论文:https://arxiv.org/abs/2205.14375
代码:https://github.com/pranavphoenix/WaveMix
文章目录
- ABSTRACT
- Introduction
- Background and Related Works
- WaveMix Architectural Framework
- Overall architecture
- WaveMix block
- Experiments and Results
- Tasks, datasets, and models compared
- Implementation details
- Semantic segmentation
- Image classification
- Image Super-resolution
- Parameter efficiency
- Ablation studies
- Conclusions, Future Directions, and Impact
ABSTRACT
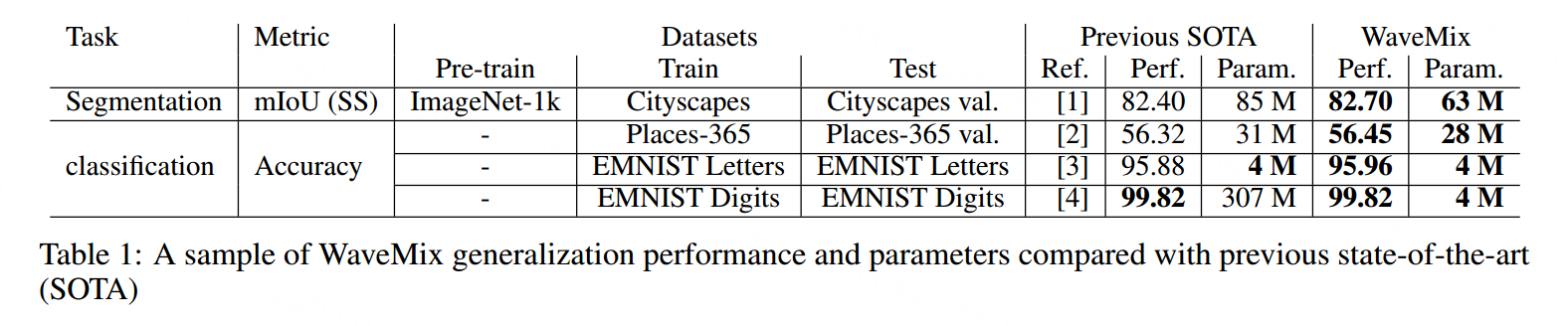
我们提出了WaveMix——一种新颖的计算机视觉神经架构,既资源高效,又具有泛化性和可扩展性。WaveMix网络在多个任务上实现了与最先进的卷积神经网络、视觉Transformer和token mixer相当或更好的准确性,为Cityscapes上的分割和Places-365、五个EMNIST数据集以及iNAT-mini上的分类建立了新的基准。值得注意的是,与之前的最先进方法相比,WaveMix架构所需的参数更少。此外,在控制参数数量的情况下,WaveMix所需的GPU RAM更少,从而节省时间、成本和能量。为了实现这些优势,我们在WaveMix块中使用了多级二维离散小波变换(2D-DWT),它具有以下优点:(1)它根据三个强图像先验重新组织空间信息——尺度不变性、平移不变性和边缘的稀疏性,(2)以无损的方式而不增加参数进行操作,(3)同时减少特征图的空间大小,从而减少前向和后向传递所需的内存和时间,以及(4)比卷积更快地扩大感受野。整个架构是一系列自相似且分辨率保持的WaveMix块的堆叠,为各种任务和资源可用性水平提供了架构灵活性。我们的代码和训练模型已公开提供。
Introduction
自然图像具有许多先验知识,在任何单一类型的神经网络架构中都没有得到全面利用。例如,卷积神经网络(CNN)只使用卷积设计元素来模拟平移不变性[5, 6, 7, 8, 9, 10, 11, 12],视觉Transformer(ViT)使用自注意机制来模拟长程依赖关系[13, 14],而token mixer也模拟长程依赖关系,但不具备自注意机制的二次复杂性[15, 16, 17]。然而,这些架构都没有充分利用其他图像先验,比如尺度不变性(例如,由于某一类别对象在图像中的深度变化)和边缘的空间稀疏性(例如,由于有限对象边界的遮挡)。此外,Transformer和token mixer在不进行重大架构改变的情况下,无法轻松地用于像分割和超分辨率这样的逐像素任务[17]。
我们通过提出一种名为WaveMix的新型计算机视觉神经架构来解决架构灵活性和全面利用自然图像先验的挑战,该架构在各种任务中以更少的资源实现更好的泛化性,如表1所示。
**WaveMix的核心是三个设计要素:一堆自相似的WaveMix块、每个块中的多级二维离散小波变换(2D-DWT)以及块内的空间分辨率收缩和扩展回原始尺寸。**使用自相似的堆叠块使得该架构具有可扩展性,这在CNN和transformer中都有应用过[17, 14]。另外两个设计要素以及我们的关键贡献,结合自适应、广泛的实验和分析来展示WaveMix设计的多样性、实用性和简明性。
在第2节中,我们将WaveMix与之前的工作联系起来,深入探讨了不同类别的视觉神经架构模拟的图像先验,以及使用小波变换填补的空白。尽管在小波变换领域中这是众所周知的,但在深度神经网络的背景下,这种分析是新颖的。
我们的关键创新——WaveMix块、每个块中多级2D-DWT的使用、通道混合和特征张量维度的保留——及其原理在第3节中解释。我们解释了如何通过使用多级2D-DWT来混合空间信息,从而利用图像中的平移不变性、尺度不变性和边缘的稀疏性。我们的全卷积框架不需要进行重大的架构改变(例如,特征图平坦化、编码器-解码器结构和跳跃连接[18]),以适应不同的图像尺寸和任务。与Transformer编码器类似,WaveMix在块之间保持特征图的分辨率,但与Transformer不同的是,它能够很好地处理图像尺寸和输出类型的变化。我们还解释了2D-DWT如何使用适合图像的下采样特性,从而降低了下一层通道混合的资源(内存和计算)需求。
在第4节中,我们展示了全面的实验和结果,将WaveMix与其他多个最先进模型进行了比较,证明了WaveMix模型在泛化方面可以与规模更大的SOTA模型相媲美或超越。用于图像分类的数据集包括ImageNet-1k、iNAT-2021、Places-365和EMNIST;用于语义分割的是Cityscapes;用于单幅图像超分辨率的是DIV2K和Urban100。除了泛化性能,我们还提供了WaveMix架构的可扩展性(通过添加WaveMix块或通道来增加泛化性)和简洁性(更少的参数、GPU RAM需求和推理时间)的证据。
我们还检查了组成部分的重要性以及它们在WaveMix块中的放置顺序。我们展示了每个块中感受野如何扩大,并解释了为什么波尺度和波滤波器不能简单地被其他滤波器(如FNet中的随机矩阵或傅立叶基础)所取代。
在第5节中,我们进行了总结,并提出了未来的工作方向。
Background and Related Works
自然图像的统计特性已经得到了深入研究,包括平移不变性、尺度不变性、高空间自相关性、特定颜色的优势,以及边缘的空间稀疏性[20, 21, 22, 23]。
平移不变性是信号的一种稳定性形式,因为假设物体和视觉特征在位置上近似均匀分布。尺度不变性来自于一个物体可能与摄像机之间的任意距离,以及物体、它们的部分,以及部分的部分等之间的分层关系[24]。高自相关性是因为每个物体在自身内部相对较均匀,与场景中其他物体相比。物体的有限空间范围导致了以边缘形式表现的空间稀疏遮挡边界。自然选择促进了具有外表上类似边缘模式的伪装物种的生存。
二维离散小波变换(2D-DWT)已经广泛研究,用于多种应用,包括去噪[25]、超分辨率[26]、识别[27]和压缩[28]。使用小波变换提取的特征还广泛用于机器学习模型[29],如支持向量机和神经网络[30],特别是用于图像分类[31]。将小波集成到神经架构中的一些实例包括以下几种。ScatNet架构通过级联小波变换层、非线性模量和平均池化来提取平移不变特征,这些特征对于图像分类具有鲁棒性,并保留了高频信息[32]。WaveCNets用2D-DWT替代CNN的最大池化、步幅卷积和平均池化,用于抗噪图像分类[33]。
多级小波卷积神经网络(MWCNN)用于图像恢复,以在感受野大小和计算效率之间取得更好的平衡[34]。小波变换也与全卷积神经网络结合,用于图像超分辨率[35]。使用小波进行池化的效果与其他池化技术相当[36]。WaveSNet使用DWT进行下采样和逆DWT进行上采样,用于分割[37]。
1D-DWT将输入信号x(长度为H)分成大约长度为H/2的两个子带。第一个称为近似子带wa(x),可以看作原始信号的低分辨率版本。在最简单的Haar小波中,wa(x)与输入两个连续样本的和成比例,然后通过2的因子下采样。第二个称为细节子带wd(x),用于捕获近似子带丢失的信息。在Haar小波中,wd(x)与两个连续样本的差成比例,然后通过下采样运算。也就是说,两个子带都是用2x1的滤波器进行卷积,步长为2,可以看作是局部低频和高频分量,它们彼此正交并紧凑地表示信号能量[39]。
2D-DWT是将1D-DWT应用于2-D信号的行,然后在得到的行上进行列向1D-DWT。2D-DWT具有一个近似子带waa和三个细节子带wad、wda、wdd[40]。可以进一步使用重复的小波变换对近似子带进行分解,得到的分解称为二级变换。所有子带都模拟平移不变性,细节子带模拟空间导数(例如边缘),而级数模拟空间尺度[38]。
过去十年中,由于架构创新使得梯度流向更深层次[41, 8],或者通过限制卷积核大小[7]或仅在一个维度上应用卷积[42]来减少每层参数,CNN在各种视觉任务上的泛化精度显著提高。空间或通道的注意层似乎在某种程度上提高了CNN的性能[43],但由于在深层CNN架构中并没有明显优势,因此在视觉任务中没有广泛采用。
视觉转换器(ViTs)受到在自然语言处理任务上使用transformers的成功启发,它使用一维的令牌序列来对应图像的图块(子图像、平铺)[14]。尽管ViTs已经证明是可扩展的模型,在图像分类方面比CNNs更具泛化性,但是在图块令牌化过程中可能会破坏潜在有用的二维结构,这需要通过使用非常大的数据集和参数数量来重新学习在被破坏的方向(例如垂直方向)上类别特定的空间关联,这种方法并不直观。例如,固定图像的行大小被用于学习垂直方向上的关系。训练这些模型需要访问大型GPU集群。
虽然对于基于图像推理,视觉特征之间存在一些长程关联需要学习,但是使用二次自注意力可能是过度设计,不像在自然语言处理中明显具有优势。此外,这样的模型在像素级和空间局部任务(例如分割和增强)中可能甚至提供的优势更小,因为它们使用非重叠的图块。此外,这种远离使用二维网格结构的方法导致了架构的不灵活性,使得同一个预训练模型可以用于多少任务和图像大小。
混合模型旨在通过将图像特定的归纳偏差以附加的架构元素形式整合进视觉转换器,其中包括蒸馏[44]、卷积嵌入[45,46]、卷积令牌[47]和编码重叠图块[48],从而减少视觉转换器的计算要求。与transformers相比,transformers在序列长度(令牌数量)方面的二次复杂性也导致了对于有效混合令牌的其他线性近似的探索[45]。然而,这些模型遭受与ViTs类似的不灵活性。
使用固定的令牌混合机制(例如傅立叶变换)替换transformers中的自注意力的令牌混合器,在自然语言处理任务上实现了具有可比较泛化性能的低计算需求[19]。还提出了其他令牌混合架构[49],其中使用标准的神经组件,如卷积层和多层感知器(MLPs,即1x1卷积滤波器)来混合视觉令牌。MLP-mixer首先对图像图块序列应用两个MLP层,然后对通道维度进行令牌混合[15]。ConvMixer使用标准卷积处理空间维度,使用深度卷积处理通道维度,以较少的计算量混合令牌,而不是使用注意力机制[17]。PoolFormer使用池化作为令牌混合操作[49]。与transformers相比,这些令牌混合模型的性能高效,而且不损害泛化性能。然而,这些模型没有很好地利用图像的先验信息。
视觉转换器(ViTs)受到在自然语言处理任务上使用transformers的成功启发,它使用一维的令牌序列来对应图像的图块(子图像、平铺)[14]。尽管ViTs已经证明是可扩展的模型,在图像分类方面比CNNs更具泛化性,但是在图块令牌化过程中可能会破坏潜在有用的二维结构,这需要通过使用非常大的数据集和参数数量来重新学习在被破坏的方向(例如垂直方向)上类别特定的空间关联,这种方法并不直观。例如,固定图像的行大小被用于学习垂直方向上的关系。训练这些模型需要访问大型GPU集群。
虽然对于基于图像推理,视觉特征之间存在一些长程关联需要学习,但是使用二次自注意力可能是过度设计,不像在自然语言处理中明显具有优势。此外,这样的模型在像素级和空间局部任务(例如分割和增强)中可能甚至提供的优势更小,因为它们使用非重叠的图块。此外,这种远离使用二维网格结构的方法导致了架构的不灵活性,使得同一个预训练模型可以用于多少任务和图像大小。
混合模型旨在通过将图像特定的归纳偏差以附加的架构元素形式整合进视觉转换器,其中包括蒸馏[44]、卷积嵌入[45,46]、卷积令牌[47]和编码重叠图块[48],从而减少视觉转换器的计算要求。与transformers相比,transformers在序列长度(令牌数量)方面的二次复杂性也导致了对于有效混合令牌的其他线性近似的探索[45]。然而,这些模型遭受与ViTs类似的不灵活性。
使用固定的令牌混合机制(例如傅立叶变换)替换transformers中的自注意力的令牌混合器,在自然语言处理任务上实现了具有可比较泛化性能的低计算需求[19]。还提出了其他令牌混合架构[49],其中使用标准的神经组件,如卷积层和多层感知器(MLPs,即1x1卷积滤波器)来混合视觉令牌。MLP-mixer首先对图像图块序列应用两个MLP层,然后对通道维度进行令牌混合[15]。ConvMixer使用标准卷积处理空间维度,使用深度卷积处理通道维度,以较少的计算量混合令牌,而不是使用注意力机制[17]。PoolFormer使用池化作为令牌混合操作[49]。与transformers相比,这些令牌混合模型的性能高效,而且不损害泛化性能。然而,这些模型没有很好地利用图像的先验信息。
我们的工作将卷积神经网络(CNNs)、令牌混合器和小波变换的思想结合起来。
WaveMix Architectural Framework
基于前面部分提到的小波变换的特性,包括平移不变性、多尺度分析、边缘检测、局部操作和能量压缩,我们建议将其作为神经网络架构中的"token mixers"(标记混合器)、“feature reorganizers”(特征重组器)和"spatial compactors"(空间压缩器),并保持权重固定,在计算机视觉领域中使用。
Overall architecture
如图1(a)、(b)和©所示,所提出的框架的宏观层面思想是堆叠N个(一个超参数)相似的WaveMix块,这些块的设计在空间维度上完全是卷积的,并在块之间保持特征图的空间分辨率。虽然一些卷积神经网络(CNN)是完全卷积的,但是视觉Transformer架构倾向于保持序列长度(即空间分辨率的扁平化版本)。将这两个元素结合在一起,使WaveMix具有架构上的灵活性,能够轻松适应不同的图像尺寸和任务。例如,对于语义分割或图像增强,该框架自然产生像素映射,但是添加一个可选的MLP层用于通道混合,然后进行全局平均池化和Softmax操作就足以将其适应各种大小的图像分类。也就是说,WaveMix将图像处理为一个二维网格,而不是像Transformer模型中那样将其展开为像素/补丁的序列。为了增加灵活性,我们将输入图像x0 ∈ R H×W×3通过一个初始卷积层,将通道数增加到嵌入维度C(即x ∈ R H×W×C,其中C是一个超参数),然后再将其传递给WaveMix块。初始卷积层还可以选择使用步进卷积或将输入分割成补丁[17, 50]来减少输入分辨率。
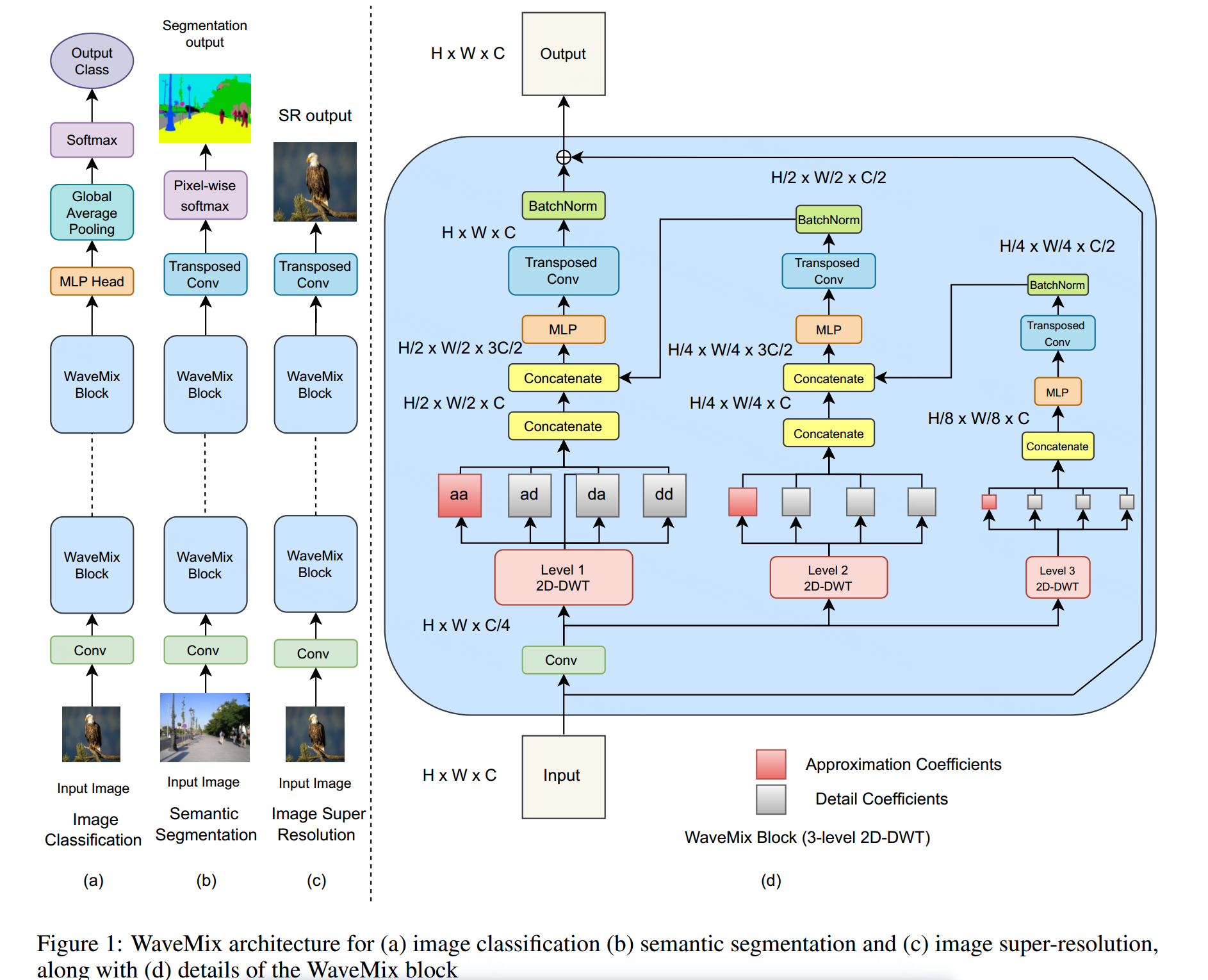
WaveMix block
如图1(d)所示,WaveMix块的设计不会降低特征图的空间分辨率,不同于使用池化操作的CNN块,比如ResNet [9]中的块。然而,它通过使用2D-DWT减少特征图的空间维度,从而减少了所需的计算量,从而减少了GPU内存、训练时间和推理时间。然而,与池化或步进卷积不同,2D-DWT是无损的,因为它通过与减少空间分辨率的因子相同的因子扩展了通道数。此外,它还具有其他能量压缩(稀疏化)属性,这是随机滤波器或傅立叶基础所不具备的。
将WaveMix块的输入和输出张量分别表示为xin和xout;小波变换的级别表示为l ∈ {1…L};每个级别上的四个小波滤波器以及它们的下采样操作分别表示为wlaa、wlad、wlda和wldd(其中a表示近似,d表示细节);卷积、多层感知器(MLP)、转置卷积(upconvolution)和批归一化操作分别表示为c、m、t和b;它们各自的可训练参数集表示为ξ、θl、φl和γl;沿通道维度的串联表示为⊕,点对点的加法表示为+,WaveMix块内部的操作可以用以下方程表示:
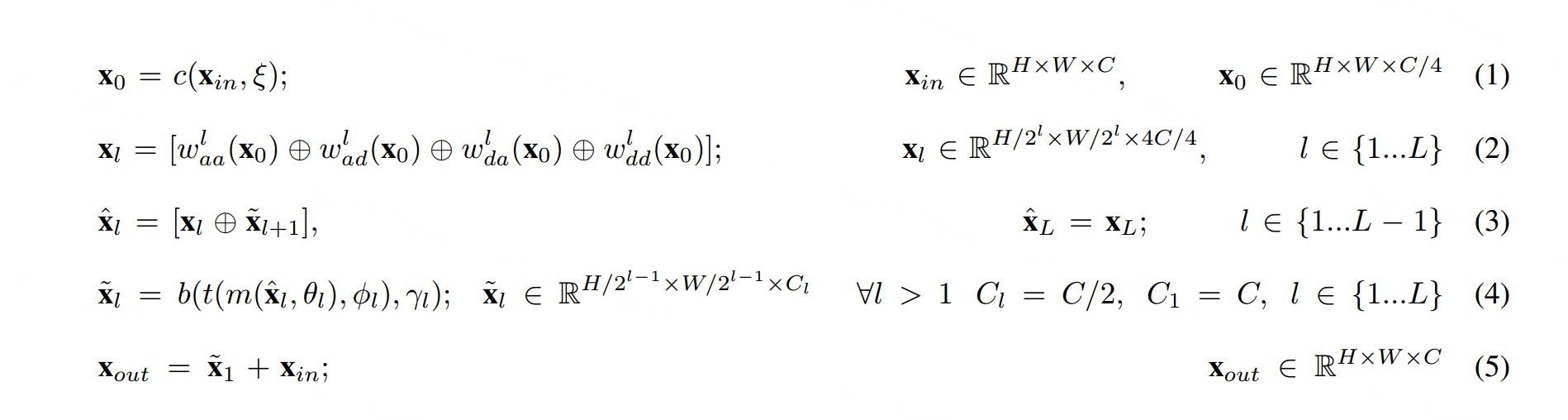
WaveMix块使用卷积层提取可学习的和空间不变的特征,然后通过多级2D-DWT(二维离散小波变换)进行空间尺度不变的特征提取,其中包括空间标记混合和下采样[51]。接着,使用可学习的MLP(1×1卷积)层进行通道混合,最后使用转置卷积层恢复特征图的空间分辨率。在小波变换之前使用可训练的卷积是我们架构的关键设计,因为它允许提取适用于所选择的小波基函数的特征图。卷积层c将嵌入维度C减小四倍,以便在每个2D-DWT级别后,经过拼接的输出xl与输入xin具有相同的通道数(等式1和2)。也就是说,由于2D-DWT是一种无损变换,它通过拼接将通道数按相同因子扩展(使用拼接),同时通过计算适用于每个输入通道的近似子带(低分辨率近似)和三个细节子带(空间导数)[38]来减小空间分辨率(等式2)。使用这种图像适用且无损的2D-DWT下采样使得WaveMix可以使用更少的层和参数。每个级别的DWT的四个输出被拼接在一起形成xl(等式2)。
我们根据图像大小决定小波分解的级别L。实验证明,使用三个或四个级别的2D-DWT足以确保在较长的空间距离上进行标记混合。例如,对大小为128×128的图像进行3级DWT分解会同时创建大小为64×64、32×32和16×16的特征图,这足以进行空间标记混合。使用更多级别的DWT会指数增加感受野,但也会放大模型中的噪声[38],从而降低性能。
每个级别DWT的输出xl与下一个更高级别路径˜xl+1的输出按照等式3进行拼接。然后将输出ˆxl传递给MLP层m,其中包含两个1×1卷积层,采用反向瓶颈设计(乘法因子>1),中间使用GELU非线性激活函数。之后,使用转置卷积层t将特征图的分辨率扩大两倍,然后进行批归一化b(等式4)。我们不在每个DWT级别路径中使用上采样卷积直接将图像调整回原始输入分辨率,因为这样会需要更大的滤波器尺寸,导致参数呈指数增加。
在使用批归一化b之前,较高级别DWT路径输出的通道数通过转置卷积层t减半(等式4)。输出˜xl与前一级别的DWT输出xl−1(等式3)进行拼接。因此,来自较高级别DWT的特征在较低级别逐渐累积,最终输出在所有标记混合和特征提取之后,由来自第1级路径的˜x1得到。使用残差连接以便于梯度传播[41](等式5)。
紧随2D-DWT后的前馈(MLP)子层可以访问相应级别和较高级别(经过转置卷积的)的输出,以学习局部和全局特征。由于信息的跨层传递和特征的累积,WaveMix能够提取具有不同尺度和抽象层次的特征,从而增强了模型的表示能力。
来自较高层级的信息向较低层级传播,局部和全局信息的混合使得模型能够在更少的参数和层级下高效学习。这种多分辨率信息的混合也导致感受野的扩展速度比CNN层快得多。仅使用2×2的内核,2D-DWT能够在每个WaveMix块内达到2 L × 2 L个像素(附录)。
在不同类型的母小波中,我们使用了Haar小波(是Daubechies小波[38]的一种特殊情况,也被称为Db1),由于其简单和更快的计算速度,Haar小波被广泛使用。Haar小波在性质上既是正交的又是对称的,并且已广泛用于从图像中提取基本结构信息[52]。对于偶数大小的图像,它将图像尺寸完全减小了2倍,这简化了后续层的设计。
小波变换的一个介绍:https://blog.csdn.net/x1131230123/article/details/131973736
Experiments and Results
我们将WaveMix模型与各种CNN、Transformer和标记混合模型进行了语义分割和图像分类的比较。我们还对单图像超分辨率进行了一些初步实验。通过消融研究,我们评估了超参数的影响以及WaveMix块中每个组件及其位置的重要性。
Tasks, datasets, and models compared
在语义分割任务中,我们使用了Cityscapes [53] 数据集(受MIT许可证保护)。官方的训练数据集被划分为训练集和验证集。其他对比模型的结果直接取自它们在Table 2中引用的原始论文。由于ConvMixer [17] 从未用于语义分割,我们将ConvMixer的分类头替换为类似于WaveMix用于分割实验的分割头。我们在Cityscapes官方验证数据集上比较了各个模型的平均交并比(mIoU)作为泛化度量。所有结果都使用单一尺度(SS)推断进行计算。在单个GPU上的推断吞吐量以每秒帧数(FPS)报告。
在图像分类任务中,我们使用了多种类型的公开数据集(受MIT许可证保护),包括CIFAR-10、CIFAR-100 [54]、EMNIST [55]、Fashion MNIST [56]、SVHN [57]、Tiny ImageNet [58]、ImageNet-1K [59]、Places-365 [60]和iNaturalist2021-10k(iNAT-2021-mini)[61]。在ImageNet-1K数据集上进行图像分类的模型包括ResNets [41]和MobileNetV3 [62]作为CNN;ViT(视觉Transformer)[14]作为Transformer;ConvMixer [17]、MLP-Mixer [15]和PoolFormer [49]作为标记混合器。根据流行的协议 [46],基于随机初始化的三次运行中的最佳结果在测试集上的Top-1准确率作为泛化度量进行报告。
对于ImageNet-1K、Places-365和iNAT-mini数据集,我们报告了验证集上的Top-1准确率。GPU内存使用情况在附录中进行了报告。
对于单张图像的2×和4×超分辨率,我们使用DIV2K [63] 的训练集进行训练,并在其验证集以及Urban100数据集 [64] 上进行推断并报告了性能。我们报告了结构相似性指数(SSIM)和峰值信噪比(PSNR)。
对于WaveMix模型的表示法,我们使用格式Model Name - Embedding Dimension/ no. of blocks,并在括号中注明DWT的级别数量。我们将仅使用一个2D-DWT级别的WaveMix模型称为WaveMix-Lite,并且已经证明在小数据集和低分辨率图像上表现良好。对于其他模型,我们使用它们论文中使用的相同表示法。

Implementation details
我们在处理高分辨率图像的所有WaveMix模型中调整了初始卷积层的步长(或补丁大小),以确保在到达WaveMix块之前,特征图的分辨率始终小于128用于分类。对于分割和低分辨率图像(小于128×128)数据集的分类,我们仅在初始卷积层中使用了步幅卷积。对于具有更大图像分辨率的数据集的分类,我们使用了分块卷积。对于超分辨率,初始卷积层不进行分辨率降低。
对于Cityscapes数据集,我们使用全分辨率的1024×2048图像进行训练和推断。对于Places-365、iNAT-mini和ImageNet-1k数据集,图像被调整为256×256和224×224。仅对语义分割进行了水平翻转作为数据增强,对于分类和超分辨率没有使用任何增强方法。超分辨率的高分辨率图像被调整为512×512,低分辨率图像分别被调整为256×256和128×128,用于2×和4×的超分辨率。
对于用于分类和超分辨率的所有WaveMix模型,没有进行预训练。对于ImageNet-1k的分类任务,我们使用了Timm(PyTorch图像模型)库[69]中提供的模型,没有使用预训练权重,并使用了Timm训练脚本[69],其中包含默认的超参数值和增强方法。
由于计算资源有限(这实际上促使我们寻找替代的神经框架),最大的训练周期数设置为300。所有实验都在单个80GB Nvidia A100 GPU上进行。
除了ImageNet-1k分类任务外,我们使用AdamW优化器(α = 0.001,β1 = 0.9,β2 = 0.999,ε = 10^-8)进行初始阶段的权重衰减为0.01,然后在最后50个周期内使用学习率为0.001和动量为0.9的SGD [70, 71]。
图像分类使用交叉熵损失;语义分割使用逐像素的焦点损失;图像超分辨率使用结构相似性损失(SSIM)。对于所有包含完整分辨率Cityscapes数据集的分割实验,使用了批大小为5。分类任务的批大小在256-512之间,超分辨率的批大小为16。我们在训练过程中使用了PyTorch中的自动混合精度技术。
Semantic segmentation
从表1中我们可以看出,在仅使用ImageNet-1k数据集进行预训练的模型中,WaveMix在Cityscapes数据集上的单尺度推理mIoU方面是目前的SOTA。WaveMix在Cityscapes验证集上的性能以及其他模型的报告结果显示在表2中。即使没有ImageNet-1k的预训练,WaveMix的表现与其他使用在ImageNet-1k上预训练的模型相当。在使用了ImageNet预训练权重后,WaveMix的性能优于所有其他CNN和基于transformer的模型。在单个GPU上进行推理时,WaveMix的速度也比之前的SOTA模型SegFromer [1]快2倍以上。通过进行多尺度推理和在ImageNet-22k数据集上进行预训练,可能可以进一步提高性能。
WaveMix的多功能性使得它可以直接用于语义分割,只需将输出层替换为两个反卷积层和一个像素级softmax层来生成分割图。另一方面,对于基本的CNN和transformer [1]来执行分割,需要进行架构更改,如编码器-解码器和跳跃连接 [72]。
通过将ConvMixer [17]的分类头替换为分割头(类似于WaveMix),所得到的较低mIoU(75.78)表明,其他适用于分类的令牌混合架构可能无法在没有重大架构修改的情况下将性能转化为分割。这显示了我们的WaveMix模型的多功能性。此外,WaveMix的GPU消耗比其他模型要低得多。
在WaveMix架构中,反卷积操作是参数的主要贡献者(>75%)。我们可以通过在每个块中使用无参数的上采样操作来进一步降低参数数量。详细信息请参阅附录。
Image classification
表3展示了WaveMix在多个数据集上进行图像分类的性能,这些数据集包含从小到大不同尺寸的图像。在Places-365标准验证集(365类,256 × 256)上,WaveMix取得了56.45%的最优准确率,超越了那些没有在更大数据集上进行预训练的模型,比如[2]。它还在iNAT-2021-mini验证集(10,000类,224 × 224)上取得了最优准确率(之前没有任何关于iNAT-2021 mini的最优结果报告)。我们还可以从表3看到,在不使用任何数据增强的情况下,WaveMix模型在较小的EMNIST数据集(28 × 28)上表现出色,超过了之前在EMNIST [55]的Balanced、Letters、Digits、Byclass和Bymerge子集中取得的最佳结果[73, 74, 4]。它在其他数据集(如SVHN [57]和MNIST [5])上的表现也接近最优状态。
表4展示了WaveMix在使用有限epochs的单GPU上进行ImageNet-1K图像分类的性能。WaveMix模型在CNN和基于transformer的模型以及token-mixers之上表现出色。
使用不可学习的固定权重和更浅的网络结构也使得WaveMix的推理速度比其他架构更快。请参阅附录获取推理速度和GPU消耗的详细信息。
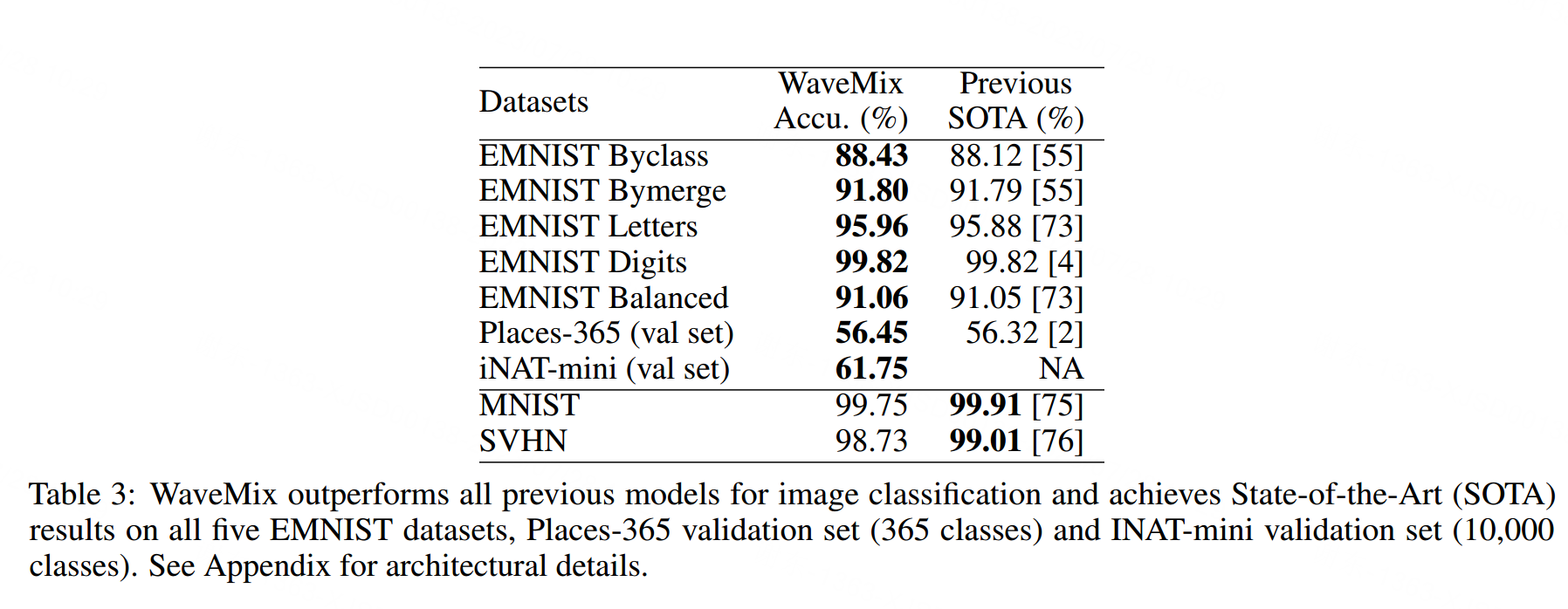
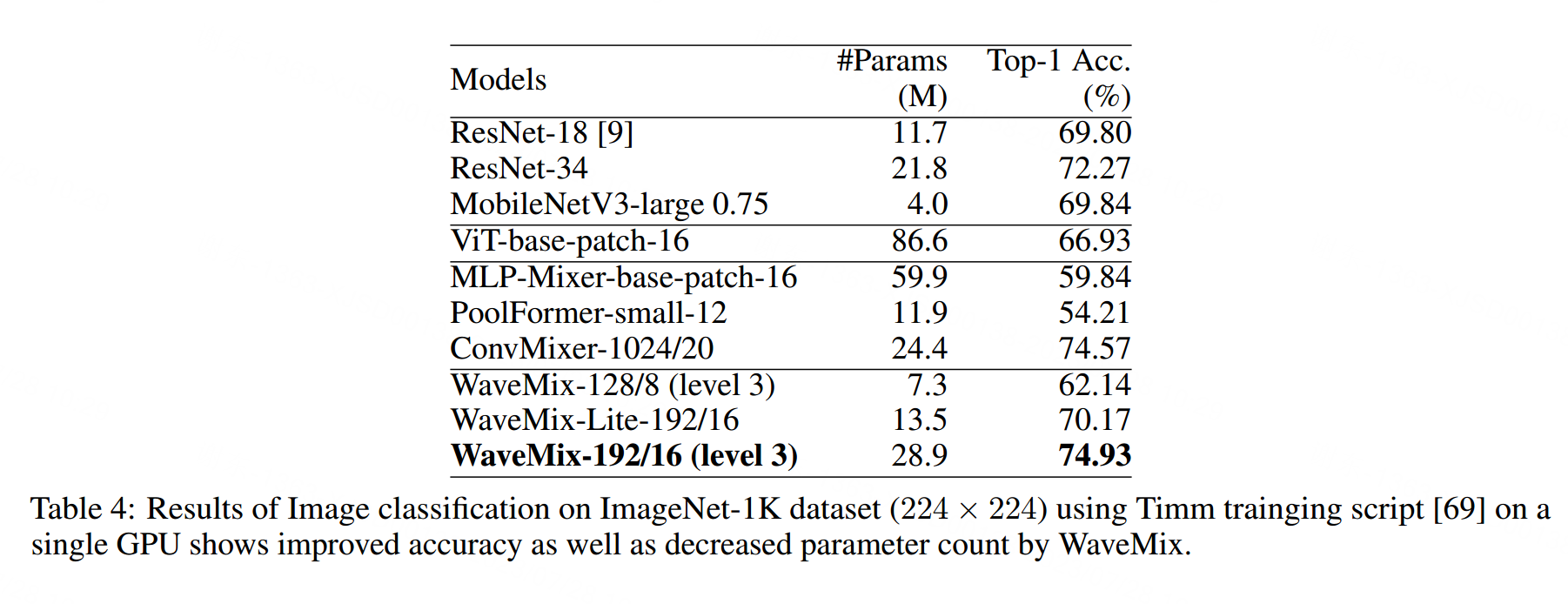
Image Super-resolution
对于图像超分辨率,我们将WaveMix的输出层替换为一个转置卷积层,从而增加图像的分辨率。表5展示了WaveMix在图像超分辨率方面的初步结果。与需要超过4000万参数的最优模型在其上采样网络中一样,WaveMix在不需要大量参数的情况下表现出良好性能[77]。一个浅层的WaveMix(2-4层)就足以取得良好的性能。在对架构和超参数进行更多实验和调整后,我们可以期待WaveMix的性能有所提升。

Parameter efficiency
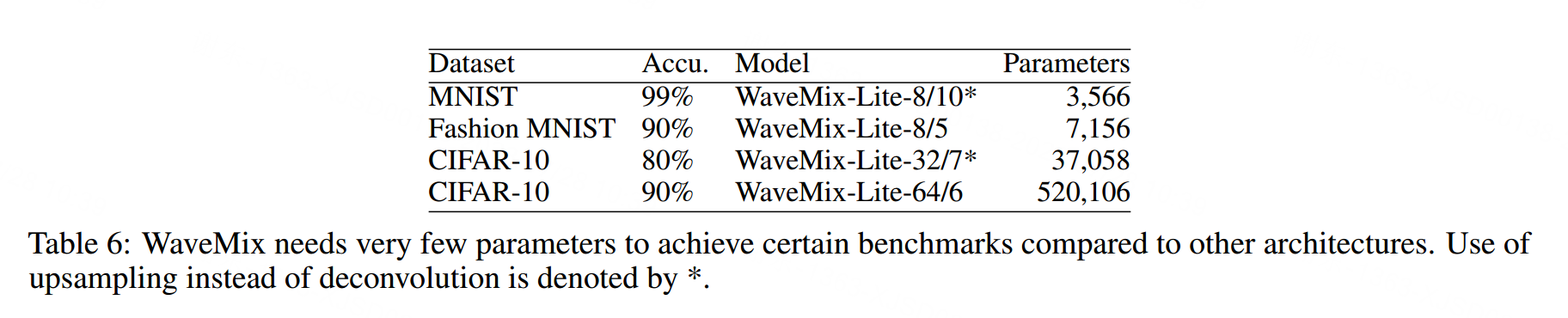
表格6显示WaveMix在与之前模型[78, 79]相比使用更少的参数达到了一定的准确性基准。由于WaveMix大量使用具有固定权重的内核进行令牌混合,因此与常用的架构相比,它使用的参数要少得多。通过使用固定的插值技术(例如逆离散小波变换、双线性或双三次插值)将反卷积层替换为上采样层,我们可以进一步减少参数数量。
Ablation studies
我们在ImageNet-1k和CIFAR-10数据集上对WaveMix进行了消融研究,通过移除2D-DWT层并将其替换为傅里叶变换或随机滤波器以及可学习小波来了解每种类型层对性能的影响。所有这些操作都导致了准确性的降低。那些没有减少特征图分辨率的方法导致了GPU内存消耗的增加。当我们从WaveMix中移除2D-DWT层时,模型的GPU内存需求增加了62%,准确性下降了5%。这是因为MLP接收到的是全分辨率的特征图,而不是来自2D-DWT的半分辨率特征图。将2D-DWT替换为2D离散傅里叶变换(2D-DFT)的实部导致了准确性下降12%,GPU消耗增加73%,因为傅里叶变换也不会降低特征图的分辨率。此外,与小波变换不同,傅里叶变换具有在空间上平滑变化(而非突变)的全局(而非局部)范围的核,不以稀疏方式建模对象边缘,因为它们在有限的空间范围内。
将2D-DWT的滤波器替换为与Haar小波具有相似大小的随机滤波器导致准确性下降6%,这证实了2D-DWT的固定核权重在基于先前研究的计算机视觉中已经很适合使用。当我们将2D-DWT替换为2×2最大池化时,GPU内存消耗增加8%,准确性下降5%,表明后者信息的丢失对泛化能力造成了伤害。
我们使用lifting scheme [80]来创建可学习的小波系数,并观察到与固定Haar小波系数相比性能下降了4%。我们还尝试了不同系列的小波系数,如Daubechies、Coiflet和Symlet,并观察到Haar小波比其他系列的小波更快,且给出更准确的测试结果。我们认为,虽然高阶的Daubechies和其他小波可能更适合用于自然图像的信息压缩,但在第一个卷积层之后的特征图已经是稀疏的,并且可能更适合由Haar小波本身进行分析。
我们通过将反-2D-DWT和双线性上采样层替换掉WaveMix块中的反卷积来比较它们的上采样效果。与反卷积相比,反-2D-DWT和双线性上采样层需要更多的WaveMix块才能实现相似的性能。尽管参数数量低于反卷积,但更大的深度导致了更多的GPU内存消耗以及训练和推理速度较慢。
有关消融研究涉及到的块数、DWT级别、嵌入维度、MLP维度、除Haar外不同类型的小波以及可学习小波的其他详细信息都包含在附录中。
Conclusions, Future Directions, and Impact
我们提出了一种新颖且多功能的神经架构框架——WaveMix,它可以在各种视觉任务中与卷积神经网络(CNNs)和视觉变换器(Vision Transformers)以及它们的混合模型相媲美(有时甚至更好)地实现泛化,同时需要更少的参数、GPU内存和计算时间。WaveMix使用多级2D-DWT进行无损和适当的图像下采样和令牌混合,以建模图像的先验知识,如尺度不变性、平移不变性和边缘稀疏性。与CNNs不同,WaveMix可以从较远的位置混合令牌,因为它可以快速扩展感受野;而与将2D图像展开成1D序列的变换器不同,后者使得它们严格绑定在图像的大小或比例上,而WaveMix直接处理图像的2D格式,使其更容易适应不同的图像大小、比例和任务。
将WaveMix架构适应到其他视觉任务,例如目标检测和实例分割,将是一个值得探索的方向,同样,将其扩展到更深和更宽的比例(增加N和C)也是如此。还需要探索更全面地利用多个图像先验的附加方式,以减少训练可泛化视觉神经网络所需的资源。