概述
自从开创性论文 Denoising Diffusion Probabilistic Models 发布以来,此类图像生成器一直在改进,生成的图像质量在多个指标上都击败了 GAN,并且与真实图像无法区分。
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis 以及随后发布的 Instant Neural Graphics Primitives with a Multiresolution Hash Encoding,让我们现在有一种方法可以将多个视图上的对象的稀疏图像集转换为所述对象的 3D 高质量渲染。
然而,尽管通过训练 NeRF 模型获得的辐射场很有前景(无论是使用原始实现还是 InstantNGP 主干进行快速训练),从中提取可用的网格都非常耗费资源,产生噪声结果,并破坏所有照明和材质数据。这是因为 NeRF 模型及其衍生模型通过新视角视图合成,仅参数化了给定某些相机姿势的 3D 场景中点的 RGB 颜色和密度。
虽然将场景表示为神经体块确实具有本质上“烘焙”照明数据的优点,但它实际上并没有进行任何显式计算来至少近似 3D 表面上的 BRDF(双向反射率分布函数)。所有这些实际上意味着表面的光照条件和属性存在模糊性,因为 NeRF 忽略了传统 PBR(基于物理的渲染)中这一非常重要的部分。
幸运的是,我们已经解决了无法从 NeRF 和 NeRF 衍生模型中提取网格和材质的问题。 Extracting Triangular 3D Models, Materials, and Lighting From Images 就是这样一项工作 — 该技术首先涉及使用 NeRF 训练神经体块,使用 DMTet 重建 3D 表面,并通过 nvdiffrast 对模型应用差分渲染。DMTet 和 nvdiffrast 都是可微分阶段,因此使用两个模型的联合梯度优化。这会产生高质量的 3D 网格以及用于可重新照明 3D 对象的 PBR 材质,而无需对输出进行任何修改。
利用 ControlVideo: Training-free Controllable Text-to-Video Generation、GroundingDINO、SegmentAnything、nvdiffrec 的工作,尝试超越 NeRF-DDIM 模型(例如 stable-dreamfusion)用于生成资产质量的 3D 角色。
一. 问题陈述
首先探讨一下生成 3D 角色的需求。
3D 模型用于描绘艺术、娱乐、模拟和绘图的真实世界和概念视觉效果,并且是许多行业不可或缺的一部分,包括虚拟现实、视频游戏、3D 打印、营销、电视和电影、科学和医学成像以及计算机辅助设计。 — 摘自 TechTarget
是的,3D 模型和 3D 角色的使用与数字世界的多个领域息息相关。让我们以视频游戏为主要焦点:
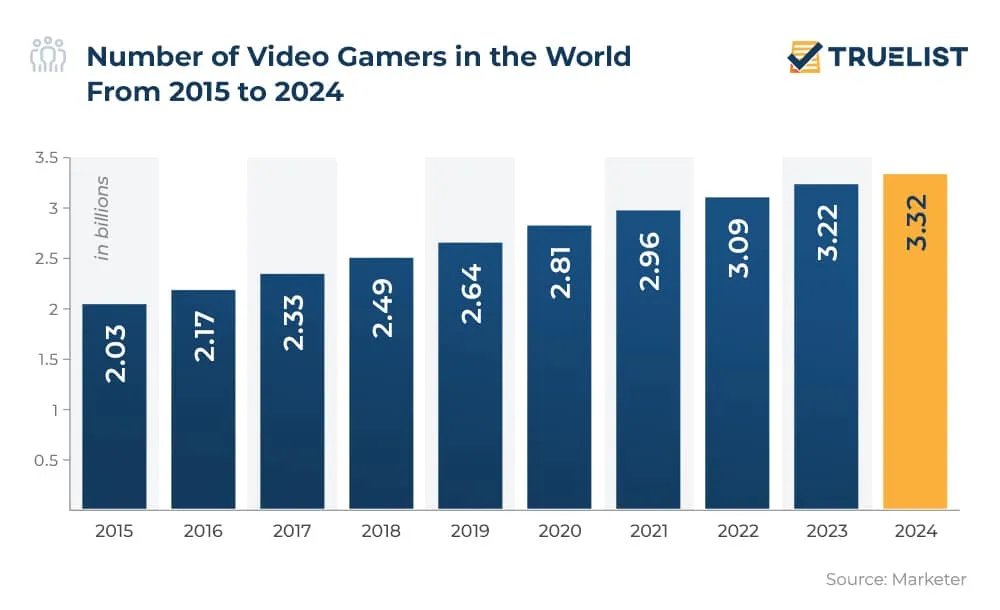
- 全球大约有 30 亿人玩视频游戏。数据来源:Marketers
- 83% 的视频游戏销售发生在数字世界。数据来源:Global X ETF
- 2021 年美国视频游戏领域的消费者支出为 604 亿美元。数据来源:美通社、Newzoo
- 大约 85% 的游戏收入来自免费游戏。数据来源:WePC、TweakTown
- 2021 年第一季度,移动游戏下载量约为 141 亿次。数据来源:Statista
- 到 2025 年,仅 PC 游戏行业就将积累 467 亿美元。数据来源:Statista
- 全球游戏玩家中 38% 年龄在 18 岁至 34 岁之间。数据来源:Statista
显然,大多数视频游戏的重要组成部分是游戏角色。
考虑到这一点,
从类型来看,2019 年 3D 细分市场占游戏引擎市场份额的 84.19%,预计到 2027 年将出现显著增长。3D 类型广泛应用于游戏或角色建模、场景建模、3D 引擎和粒子系统。 — 摘自 BusinessWire
对角色设计师和 3D 艺术家等的需求量很大。
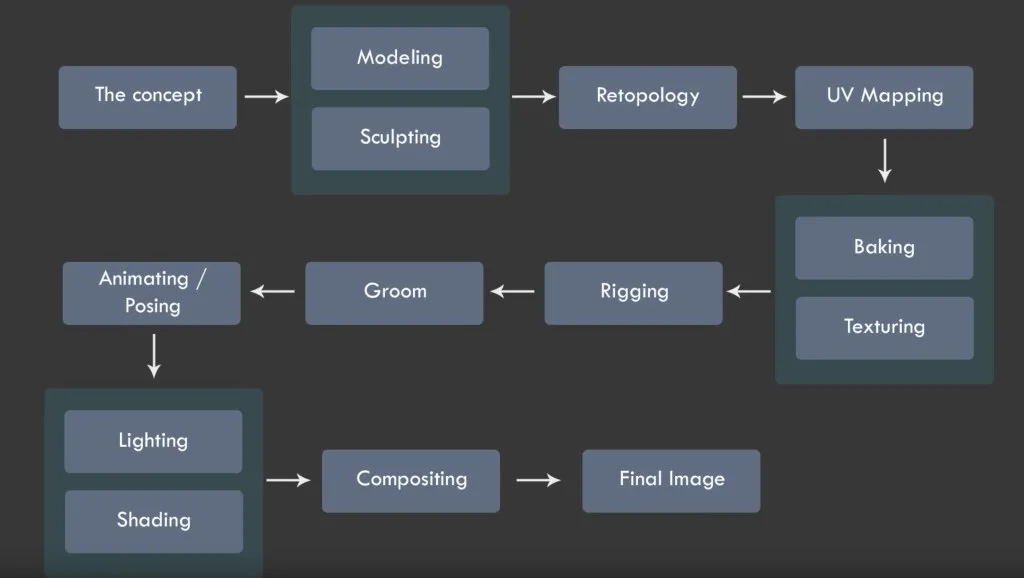
另请考虑 3D 角色创建的 工作流程/管道:
构思 -> 概念建模 -> 雕刻 -> 重新拓扑 -> UV 展开 -> 烘焙 -> 纹理化 -> 装备和蒙皮 -> 动画 -> 渲染
每一步都需要专家的艰苦努力才能完成。如果我们能够以某种方式自动化这个过程,或者至少自动化其中的一部分,那么将节省大量的开发资源,并向更多的人开放 3D 角色创建。
二. 指标和基线
我们已经了解了传统 3D 角色创建如何具有多个阶段。尽管这最终会产生非常高质量的资产,用于电影、视频游戏、营销、VR 等。但完成它们确实需要多个工作日到几周的时间。
现有的文本转 3D 解决方案怎么样?
2.1 Google DreamFusion
首先可以参考 DreamFusion,这是一个基于 2D 扩散模型的文本生成 3D 的项目,由 Google Research 于 2022 年发布,利用 Imagen 作为优化 NeRF MLP 的先验。不过,由于 DreamFusion 是闭源的,我们无法对其进行测试。重新实现也很困难,因为 Imagen 是一个像素空间扩散模型,需要大量的计算资源才能运行。
其结果如何?让我们使用 DreamFusion 示例 中的提示语和生成参数:
— text “masterpiece, best quality, 1girl, slight smile, white hoodie, blue jeans, blue sneakers, short blue hair, aqua eyes, bangs” \— negative “worst quality, low quality, logo, text, watermark, username” \— hf_key rossiyareich/abyssorangemix3-popupparade-fp16 \__— iters 5000
得到如下结果:

2.2 OpenAI SHAP-E
Shap-e 由 OpenAI 于 2023 年发布,采用编码器 - 解码器架构,其中编码器经过训练将 3D 点云和空间坐标编码为解码器的隐式参数函数。那么,解码器是一个隐式 NeRF MLP,经过训练可以输出带符号的距离场。
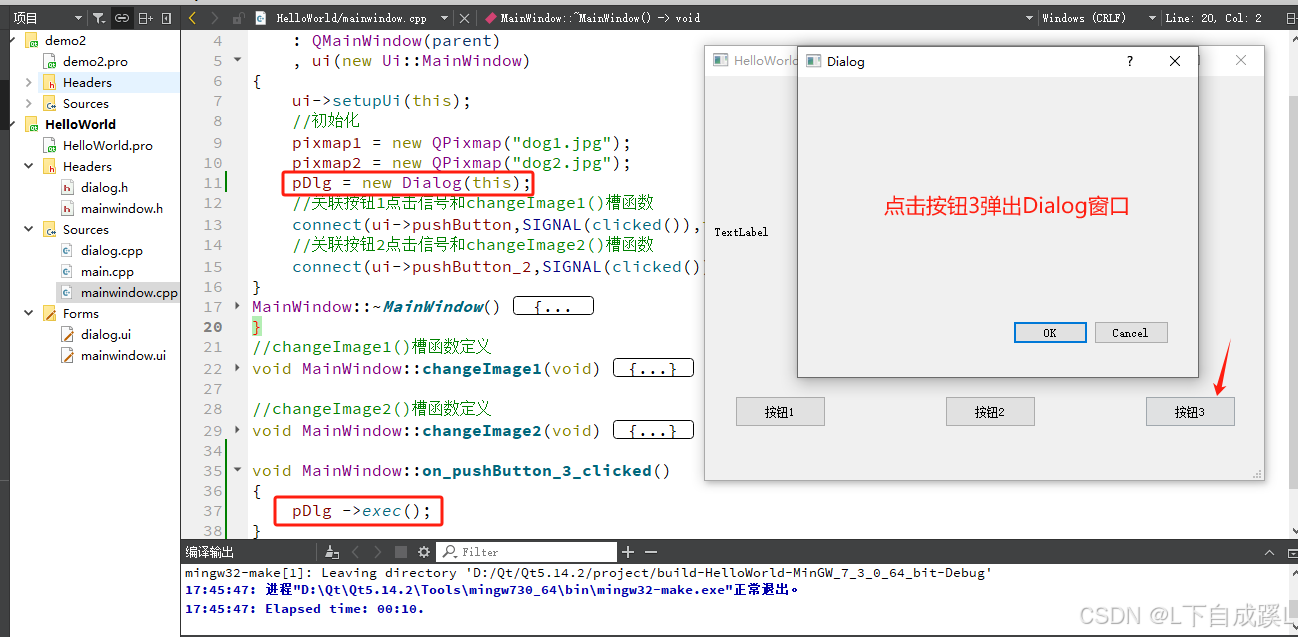
其结果如何?

一个女孩的雕像,由 SHAP-E 生成

一个女孩,由 SHAP-E 生成
2.3 开源项目
公开的文本转 3D 模型要么过于实验性,要么不会产生很好的结果。例如开源的 stable-dreamfusion:
三. 数据采集和清理
我们的角色生成管道可以分为两个步骤:文本到视频和视频到 3D。因为我们正在尝试合成 NeRF 模型的数据。我们最好的选择是扩散概率模型。稳定扩散(由 Huggingface/diffusers 实现)就是这样的模型之一。
我们还利用类似 ControlNet 的技术进行图像调节。因此,为了生成 ControlNet 图像,我们的渲染基于基础网格。

OpenPose 调节图像
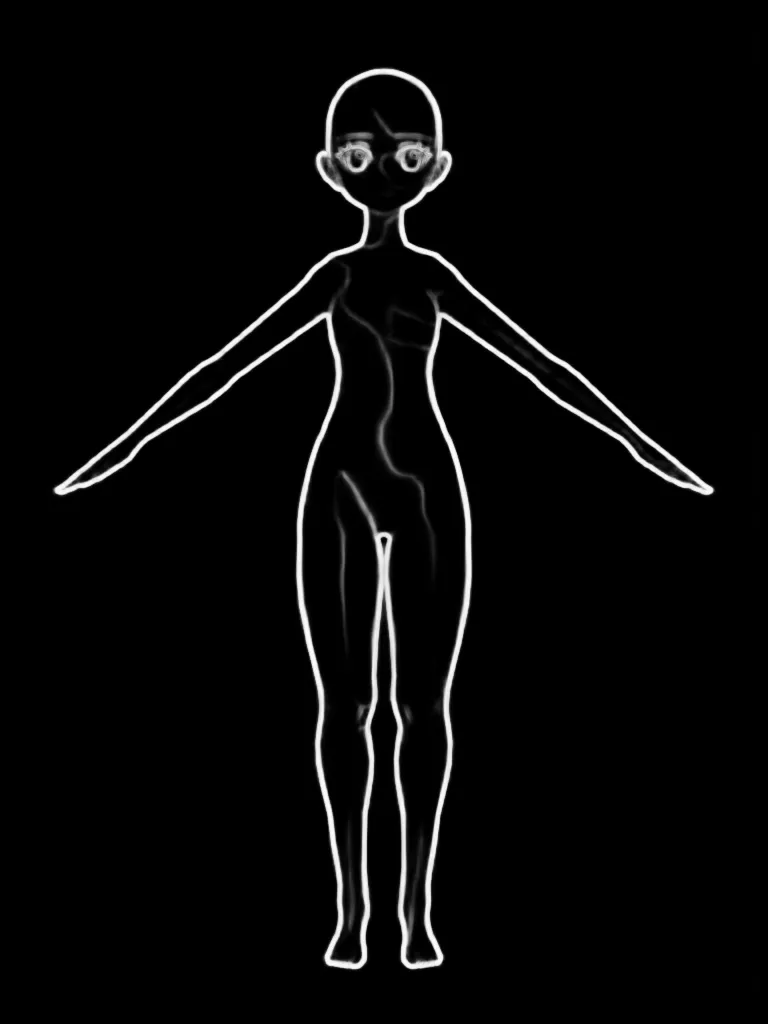
SoftEdge HED 调节图像
我们每次在 Blender 中以不同的相机视图以相同的 A 姿势为同一角色渲染 100 帧。
然后,为了合成训练 nvdiffrec 所需的数据集,我们利用一种新颖的一致生成技术,这也恰好是我们的主要贡献。
为了理解所使用技术的工作原理,我们首先应该退一步看看像素空间扩散模型是如何工作的,你可以查看 这个视频。
潜在扩散模型应用潜在空间中的扩散过程;图像首先通过 VAE 编码器编码到潜在空间,扩散过程的输出结果通过 VAE 解码器进行解码。不过,在运行文本到图像推理时,仅使用 VAE 解码器。
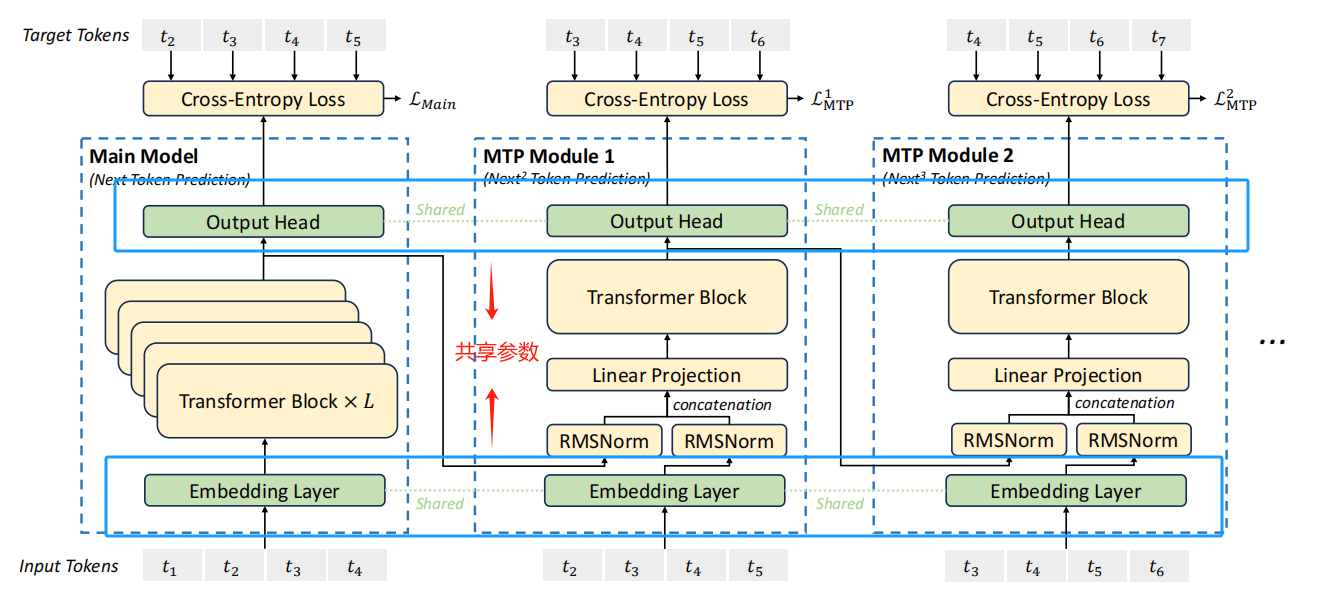
为了更好地控制扩散模型输出的结果,我们从 ControlVideo: Training-free Controllable Text-to-Video Generation 中汲取灵感,并采用了类似的技术:
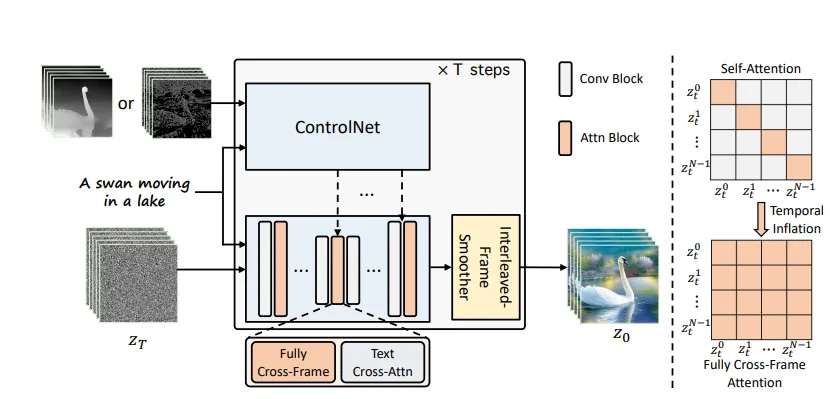
原始论文将时间膨胀应用于稳定扩散的 UNet 噪声预测模型中的 Conv2D 和自注意力层,以便能够从其他帧输入条件,我们也这样做。我们与原始实现的偏差是输入固定数量的潜在代码(在我们的例子中最多 3 个)以减轻内存限制。
我们的跨帧注意力机制中仅使用第一帧和之前的帧。我们发现我们的结果和稀疏因果注意力的原始实现总体上是一致的,但仍在努力解决图像中的更精细的细节;然而,这仍然是 DPM 的一个限制,可以预见,但仍有待解决。
四. 探索性数据分析
使用的基准 ControlNet 是:
- lllyasviel/control_v11p_sd15_openpose
- lllyasviel/control_v11e_sd15_ip2p
- lllyasviel/control_v11p_sd15_softedge
我们发现这种组合对于一致性来说是最好的(尽管仍然可以进行一些改进)。
我们还将 AOM3 (AbyssOrangeMix3) 与 Pop Up Parade 合并,比例为 0.5 作为 我们的基础模型,并利用 NAI 派生的 VAE 权重 (anything-v4.0-vae) 作为 我们的 VAE。重要的是 VAE 必须不产生 NaN,否则整个生成过程都会被浪费。
五. 建模、验证和错误分析
更深入地了解我们对 ControlVideo 实现的修改和偏差。
首先,我们采用 order=2 的 DPMSolverMultistepScheduler 来配合实现。这将生成时间缩短了 60%,因为我们只需要 20 个采样步骤(本文假设使用 50 个 DDIM 采样步骤)。
其次,我们删除了 RIFE(视频帧插值实时中间流估计)模型。虽然它稍微改善了闪烁问题,但它会使图像变得不清晰和饱和度降低,从而造成更大的危害。
最后,我们修改了去噪循环,使其仅关注第一个潜在代码和前一帧的潜在代码:
for i, t in enumerate(timesteps):
torch.cuda.empty_cache()
# Expand latents for CFG
latent_model_input = torch.cat([latents] * 2)
latent_model_input = self.scheduler.scale_model_input(
latent_model_input, t
)
noise_pred = torch.zeros_like(latents)
pred_original_sample = torch.zeros_like(latents)
for frame_n in range(video_length):
torch.cuda.empty_cache()
if frame_n == 0:
frames = [0]
focus_rel = 0
elif frame_n == 1:
frames = [0, 1]
focus_rel = 1
else:
frames = [frame_n - 1, frame_n, 0]
focus_rel = 1
# Inference on ControlNet
(
down_block_res_samples,
mid_block_res_sample,
) = self.controlnet(
latent_model_input[:, :, frames],
t,
encoder_hidden_states=frame_wembeds[frame_n],
controlnet_cond=[
cnet_frames[:, :, frames]
for cnet_frames in controlnet_frames
],
conditioning_scale=controlnet_scales,
return_dict=False,
)
block_res_samples = [
*down_block_res_samples,
mid_block_res_sample,
]
block_res_samples = [
b * s
for b, s in zip(block_res_samples, controlnet_block_scales)
]
down_block_res_samples = block_res_samples[:-1]
mid_block_res_sample = block_res_samples[-1]
# Inference on UNet
pred_noise_pred = self.unet(
latent_model_input[:, :, frames],
t,
encoder_hidden_states=frame_wembeds[frame_n],
cross_attention_kwargs=cross_attention_kwargs,
down_block_additional_residuals=down_block_res_samples,
mid_block_additional_residual=mid_block_res_sample,
inter_frame=False,
).sample
# Perform CFG
noise_pred_uncond, noise_pred_text = pred_noise_pred[
:, :, focus_rel
].chunk(2)
noise_pred[:, :, frame_n] = noise_pred_uncond + guidance_scale * (
noise_pred_text - noise_pred_uncond
)
# Compute the previous noisy sample x_t -> x_t-1
step_dict = self.scheduler.step(
noise_pred[:, :, frame_n],
t,
latents[:, :, frame_n],
frame_n,
**extra_step_kwargs,
)
latents[:, :, frame_n] = step_dict.prev_sample
pred_original_sample[:, :, frame_n] = step_dict.pred_original_sample
然后我们使用以下参数训练 nvdiffrec:
{
"ref_mesh": "data/ngp",
"random_textures": true,
"iter": 5000,
"save_interval": 100,
"texture_res": [2048, 2048],
"train_res": [1024, 768],
"batch": 2,
"learning_rate": [0.03, 0.01],
"ks_min": [0, 0.08, 0.0],
"dmtet_grid": 128,
"mesh_scale": 2.1,
"laplace_scale": 3000,
"display": [{"latlong": true}, {"bsdf": "kd"}, {"bsdf": "ks"}, {"bsdf": "normal"}],
"background": "white",
"out_dir": "output"
}
得到如下的结果:


从左到右:组合、基准事实、环境图、反照率、深度、法线
经过 5000 次迭代后,我们得到以下结果:
- 均方误差:0.00283534
- 峰值信噪比:25.590
- 5504 个顶点
- 9563 个纹理坐标
- 5504 个法线
- 11040 个面
正如预期的那样,使用 InstantNGP 进行的新颖视图合成在预期角度下会产生更好的结果,但是,当从极端角度观看时,结果往往会不一致。
使用 Sentence-Transformers/clip-ViT-B-32 计算的 R-Precision 分数证实了我们的发现:
_提示:“a 3d model of a girl”_0.34226945 — LDM R-Precision
0.338451 — InstantNGP R-Precison
0.3204362 — nvdiffrec R-Precision
6. 部署
这里提供了 Colab ,运行 3 个 ControlNet 模块,导致峰值 vram 使用量为 14GiB。生成总共需要 2.5 小时。
原文链接:Diffusion models are zero-shot 3D character generators, too




![[ctfshow web入门] web25](https://i-blog.csdnimg.cn/direct/b7d8e7fd62bf436a876bb3a0204eea36.png)