文章目录
- 0 图的遍历
- 1 图的遍历方法
- 1.1 深度优先搜索DFS
- 1.1.1 DFS的思想
- 1.1.2 邻接矩阵DFS的实现
- 1.1.3 邻接矩阵DFS的代码实现
- 1.1.4 非连通图的DFS遍历
- 1.1.5 DFS算法效率分析
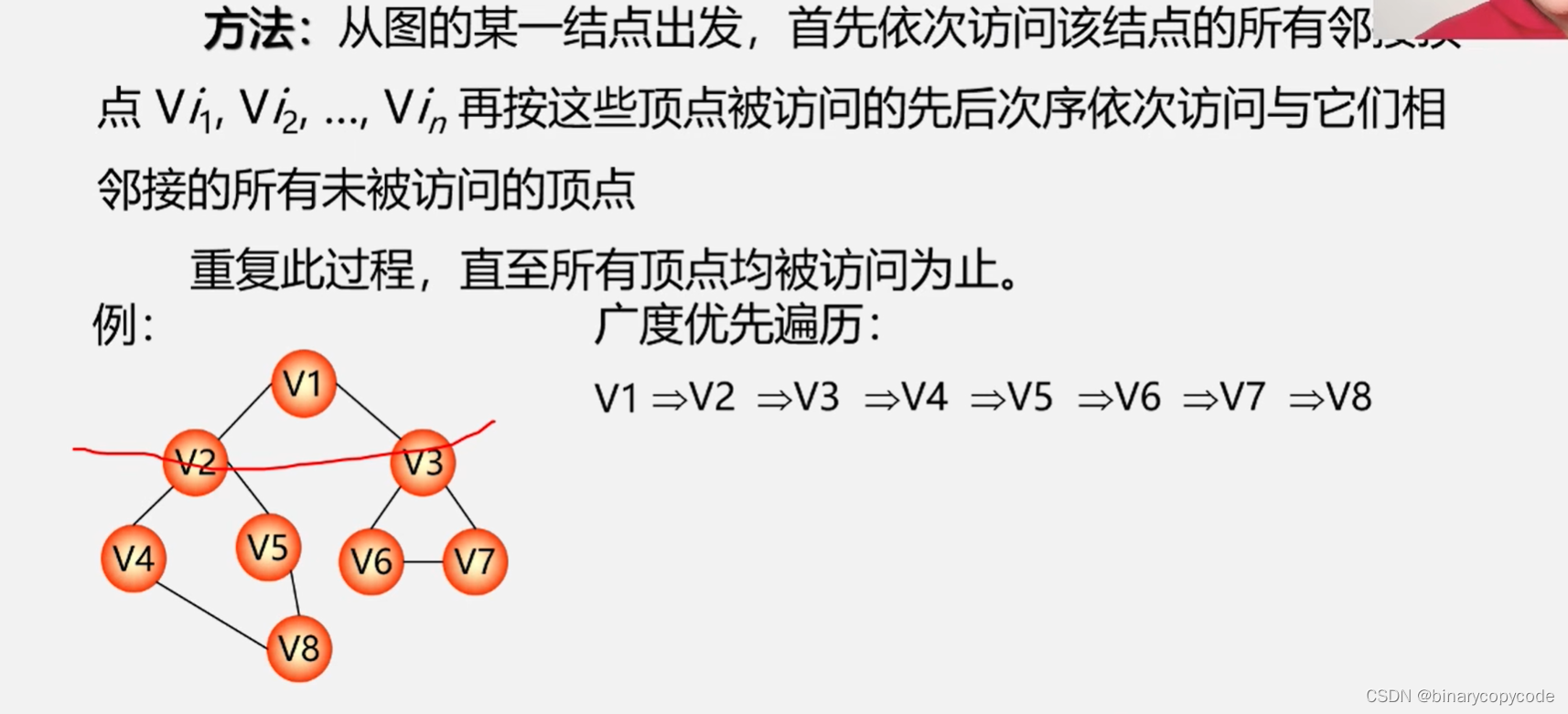
- 1.2 广度优先搜索BFS
- 1.2.1 BFS的思想(连通图)
- 1.2.2 BFS的思想(非连通图)
- 1.2.3 邻接表BFS的实现
- 1.2.4 邻接表BFS的代码实现
- 1.2.5 BFS算法效率分析
- 2 DFS与BFS算法效率比较
0 图的遍历
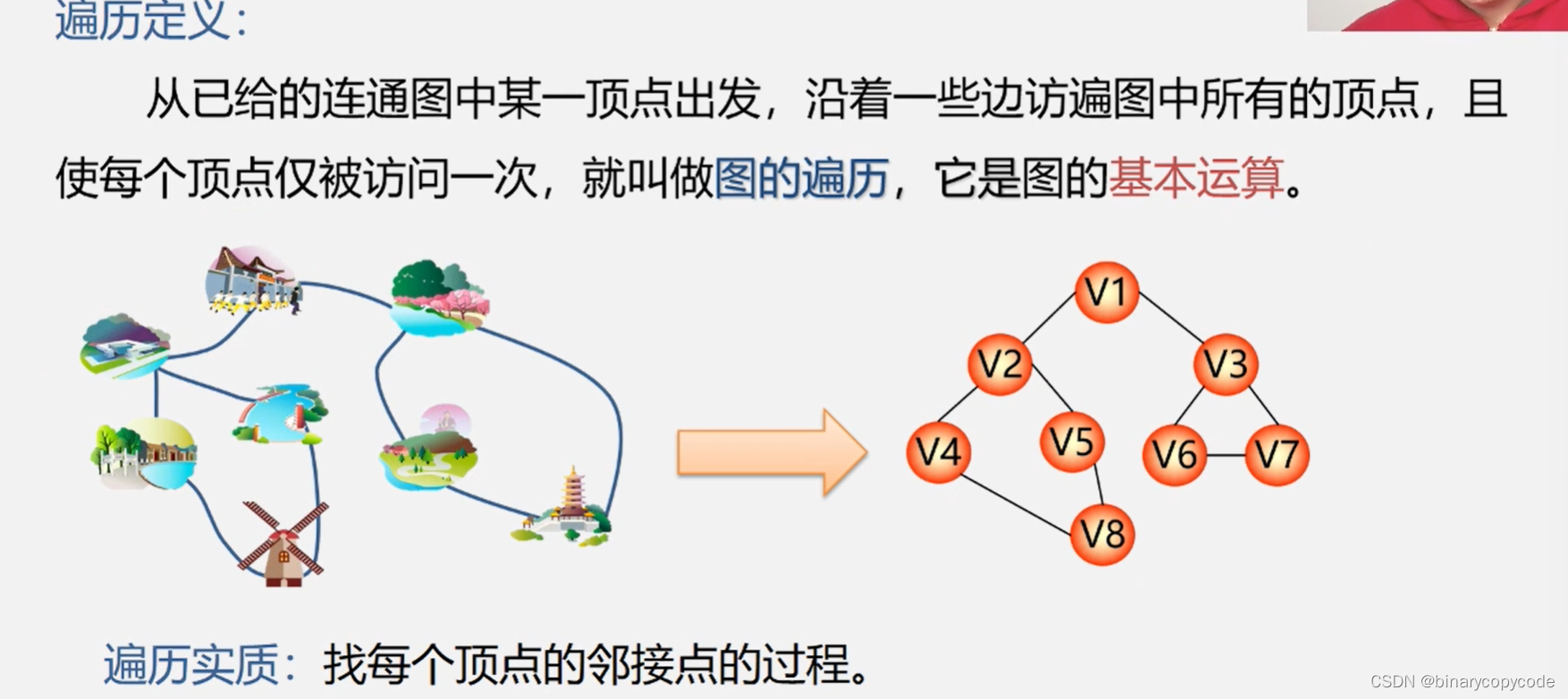
实际上就是找出每个顶点的邻接点的过程。

1 图的遍历方法
图常用的遍历有两种方法:
- 深度优先搜索DFS
- 广度优先搜索BFS
1.1 深度优先搜索DFS
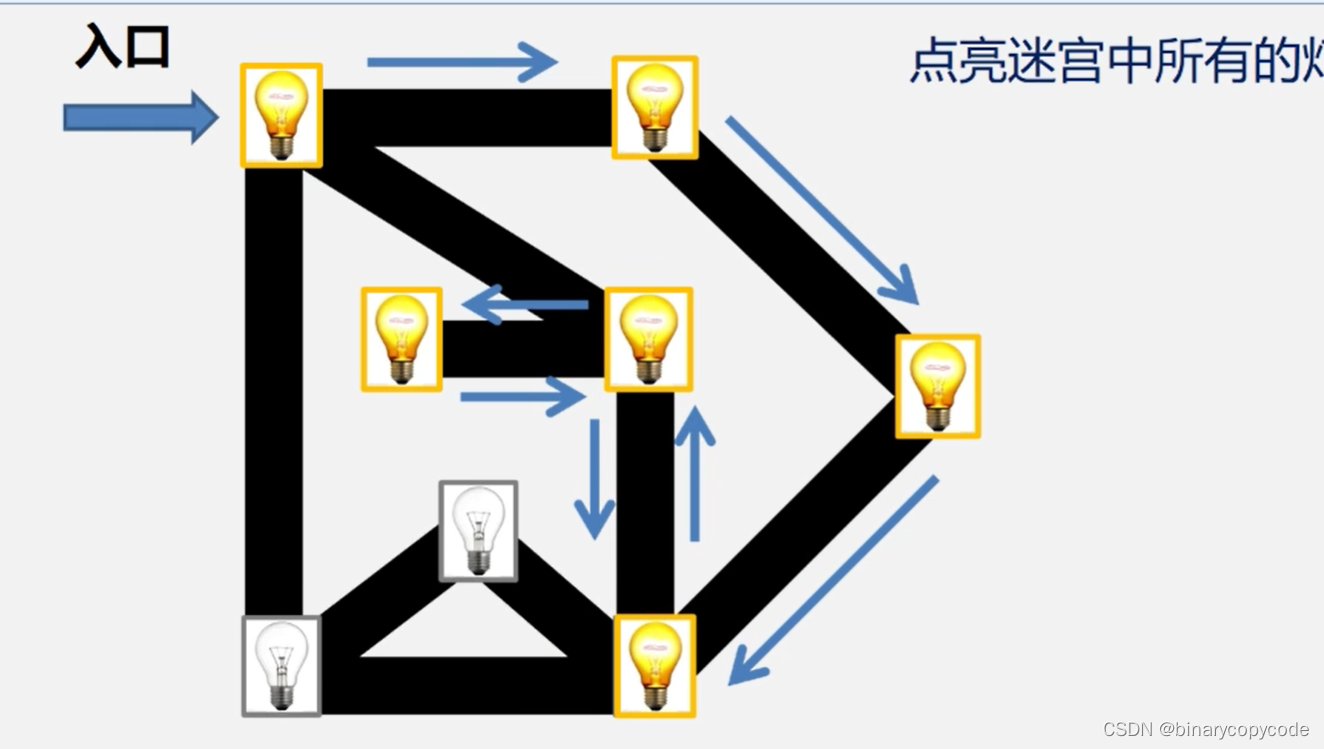
基本思路就是,一条路走到黑,走到无路可走就往回退,再检查是否有未走过的路(邻接点)。
(发现有邻接点未访问就去访问,直到所有邻接点都被访问)
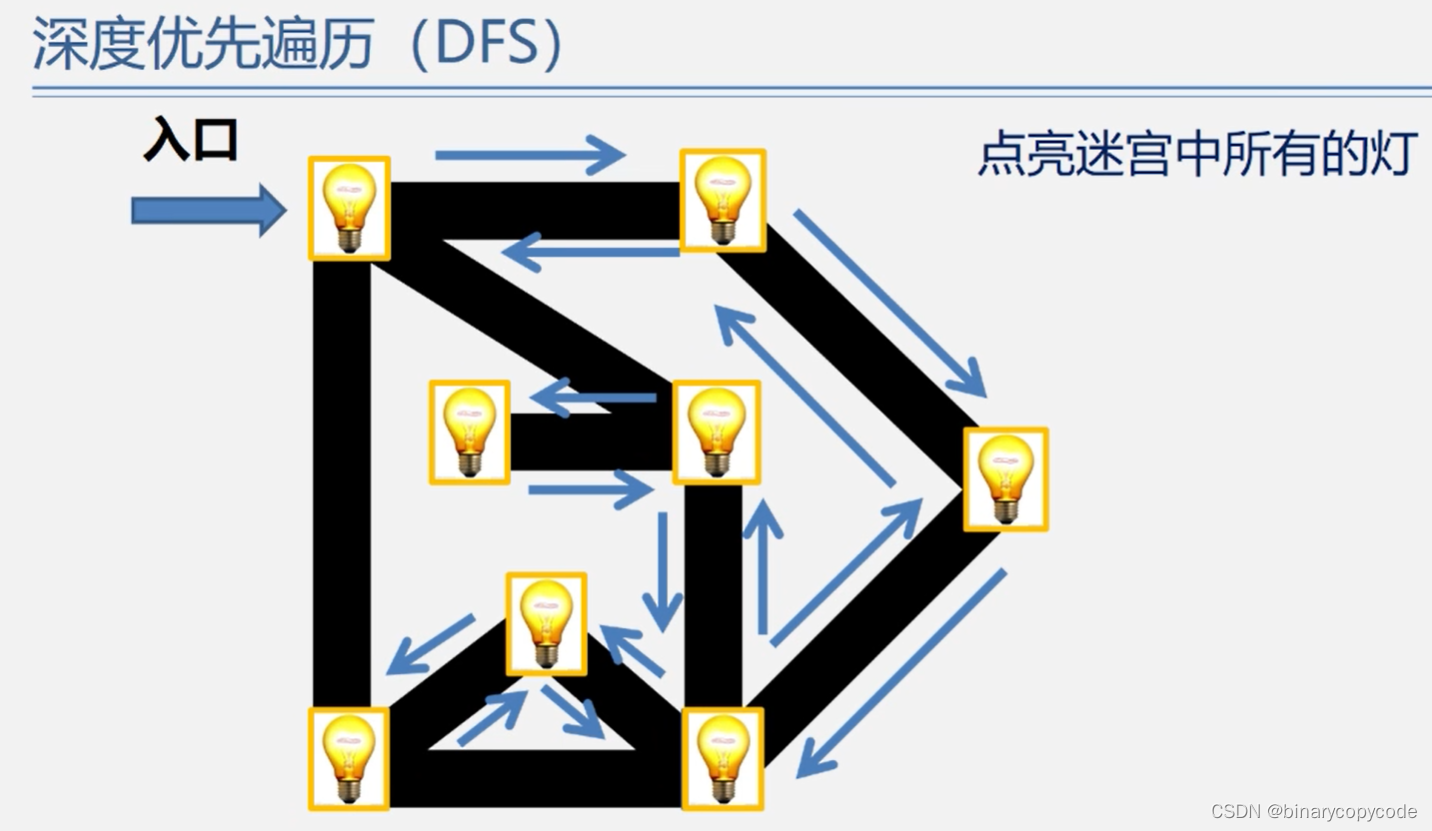
1.1.1 DFS的思想

记住,往回退的时候只能走来的时候的路(原路返回)。

DFS很像树的先序遍历。
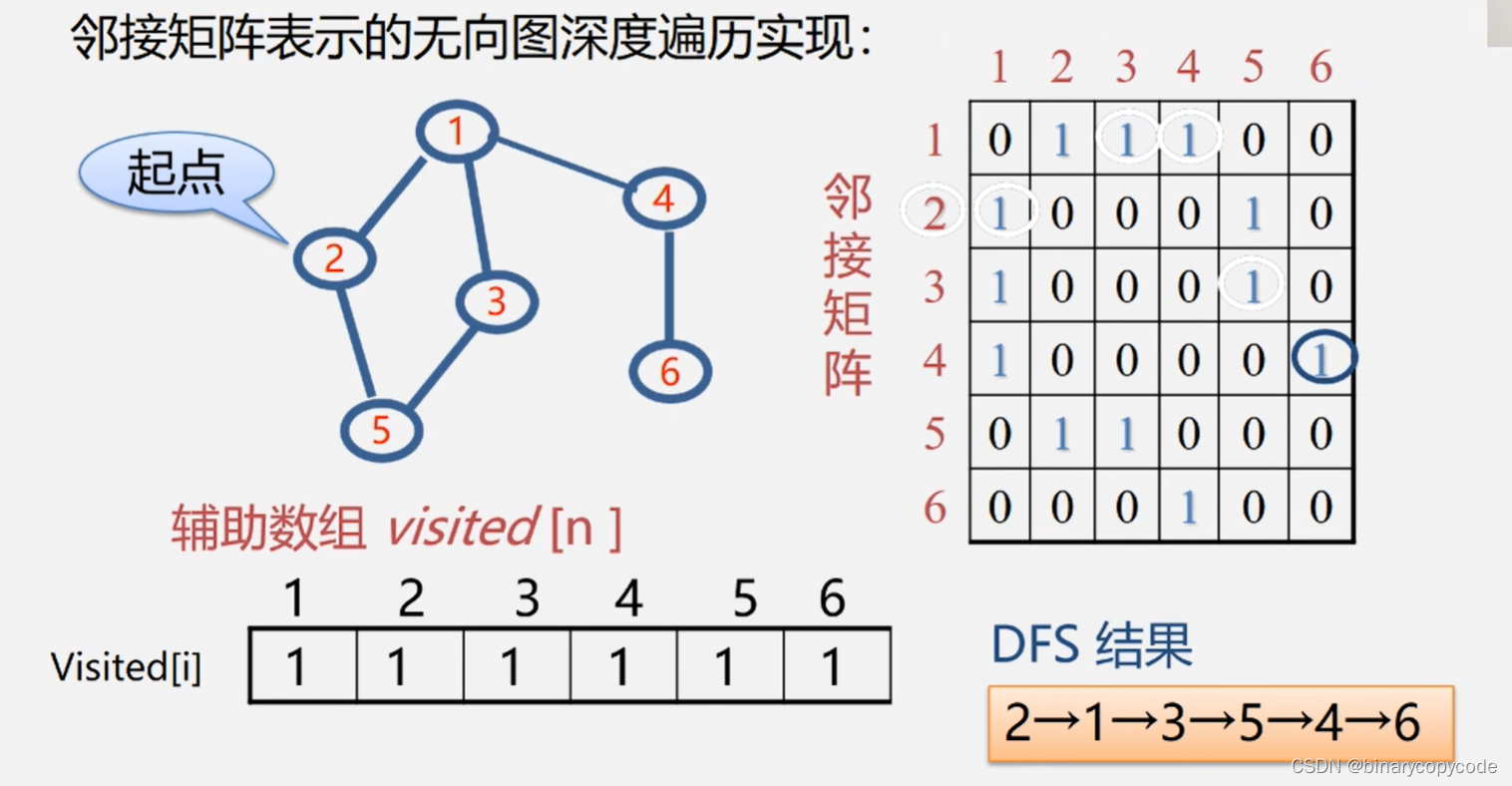
1.1.2 邻接矩阵DFS的实现
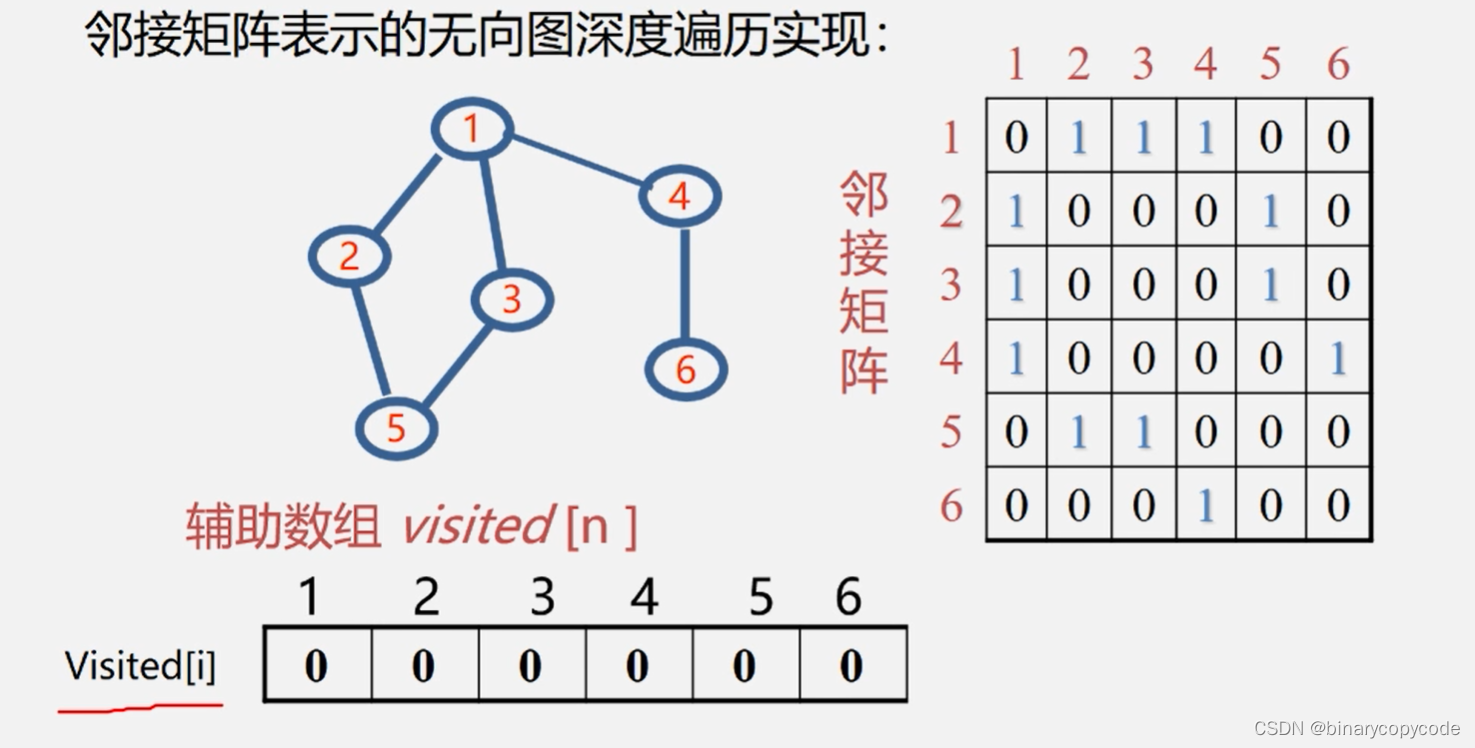
每个顶点只能访问一次,设置一个辅助数组Visted[i],开始的时候将数组初始化为0,所有顶点一开始都没访问过,访问过就设置1。
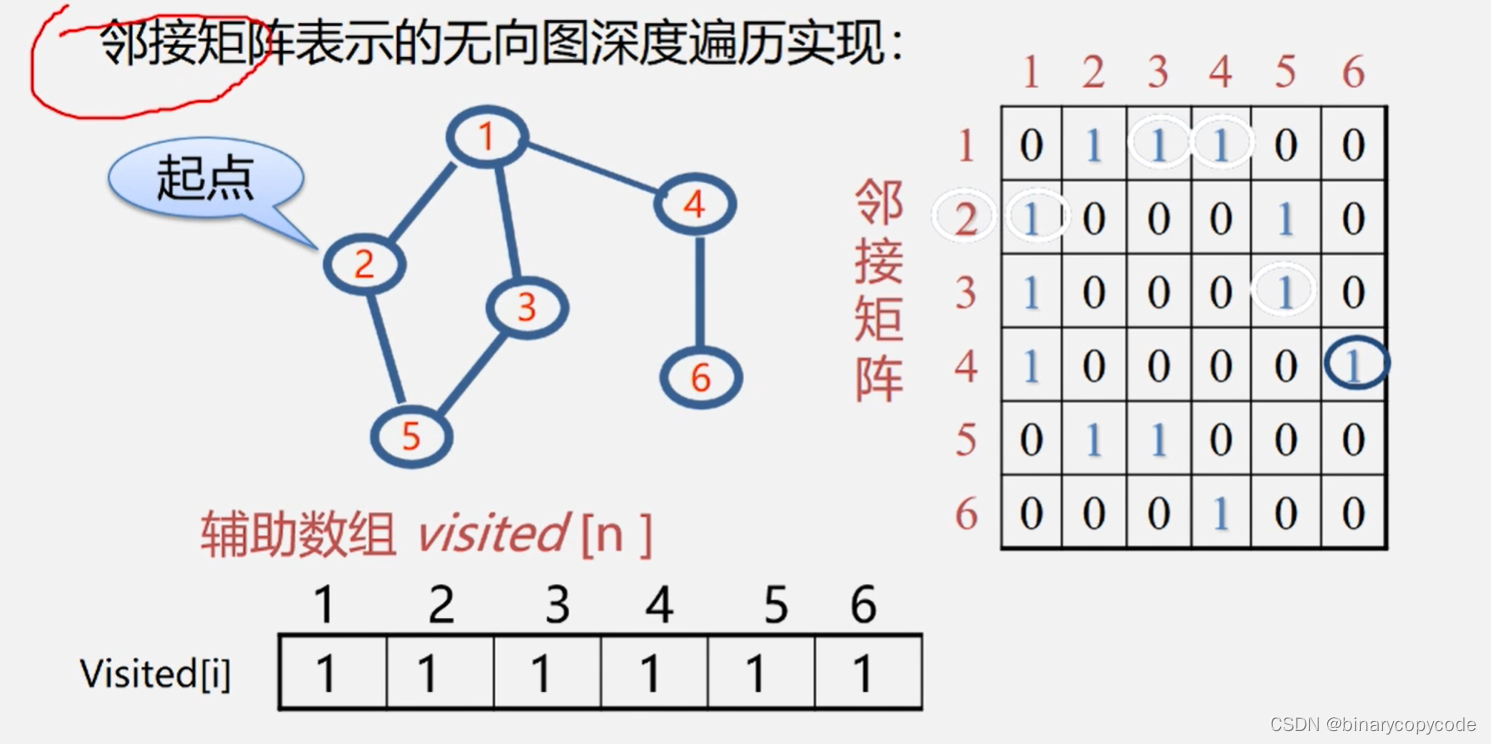
基本流程:
假设,起点从
v
2
v_2
v2开始,并将其在辅助数组中的值改为1,接下来看
v
2
v_2
v2的没有被访问过的邻接点。怎么去找呢?查看邻接矩阵,行下标为2的,顺序去找。现在
v
2
v_2
v2的一个邻接点为
v
1
v_1
v1,正好
v
1
v_1
v1没有访问过(因为visited[1]=0),所以就可以往
v
1
v_1
v1那里走。到了
v
1
v_1
v1后,开始找
v
1
v_1
v1未访问的邻接点,按顺序来,首先找到了
v
2
v_2
v2,但是
v
2
v_2
v2此时被访问过了,不能访问,所以接着寻找,找到了
v
3
v_3
v3,没被访问过,就可以访问。到了几号,就要从几号出发,进行DFS。过了
v
3
v_3
v3找到了
v
5
v_5
v5没有访问,即走到了
v
5
v_5
v5。到了
v
5
v_5
v5发现
v
2
v_2
v2和
v
3
v_3
v3都访问过了,所以进行回退,此时
v
5
v_5
v5是由
v
3
v_3
v3访问过来的,所以先回退到
v
3
v_3
v3,从哪来的就往哪里退,再接着从
v
3
v_3
v3访问,此时,与
v
3
v_3
v3相关的都被访问了,所以继续回退,回退到
v
1
v_1
v1继续进行DFS,发现
v
4
v_4
v4还没被访问,进行访问同时数组置1。到了
v
4
v_4
v4发现
v
6
v_6
v6还没被访问,所以进行访问。到了
v
6
v_6
v6发现邻接点都被访问了,所以往回退到
v
4
v_4
v4。
v
4
v_4
v4往回退为
v
1
v_1
v1,还是都访问过,再回退到
v
2
v_2
v2,发现还是都访问过了,再发现visited[i]数组全是1,都访问过了,DFS结束。
1.1.3 邻接矩阵DFS的代码实现
void DFS(AMGraph G, int v) //图G为邻接矩阵类型
{
cout << v;
visited[v] = true; //访问第v个顶点
for (w = 0; w < G.vexnum; ++w) //依次检查邻接矩阵v所在的行
{
if((G.arcs[v][w]!=0) && (!visited[w]))
{
DFS(G, w);
//w是v的邻接点,如果w未访问,则递归调用DFS
}
}
}
1.1.4 非连通图的DFS遍历
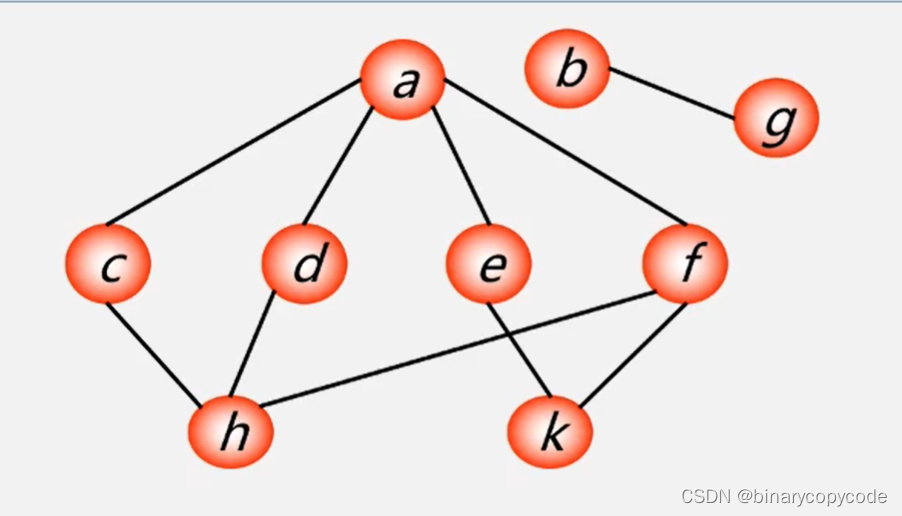
从任意一个顶点开始,找其未被访问的邻接点进行访问。当连通图的顶点都访问完后,再在其他的未被访问的顶点当中选一个点进行访问,进行DFS。
1.1.5 DFS算法效率分析
1.2 广度优先搜索BFS
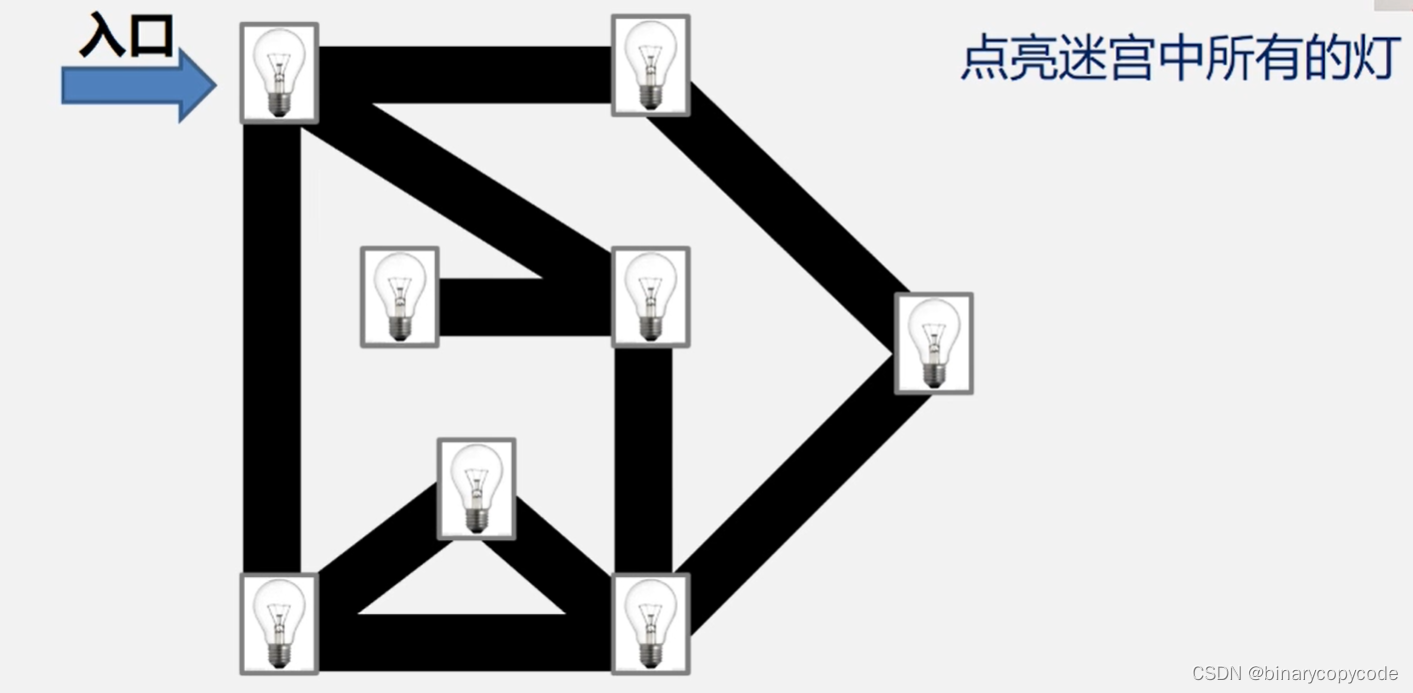
1.2.1 BFS的思想(连通图)
首先从一个点开始(假设就是入口的那个点),访问其所有的邻接点,如下所示:
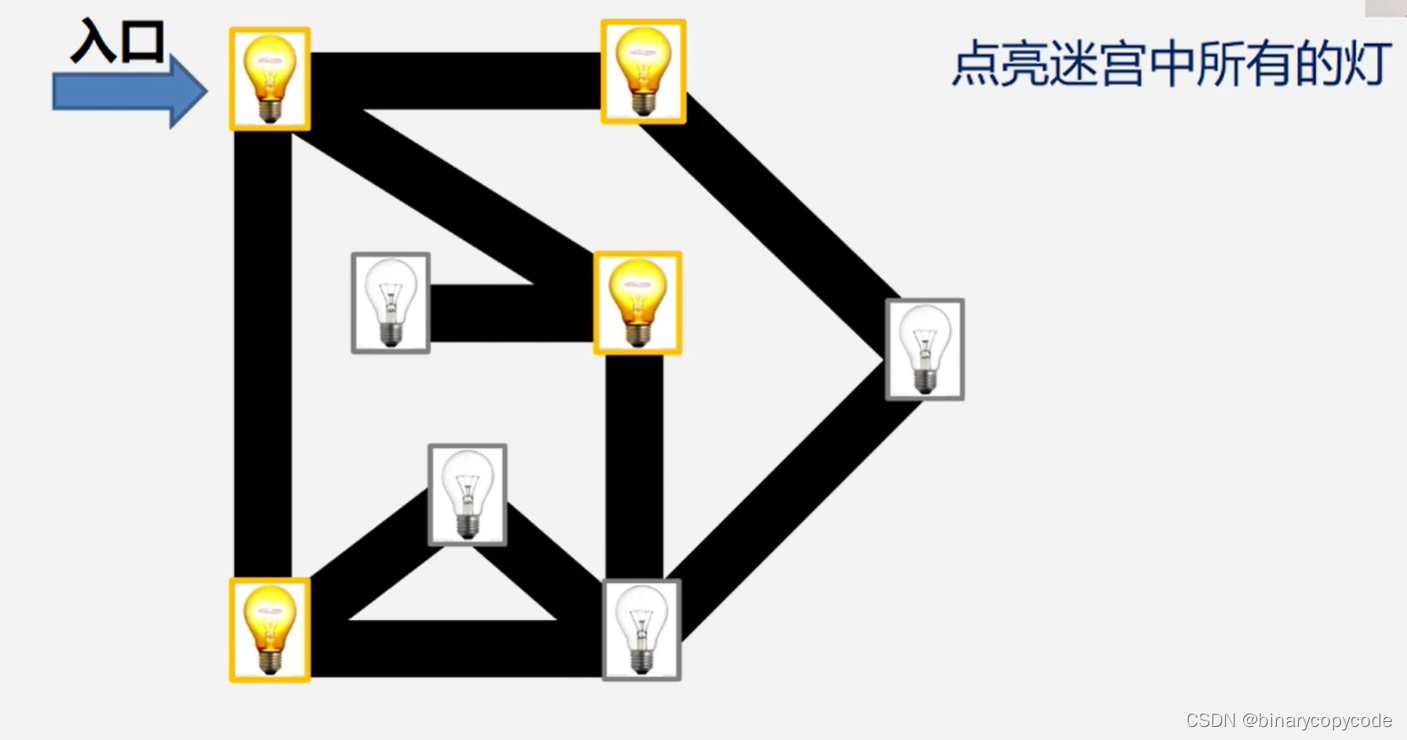
都点亮之后,再扩大一层,即找邻接点的邻接点,直到所有点都被访问。
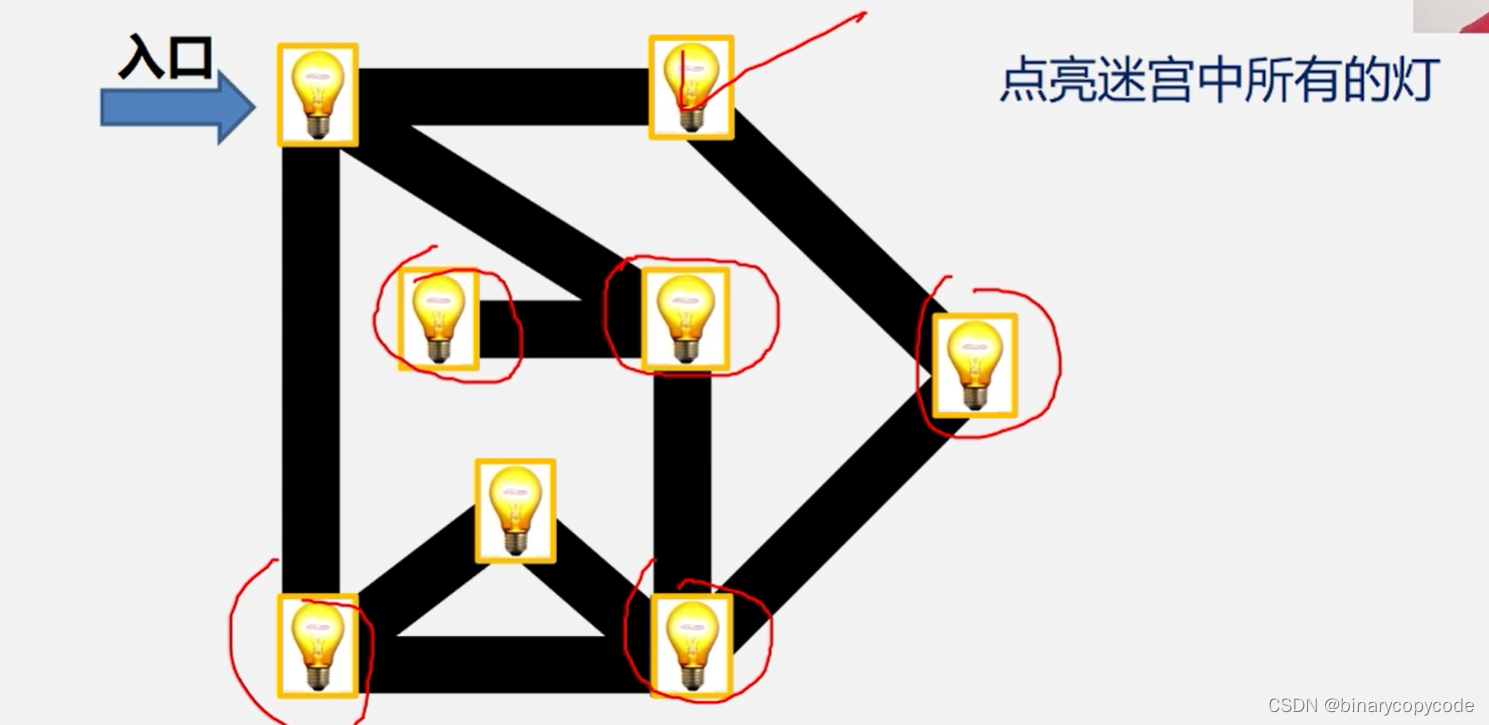
1.2.2 BFS的思想(非连通图)
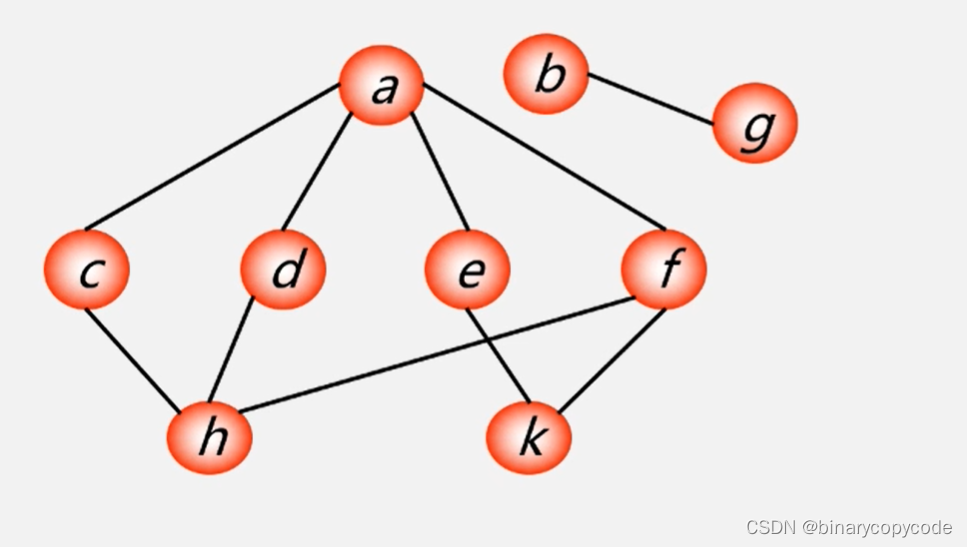
也是从一个顶点出发,访问其邻接点,之后再找邻接点的邻接点。接下来找非连通的部分,未访问的顶点中任取一个来访问。
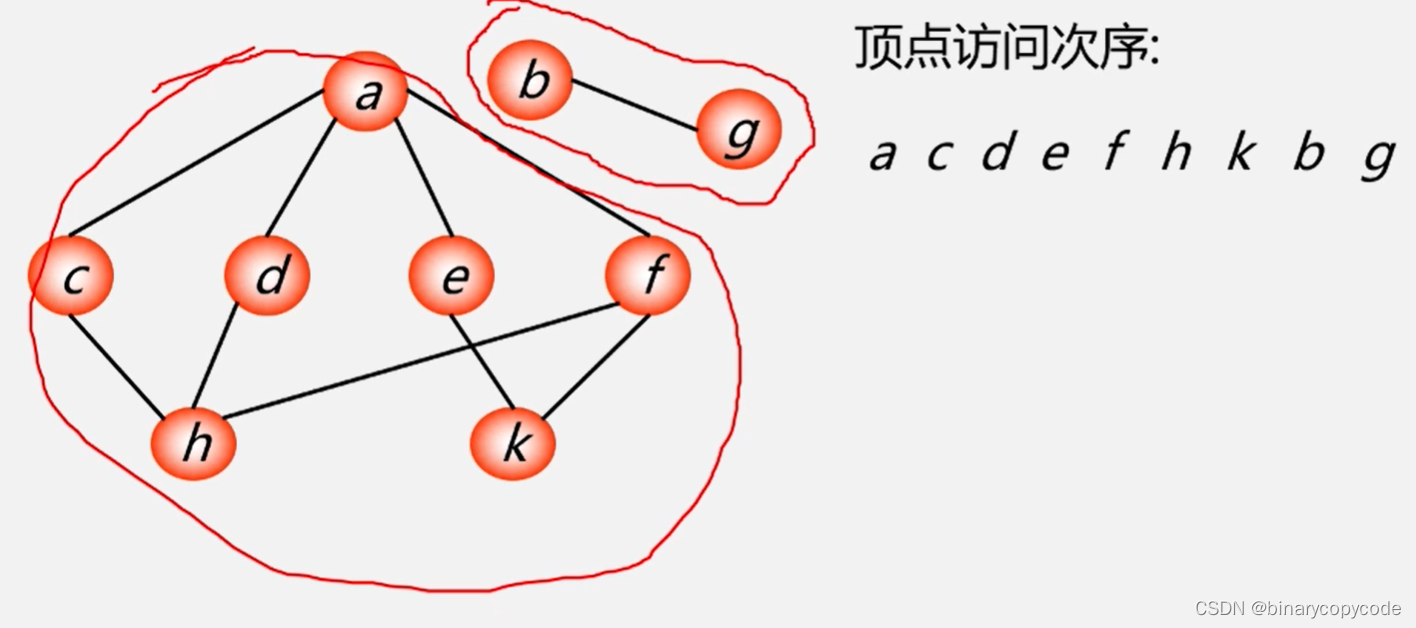
1.2.3 邻接表BFS的实现
需要一个visited[i]数组来表示点是否被访问。
其实现过程,访问顺序与树的层次遍历有点像。在树的层次遍历当中,是用队列来实现的,加入节点,加入其孩子,加入其孩子的孩子,以此类推;而邻接表当中是加入节点,加入其邻接点,加入其邻接点的邻接点,以此类推。
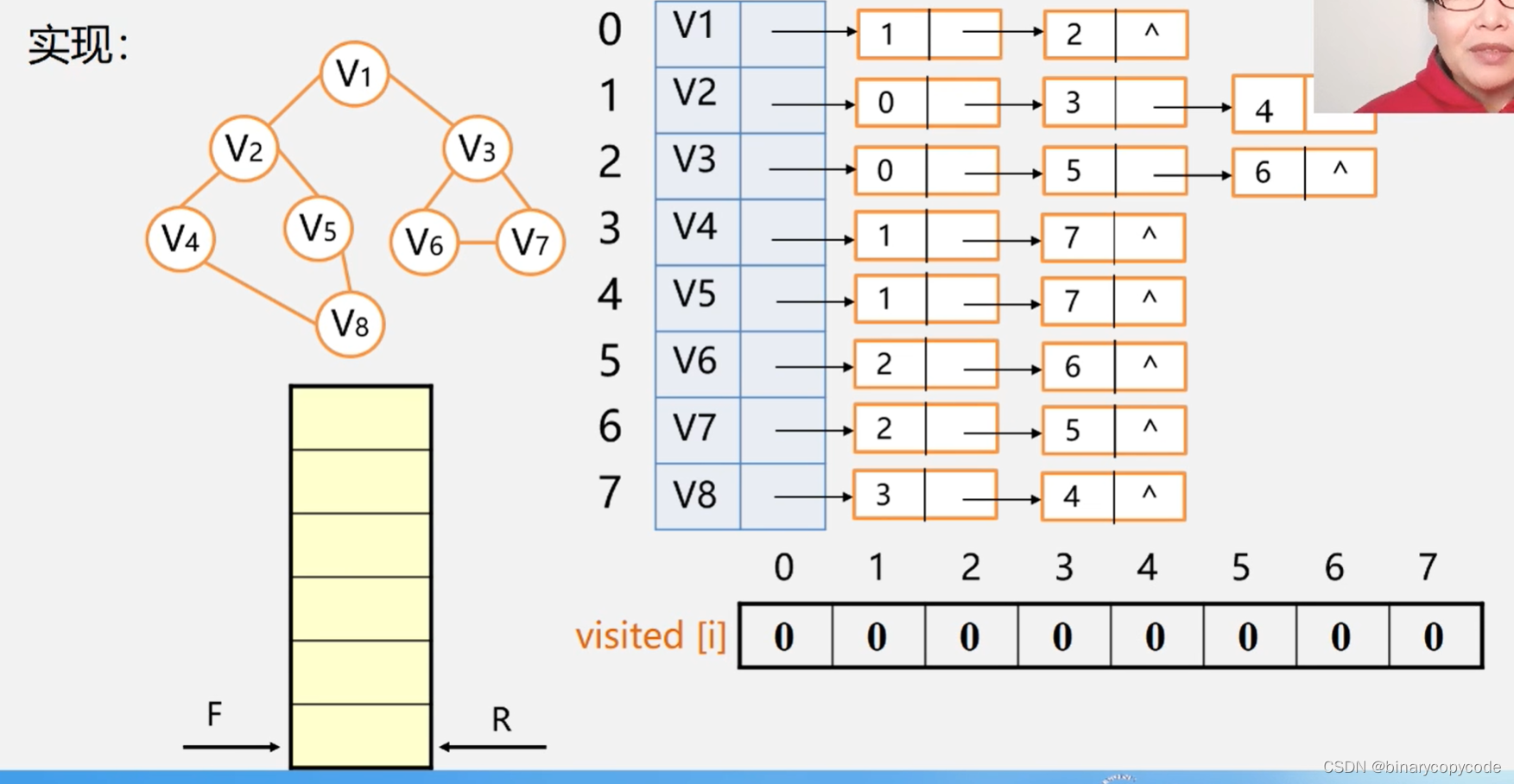
实现过程
0号位置即
v
1
v_1
v1入队,在队尾,队尾指针移动一下,visited[0]相应的置1,代表被访问过,之后队列中的0号出队,找其邻接点并入队。
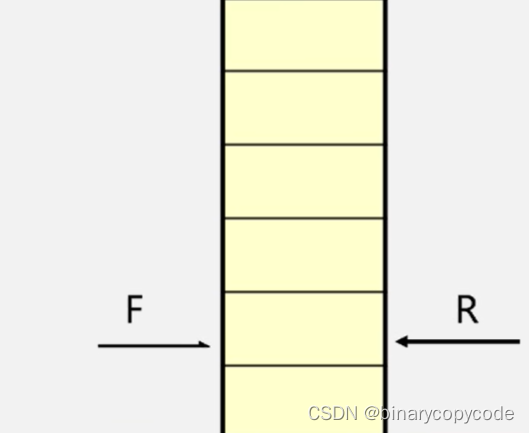
如何找
v
1
v_1
v1的邻接点?在邻接表中进行寻找,第一个单链表就是。发现了1号位置的
v
2
v_2
v2和2号位置的
v
3
v_3
v3,被访问了,数组相应位数置1,且入队。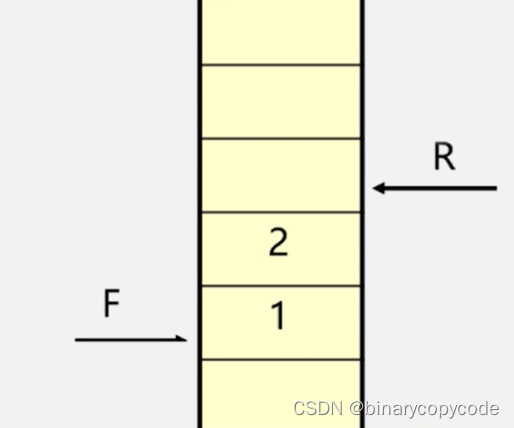
被访问后就出队,出队到
v
2
v_2
v2,找其邻接点3号也就是
v
4
v_4
v4,进行入队置1,接下来又找到了4号也就是
v
5
v_5
v5,进行入队置1。
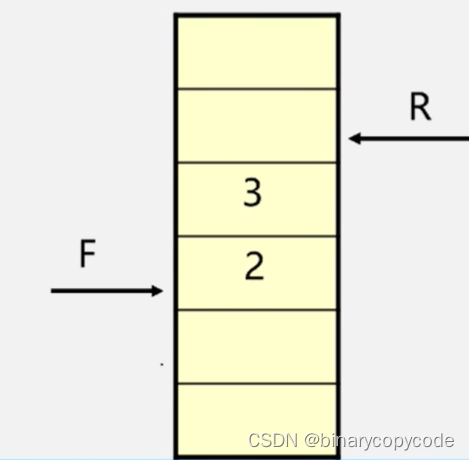
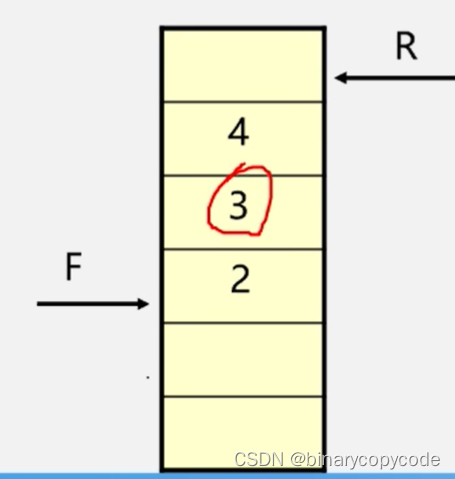
现在
v
2
v_2
v2顶点的两个邻接点都入队了。接下来就下一个,2号
v
3
v_3
v3为队头,出队,开始找其邻接点。找到了5号6号,即
v
6
v_6
v6和
v
7
v_7
v7。
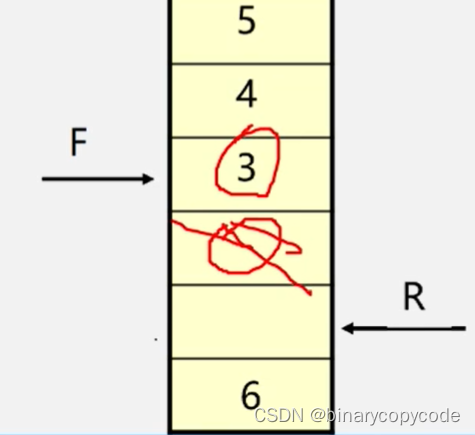
之后再看3号即
v
4
v_4
v4的邻接点,为7号
v
8
v_8
v8,加入进来。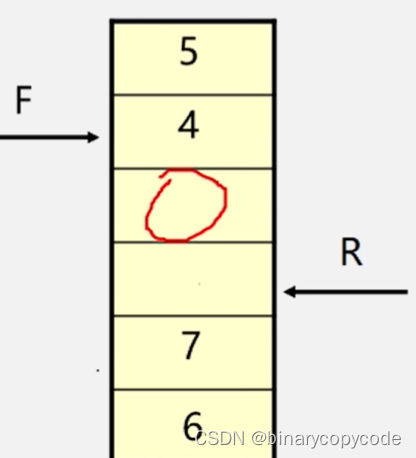
之后访问4号
v
5
v_5
v5的邻接点。将
v
5
v_5
v5的两个邻接点入队,但是1号和7号都入队了,所以忽略。
所以接着访问5号
v
6
v_6
v6发现其邻接点都访问过了。之后看6号的邻接点,也是都访问过了,之后看7号的邻接点,都访问过了。BFS结束。
1.2.4 邻接表BFS的代码实现
void BFS(Graph G, int v)//广度优先搜索
{
cout << v;
visited[v] = true; //访问第v个顶点
InitQueue(Q, v); //辅助队列Q初始化,置空
EnQueue(Q, v);//V进队
while(!QueueEmpty(Q))//队列非空
{
DeQueue(Q, u); //队头元素出队并置为u
for (w = FirstAdjVex(G, u); w >= 0; w = NextAdjVex(G, u, w))
if(!visited[w]) //w为u的尚未访问的邻接顶点
{
cout << w;
visited[w] = true;
EnQueue(Q, w); //w进队
}
}
}
1.2.5 BFS算法效率分析

2 DFS与BFS算法效率比较
空间复杂度:
- 空间复杂度相同,都是 O ( n ) O(n) O(n)(借用了堆栈或队列)
时间复杂度:
- 时间复杂度只与存储结构(邻接矩阵或邻接表)有关,而与搜索路径无关。邻接矩阵为 O ( n 2 ) O(n^2) O(n2),邻接表为 O ( n + e ) O(n+e) O(n+e)。