FastText概念介绍
FastText 是一个由 Facebook 开发的用于文本分类和向量化的开源工具,它是 Word2Vec 的一个拓展,能够处理词汇中的子词信息。FastText 基于神经网络模型,可以将词语表示为高维向量,并且保留了词汇中的语义信息。FastText 的主要作用包括:
-
文本分类:FastText 可以对文本进行分类。它通过学习文本中的特征,可以将文本分类成不同的类别。这使得 FastText 在自然语言处理和文本分类任务中具有广泛的应用。
-
词向量表示:FastText 可以将每个词语表示为高维向量。这些向量包含词语的语义信息,因此可以用于衡量不同词语之间的相似度。这些向量可以用于各种自然语言处理任务,如词义消歧、文本分类、聚类等。
-
处理低频词:FastText 能够处理低频词。由于词向量是由词汇的子词组成的,因此即使一个词语很少出现在训练数据中,它的向量仍然可以被计算出来。这使得 FastText 能够更好地处理低频词,从而提高了其在自然语言处理任务中的性能。
-
训练速度快:FastText 可以在大规模语料库上快速训练模型。这得益于其采用的分层 softmax 技术和并行化训练方法。这使得 FastText 成为处理大量文本数据的理想选择。
文本分类Demo
上面是理论介绍,接下来看看如何使用FastText完成情感分析,下面的代码中先准备了一份训练数据,这份训练数据来源于kaggle,训练数据中包含多条被标记为negative,positive,neutral的句子。下面的代码中将csv格式的原始数据,转换成fasttext能读取的txt格式的数据,然后调用fasttext.train_supervised进行训练,训练完成后,给了三条测试数据来检验模型的正确率。
import fasttext
import pandas as pd
# Load the training data from CSV file
df = pd.read_csv('./fasttext/sentiment_data.csv')
sentences = df['Sentence'].tolist()
labels = df['Sentiment'].tolist()
# Create the FastText training data file
with open('./fasttext/train.txt', 'w') as f:
for sentence, label in zip(sentences, labels):
f.write(f"__label__{label} {sentence}\n")
# Train the model
model = fasttext.train_supervised(
input='./fasttext/train.txt', epoch=25, lr=1.0, wordNgrams=2, bucket=200000, dim=50, loss='ova')
# Test the model
test_data = ["This movie is great!",
"I hate this product,it is very bad.", "Operating loss totalled EUR 3.2 mn "]
for sentence in test_data:
result = model.predict(sentence)
label = result[0][0].replace('__label__', '')
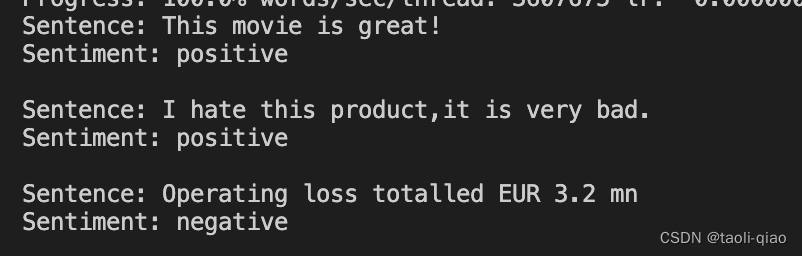
print(f"Sentence: {sentence}\nSentiment: {label}\n")下面是三条测试数据的预测结果,可以看到第二个结果并不正确,实际是一句negative的句子,但是预测结果是positive,预测不正确和训练数据也有很大关系,上面的csv文件只有几千条数据而已,第三句是从训练数据中提取的某个句子的部分,预测就正确了。
上面的例子是通过传入数据训练模型,传入测试数据检测训练的模型的正确率。实际还可以下载fasttext预训练好的模型,直接传输测试数据看模型的正确率。下面的代码中直接加载训练好的sentiment_model.bin模型,官网提供了各种预训练模型下载。因为模型一般都是G级别。
import fasttext
import pandas as pd
# Load the pre-trained model
model = fasttext.load_model('sentiment_model.bin')
# Load the test dataset
test_data = pd.read_csv('test.csv')
# Define a function to predict sentiment for a single sentence
def predict_sentiment(sentence):
result = model.predict(sentence)
label = result[0][0].replace('__label__', '')
return label
# Classify the sentences in the test dataset and store the results in a new column
test_data['Predicted Sentiment'] = test_data['Sentence'].apply(predict_sentiment)
# Print the accuracy of the model on the test dataset
correct = 0
total = len(test_data)
for index, row in test_data.iterrows():
if row['Sentiment'] == row['Predicted Sentiment']:
correct += 1
accuracy = correct / total
print(f'Accuracy: {accuracy:.2f}')
词向量表示Demo
上面的代码是直接使用fasttext.load_model来加载模型,当然,还可以使用gensim来加载模型。下面的代码中就使用gensim来加载"cc.en.300.bin"模型,加载模型后,通过model.wv['word]方法获取文本的向量,还可以通过model.wv.similarity()计算不同word的相似度。
from gensim.models.fasttext import load_facebook_model
# 加载 FastText 模型
model = load_facebook_model("cc.en.300.bin")
# 获取单词的向量表示
vector = model.wv['word']
# 计算两个词之间的相似度
similarity = model.wv.similarity('word1', 'word2')
# 使用词向量来推断一个单词的意思
inferred_vector = model.infer_vector(['text', 'classification', 'task'])
总结
当你下载了已有的pre-model来对句子做情感分析的时候,可能结果不一定理想,为什么呢?因为,FastText 适用于离散标记(discrete tokens)。离散标记指的是对文本进行分词(tokenization)之后得到的单词或词语等离散单元,例如 "cat"、"dog"、"is"、"a" 等。这种文本表示方法不考虑单词之间的顺序和连续性,将文本看作是由一系列离散单元组成的集合。相比之下,连续标记则更注重文本中单词的顺序和连续性。例如,一个句子"I does not like the product",实际是一个negative的句子,但是因为Fasttext是适用于离散标记,无法处理多个词语连起来的含义,很有可能会把他判断成positive的句子,因为有like这个单词。