目录
1.业务场景
2.传统hash算法
2.一致性hash算法
2.1.算法过程
2.1.一直性hash算法的优点
2.2.一致性hash算法的缺点
2.3.hash倾斜的解决办法
1.业务场景
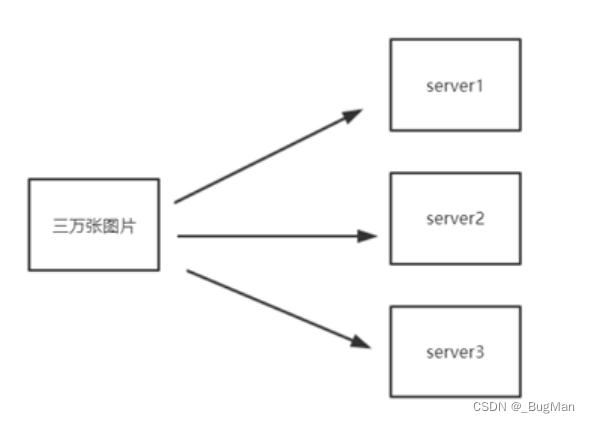
假设有30000张图片需要存放到编号为1、2、3的3台服务器上。
2.传统hash算法
假设有30000张图片需要存到3台服务器上,先给服务器编个号1、2、3,那么很显然使用设计一个碰撞小的hash函数,对每个图片的唯一标识(图片编号之类的)进行hash运算,然后将hash值%3=该图片应该存放的服务器编号。
当需要查找该图片的时候用key来重复以上过程就可以知道图片存放的位置在哪里。
传统hash算法的缺陷:
一旦新增一个服务器结点,会影响全局,需要全局重新进行hash运算。
2.一致性hash算法
2.1.算法过程
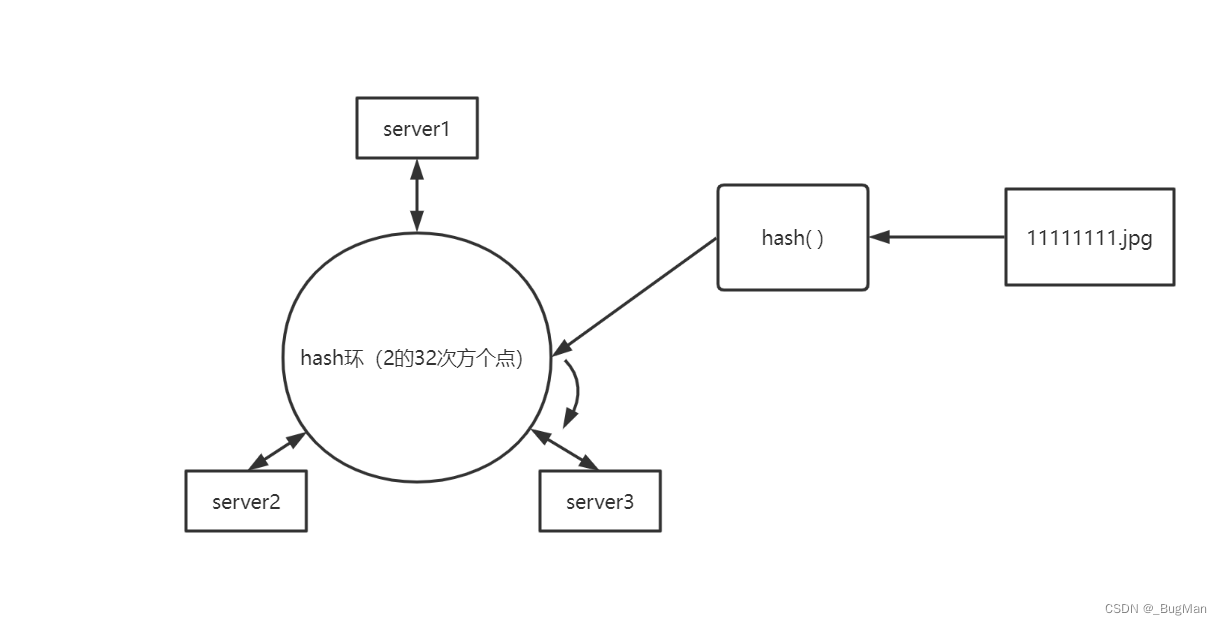
一致性hash算法不再是对服务器的数量进行取模,而是对“hash环”进行取模。
hash环:
假设有2的32次方个点,组成了一个虚拟的环,这个环称为hash环。之所以是2的32次方是因为32位(不用64位是为了向下兼容)的操作系统1个指针是4字节,1个字节是8位,也就是说1个指针能指向的内存地址有2的32次个。
一致性hash算法的过程:
整个过程开始前先对服务器进行散列,取服务器的唯一标识(一般就是用IP地址了)计算出服务器的hash值在hash环上对应的点。
然后进行图片的散列,取图片的唯一标识进行hash运算,然后将得到的hash值对2的32次方进行取模得到图片在hash环上的对应的点,如果这个点正好落在服务器上那就说明图片应该存在这台服务器上,如果没有则找到顺时针方向的第一台服务器,这台服务器就是图片应该存储的服务器。
2.1.一直性hash算法的优点
如果新增一台服务器D,可以发现受影响的就只有一小部分,大部分的数据都不会受影响,
查找的时候都可以准确的找到。要重新做hash运算,重新进行散列的也只有受影响的那一小部分。
2.2.一致性hash算法的缺点
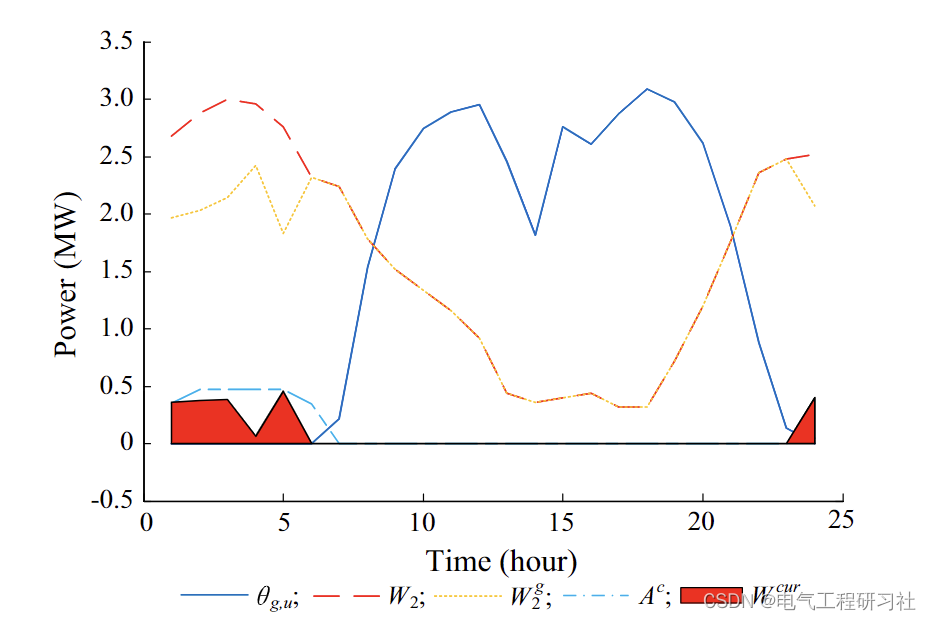
hash偏斜,即存在服务器结点能映射到它上面的hash值明显要多于其他结点,直白点说就是在hash环上管了更多的范围,存了更多的图片。上图三台服务器分布在hash环上的位置是均匀的,但是这种理想情况很少,现实中很可能都是分布不均匀的,比如按照下图,可以明显看到很大几率运算出来的图片存放位置会是A,这样也会造成存储的不均匀。

2.3.hash倾斜的解决办法
解决hash倾斜的方法就是加服务器,很明显环上服务器结点越多被管的范围就切得越小,图片的存放越可能趋近于均匀。当然在实际中增加物理服务器结点的可能性是不大的,成本太高了,可以通过增加虚拟节点然后将虚拟节点映射到实际存在的物理节点即可。