创建,可以是 SQL/MR 任务,也可以是 hell 务或者数据同步任务等,用户需要编写节点代
码、设置节点属性和通过输入输出关联节点间依赖。设置好这些后,可以通过试运行来测试计算逻辑是否正确、结果是否合预期。
用户点击提交,节点进入开发环境中,并成为某个工作流的其中个节点。整个工作流可以被触发调度,这种触发可以是人为的(称之为“临时工作流”),也可以是系统自动的(称之为“日常工作流”)。当某个节点满足所有触发条件后,会被下发到度系统的执行引擎Alisa 中, 完成资源分配和执行的整个过程。
如果节点在开发环境中运行无误,用户可以点击发布,将该节正式提交到生产环境中,成为线上生产链路的 一个环节。
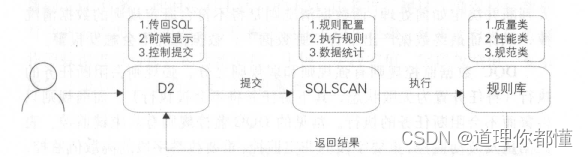
(2)SQLSCAN
① SQLSCAN的作用
SQLSCAN 将在任务开发中遇到的各种问题,如用户编写的质量差、性能低、不遵守规范等,总结后形成规则,并通过系统及研发流程保障,事前解决故障隐患,避免事后处理。SQLSCAN与D2 进行结合,嵌入到开发流程中,用户在提交代码时会触发 SQLSCAN 检查。
② 工作流程
用户在 D2 IDE 中编写代码。
用户提交代码, D2 将代码、调度等信息传到 CAN
SQLSCAN 根据所配置的规则执行相应的规则校验。
SQLSCAN 将检查成功或者失败的信息传回 20
D2 IDE 显示 OK (成功)、 WARNNING (警告)、 FAILE(失败,禁止用户提交)等消息。
③ 规则校验
代码规范类规则,如表命名规范、生命周期设置、表注释等。
代码质量类规则,如调度参数使用检查、分母为0提醒、 NULL值参与计算影响结果提醒、插入字段顺序错误等。
代码性能类规则,如分区裁剪失效、扫描大表提醒、重复计算检测等
注:SQLSCAN 规则有强规则和弱规则两类。触发强规则后,任务的提交会被阻断,必须修复代码后才能再次提交而触发弱规则,则只会显示违反规则的提示,用户可以继续提交任务。
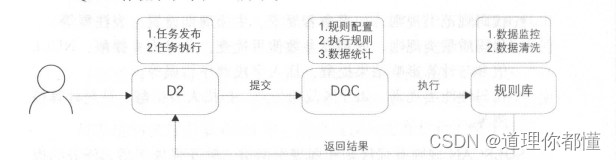
(3)DQC
① 什么是DQC
DQC (Data Quality Center ,数据质量中心)主要关注数据质量,通过配置数据质量校验规则,自动在数据处理任务过程中进行数据质量方面的监控。
② DQC的功能
a.数据监控
数据监控,顾名思义,能监控数据质量并报警,其本身不对数据产出进行处理,需要报警接收人判断并决定如何处理;
数据监控规则:
主键监控
表数据量及波动监控
重要字段的非空监控
重要枚举宇段的离散值监控
指标值波动监控
业务规则监控等。b.数据清洗
数据清洗是将不符合既定规则的数据清洗掉,以保证最终数据产出不含“脏数据”,数据清洗不会触发报警。
阿里数据仓库的数据清洗采用非侵人式的清洗策略,在数据同步过程中不进行数据清洗,避免影响数据同步的效率,其过程在数据进入ODS 层之后执行。对于需要清洗的表,首先在 DQC 置清洗规则;对于离线任务,每隔固定的时间间隔,数据人仓之后,启动清洗任务,调DQC 配置的清洗规则,将符合清洗规则的数据清洗掉,并保存至DIRTY 表归档。如果清洗掉的数据量大于预设的阐值,则阻断任务的执行 否则不会阻断。
③ 工作流程
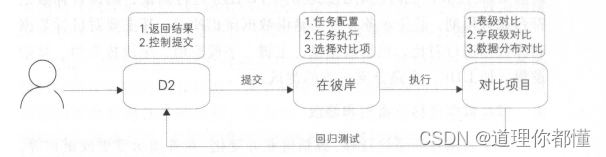
(4)在彼岸
① 什么是在彼岸
在彼岸则是用于解决上述测试问题而开发的大数据系统的自动化测试平台,将通用的、重复性的操作沉淀在测试平台中,避免被“人肉”,提高测试效率。
② 主要场景
a.新增业务需求
新增产品经理、运营、 BI 等的报表、应用或产品需求 需要开发新的 TL 务,此时应对上线前的 ETL 任务进行测试,确保目标数据符合业务预期,避免业务方根据错误数据做出决策。其主要对目标数据和源数据进行对比,包括数据量、主键、字段空值 、字段枚举值、复杂逻辑(如 UDF 、多路分支)等的测试。
b.数据迁移、重构和修改
由于数据仓库系统迁移、源系统业务变化、业务需求变更或重构等,需要对现有的代码逻辑进行修改 ,为保证数据质量需要对修改前后的数据进行对比,包括数据量差异、宇段值差异对比等,保证逻辑变更正确。为了严格保证数据质量,对于优先级大于某个阔值的任务,强制要求必须使用在彼岸进行回归测试,在彼岸回归测试通过之后,才允许进入发布流程。
③ 主要组件
数据对比: 支持不同集群、异构数据库的表做数据对比。表级对比规则主要包括数据量和全文对比;字段级对比规则主要包括字段的统计值(如 SUM VG MAX MIN 等)、枚举值、空值、去重数、长度值等。
数据分布:提取表和字段的 些特征值 ,并将这些特征值与预期值进行比对。表级数据特征提取主要包括数据量、主键等;字段级数据特征提取主要包括字段枚举值分布、空值分布、统计值(如SUM AVG MAX MIN 等)、去重数、长度值等。
数据脱敏:将敏感数据模糊化。在数据安全的大前提下,实现线上数据脱敏,在保证数据安全的同时又保持数据形态的分布,以便业务联调、数据调研和数据交换。
③ 工作流程
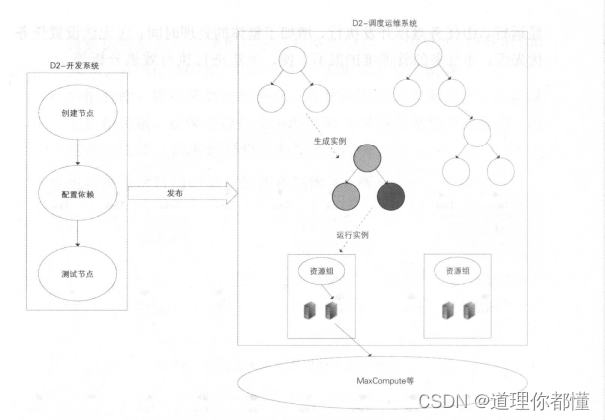
2.任务调度系统

用户通过D2平台提交、发布的任务结点,需要通过调度系统,按照任务的运行顺序调度运行。
- 调度引擎
在了解调度引擎之前,需要先了解两个模型:
(1)任务状态机模型
任务状态机模型时针对数据任务在整个运行声明周期的状态定义,总共有6种状态,状态之间的转换逻辑如下所示
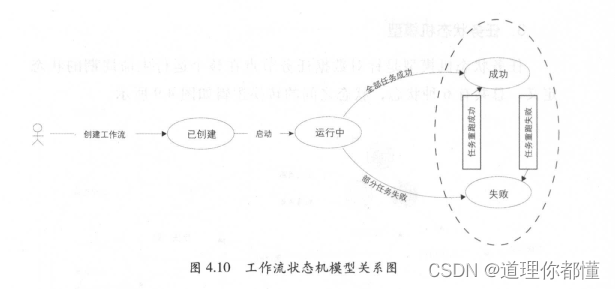
(2)工作流状态机模型
工作流状态机模型时针对数据任务结点在调度树中生成的工作流状态的不同状态定义,共有5中状态,其关系如下所示。

调度引擎工作原理
调度引擎( Phoenix Engine )基于以上两个状态机模型原理,以件驱动的方式运行,为数据任务节点生成实例,并在调度树中生成具体执行的工作流。任务节点实例在工作流状态机、任务状态机和事件处器之间转换,其中调度引擎只涉及任务状态机的未运行和 待运行两状态,其他 种状态存在于执行引擎中。

Async Dispatcher :异步处理任务调度。
Sync Dispatcher :同步处理任务调度。
Task 事件处理器:任务事件处理器,与任务状态机。
DAG 事件处理器:工作流事件处理器,与工作流状态机交互。一个DAG 事件处理器包含若干个Task 件处理器。
- 执行引擎
工作原理
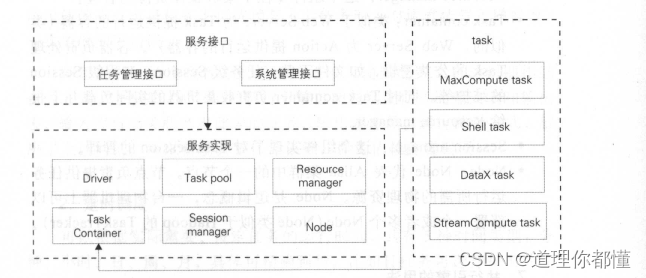
任务管理接口:供用户系统向 Alisa 中提交、查询和操作离线任务,并获得异步通知。
系统管理接口 :供系统管理员进行后台管理,包括为集群增加新的机器、划分资源组、查看集群资源和负载、追踪任务状态等。
Driver: Alisa 的调度器, Driver 中实现了任务管理接口和系统理接口;负责任务的调度策略、集群容灾和伸缩、任务失效备援、负载均衡实现。 Drive 的任务调度策略是可插拔替换的,以满不同的使用场景。 Driver 使用 Resource manager 管理整个集群的负载。 (我们可以把 Driver 理解为 Hadoop Job Tracker 。)
Task pool: Driver 也将已经提交的全部任务都放入到 Task pool 中管理,包括等待资源、数据质量检测、运行中、运行成功和败的所有任务。直到任务运行完成(不论成功或者失败),并用户确实获取到了关于这个状态的通知, Driver 将任务从Task pool 中移除。 Driver Node 通过 Task pool 提供的事件机制进行可靠的通信。整个系统全部状态(除了与运行无关的部分管理信息外)都保存在 Task pool 中,这样系统的其他部分很易实现高可用性和伸缩性。而 Task pool 本身采用 Zookeeper现,这样它本身也是具备高可用能力的。
Resource manager :这个组件专注于集群整体资源的管理。
Task container :类似于 Web Server ,为 Task 提供运行的容器(似的, Web Server Action 提供运行的容器)。容器负责处理Task 的公共逻辑,如文件下载,任务级 Session 、流程级 Session的维护等。同时 Task container 负责收集机器的实际负载并上报给Resource manager。
Session manager :这个组件实现了对 Task session 的管理。
Node: Node 代表 Alisa 集群中的 个节点。节点负责提供任运行所需的物理资源。 Node 是逻辑概念, 台物理机器上可部署一个或者多个 Node (Node 类似于 Hadoop的TaskTracke)。
- 调度系统的应用
调度配置
定时调度
周期调度
手动运行
补数据
基线管理
监控警报