系列文章目录
文章目录
- 系列文章目录
- 前言
- 1、引入库
- 2、读取dat文件
- 3、输出行列数控制(省略号去除)
- 4、只显示前/后几行
- 5、保存为Excel
- 总结
前言
1、引入库
import pandas as pd
import numpy as np
import sys
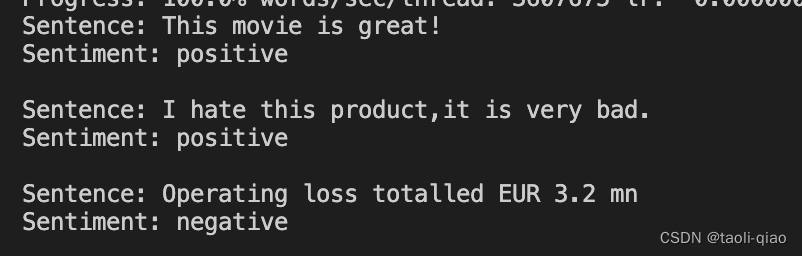
2、读取dat文件
2.1、第一种读取
df = pd.read_table(r"E:\py\python3.7\test\test66dat\1.dat",header=None,engine='python')
2.2、第二种读取
import pandas as pd
import numpy as np
f=open(r'E:\py\python3.7\test\test66dat\1.dat',encoding='utf-8')
sentimentlist = []
for line in f:
s = line.strip().split('\t')
sentimentlist.append(s)
f.close()
df_train=pd.DataFrame(sentimentlist)
print(df_train)
3、输出行列数控制(省略号去除)
去除省略号只需将对应参数设置大一些即可
pd.set_option('display.max_rows', None) # 设置显示最大行数,None为显示所有行
pd.set_option('display.max_columns', None) # 设置显示最大列数,None为显示所有列
pd.set_option('display.max_colwidth',200) # 设置显示最大列宽
pd.set_option('display.width', 200) # 设置字符显示宽度
4、只显示前/后几行
df = df.head(20) #只显示前20行,若不填数字,默认为5行
df = df.tail(20) #只显示前20行,若不填数字,默认为5行


5、保存为Excel
df.to_excel(r"E:\py\python3.7\test\test66dat\1.xlsx", index = False)
总结
分享:
优雅的代码第一眼看上去,就知道它的用处,而且很简洁。但是这样的解决方案不是那么容易想出来的。这就是说,优雅是易于理解和辨识的,但是要想创建出来就困难得多了。