一、Java 中的列表
1.1 介绍
列表是一种数据结构,为了方便理解,我们可以认为它是动态的数组。众所周知,数组的大小在定义的时候就固定了,不可改变,那么它就无法存储超过它容量的数据,而列表的容量是无限大的,因为它可以随着其存储内容的大小进行动态的变化(包括容量扩增和缩小),这和 java.util.Vector 很像,但又不完全相同。
Java 中对列表的实现有两种,ArrayList 和 LinkedList。
1.2 继承结构
Java 的整个集合框架继承比较复杂,这里只画出和 ArrayList、LinkedList 相关的部分。
说明:灰色是接口(Interface),黄色是抽象类(AbstractClass),橙色是实现类(Class);虚线是实现(inplements),实线是继承(extends)。
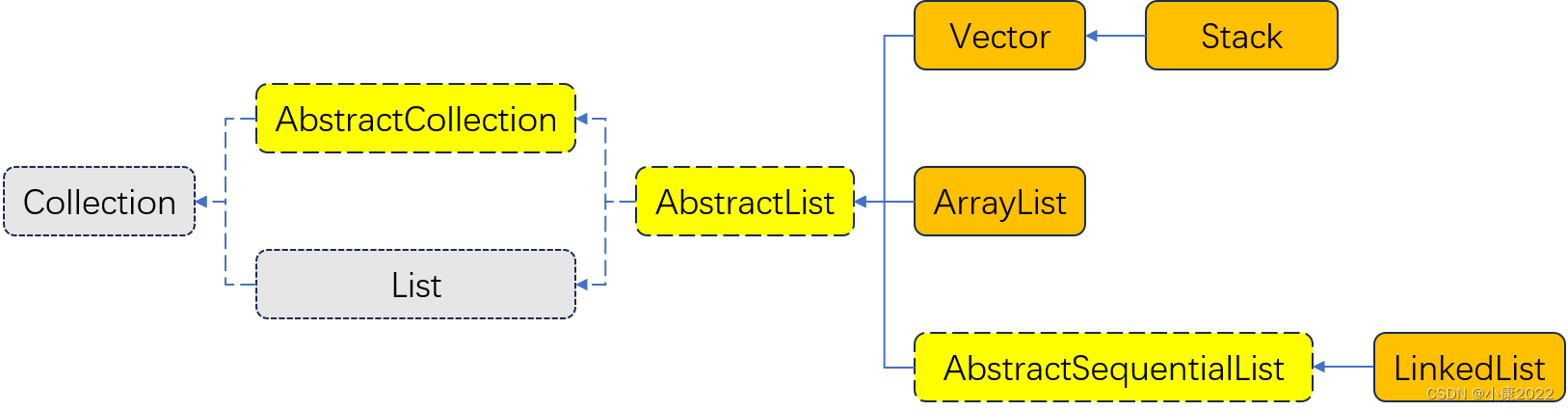
由上面可见,ArrayList 和 LinkedList 功能应该是类似的,只不过内部实现方式不同,各有优缺点,各有各的适用场景。它们都位于 java.util 中。
二、ArrayList
2.1 介绍
ArrayList 是 Java 中列表的一种实现,从类名中我们可以看出,它的底层是用数组实现的,因此 ArrayList 本质上就是一个数组队列,提供了添加、删除和修改等基本方法。
2.2 方法
下面给出类 ArrayList 的常用方法。
| 方法 | 描述 |
| boolean add(E element) | 将 element 添加到 ArrayList 的末尾,添加成功则返回 true |
| void add(int index, E element) | 将 elemnet 插入到索引为 index 的位置 |
| boolean addAll(Collection c) | 将集合 c 中的所有元素添加到 ArrayList 的末尾,成功则返回 true |
| boolean addAll(int index, Collection c) | 将集合 c 中的所有元素插入到索引为 index 的位置,成功则返回 true |
| void clear() | 清除 ArrayList 的所有元素 |
| Object clone() | 返回 ArrayList 的浅拷贝 |
| boolean contains(Object o) | 判断 ArrayList 是否含有对象 o |
| boolean containsAll(Collection c) | 判断 ArrayList 是否含有集合 c 中的全部对象 o |
| E get(int index) | 返回索引值为 index 的元素 |
| int indexOf(Object o) | 返回对象 o 在 ArrayList 中最先出现的索引,不存在则返回 -1 |
| int lastIndexOf(Object o) | 返回对象 o 在 ArrayList 中最后出现的索引,不存在则返回 -1 |
| boolean retainAll(Collection c) | 保留 ArrayList 中与集合 c 的交叉元素,成功则返回 true |
| boolean removeAll(Collection c) | 移除 ArrayList 中与集合 c 的交叉元素,成功则返回 true |
| boolean remove(Object o) | 移除 ArrayList 中最先出现的一个对象 o |
| E remove(int index) | 移除索引为 index 的元素并返回该元素 |
| int size() | 返回 ArrayList 的元素个数 |
| boolean isEmpty() | 判断 ArrayList 是否为空 |
| List<E> subList(int fromIndex, int toIndex) | 返回 ArrayList 索引从 fromIndex 开始,toIndex 结尾的部分,不包含索引为 toIndex 的元素 |
| E set(int index, E element) | 将 ArrayList 索引为 index 的元素替换为 element,并返回被替换的元素 |
| void sort(Comparator c) | 根据比较接口 c 来对 ArrayList 进行排序 |
| Object[] toArray() | 返回将 ArrayList 转换后的 Object 类型的数组,元素类型没有改变 |
| T[] toArray(T[] a) | 返回将 ArrayList 转换后的 T 类型数组 |
| String toString() | 将 ArrayList 转换成 String 类型 |
| void ensureCapacity(int minCapacity) | 将 ArrayList 的容量大小设置为 minCapacity |
| void trimToSize() | 将 ArrayList 的容量大小设置为当前元素个数 |
| void replaceAll(UnaryOperator<E> operator) | 将 ArrayList 的每个元素都执行操作 operator,并替换将返回值替换原来的元素 |
| boolean removeIf(Predicate<E> filter) | 移除 ArrayList 中符合过滤器 filter 的元素,如果成功则返回 true |
| void forEach(Comsumer<E> action) | 对 ArrayList 的每个元素都执行操作 action |
代码示例:
import java.util.*;
class Test {
public static void main(String[] args) {
ArrayList<String> arrayList = new ArrayList<>();
arrayList.add("ArrayList"); // 增加元素
arrayList.add(0, "Java"); // 插入元素
for (String s:arrayList) System.out.println(s); // 打印元素
arrayList.replaceAll(String::toUpperCase); // 替换为大写
arrayList.forEach(System.out::println); // 打印元素
System.out.println(arrayList); // Output: [JAVA, ARRAYLIST]
}
}2.3 扩容机制
ArrayList 的底层实现是数组,但数组是定长,而 ArrayList 的动态大小的,因此 ArrayList 需要在容量不够的时候进行扩容。当容量不够的时候,ArrayList 会重新开一个原来 1.5 倍大小的新数组,并将原来的数据都搬到新的数组中去,以此来完成扩容的操作。
但这里有个问题,扩容之后,ArrayList 的数组会有很多空的部分,虽然只是 1.5 倍,看起来不是很多,但在原来的数组就特别大的情况下,这 1.5 倍就显得格外多了,太浪费了,而且可能导致机器内存不足。因此 ArrayList 就设计了一些方法来解决这个问题,比如方法 ensureCapacity,它可以一次性直接将容量设置到指定的大小,防止在某些情况自动扩容导致内存不足,而方法 trimToSize 可以将容量大小立即设置为当前元素的数量,这样数组中就不会有多余的部分了。
2.4 性能分析
因为 ArrayList 是用数组实现的,因此在遍历元素上非常有优势,但由于数组定长,扩容时需要新开辟内存空间,同时还要搬运原来的数据到新的数组中,效率较低,因此 ArrayList 在增减元素这方面就稍微慢了一点。
三、LinkedList
3.1 介绍
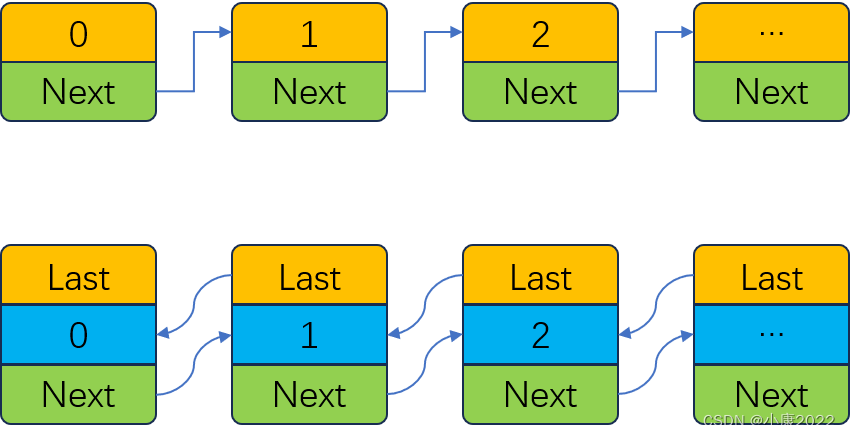
LinkedList 的底层是用链表实现的,链表是一种特殊的数据结构,主要分为单向链表和双向链表。除此之外,其余的都和 ArrayList 比较相像。
对于单向链表,每个节点都指向下一个节点的内存地址,而对于双向链表,每个节点都有两个分别指向前一个节点和后一个节点内存地址的值。LinkedList 的底层就是双向链表。
3.2 具体方法
下面具体描述 LinkedList 的常用方法。
| 方法 | 描述 |
| boolean add(E e) | 向 LinkedList 的末尾添加元素 e,成功则返回 true |
| void add(int index, E element) | 向索引为 index 的位置添加元素 element |
| boolean addAll(Collection c) | 将集合 c 中的全部元素添加到 LinkedList 的末尾,成功则返回 true |
| void addAll(int index, Collection c) | 将集合 c 中的全部元素添加到 LinkedList 中索引为 index 的位置 |
| void addFirst(E e) | 将元素 e 添加到 LinkedList 的最前端 |
| void addLast(E e) | 将元素 e 添加到 LinkedList 的最后端 |
| boolean offer(E e) | 将元素 e 添加到 LinkedList 的末尾,成功则返回 true |
| boolean offerFirst(E e) | 将元素 e 添加到 LinkedList 的最前端,成功则返回 true |
| boolean offerLast(E e) | 将元素 e 添加到 LinkedList 的最后端,成功则返回 true |
| void clear() | 清空 LinkedList 的全部元素 |
| E removeFirst() | 移除 LinkedList 中最前端的元素,并返回这个元素 |
| E removeLast() | 移除 LinkedList 中最后端的元素,并返回这个元素 |
| boolean remove(Object o) | 移除 LinkedList 中最先出现的对象 o,成功则返回 true |
| E remove(int index) | 移除 LinkedList 中索引为 index 的元素 |
| E poll() | 移除 LinkedList 中最前端的元素,并返回这个元素 |
| E remove() | 移除 LinkedList 中最前端的元素,并返回这个元素 |
| boolean contains(Object o) | 判断 LinkedList 是否包含对象 o |
| E get(int index) | 返回 LinkedList 中索引为 index 的元素 |
| E getFirst() | 返回 LinkedList 中最前端的元素 |
| E getLast() | 返回 LinkedList 中最后端的元素 |
| int indexOf(Object o) | 返回 LinkedList 中最先出现对象 o 的索引,若没有则返回 -1 |
| int lastIndexOf(Object o) | 返回 LinkedList 中最后出现对象 o 的索引,若没有则返回 -1 |
| E element() | 返回 LinkedList 的第一个元素 |
| E peek() | 返回 LinkedList 的第一个元素 |
| E peekFirst() | 返回 LinkedList 的头部元素 |
| E peekLast() | 返回 LinkedList 的尾部元素 |
| E set(int index, E element) | 将 LinkedList 中索引为 index 的元素替换为元素 element,并返回被替换的元素 |
| Object clone() | 返回 LinkedList 的浅拷贝 |
| Iterator descendingIterator() | 返回 LinkedList 的倒序迭代器 |
| int size() | 返回 LinkedList 的元素个数 |
| ListIterator listIterator() | 返回 LinkedList 的顺序迭代器 |
| ListIterator listIterator(int index) | 返回 LinkedList 从索引为 index 的位置开始的顺序迭代器 |
| Object[] toArray() | 返回将 LinkedList 转换后的 Object 类型的数组,元素类型没有改变 |
| T[] toArray(T[] a) | 返回将 LinkedList 转换后的 T 类型数组 |
| String toString() | 将 LinkedList 转换成 String 类型 |
代码示例:
import java.util.*;
class Test {
public static void main(String[] args) {
LinkedList<String> linkedList = new LinkedList<>();
linkedList.add("LinkedList"); // 增加元素
linkedList.add(0, "Java"); // 插入元素
for (String s:linkedList) System.out.println(s); // 打印元素
linkedList.replaceAll(String::toUpperCase); // 替换为大写
linkedList.forEach(System.out::println); // 打印元素
System.out.println(linkedList); // Output: [JAVA, LINKEDLIST]
}
}3.3 性能分析
LinkedList 的底层是用链表这种数据结构实现的,而链表每个节点之间是通过内存地址来联系的,因此它不能像数组那样直接访问到某一索引处的元素,只能从头开始遍历,直到找到该元素,所以 LinkedList 在遍历上性能偏低。但正因为它是由链表实现的,不需要像 ArrayList 那样对数组进行 1.5 倍大小的扩容,每次增加元素只需要扩增一个节点就行了,因此 LinkedList 在增减元素上性能较好。
四、二者的联系和区别
4.1 联系
ArrayList 和 LinkedList 都是用来存储数据的线性结构,都属于 Java 中的集合框架,都实现了 List 接口的功能。
4.2 区别
ArrayList 和 LinkedList 各有优缺点,适用场景不一样。
- ArrayList 的底层数据结构是数组;LinkedList 的底层数据结构是链表;
- ArrayList 在遍历元素上性能较优,而在增减元素上性能较差;LinkedList 在遍历元素上性能较差,而在增减元素上性能较优;
- 一般情况下,由于 ArrayList 的 1.5 倍扩容机制,因此 ArrayList 比 LinkedList 更占用内存空间;相同容量情况下,由于 LinkedList 每个节点需要记住前后节点的地址,因此 LinkedList 比 ArrayList 更加占用内存空间;
查找和修改需要较高的遍历性能,而增加和减少需要较高的增减性能。因此,若需要频繁地查找和修改元素,且一般只在末尾增减元素的情况下,应该采用 ArrayList;在需要频繁增减开头和中间部分元素的情况下,应该采用 LinkedList。