# 关注并星标腾讯云开发者
# 每周4 | 鹅厂一线程序员,为你“试毒”新技术
# 第1期 | 腾讯王锐:测评二维码艺术画生成体验

都说AI绘画来势汹汹,但论创意,还是人类玩得花🤫。下面这几张乍一看平平无奇、却在网上疯传的AI生成图片,你能看出其中暗藏的玄机吗?




建议大家在手机上手动缩放一下这些图。缩得越小,图片夹带的文字/二维码能展示得更清晰。
还有网友给了别的“认字”秘诀,比如摘下你的近视眼镜:

大家可以发现,这些图片生成的思路如出一辙——通过光影、着色等等控制手段,确保文字或者二维码作为光影、衣服图案等,融入图像中。
令本人震惊的是,艺术画二维码还是由几位在校学生使用 ControlNet+StableDiffusion 生成的。后生可畏!他们训练的 ControlNet 生成的二维码图片极具艺术感。二维码不再是经典的黑白格子矩阵,而是被巧妙地融合在图片的内容当中。

@倪豪@陈柏宇(时辰) @王照涵 @陈智勇的 QR Code ControlNet 作品
我不禁思考这种图为什么依然是一个可用的二维码呢?怎样才能制作这样的二维码图片呢?遂开始一次小实验。

首先我们需要快速了解二维码识别的原理。

二维码图片主要包含定位图案(图上的三个大“回”形方框)、中间的点阵数据图案。二维码的扫描过程看上去也很复杂,我看了一下网上的介绍,粗略地将其解码过程总结为:
根据三个定位图案检测以及“摆正”二维码。
将二维码区域转换为灰度图,切分成不重叠的区块,每个区块内单独计算得到一个阈值,高于阈值的为1,小于阈值的为0。
根据一定的规则,从读取的一串010110...数据流中解码得到信息。二维码的编码有一定的冗余,数据流中偶然几位的0,1被搞混也不会影响解码。
因此,虽然上面这些艺术画二维码看上去不再是黑白格子矩阵,但只要它:
依然包含关键的三个定位图案。
定位图案包围的数据区域有明显的亮暗关系变化,可以被解码为0,1数据流。
数据流中被扰乱的0,1比特还没有那么多,还能被冗余信息恢复。
那么它就是一个二维码。
总结一下:只要二维码的亮暗关系还没被破坏得太多,那就还是一个可用的二维码?
好的,现在我们已经知道关键点是保留亮暗关系了,接着一个问题就是,怎么才能制作满足这种亮暗关系的二维码图片?
引子中提到的文章作者并没有透露他们使用的 ControlNet 方案。现网制作这些二维码的方案很多,而且效果上差距还挺明显。
下面我尽量多介绍几种合成艺术画二维码的方案,例如开源社区很快有人提出可以用 tile_resample ControlNet ,来模拟一下类似的效果。

ControlNet 1.1 Tile 是 ControlNet 作者(github: lllyasviel)制作的一个功能类似于补充细节的 ControlNet。
当被输入丢失了很多细节纹理的图片(如下面的模糊狗狗图)时:

输出则是一幅正常的细节完善的图片:

利用其补细节这一特性,我们使用一张包含黑白格子二维码的图片作为 ControlNet 的输入,同时用 ControlNet 的输入当作 img2img 的垫图,即基于 resample ControlNet + img2img,可以搞出类似于下图的效果:

具体来说,用这种图同时当作 img2img 的垫图及 ControlNet 的输入:

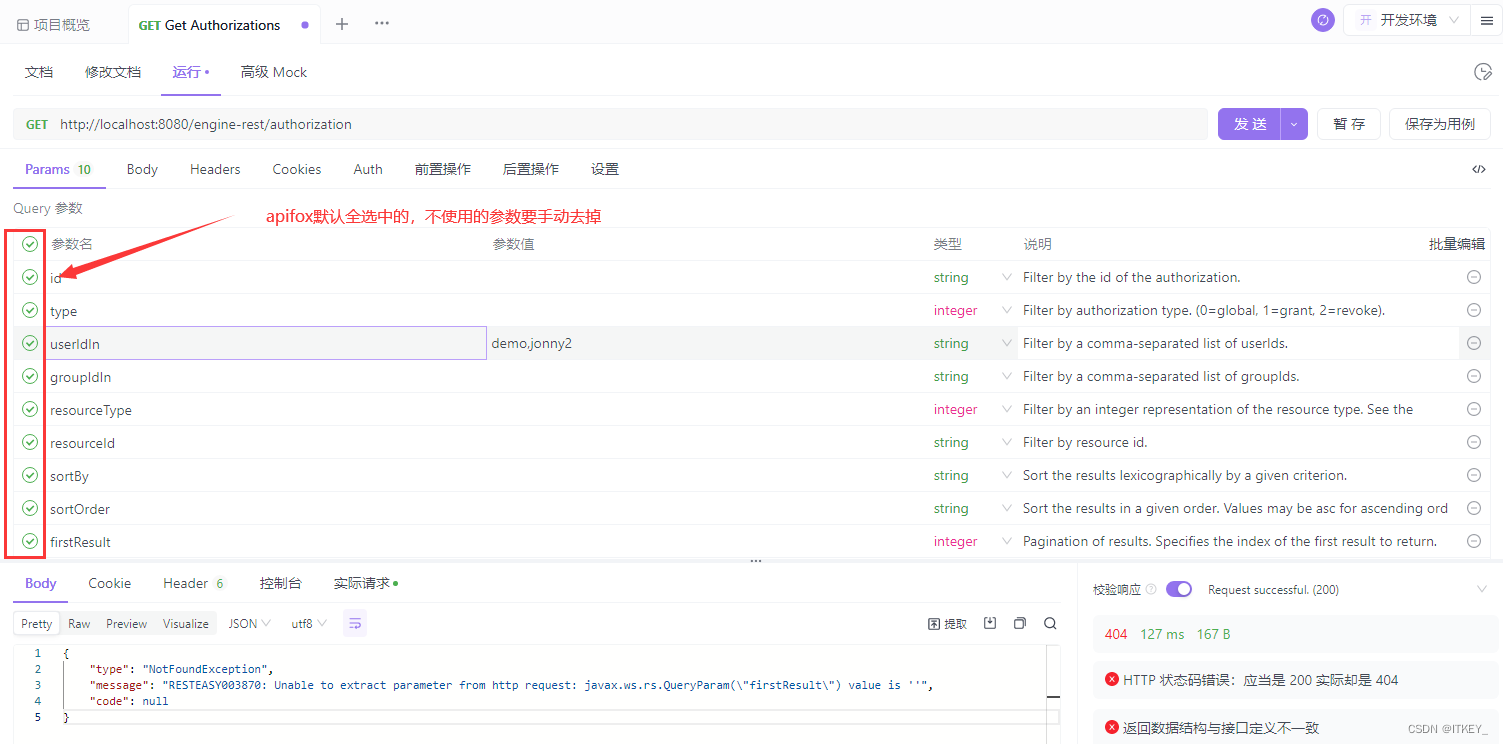
在 Stable Diffusion WebUI 的 img2img Tab,设置调整那一系列参数,然后点 Generate 就可以“开盲盒”了。
为了降低大家“开盲盒”的难度,我这里分享下我使用的 WebUI 参数:
Tony Stark, bruise wounded, wet soaked, water splash, torn apart, ripped clothes, random background vintage, neons lights, (high detailed skin:1.2), 8k uhd, dslr, soft lighting, hyperdetailed, intricately detailed, unreal engine, fantastical, ideal human, high quality, film grain, bokeh, Fujifilm XT3, hyper realisticNegative prompt: ugly, disfigured, low quality, blurry, nsfwSteps: 50, Sampler: DPM++ 2M Karras, CFG scale: 10, Seed: 3724036266, Size: 768x768, Model hash: 4199bcdd14, Model: revAnimated_v122, Denoising strength: 0.85, Mask blur: 4, ControlNet 1: "preprocessor: tile_resample, model: control_v11f1e_sd15_tile [a371b31b], weight: 0.8, starting/ending: (0.23, 0.9), resize mode: Just Resize, pixel perfect: False, control mode: Balanced, preprocessor params: (512, 1, 64)"我用了 revAnimated_v122 模型,Prompt 和 Negative Prompt 已经包含在上面。
最关键的 ControlNet 参数是:
ControlNet 1: "preprocessor: tile_resample, model: control_v11f1e_sd15_tile [a371b31b], weight: 0.8, starting/ending: (0.23, 0.9), resize mode: Just Resize, pixel perfect: False, control mode: Balanced, preprocessor params: (512, 1, 64)"这里 weight: 0.8, starting/ending: (0.23, 0.9),是我主要调整的参数。分别对应了 ControlNet 起效的力度、起效的 diffusion step 开始与结束。这本质上是在调整 ControlNet 在图生图过程中的作用大小。
ControlNet 作用太大,出来的图格子感太重;反之作用太小,生成图很有可能已经不是二维码了。
当然,你可以预先调整一下输入图的二维码颜色位置,提前安排一下生成结果中二维码大概的颜色和位置。比如把二维码设置成红色,那么你就能得到下面这幅铠甲颜色更为自然的图片。

这种方案我测试了很久,真实体验就是:摸奖的成分很重。
比如上面的钢铁侠二维码,调整好 ControlNet+img2img 参数后,大部分随机数种子对应的图片中钢铁侠的人脸都有黑白格子对应的”污损“:


想得到上面那种脸没有污损的图片,要抽很多随机数种子(随机数选42结果不好,我试了ヾ(•ω•)o)。
自然而然地,我又有一个问题:有没有办法指定图中人物的位置 or 姿势呢?用多了 WebUI 的开发者,能立马想到再加一个 ControlNet 控制人物的方案(当然我没想到,在 reddit 上盯了半天才学到这个方案)。

这一方案是上面的方案改进版。
ControlNet tile 负责补充二维码区域的纹理细节,ControlNet OpenPose 负责控制人物位置。
依然是用 Stable Diffusion WebUI 的 img2img tab,但开启了两个 ControlNet。其中 ControlNet1 是 Openpose:输入图及其提供的火柴人 pose 图如下:

ControlNet2 则是和上一个方案类似的一个带二维码的图片:

依然公开一下我调出来的 webui 参数,供大家参考:
futobot, cyborg, ((masterpiece),(best quality),(ultra-detailed), (full body:1.2), 1 female, solo, hood up, upper body, mask, 1 girl, female focus, black gloves, cloak, long sleevesNegative prompt: paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, glans, nsfw, nipples, (((necklace))), (worst quality, low quality:1.2), watermark, username, signature, text, multiple breasts, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, bad feet, single color, ((((ugly)))), (((duplicate))), ((morbid)), ((mutilated)), (((tranny))), (((trans))), (((trannsexual))), (hermaphrodite), extra fingers, mutated hands, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))), ((extra limbs)), (((disfigured))), (bad anatomy), gross proportions, (malformed limbs), ((missing arms)), (missing legs), (((extra arms))), (((extra legs))), mutated hands,(fused fingers), (too many fingers), (((long neck))), (bad body perspect:1.1)Steps: 60, Sampler: DPM++ 2M Karras, CFG scale: 11, Seed: 2912497446, Size: 768x768, Model hash: ed4f26c284, Model: camelliamix25D_v2, Denoising strength: 1, Mask blur: 4, ControlNet 0: "preprocessor: openpose_full, model: control_sd15_openpose [fef5e48e], weight: 1, starting/ending: (0, 1), resize mode: Resize and Fill, pixel perfect: False, control mode: Balanced, preprocessor params: (512, 64, 64)", ControlNet 1: "preprocessor: tile_resample, model: control_v11f1e_sd15_tile [a371b31b], weight: 0.75, starting/ending: (0.23, 1), resize mode: Resize and Fill, pixel perfect: False, control mode: Balanced, preprocessor params: (512, 1, 64)"这种方案生成的图片类似于这样:

更换一下提供姿势的图片,就能调整生成图片中人物的姿势:

这个方案的生成效果格子感很重,但成功率较高。基本上每个随机数种子的结果都大差不差,毕竟使用了两个 ControlNet,对生成图片的控制程度提升了很多。
以上两个方案虽然能搞出一些惊艳的效果,但是整体上看成功率不高,生成图格子感也比较重。
看来,针对二维码这个特定的场景,单独训练一个对应的 QRCode ControlNet 还是很有必要的。

本人在研究上面两个方案的同时,发现huggingface 上有人开源了一个 QRCode ControlNet。这个 ControlNet 效果怎么样呢?
社区开源的 QRCodeControlNet 在:DionTimmer/controlnet_qrcode-control_v1p_sd15 · Hugging Face 其展示的效果类似于:

我个人评价不是特别好。它使用成对的二维码及其艺术二维码图片作为训练集,生成的图片二维码感非常强,可扫性很高,但不好看。
但即使是这样,开源到社区后,还是很快有人用这个模型搞出来类似于下图这样的效果:

是不是感觉还可以?开源社区调 Prompt 的技巧还是很强的!但我觉得它这种思路还是有点问题。
我们期望的是生成的图片看不出来是二维码。如果训练时就用了一堆二维码图片当作输出,那么网络就会很快地过拟合到二维码域,二维码感会很强。我们需要的是没有“二维码感”的二维码!有没有什么更好的思路呢?

在尝试训练 ControlNet 前,先要理清楚如何构造数据。回顾一下,我们期望的 ControlNet 有两个关键点:
ControlNet tile 实际上解决了第一个问题,配合着 img2img,它能够把输入二维码的明暗关系保留下来,但同时也过多地保留了输入图的颜色,以及“格子感”。保留明暗,忽略颜色、格子......
这些需求启发我设计了对应的数据处理策略,训练一个专门的 QRCode ControlNet。初步测试的结果也支持了我的想法。
上述两个关键点启发的 QRCode ControlNet 能得到一些类似于这样的输出:

但是还有一个问题:二维码出现的位置还是很突兀。感觉二维码和图片没有很自然地融合在一起。之后,我又思考了一下突兀问题的解法,给上面的思路增加了一点细节。可以得到下面这样的二维码艺术画:


自训练的 QRCode ControlNet 制作的图片美观程度,相较于其它方法改进了很多。我也制作了一个生成 demo 分享给了同事,大家基本上很容易就能生成一些很美观的二维码图片,远胜于之前我一个人用 Stable Diffusion WebUI 频繁“开盲盒”。
也许会有读者朋友想要个艺术二维码生成体验链接?先卖个关子,相关的体验活动近期会在QQ上线。上面提到的多个生成思路,非常推荐大家动手体验!!
整体来说,萌生 AIGC 二维码这个想法后的这个探索过程,我学着用起了 Stable Diffusion WebUI,尝试了很多方案最终才有了一个还不错的效果,体验到了一种解密的快感。实际效果其实也超出了我原先预期,这就是 AIGC的奇妙可能性。欢迎大家转发分享~
-End-
原创作者|王锐
古有神农尝百草,一日而遇七十毒。今有码农尝百技,拥抱变化、让星火燎原。我们推出《码农尝百草》栏目,每期邀请腾讯工程师“试毒”新技术。
你还想看腾讯工程师体验测评哪些新产品、新技术?对本栏目有什么建议和看法?欢迎留言。我们将为1位提案提供者送出腾讯定制程序员文化衫。8月3日中午12点开奖。

*如果您不希望您的留言被精选公开,可以在留言时加入文字备注。





关注并星标腾讯云开发者
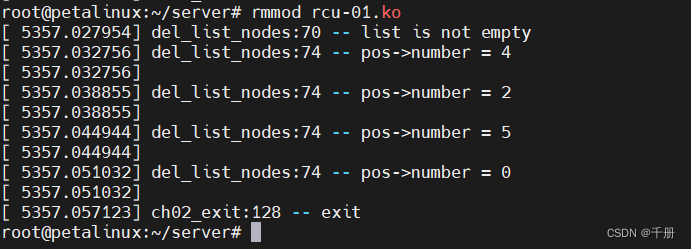
每周4看鹅厂程序员测评新技术