KNN工作原理
“近朱者赤,近墨者黑”可以说是KNN的工作原理。整个计算过程分为三步:1:计算待分类物体与其他物体之间的距离;2:统计距离最近的K个邻居;3:对于K个最近的邻居,它们属于哪个分类最多,待分类物体就属于哪一类。K-最近邻算法(K-Nearest Neighbor, KNN)中的K值是一个重要的超参数,不同的K值会影响模型的性能。常见的选择K值的方法包括以下几种
- 网格搜索(Grid Search):指定一组候选的K值,对每个K值进行交叉验证,选取平均交叉验证误差最小的K值作为最佳K值。缺点是需要进行大量的计算,时间开销较大。
- K折交叉验证(K-fold Cross Validation):将训练集分成K个子集,每次使用其中K-1个子集作为训练集,剩下的1个子集作为验证集,重复K次。对于每个K值,计算K次的平均交叉验证误差,选取平均交叉验证误差最小的K值作为最佳K值。这种方法的优点是可以减少模型的方差,但是计算时间仍然比较长。
- 自助法(Bootstrap):从训练集中有放回地随机抽取样本,构建新的训练集。对于每个K值,计算自助样本的平均误差,选取平均误差最小的K值作为最佳K值。这种方法的优点是计算速度快,但是对于小数据集来说,可能会出现较大的方差。
网格搜索(Grid Search)
接下来先看看如何通过网格搜索(Grid Search)获取K值。GridSearchCV是Scikit-Learn库中用于网格搜索的函数,其主要作用是在指定的超参数范围内进行穷举搜索,并使用交叉验证来评估每种超参数组合的性能,以找到最优的超参数组合。该函数包含多个参数,具体参数以及每个参数含义如下所示:
estimator:通常是一个Scikit-Learn模型对象,例如KNeighborsClassifier()、RandomForestClassifier()等,用于表示要使用的模型。
param_grid:需要遍历的超参数空间,是一个字典,其中每个键是一个超参数名称,对应的值是超参数的取值列表。例如,对于KNN模型,可以指定param_grid = {'n_neighbors': [3, 5, 7, 9], 'weights': ['uniform', 'distance'], 'p': [1, 2]},表示K值在3, 5, 7和9中选择,权重方式为'uniform'和'distance',距离度量方式为曼哈顿距离和欧几里得距离。当然,除了这两种距离计算方式,还可以选择:闵可夫斯基距离;切比雪夫距离;余弦距离。
scoring:评价指标,用于评估模型性能的指标,通常是一个字符串或可调用的函数,例如'accuracy'、'f1'、'precision'、'recall'等。如果需要评估多个指标,则可以将评价指标指定为列表或元组。
cv:交叉验证的折数,通常为整数或KFold对象。例如,cv = 5表示将数据集分成5个折,其中4个用于训练,1个用于验证。
n_jobs:并行处理的数量,通常为整数,指定在训练期间使用的CPU数量。如果设置为-1,则使用所有可用的CPU。
verbose:输出详细程度,通常为整数。0表示不输出任何消息,1表示输出少量消息,大于1表示输出更多消息。
return_train_score:是否返回每个超参数组合在训练集上的性能指标。默认情况下,它为False,表示只返回每个超参数组合在验证集上的性
下面是使用GridSearchCV执行分类任务的demo代码,运行demo代码会显示执行的交叉参数组合,且给出最优的参数组合值。
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV, train_test_split
# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.3,
random_state=42)
# 定义待调优的超参数及其取值范围
param_grid = {
'n_neighbors': [3, 5, 7, 9],
'weights': ['uniform', 'distance'],
'p': [1, 2]
}
# 构建KNN模型
knn = KNeighborsClassifier()
# 使用网格搜索进行超参数调优
grid_search = GridSearchCV(knn, param_grid, cv=5, verbose=2)
grid_search.fit(X_train, y_train)
# 输出最优超参数组合及其在验证集上的性能指标
print("Best parameters: ", grid_search.best_params_)
print("Best score: ", grid_search.best_score_)
# 在测试集上进行评估
score = grid_search.score(X_test, y_test)
print("Test score: ", score)K折交叉验证(K-fold Cross Validation)
KFold函数是Scikit-Learn库中用于生成K折交叉验证分割的函数。该函数的主要参数及含义如下:
n_splits:交叉验证折数,默认值为5。shuffle:是否对样本进行随机排序,默认值为False。random_state:随机种子数,默认为None,即随机种子为当前时间戳。indices:指定分割的索引数组,可以用于固定分割以进行可重复的交叉验证。
下面是使用KFold函数,采用交叉验证进行模型评估的demo代码。
from sklearn.datasets import load_iris
from sklearn.model_selection import KFold, cross_val_score
from sklearn.neighbors import KNeighborsClassifier
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 定义模型和超参数
knn = KNeighborsClassifier(n_neighbors=5, weights='uniform', p=2)
# 定义交叉验证的折数
kfold = KFold(n_splits=10, shuffle=True, random_state=42)
# 使用交叉验证进行模型评估
scores = cross_val_score(knn, X, y, cv=kfold)
# 输出平均分数和标准差
print("Accuracy: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2))各类算法准确率对比
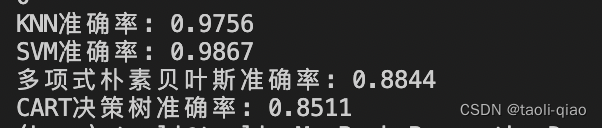
前面介绍了KNN算法、SVM 算法、多项式朴素贝叶斯算法等,下面的demo例子使用手写数字作为训练数据,观察每种算法的精确度,具体code如下所示。其中,sklearn.datasets是Scikit-Learn库中用于加载各种标准数据集的模块之一。load_digits函数可以加载一个手写数字数据集,该数据集包含1797个8x8像素的手写数字图像。每个图像都有相应的标签,表示图像中的数字。该数据集可以用于分类和降维等任务。
# 手写数字分类
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_digits
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.naive_bayes import MultinomialNB
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
# 加载数据
digits = load_digits()
data = digits.data
# 数据探索
print(data.shape)
# 查看第一幅图像
print(digits.images[0])
# 第一幅图像代表的数字含义
print(digits.target[0])
# 将第一幅图像显示出来
plt.gray()
plt.imshow(digits.images[0])
plt.show()
# 分割数据,将25%的数据作为测试集,其余作为训练集
train_x, test_x, train_y, test_y = train_test_split(data,
digits.target,
test_size=0.25,
random_state=33)
# 采用Z-Score规范化
ss = preprocessing.StandardScaler()
train_ss_x = ss.fit_transform(train_x)
test_ss_x = ss.transform(test_x)
# 创建KNN分类器
knn = KNeighborsClassifier()
knn.fit(train_ss_x, train_y)
predict_y = knn.predict(test_ss_x)
print("KNN准确率: %.4lf" % accuracy_score(test_y, predict_y))
# 创建SVM分类器
svm = SVC()
svm.fit(train_ss_x, train_y)
predict_y = svm.predict(test_ss_x)
print('SVM准确率: %0.4lf' % accuracy_score(test_y, predict_y))
# 采用Min-Max规范化
mm = preprocessing.MinMaxScaler()
train_mm_x = mm.fit_transform(train_x)
test_mm_x = mm.transform(test_x)
# 创建Naive Bayes分类器
mnb = MultinomialNB()
mnb.fit(train_mm_x, train_y)
predict_y = mnb.predict(test_mm_x)
print("多项式朴素贝叶斯准确率: %.4lf" % accuracy_score(test_y, predict_y))
# 创建CART决策树分类器
dtc = DecisionTreeClassifier()
dtc.fit(train_mm_x, train_y)
predict_y = dtc.predict(test_mm_x)
print("CART决策树准确率: %.4lf" % accuracy_score(test_y, predict_y))实验结果如下图所示,可以看到KNN和SVM准确率比较接近,多项式朴素贝叶斯和CART决策树准确率稍低。